 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MuChin: A Chinese Colloquial Description Benchmark for Evaluating Language Models in the Field of Music
Feb 15, 2024
The rapidly evolving multimodal Large Language Models (LLMs) urgently require new benchmarks to uniformly evaluate their performance on understanding and textually describing music. However, due to semantic gaps between Music Information Retrieval (MIR) algorithms and human understanding, discrepancies between professionals and the public, and low precision of annotations, existing music description datasets cannot serve as benchmarks. To this end, we present MuChin, the first open-source music description benchmark in Chinese colloquial language, designed to evaluate the performance of multimodal LLMs in understanding and describing music. We established the Caichong Music Annotation Platform (CaiMAP) that employs an innovative multi-person, multi-stage assurance method, and recruited both amateurs and professionals to ensure the precision of annotations and alignment with popular semantics. Utilizing this method, we built a dataset with multi-dimensional, high-precision music annotations, the Caichong Music Dataset (CaiMD), and carefully selected 1,000 high-quality entries to serve as the test set for MuChin. Based on MuChin, we analyzed the discrepancies between professionals and amateurs in terms of music description, and empirically demonstrated the effectiveness of annotated data for fine-tuning LLMs. Ultimately, we employed MuChin to evaluate existing music understanding models on their ability to provide colloquial descriptions of music. All data related to the benchmark and the code for scoring have been open-sourced.
A Framework For Gait-Based User Demography Estimation Using Inertial Sensors
Feb 15, 2024Human gait has been shown to provide crucial motion cues for various applications. Recognizing patterns in human gait has been widely adopted in various application areas such as security, virtual reality gaming, medical rehabilitation, and ailment identification. Furthermore, wearable inertial sensors have been widely used for not only recording gait but also to predict users' demography. Machine Learning techniques such as deep learning, combined with inertial sensor signals, have shown promising results in recognizing patterns in human gait and estimate users' demography. However, the black-box nature of such deep learning models hinders the researchers from uncovering the reasons behind the model's predictions. Therefore, we propose leveraging deep learning and Layer-Wise Relevance Propagation (LRP) to identify the important variables that play a vital role in identifying the users' demography such as age and gender. To assess the efficacy of this approach we train a deep neural network model on a large sensor-based gait dataset consisting of 745 subjects to identify users' age and gender. Using LRP we identify the variables relevant for characterizing the gait patterns. Thus, we enable interpretation of non-linear ML models which are experts in identifying the users' demography based on inertial signals. We believe this approach can not only provide clinicians information about the gait parameters relevant to age and gender but also can be expanded to analyze and diagnose gait disorders.
AbuseGPT: Abuse of Generative AI ChatBots to Create Smishing Campaigns
Feb 15, 2024SMS phishing, also known as "smishing", is a growing threat that tricks users into disclosing private information or clicking into URLs with malicious content through fraudulent mobile text messages. In recent past, we have also observed a rapid advancement of conversational generative AI chatbot services (e.g., OpenAI's ChatGPT, Google's BARD), which are powered by pre-trained large language models (LLMs). These AI chatbots certainly have a lot of utilities but it is not systematically understood how they can play a role in creating threats and attacks. In this paper, we propose AbuseGPT method to show how the existing generative AI-based chatbot services can be exploited by attackers in real world to create smishing texts and eventually lead to craftier smishing campaigns. To the best of our knowledge, there is no pre-existing work that evidently shows the impacts of these generative text-based models on creating SMS phishing. Thus, we believe this study is the first of its kind to shed light on this emerging cybersecurity threat. We have found strong empirical evidences to show that attackers can exploit ethical standards in the existing generative AI-based chatbot services by crafting prompt injection attacks to create newer smishing campaigns. We also discuss some future research directions and guidelines to protect the abuse of generative AI-based services and safeguard users from smishing attacks.
Towards Robust Model-Based Reinforcement Learning Against Adversarial Corruption
Feb 15, 2024This study tackles the challenges of adversarial corruption in model-based reinforcement learning (RL), where the transition dynamics can be corrupted by an adversary. Existing studies on corruption-robust RL mostly focus on the setting of model-free RL, where robust least-square regression is often employed for value function estimation. However, these techniques cannot be directly applied to model-based RL. In this paper, we focus on model-based RL and take the maximum likelihood estimation (MLE) approach to learn transition model. Our work encompasses both online and offline settings. In the online setting, we introduce an algorithm called corruption-robust optimistic MLE (CR-OMLE), which leverages total-variation (TV)-based information ratios as uncertainty weights for MLE. We prove that CR-OMLE achieves a regret of $\tilde{\mathcal{O}}(\sqrt{T} + C)$, where $C$ denotes the cumulative corruption level after $T$ episodes. We also prove a lower bound to show that the additive dependence on $C$ is optimal. We extend our weighting technique to the offline setting, and propose an algorithm named corruption-robust pessimistic MLE (CR-PMLE). Under a uniform coverage condition, CR-PMLE exhibits suboptimality worsened by $\mathcal{O}(C/n)$, nearly matching the lower bound. To the best of our knowledge, this is the first work on corruption-robust model-based RL algorithms with provable guarantees.
