 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Rewards, Not Labels: Adversarial Inverse Reinforcement Learning for Machinery Fault Detection
Feb 25, 2026Reinforcement learning (RL) offers significant promise for machinery fault detection (MFD). However, most existing RL-based MFD approaches do not fully exploit RL's sequential decision-making strengths, often treating MFD as a simple guessing game (Contextual Bandits). To bridge this gap, we formulate MFD as an offline inverse reinforcement learning problem, where the agent learns the reward dynamics directly from healthy operational sequences, thereby bypassing the need for manual reward engineering and fault labels. Our framework employs Adversarial Inverse Reinforcement Learning to train a discriminator that distinguishes between normal (expert) and policy-generated transitions. The discriminator's learned reward serves as an anomaly score, indicating deviations from normal operating behaviour. When evaluated on three run-to-failure benchmark datasets (HUMS2023, IMS, and XJTU-SY), the model consistently assigns low anomaly scores to normal samples and high scores to faulty ones, enabling early and robust fault detection. By aligning RL's sequential reasoning with MFD's temporal structure, this work opens a path toward RL-based diagnostics in data-driven industrial settings.
Learning the Value Systems of Societies with Preference-based Multi-objective Reinforcement Learning
Feb 09, 2026Value-aware AI should recognise human values and adapt to the value systems (value-based preferences) of different users. This requires operationalization of values, which can be prone to misspecification. The social nature of values demands their representation to adhere to multiple users while value systems are diverse, yet exhibit patterns among groups. In sequential decision making, efforts have been made towards personalization for different goals or values from demonstrations of diverse agents. However, these approaches demand manually designed features or lack value-based interpretability and/or adaptability to diverse user preferences. We propose algorithms for learning models of value alignment and value systems for a society of agents in Markov Decision Processes (MDPs), based on clustering and preference-based multi-objective reinforcement learning (PbMORL). We jointly learn socially-derived value alignment models (groundings) and a set of value systems that concisely represent different groups of users (clusters) in a society. Each cluster consists of a value system representing the value-based preferences of its members and an approximately Pareto-optimal policy that reflects behaviours aligned with this value system. We evaluate our method against a state-of-the-art PbMORL algorithm and baselines on two MDPs with human values.
Optimizing Robotic Placement via Grasp-Dependent Feasibility Prediction
Dec 21, 2025



In this paper, we study whether inexpensive, physics-free supervision can reliably prioritize grasp-place candidates for budget-aware pick-and-place. From an object's initial pose, target pose, and a candidate grasp, we generate two path-aware geometric labels: path-wise inverse kinematics (IK) feasibility across a fixed approach-grasp-lift waypoint template, and a transit collision flag from mesh sweeps along the same template. A compact dual-output MLP learns these signals from pose encodings, and at test time its scores rank precomputed candidates for a rank-then-plan policy under the same IK gate and planner as the baseline. Although learned from cheap labels only, the scores transfer to physics-enabled executed trajectories: at a fixed planning budget the policy finds successful paths sooner with fewer planner calls while keeping final success on par or better. This work targets a single rigid cuboid with side-face grasps and a fixed waypoint template, and we outline extensions to varied objects and richer waypoint schemes.
