 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Attributed Network Embedding for Incomplete Structure Information
Nov 28, 2018

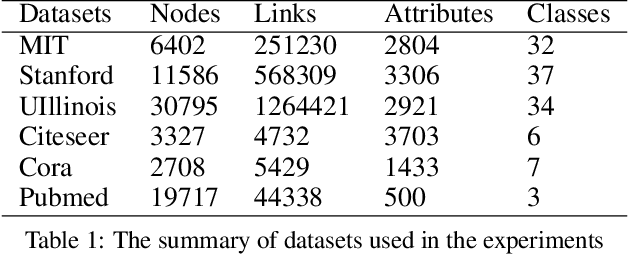
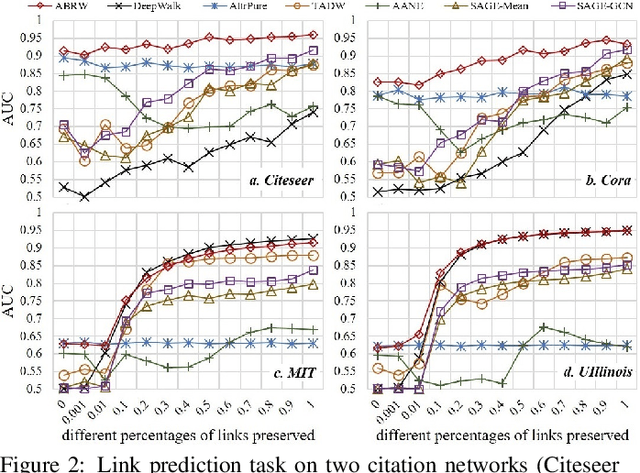
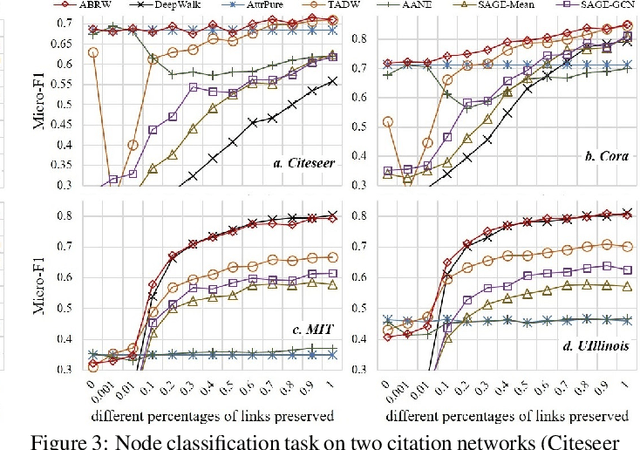
An attributed network enriches a pure network by encoding a part of widely accessible node auxiliary information into node attributes. Learning vector representation of each node a.k.a. Network Embedding (NE) for such an attributed network by considering both structure and attribute information has recently attracted considerable attention, since each node embedding is simply a unified low-dimension vector representation that makes downstream tasks e.g. link prediction more efficient and much easier to realize. Most of previous works have not considered the significant case of a network with incomplete structure information, which however, would often appear in our real-world scenarios e.g. the abnormal users in a social network who intentionally hide their friendships. And different networks obviously have different levels of incomplete structure information, which imposes more challenges to balance two sources of information. To tackle that, we propose a robust NE method called Attributed Biased Random Walks (ABRW) to employ attribute information for compensating incomplete structure information by using transition matrices. The experiments of link prediction and node classification tasks on real-world datasets confirm the robustness and effectiveness of our method to the different levels of the incomplete structure information.
