 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DProST: 6-DoF Object Pose Estimation Using Space Carving and Dynamic Projective Spatial Transformer
Dec 16, 2021
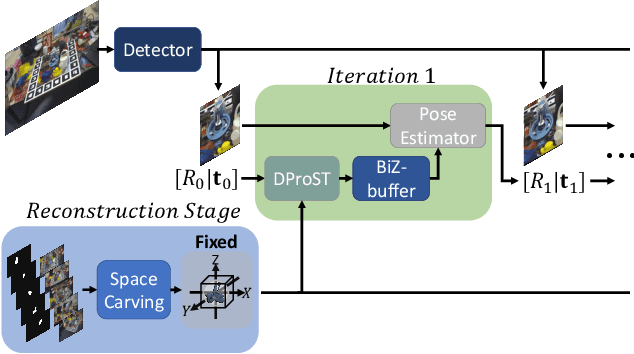
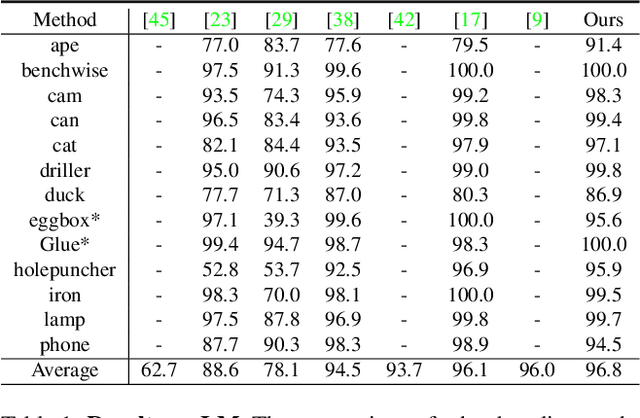
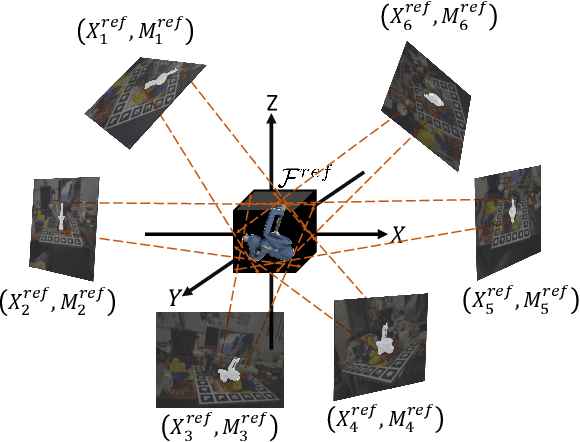
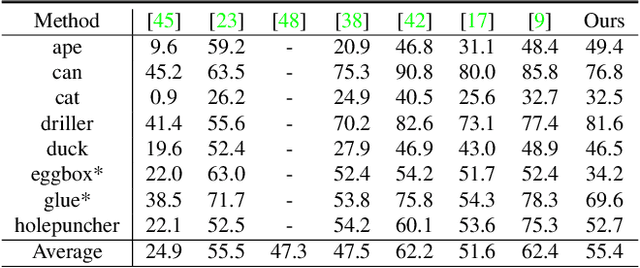
Predicting the pose of an object is a core computer vision task. Most deep learning-based pose estimation methods require CAD data to use 3D intermediate representations or project 2D appearance. However, these methods cannot be used when CAD data for objects of interest are unavailable. Besides, the existing methods did not precisely reflect the perspective distortion to the learning process. In addition, information loss due to self-occlusion has not been studied well. In this regard, we propose a new pose estimation system consisting of a space carving module that reconstructs a reference 3D feature to replace the CAD data. Moreover, Our new transformation module, Dynamic Projective Spatial Transformer (DProST), transforms a reference 3D feature to reflect the pose while considering perspective distortion. Also, we overcome the self-occlusion problem by a new Bidirectional Z-buffering (BiZ-buffer) method, which extracts both the front view and the self-occluded back view of the object. Lastly, we suggest a Perspective Grid Distance Loss (PGDL), enabling stable learning of the pose estimator without CAD data. Experimental results show that our method outperforms the state-of-the-art method on the LINEMOD dataset and comparable performance on LINEMOD-OCCLUSION dataset even compared to the methods that require CAD data in network training.