LaserSAM: Zero-Shot Change Detection Using Visual Segmentation of Spinning LiDAR
Feb 15, 2024This paper presents an approach for applying camera perception techniques to spinning LiDAR data. To improve the robustness of long-term change detection from a 3D LiDAR, range and intensity information are rendered into virtual perspectives using a pinhole camera model. Hue-saturation-value image encoding is used to colourize the images by range and near-IR intensity. The LiDAR's active scene illumination makes it invariant to ambient brightness, which enables night-to-day change detection without additional processing. Using the colourized, perspective range image allows existing foundation models to detect semantic regions. Specifically, the Segment Anything Model detects semantically similar regions in both a previously acquired map and live view from a path-repeating robot. By comparing the masks in both views, changes in the live scan are detected. Results indicate that the Segment Anything Model is capable of accurately capturing the shape of arbitrary changes introduced into scenes. The system achieves an object recall of 82.6% and a precision of 47.0%. Changes can be detected through day-to-night illumination variations reliably. After pixel-level masks are generated, the one-to-one correspondence with 3D points means that the 2D masks can be directly used to recover the 3D location of the changes. Eventually, the detected 3D changes can be avoided by treating them as obstacles in a local motion planner.
The Duet of Representations and How Explanations Exacerbate It
Feb 13, 2024An algorithm effects a causal representation of relations between features and labels in the human's perception. Such a representation might conflict with the human's prior belief. Explanations can direct the human's attention to the conflicting feature and away from other relevant features. This leads to causal overattribution and may adversely affect the human's information processing. In a field experiment we implemented an XGBoost-trained model as a decision-making aid for counselors at a public employment service to predict candidates' risk of long-term unemployment. The treatment group of counselors was also provided with SHAP. The results show that the quality of the human's decision-making is worse when a feature on which the human holds a conflicting prior belief is displayed as part of the explanation.
Retrieve, Merge, Predict: Augmenting Tables with Data Lakes
Feb 13, 2024We present an in-depth analysis of data discovery in data lakes, focusing on table augmentation for given machine learning tasks. We analyze alternative methods used in the three main steps: retrieving joinable tables, merging information, and predicting with the resultant table. As data lakes, the paper uses YADL (Yet Another Data Lake) -- a novel dataset we developed as a tool for benchmarking this data discovery task -- and Open Data US, a well-referenced real data lake. Through systematic exploration on both lakes, our study outlines the importance of accurately retrieving join candidates and the efficiency of simple merging methods. We report new insights on the benefits of existing solutions and on their limitations, aiming at guiding future research in this space.
Multi-Behavior Collaborative Filtering with Partial Order Graph Convolutional Networks
Feb 12, 2024Representing the information of multiple behaviors in the single graph collaborative filtering (CF) vector has been a long-standing challenge. This is because different behaviors naturally form separate behavior graphs and learn separate CF embeddings. Existing models merge the separate embeddings by appointing the CF embeddings for some behaviors as the primary embedding and utilizing other auxiliaries to enhance the primary embedding. However, this approach often results in the joint embedding performing well on the main tasks but poorly on the auxiliary ones. To address the problem arising from the separate behavior graphs, we propose the concept of Partial Order Graphs (POG). POG defines the partial order relation of multiple behaviors and models behavior combinations as weighted edges to merge separate behavior graphs into a joint POG. Theoretical proof verifies that POG can be generalized to any given set of multiple behaviors. Based on POG, we propose the tailored Partial Order Graph Convolutional Networks (POGCN) that convolute neighbors' information while considering the behavior relations between users and items. POGCN also introduces a partial-order BPR sampling strategy for efficient and effective multiple-behavior CF training. POGCN has been successfully deployed on the homepage of Alibaba for two months, providing recommendation services for over one billion users. Extensive offline experiments conducted on three public benchmark datasets demonstrate that POGCN outperforms state-of-the-art multi-behavior baselines across all types of behaviors. Furthermore, online A/B tests confirm the superiority of POGCN in billion-scale recommender systems.