Utilizing Wordnets for Cognate Detection among Indian Languages
Dec 30, 2021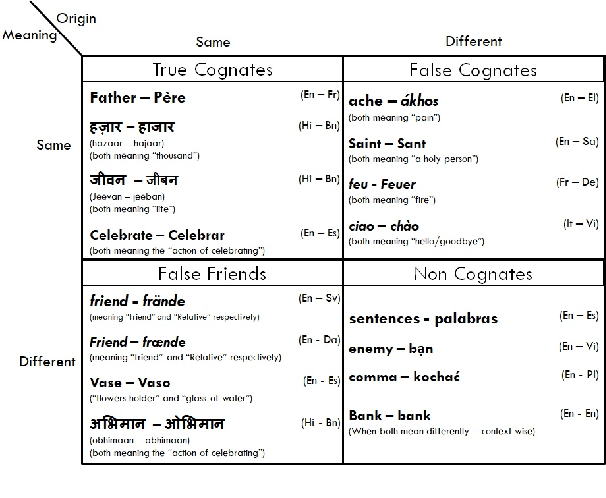
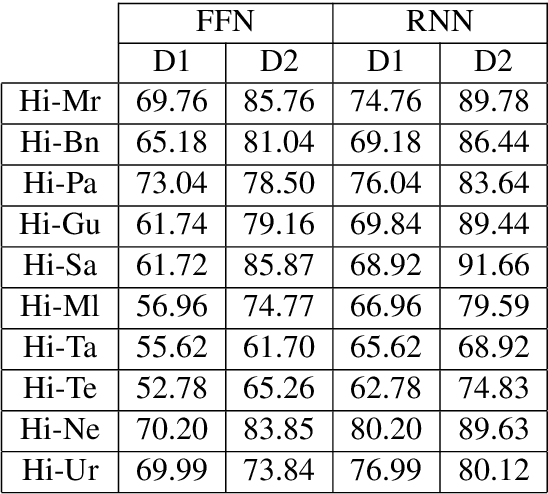
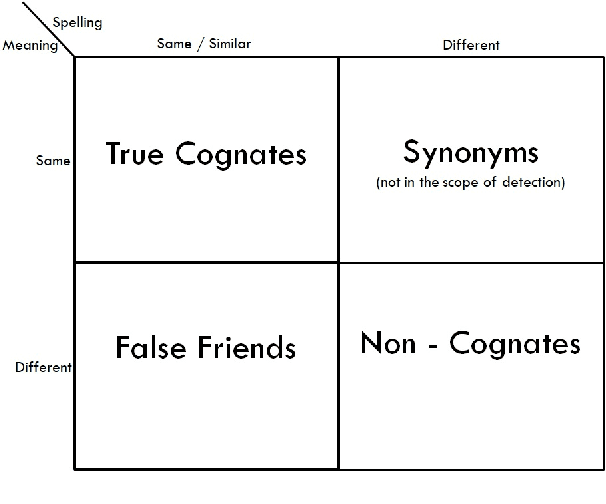
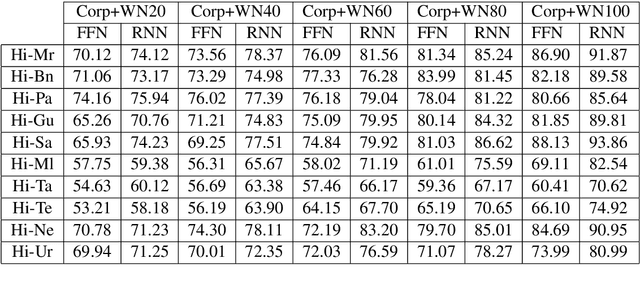
Automatic Cognate Detection (ACD) is a challenging task which has been utilized to help NLP applications like Machine Translation, Information Retrieval and Computational Phylogenetics. Unidentified cognate pairs can pose a challenge to these applications and result in a degradation of performance. In this paper, we detect cognate word pairs among ten Indian languages with Hindi and use deep learning methodologies to predict whether a word pair is cognate or not. We identify IndoWordnet as a potential resource to detect cognate word pairs based on orthographic similarity-based methods and train neural network models using the data obtained from it. We identify parallel corpora as another potential resource and perform the same experiments for them. We also validate the contribution of Wordnets through further experimentation and report improved performance of up to 26%. We discuss the nuances of cognate detection among closely related Indian languages and release the lists of detected cognates as a dataset. We also observe the behaviour of, to an extent, unrelated Indian language pairs and release the lists of detected cognates among them as well.