Anonymization for Skeleton Action Recognition
Nov 30, 2021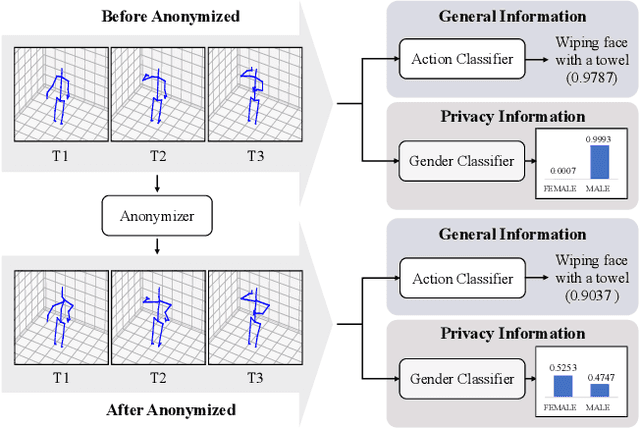
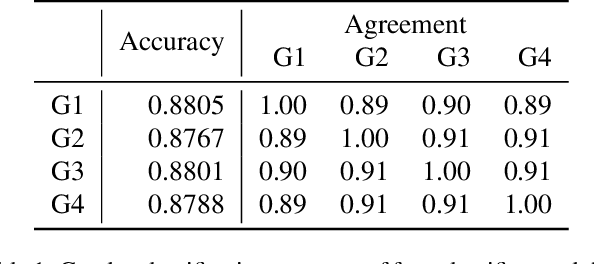
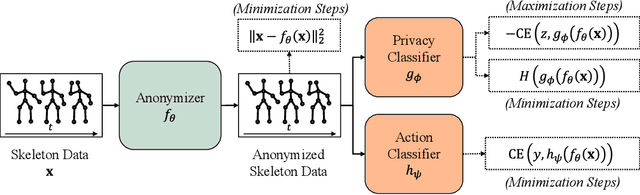
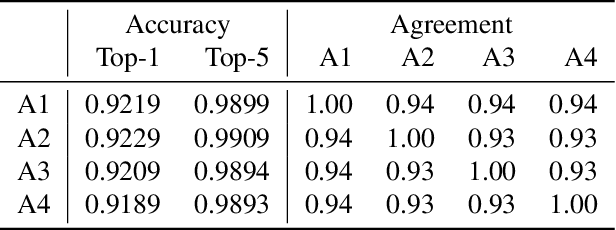
The skeleton-based action recognition attracts practitioners and researchers due to the lightweight, compact nature of datasets. Compared with RGB-video-based action recognition, skeleton-based action recognition is a safer way to protect the privacy of subjects while having competitive recognition performance. However, due to the improvements of skeleton estimation algorithms as well as motion- and depth-sensors, more details of motion characteristics can be preserved in the skeleton dataset, leading to a potential privacy leakage from the dataset. To investigate the potential privacy leakage from the skeleton datasets, we first train a classifier to categorize sensitive private information from a trajectory of joints. Experiments show the model trained to classify gender can predict with 88% accuracy and re-identify a person with 82% accuracy. We propose two variants of anonymization algorithms to protect the potential privacy leakage from the skeleton dataset. Experimental results show that the anonymized dataset can reduce the risk of privacy leakage while having marginal effects on the action recognition performance.