Multi-Scale Attention and Gated Shifting for Fine-Grained Event Spotting in Videos
Jul 10, 2025
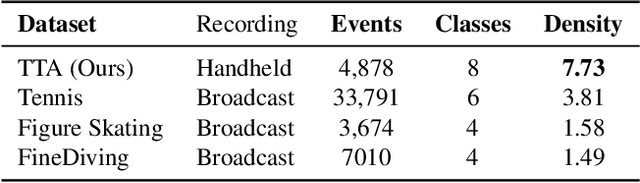
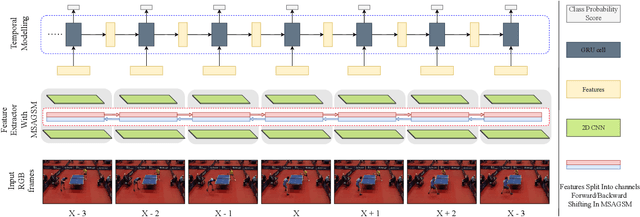
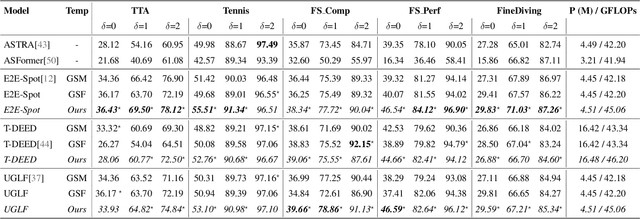
Precise Event Spotting (PES) in sports videos requires frame-level recognition of fine-grained actions from single-camera footage. Existing PES models typically incorporate lightweight temporal modules such as Gate Shift Module (GSM) or Gate Shift Fuse (GSF) to enrich 2D CNN feature extractors with temporal context. However, these modules are limited in both temporal receptive field and spatial adaptability. We propose a Multi-Scale Attention Gate Shift Module (MSAGSM) that enhances GSM with multi-scale temporal dilations and multi-head spatial attention, enabling efficient modeling of both short- and long-term dependencies while focusing on salient regions. MSAGSM is a lightweight plug-and-play module that can be easily integrated with various 2D backbones. To further advance the field, we introduce the Table Tennis Australia (TTA) dataset-the first PES benchmark for table tennis-containing over 4800 precisely annotated events. Extensive experiments across five PES benchmarks demonstrate that MSAGSM consistently improves performance with minimal overhead, setting new state-of-the-art results.
Ensemble Elastic DQN: A novel multi-step ensemble approach to address overestimation in deep value-based reinforcement learning
Jun 06, 2025While many algorithmic extensions to Deep Q-Networks (DQN) have been proposed, there remains limited understanding of how different improvements interact. In particular, multi-step and ensemble style extensions have shown promise in reducing overestimation bias, thereby improving sample efficiency and algorithmic stability. In this paper, we introduce a novel algorithm called Ensemble Elastic Step DQN (EEDQN), which unifies ensembles with elastic step updates to stabilise algorithmic performance. EEDQN is designed to address two major challenges in deep reinforcement learning: overestimation bias and sample efficiency. We evaluated EEDQN against standard and ensemble DQN variants across the MinAtar benchmark, a set of environments that emphasise behavioral learning while reducing representational complexity. Our results show that EEDQN achieves consistently robust performance across all tested environments, outperforming baseline DQN methods and matching or exceeding state-of-the-art ensemble DQNs in final returns on most of the MinAtar environments. These findings highlight the potential of systematically combining algorithmic improvements and provide evidence that ensemble and multi-step methods, when carefully integrated, can yield substantial gains.
Action Spotting and Precise Event Detection in Sports: Datasets, Methods, and Challenges
May 06, 2025Video event detection has become an essential component of sports analytics, enabling automated identification of key moments and enhancing performance analysis, viewer engagement, and broadcast efficiency. Recent advancements in deep learning, particularly Convolutional Neural Networks (CNNs) and Transformers, have significantly improved accuracy and efficiency in Temporal Action Localization (TAL), Action Spotting (AS), and Precise Event Spotting (PES). This survey provides a comprehensive overview of these three key tasks, emphasizing their differences, applications, and the evolution of methodological approaches. We thoroughly review and categorize existing datasets and evaluation metrics specifically tailored for sports contexts, highlighting the strengths and limitations of each. Furthermore, we analyze state-of-the-art techniques, including multi-modal approaches that integrate audio and visual information, methods utilizing self-supervised learning and knowledge distillation, and approaches aimed at generalizing across multiple sports. Finally, we discuss critical open challenges and outline promising research directions toward developing more generalized, efficient, and robust event detection frameworks applicable to diverse sports. This survey serves as a foundation for future research on efficient, generalizable, and multi-modal sports event detection.