Motif-based Graph Self-Supervised Learning forMolecular Property Prediction
Oct 03, 2021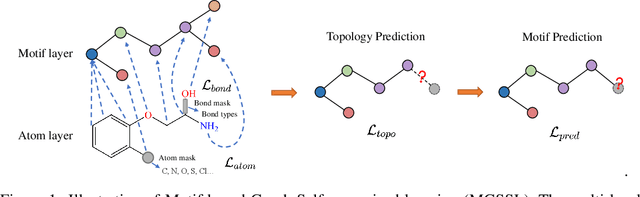
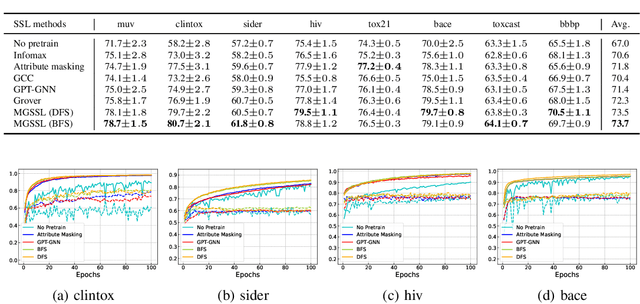
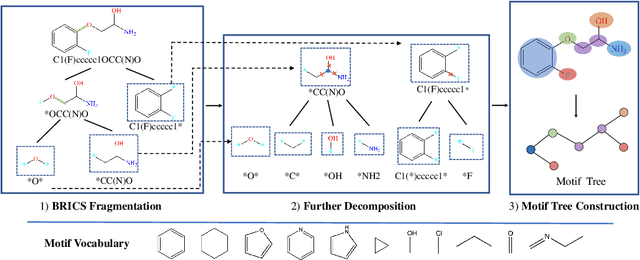
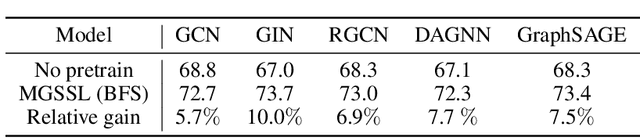
Predicting molecular properties with data-driven methods has drawn much attention in recent years. Particularly, Graph Neural Networks (GNNs) have demonstrated remarkable success in various molecular generation and prediction tasks. In cases where labeled data is scarce, GNNs can be pre-trained on unlabeled molecular data to first learn the general semantic and structural information before being fine-tuned for specific tasks. However, most existing self-supervised pre-training frameworks for GNNs only focus on node-level or graph-level tasks. These approaches cannot capture the rich information in subgraphs or graph motifs. For example, functional groups (frequently-occurred subgraphs in molecular graphs) often carry indicative information about the molecular properties. To bridge this gap, we propose Motif-based Graph Self-supervised Learning (MGSSL) by introducing a novel self-supervised motif generation framework for GNNs. First, for motif extraction from molecular graphs, we design a molecule fragmentation method that leverages a retrosynthesis-based algorithm BRICS and additional rules for controlling the size of motif vocabulary. Second, we design a general motif-based generative pre-training framework in which GNNs are asked to make topological and label predictions. This generative framework can be implemented in two different ways, i.e., breadth-first or depth-first. Finally, to take the multi-scale information in molecular graphs into consideration, we introduce a multi-level self-supervised pre-training. Extensive experiments on various downstream benchmark tasks show that our methods outperform all state-of-the-art baselines.