Pre-scaling and Codebook Design for Joint Radar and Communication Based on Index Modulation
Nov 20, 2021
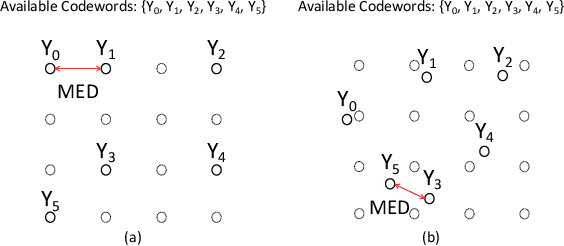
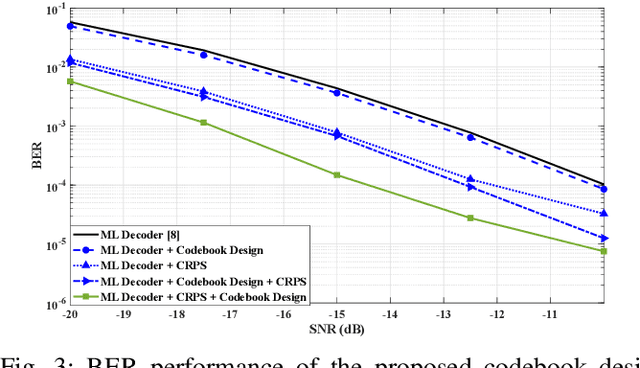
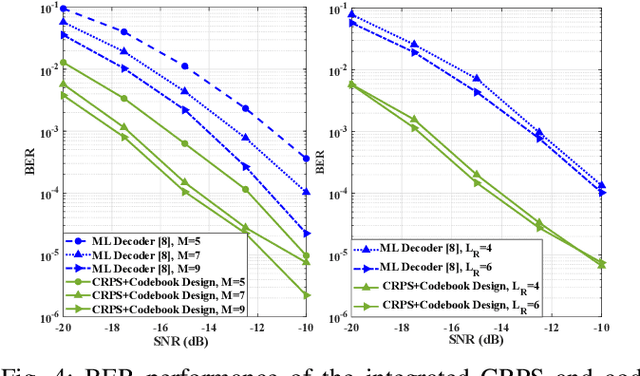
This paper develops an efficient index modulation (IM) approach for the joint radar-communication (JRC) system based on a multi-carrier multiple-input multiple-output (MIMO) radar. The communication information is embedded into the transmitted radar pulses by selecting the corresponding indices of the carrier frequencies and antenna allocations, providing two degrees of freedom. Our contribution involves the development of a novel codebook based minimum Euclidean distance (MED) maximization and a constellation randomization pre-scaling (CRPS) scheme for efficient IM-JRC transmission. It can be inferred that the IM approach integrating the CRPS scheme followed by the codebook design maximizes the signal-to-noise ratio gain. The numerical results support the effectiveness of the proposed approach and show enhanced bit error rate performance when compared to the existing baseline.
A Broad-persistent Advising Approach for Deep Interactive Reinforcement Learning in Robotic Environments
Oct 15, 2021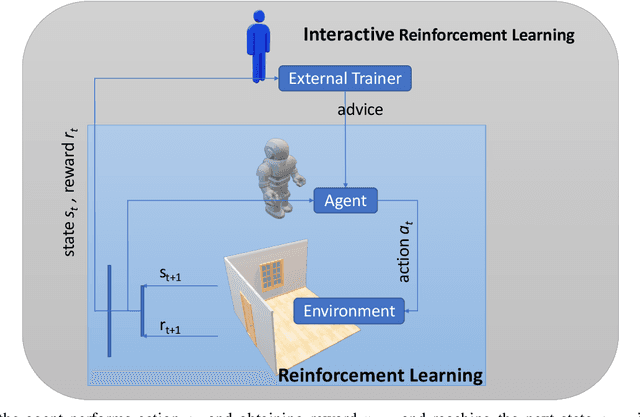
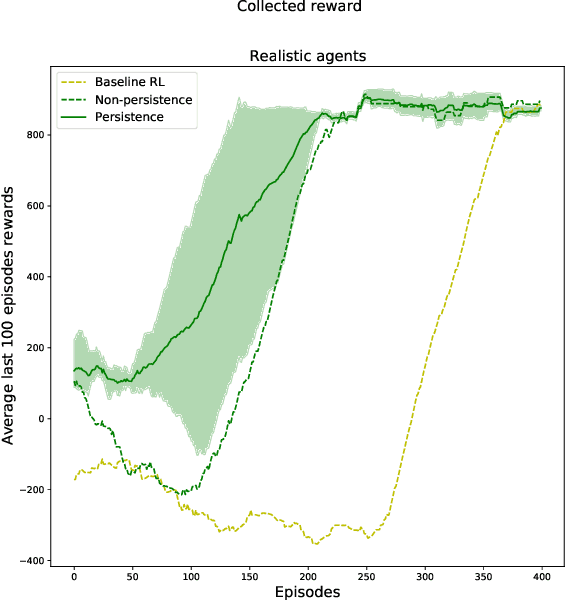
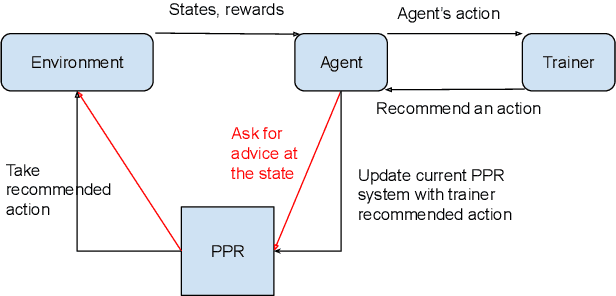
Deep Reinforcement Learning (DeepRL) methods have been widely used in robotics to learn about the environment and acquire behaviors autonomously. Deep Interactive Reinforcement Learning (DeepIRL) includes interactive feedback from an external trainer or expert giving advice to help learners choosing actions to speed up the learning process. However, current research has been limited to interactions that offer actionable advice to only the current state of the agent. Additionally, the information is discarded by the agent after a single use that causes a duplicate process at the same state for a revisit. In this paper, we present Broad-persistent Advising (BPA), a broad-persistent advising approach that retains and