 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Inconsistency Learning for DeepFake Video Detection
Paper and Code
Sep 07, 2021
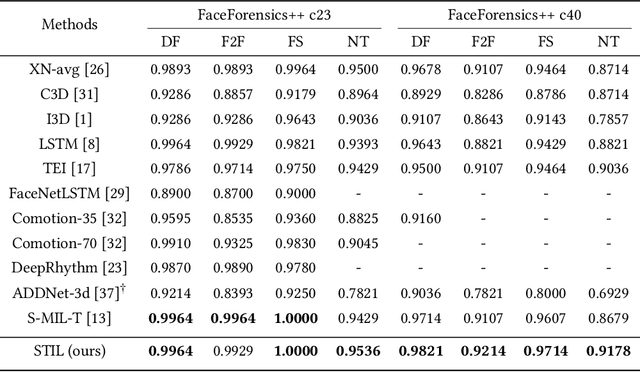
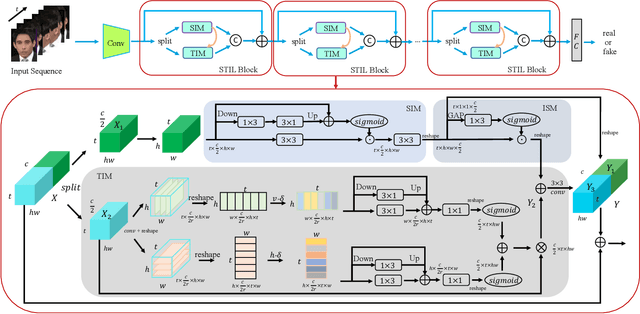
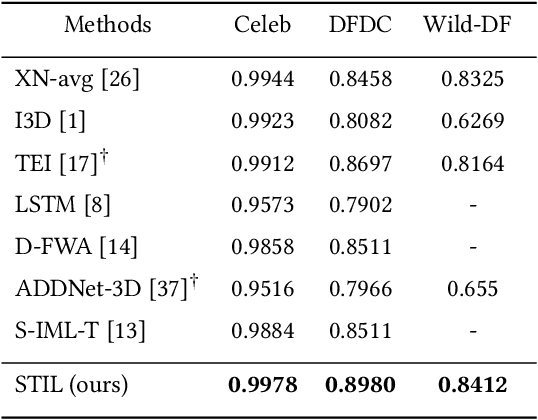
The rapid development of facial manipulation techniques has aroused public concerns in recent years. Following the success of deep learning, existing methods always formulate DeepFake video detection as a binary classification problem and develop frame-based and video-based solutions. However, little attention has been paid to capturing the spatial-temporal inconsistency in forged videos. To address this issue, we term this task as a Spatial-Temporal Inconsistency Learning (STIL) process and instantiate it into a novel STIL block, which consists of a Spatial Inconsistency Module (SIM), a Temporal Inconsistency Module (TIM), and an Information Supplement Module (ISM). Specifically, we present a novel temporal modeling paradigm in TIM by exploiting the temporal difference over adjacent frames along with both horizontal and vertical directions. And the ISM simultaneously utilizes the spatial information from SIM and temporal information from TIM to establish a more comprehensive spatial-temporal representation. Moreover, our STIL block is flexible and could be plugged into existing 2D CNNs. Extensive experiments and visualizations are presented to demonstrate the effectiveness of our method against the state-of-the-art competitors.