Kleister: A novel task for Information Extraction involving Long Documents with Complex Layout
Mar 06, 2020
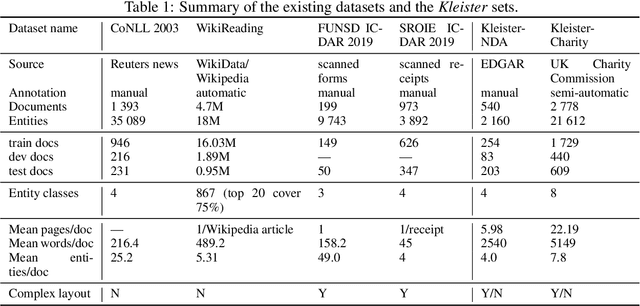

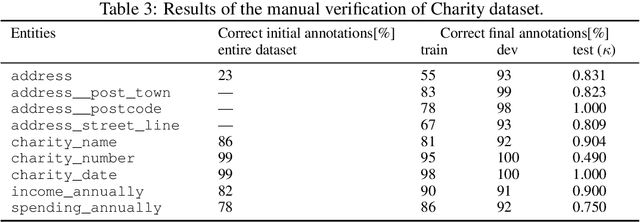
State-of-the-art solutions for Natural Language Processing (NLP) are able to capture a broad range of contexts, like the sentence-level context or document-level context for short documents. But these solutions are still struggling when it comes to longer, real-world documents with the information encoded in the spatial structure of the document, such as page elements like tables, forms, headers, openings or footers; complex page layout or presence of multiple pages. To encourage progress on deeper and more complex Information Extraction (IE) we introduce a new task (named Kleister) with two new datasets. Utilizing both textual and structural layout features, an NLP system must find the most important information, about various types of entities, in long formal documents. We propose Pipeline method as a text-only baseline with different Named Entity Recognition architectures (Flair, BERT, RoBERTa). Moreover, we checked the most popular PDF processing tools for text extraction (pdf2djvu, Tesseract and Textract) in order to analyze behavior of IE system in presence of errors introduced by these tools.
Improving Channel Charting using a Split Triplet Loss and an Inertial Regularizer
Oct 21, 2021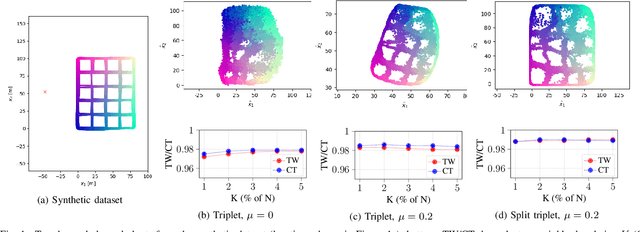
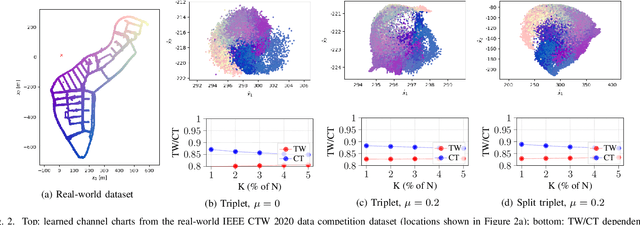
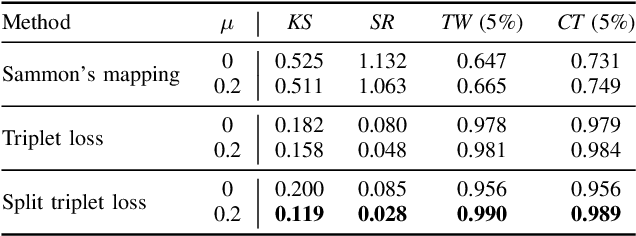
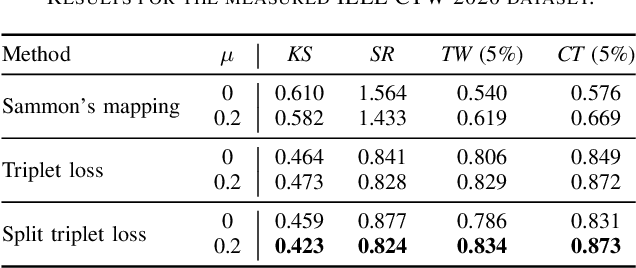
Channel charting is an emerging technology that enables self-supervised pseudo-localization of user equipments by performing dimensionality reduction on large channel-state information (CSI) databases that are passively collected at infrastructure base stations or access points. In this paper, we introduce a new dimensionality reduction method specifically designed for channel charting using a novel split triplet loss, which utilizes physical information available during the CSI acquisition process. In addition, we propose a novel regularizer that exploits the physical concept of inertia, which significantly improves the quality of the learned channel charts. We provide an experimental verification of our methods using synthetic and real-world measured CSI datasets, and we demonstrate that our methods are able to outperform the state-of-the-art in channel charting based on the triplet loss.