reuses the processed information. It not only helps trainers to give more general advice relevant to similar states instead of only the current state but also allows the agent to speed up the learning process. We test the proposed approach in two continuous robotic scenarios, namely, a cart pole balancing task and a simulated robot navigation task. The obtained results show that the performance of the agent using BPA improves while keeping the number of interactions required for the trainer in comparison to the DeepIRL approach.
CONFIT: Toward Faithful Dialogue Summarization with Linguistically-Informed Contrastive Fine-tuning
Dec 16, 2021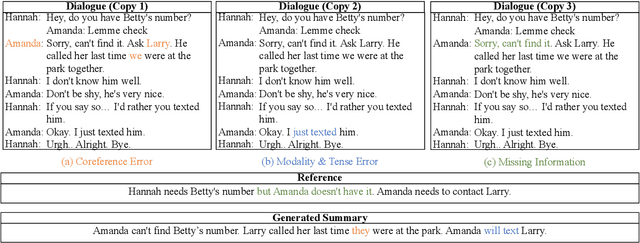
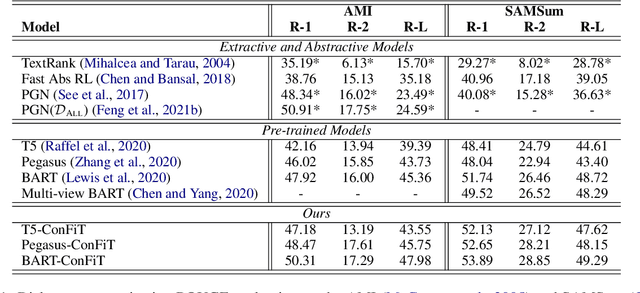
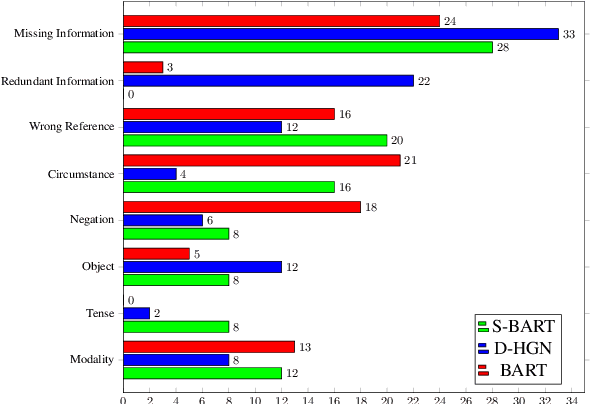
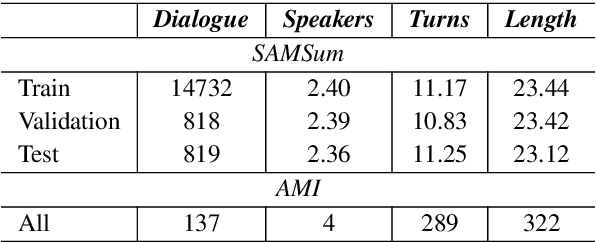
Factual inconsistencies in generated summaries severely limit the practical applications of abstractive dialogue summarization. Although significant progress has been achieved by using pre-trained models, substantial amounts of hallucinated content are found during the human evaluation. Pre-trained models are most commonly fine-tuned with cross-entropy loss for text summarization, which may not be an optimal strategy. In this work, we provide a typology of factual errors with annotation data to highlight the types of errors and move away from a binary understanding of factuality. We further propose a training strategy that improves the factual consistency and overall quality of summaries via a novel contrastive fine-tuning, called ConFiT. Based on our linguistically-informed typology of errors, we design different modular objectives that each target a specific type. Specifically, we utilize hard negative samples with errors to reduce the generation of factual inconsistency. In order to capture the key information between speakers, we also design a dialogue-specific loss. Using human evaluation and automatic faithfulness metrics, we show that our model significantly reduces all kinds of factual errors on the dialogue summarization, SAMSum corpus. Moreover, our model could be generalized to the meeting summarization, AMI corpus, and it produces significantly higher scores than most of the baselines on both datasets regarding word-overlap metrics.