DAPoinTr: Domain Adaptive Point Transformer for Point Cloud Completion
Dec 26, 2024



Point Transformers (PoinTr) have shown great potential in point cloud completion recently. Nevertheless, effective domain adaptation that improves transferability toward target domains remains unexplored. In this paper, we delve into this topic and empirically discover that direct feature alignment on point Transformer's CNN backbone only brings limited improvements since it cannot guarantee sequence-wise domain-invariant features in the Transformer. To this end, we propose a pioneering Domain Adaptive Point Transformer (DAPoinTr) framework for point cloud completion. DAPoinTr consists of three key components: Domain Query-based Feature Alignment (DQFA), Point Token-wise Feature alignment (PTFA), and Voted Prediction Consistency (VPC). In particular, DQFA is presented to narrow the global domain gaps from the sequence via the presented domain proxy and domain query at the Transformer encoder and decoder, respectively. PTFA is proposed to close the local domain shifts by aligning the tokens, \emph{i.e.,} point proxy and dynamic query, at the Transformer encoder and decoder, respectively. VPC is designed to consider different Transformer decoders as multiple of experts (MoE) for ensembled prediction voting and pseudo-label generation. Extensive experiments with visualization on several domain adaptation benchmarks demonstrate the effectiveness and superiority of our DAPoinTr compared with state-of-the-art methods. Code will be publicly available at: https://github.com/Yinghui-Li-New/DAPoinTr
Adaptive Alignment: Dynamic Preference Adjustments via Multi-Objective Reinforcement Learning for Pluralistic AI
Oct 31, 2024
Emerging research in Pluralistic Artificial Intelligence (AI) alignment seeks to address how intelligent systems can be designed and deployed in accordance with diverse human needs and values. We contribute to this pursuit with a dynamic approach for aligning AI with diverse and shifting user preferences through Multi Objective Reinforcement Learning (MORL), via post-learning policy selection adjustment. In this paper, we introduce the proposed framework for this approach, outline its anticipated advantages and assumptions, and discuss technical details about the implementation. We also examine the broader implications of adopting a retroactive alignment approach through the sociotechnical systems perspective.
Multi-objective Reinforcement Learning: A Tool for Pluralistic Alignment
Oct 15, 2024Reinforcement learning (RL) is a valuable tool for the creation of AI systems. However it may be problematic to adequately align RL based on scalar rewards if there are multiple conflicting values or stakeholders to be considered. Over the last decade multi-objective reinforcement learning (MORL) using vector rewards has emerged as an alternative to standard, scalar RL. This paper provides an overview of the role which MORL can play in creating pluralistically-aligned AI.
IReCa: Intrinsic Reward-enhanced Context-aware Reinforcement Learning for Human-AI Coordination
Aug 15, 2024



In human-AI coordination scenarios, human agents usually exhibit asymmetric behaviors that are significantly sparse and unpredictable compared to those of AI agents. These characteristics introduce two primary challenges to human-AI coordination: the effectiveness of obtaining sparse rewards and the efficiency of training the AI agents. To tackle these challenges, we propose an Intrinsic Reward-enhanced Context-aware (IReCa) reinforcement learning (RL) algorithm, which leverages intrinsic rewards to facilitate the acquisition of sparse rewards and utilizes environmental context to enhance training efficiency. Our IReCa RL algorithm introduces three unique features: (i) it encourages the exploration of sparse rewards by incorporating intrinsic rewards that supplement traditional extrinsic rewards from the environment; (ii) it improves the acquisition of sparse rewards by prioritizing the corresponding sparse state-action pairs; and (iii) it enhances the training efficiency by optimizing the exploration and exploitation through innovative context-aware weights of extrinsic and intrinsic rewards. Extensive simulations executed in the Overcooked layouts demonstrate that our IReCa RL algorithm can increase the accumulated rewards by approximately 20% and reduce the epochs required for convergence by approximately 67% compared to state-of-the-art baselines.