* 6 pages, 2 figures
Functional Anomaly Detection: a Benchmark Study
Jan 13, 2022
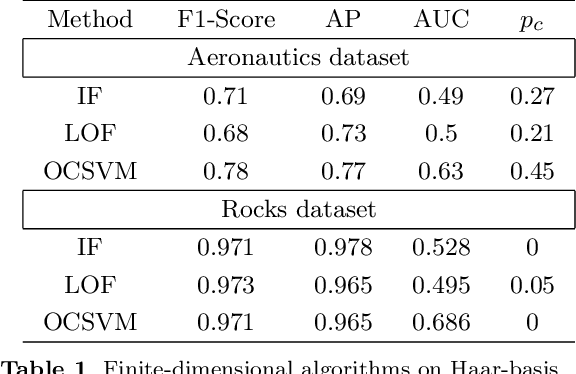
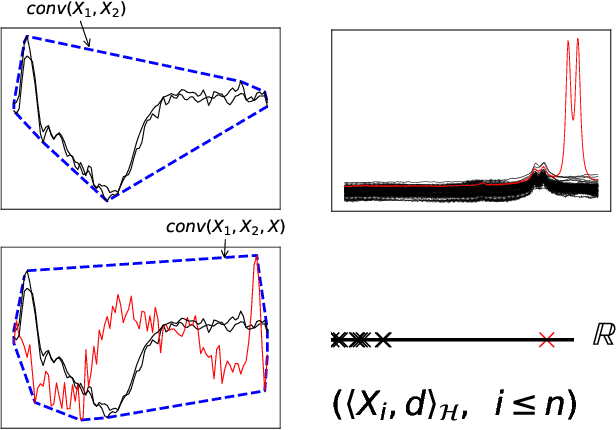
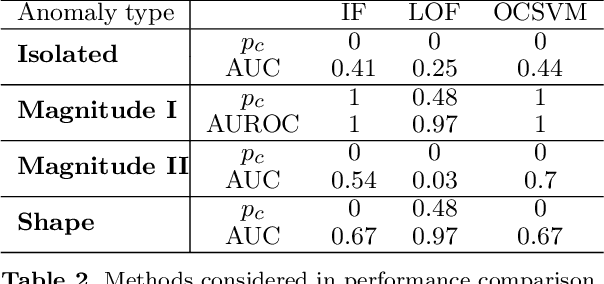
The increasing automation in many areas of the Industry expressly demands to design efficient machine-learning solutions for the detection of abnormal events. With the ubiquitous deployment of sensors monitoring nearly continuously the health of complex infrastructures, anomaly detection can now rely on measurements sampled at a very high frequency, providing a very rich representation of the phenomenon under surveillance. In order to exploit fully the information thus collected, the observations cannot be treated as multivariate data anymore and a functional analysis approach is required. It is the purpose of this paper to investigate the performance of recent techniques for anomaly detection in the functional setup on real datasets. After an overview of the state-of-the-art and a visual-descriptive study, a variety of anomaly detection methods are compared. While taxonomies of abnormalities (e.g. shape, location) in the functional setup are documented in the literature, assigning a specific type to the identified anomalies appears to be a challenging task. Thus, strengths and weaknesses of the existing approaches are benchmarked in view of these highlighted types in a simulation study. Anomaly detection methods are next evaluated on two datasets, related to the monitoring of helicopters in flight and to the spectrometry of construction materials namely. The benchmark analysis is concluded by recommendation guidance for practitioners.