Learning Robust and Lightweight Model through Separable Structured Transformations
Dec 29, 2021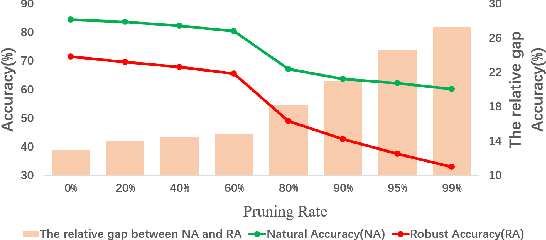

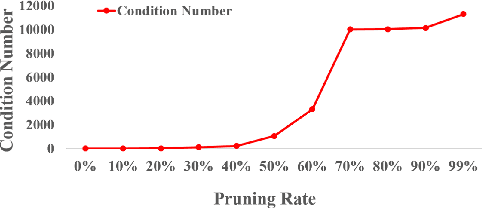
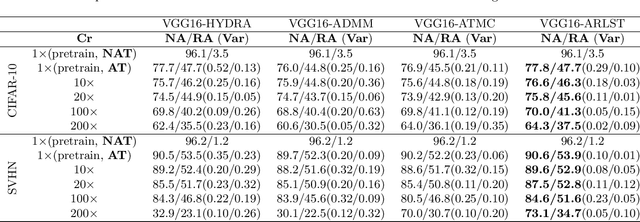
With the proliferation of mobile devices and the Internet of Things, deep learning models are increasingly deployed on devices with limited computing resources and memory, and are exposed to the threat of adversarial noise. Learning deep models with both lightweight and robustness is necessary for these equipments. However, current deep learning solutions are difficult to learn a model that possesses these two properties without degrading one or the other. As is well known, the fully-connected layers contribute most of the parameters of convolutional neural networks. We perform a separable structural transformation of the fully-connected layer to reduce the parameters, where the large-scale weight matrix of the fully-connected layer is decoupled by the tensor product of several separable small-sized matrices. Note that data, such as images, no longer need to be flattened before being fed to the fully-connected layer, retaining the valuable spatial geometric information of the data. Moreover, in order to further enhance both lightweight and robustness, we propose a joint constraint of sparsity and differentiable condition number, which is imposed on these separable matrices. We evaluate the proposed approach on MLP, VGG-16 and Vision Transformer. The experimental results on datasets such as ImageNet, SVHN, CIFAR-100 and CIFAR10 show that we successfully reduce the amount of network parameters by 90%, while the robust accuracy loss is less than 1.5%, which is better than the SOTA methods based on the original fully-connected layer. Interestingly, it can achieve an overwhelming advantage even at a high compression rate, e.g., 200 times.