Multimodal Clinical Trial Outcome Prediction with Large Language Models
Feb 09, 2024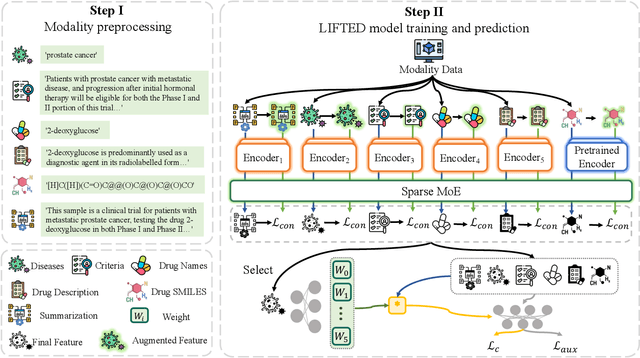
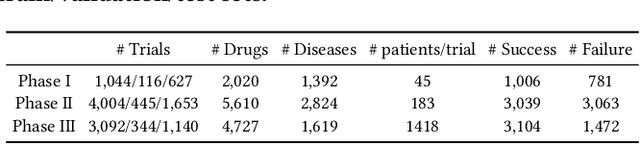
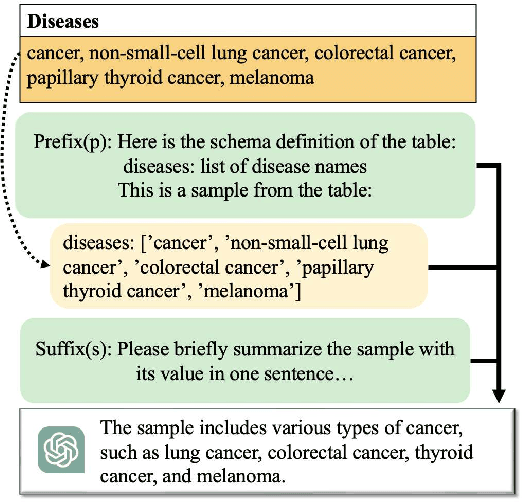
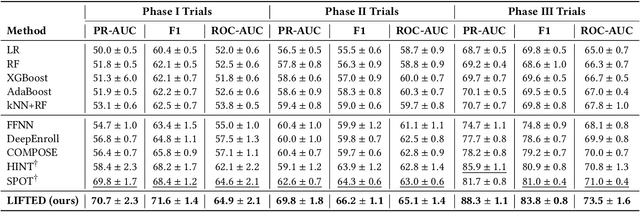
The clinical trial is a pivotal and costly process, often spanning multiple years and requiring substantial financial resources. Therefore, the development of clinical trial outcome prediction models aims to exclude drugs likely to fail and holds the potential for significant cost savings. Recent data-driven attempts leverage deep learning methods to integrate multimodal data for predicting clinical trial outcomes. However, these approaches rely on manually designed modal-specific encoders, which limits both the extensibility to adapt new modalities and the ability to discern similar information patterns across different modalities. To address these issues, we propose a multimodal mixture-of-experts (LIFTED) approach for clinical trial outcome prediction. Specifically, LIFTED unifies different modality data by transforming them into natural language descriptions. Then, LIFTED constructs unified noise-resilient encoders to extract information from modal-specific language descriptions. Subsequently, a sparse Mixture-of-Experts framework is employed to further refine the representations, enabling LIFTED to identify similar information patterns across different modalities and extract more consistent representations from those patterns using the same expert model. Finally, a mixture-of-experts module is further employed to dynamically integrate different modality representations for prediction, which gives LIFTED the ability to automatically weigh different modalities and pay more attention to critical information. The experiments demonstrate that LIFTED significantly enhances performance in predicting clinical trial outcomes across all three phases compared to the best baseline, showcasing the effectiveness of our proposed key components.
VCR: Video representation for Contextual Retrieval
Feb 12, 2024Streamlining content discovery within media archives requires integrating advanced data representations and effective visualization techniques for clear communication of video topics to users. The proposed system addresses the challenge of efficiently navigating large video collections by exploiting a fusion of visual, audio, and textual features to accurately index and categorize video content through a text-based method. Additionally, semantic embeddings are employed to provide contextually relevant information and recommendations to users, resulting in an intuitive and engaging exploratory experience over our topics ontology map using OpenAI GPT-4.