Self- and Pseudo-self-supervised Prediction of Speaker and Key-utterance for Multi-party Dialogue Reading Comprehension
Sep 16, 2021
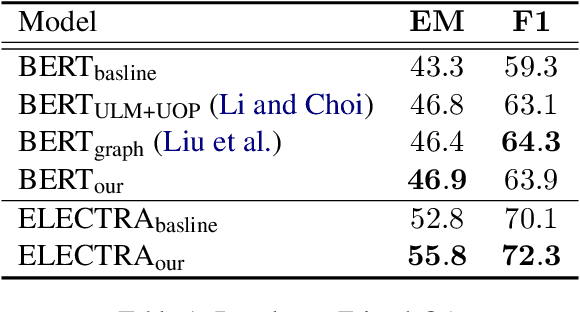
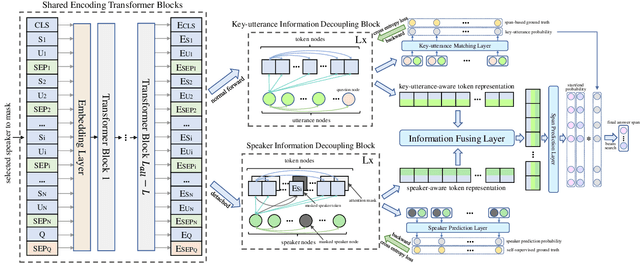
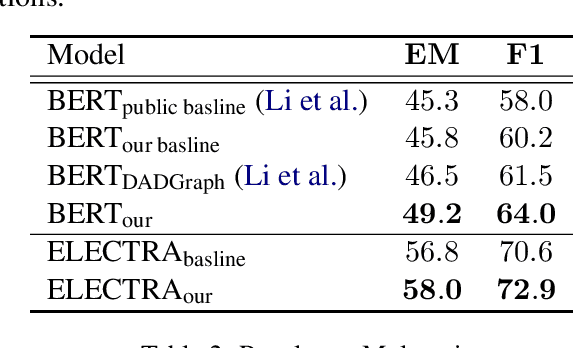
Multi-party dialogue machine reading comprehension (MRC) brings tremendous challenge since it involves multiple speakers at one dialogue, resulting in intricate speaker information flows and noisy dialogue contexts. To alleviate such difficulties, previous models focus on how to incorporate these information using complex graph-based modules and additional manually labeled data, which is usually rare in real scenarios. In this paper, we design two labour-free self- and pseudo-self-supervised prediction tasks on speaker and key-utterance to implicitly model the speaker information flows, and capture salient clues in a long dialogue. Experimental results on two benchmark datasets have justified the effectiveness of our method over competitive baselines and current state-of-the-art models.
Continually Learning Self-Supervised Representations with Projected Functional Regularization
Dec 30, 2021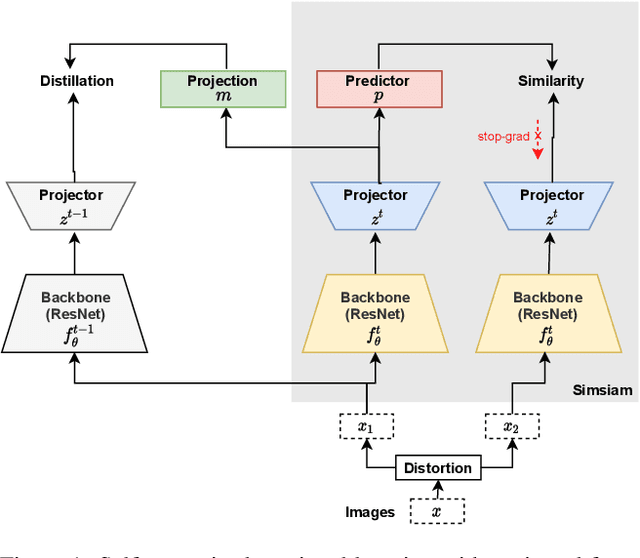
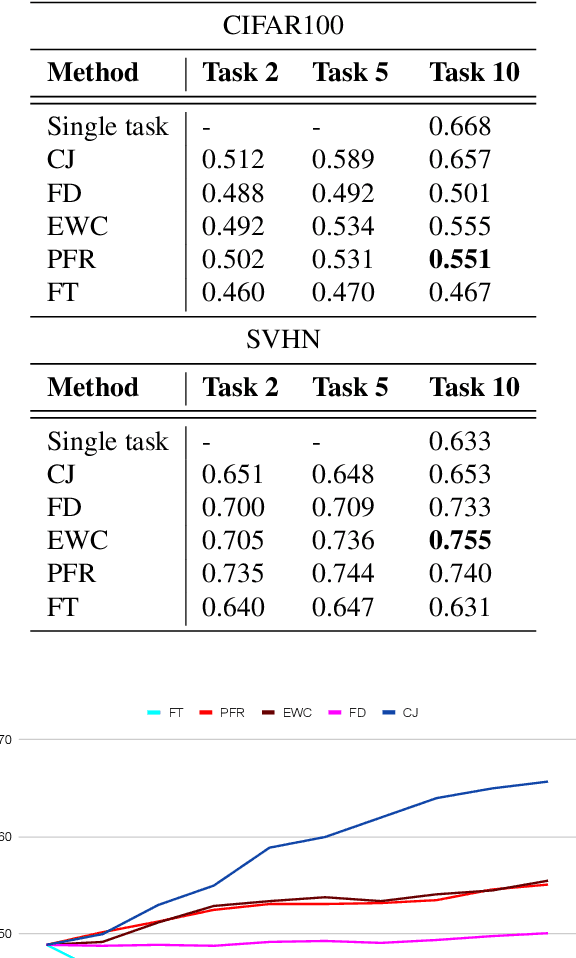
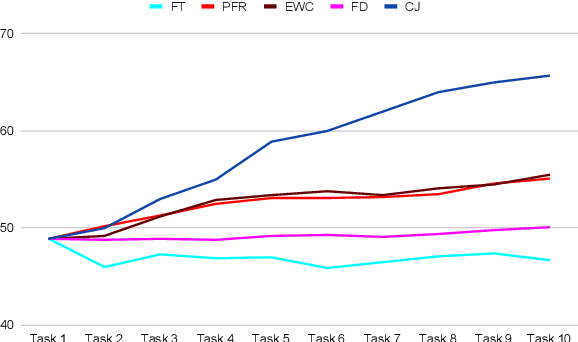
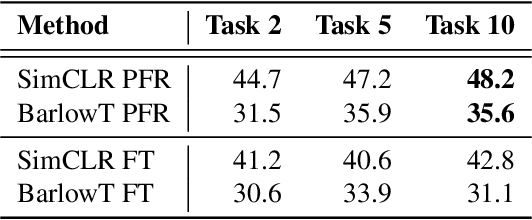