Spatiotemporal Inconsistency Learning for DeepFake Video Detection
Sep 07, 2021
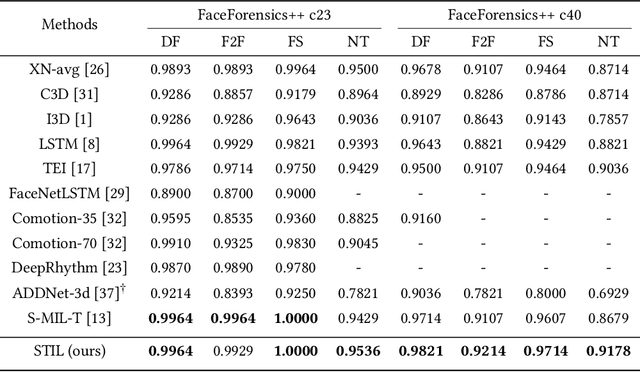
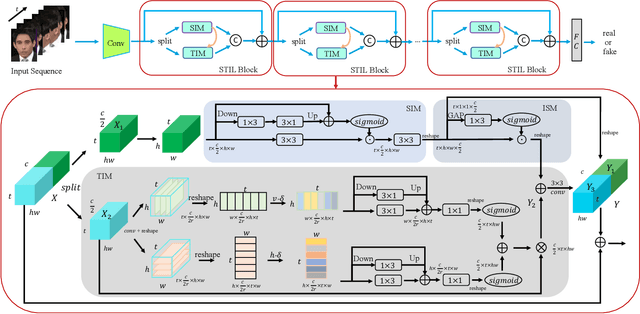
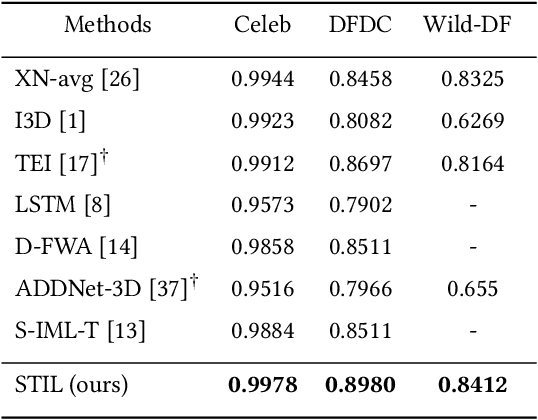
The rapid development of facial manipulation techniques has aroused public concerns in recent years. Following the success of deep learning, existing methods always formulate DeepFake video detection as a binary classification problem and develop frame-based and video-based solutions. However, little attention has been paid to capturing the spatial-temporal inconsistency in forged videos. To address this issue, we term this task as a Spatial-Temporal Inconsistency Learning (STIL) process and instantiate it into a novel STIL block, which consists of a Spatial Inconsistency Module (SIM), a Temporal Inconsistency Module (TIM), and an Information Supplement Module (ISM). Specifically, we present a novel temporal modeling paradigm in TIM by exploiting the temporal difference over adjacent frames along with both horizontal and vertical directions. And the ISM simultaneously utilizes the spatial information from SIM and temporal information from TIM to establish a more comprehensive spatial-temporal representation. Moreover, our STIL block is flexible and could be plugged into existing 2D CNNs. Extensive experiments and visualizations are presented to demonstrate the effectiveness of our method against the state-of-the-art competitors.
Representation Edit Distance as a Measure of Novelty
Nov 04, 2021
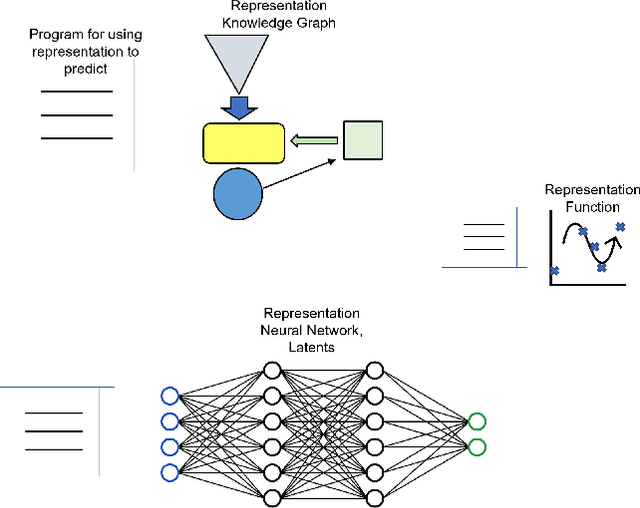
Adaptation to novelty is viewed as learning to change and augment existing skills to confront unfamiliar situations. In this paper, we propose that the amount of editing of an effective representation (the Representation Edit Distance or RED) used in a set of skill programs in an agent's mental model is a measure of difficulty for adaptation to novelty. The RED is an intuitive approximation to the change in information content in bit strings measured by comparing pre-novelty and post-novelty skill programs. We also present some notional examples of how to use RED for predicting difficulty.
Scheduling in Parallel Finite Buffer Systems: Optimal Decisions under Delayed Feedback
Sep 17, 2021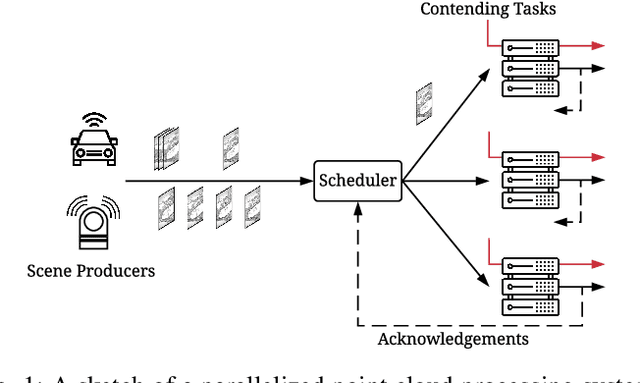
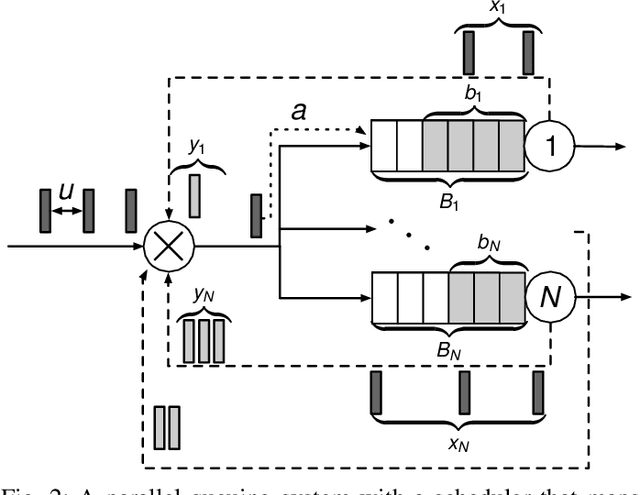
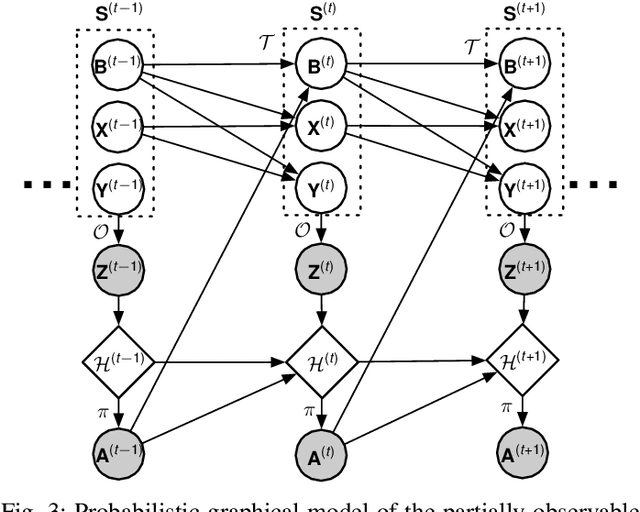

Scheduling decisions in parallel queuing systems arise as a fundamental problem, underlying the dimensioning and operation of many computing and communication systems, such as job routing in data center clusters, multipath communication, and Big Data systems. In essence, the scheduler maps each arriving job to one of the possibly heterogeneous servers while aiming at an optimization goal such as load balancing, low average delay or low loss rate. One main difficulty in finding optimal scheduling decisions here is that the scheduler only partially observes the impact of its decisions, e.g., through the delayed acknowledgements of the served jobs. In this paper, we provide a partially observable (PO) model that captures the scheduling decisions in parallel queuing systems under limited information of delayed acknowledgements. We present a simulation model for this PO system to find a near-optimal scheduling policy in real-time using a scalable Monte Carlo tree search algorithm. We numerically show that the resulting policy outperforms other limited information scheduling strategies such as variants of Join-the-Most-Observations and has comparable performance to full information strategies like: Join-the-Shortest-Queue, Join-the- Shortest-Queue(d) and Shortest-Expected-Delay. Finally, we show how our approach can optimise the real-time parallel processing by using network data provided by Kaggle.
Learning Structured Latent Factors from Dependent Data:A Generative Model Framework from Information-Theoretic Perspective
Jul 21, 2020
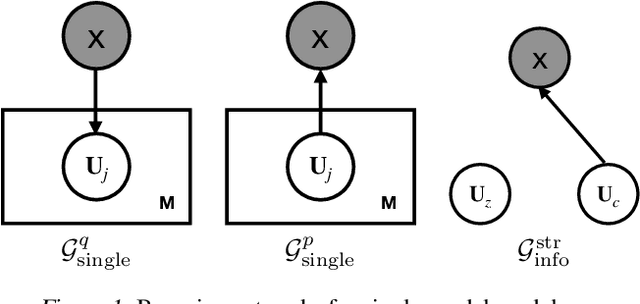
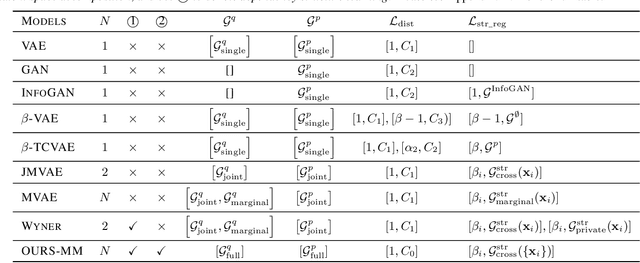
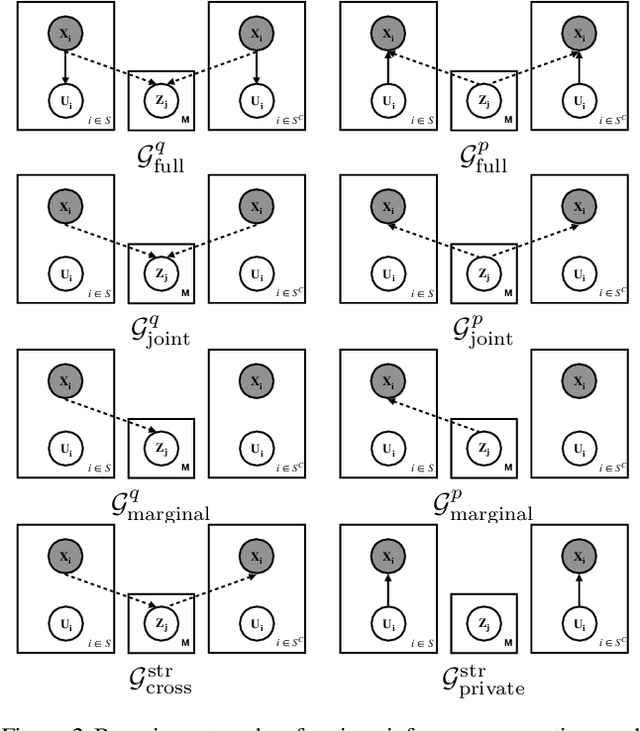
Learning controllable and generalizable representation of multivariate data with desired structural properties remains a fundamental problem in machine learning. In this paper, we present a novel framework for learning generative models with various underlying structures in the latent space. We represent the inductive bias in the form of mask variables to model the dependency structure in the graphical model and extend the theory of multivariate information bottleneck to enforce it. Our model provides a principled approach to learn a set of semantically meaningful latent factors that reflect various types of desired structures like capturing correlation or encoding invariance, while also offering the flexibility to automatically estimate the dependency structure from data. We show that our framework unifies many existing generative models and can be applied to a variety of tasks including multi-modal data modeling, algorithmic fairness, and invariant risk minimization.