Recent self-supervised learning methods are able to learn high-quality image representations and are closing the gap with supervised methods. However, these methods are unable to acquire new knowledge incrementally -- they are, in fact, mostly used only as a pre-training phase with IID data. In this work we investigate self-supervised methods in continual learning regimes without additional memory or replay. To prevent forgetting of previous knowledge, we propose the usage of functional regularization. We will show that naive functional regularization, also known as feature distillation, leads to low plasticity and therefore seriously limits continual learning performance. To address this problem, we propose Projected Functional Regularization where a separate projection network ensures that the newly learned feature space preserves information of the previous feature space, while allowing for the learning of new features. This allows us to prevent forgetting while maintaining the plasticity of the learner. Evaluation against other incremental learning approaches applied to self-supervision demonstrates that our method obtains competitive performance in different scenarios and on multiple datasets.
BROS: A Layout-Aware Pre-trained Language Model for Understanding Documents
Aug 24, 2021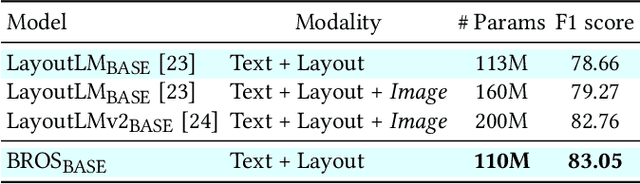
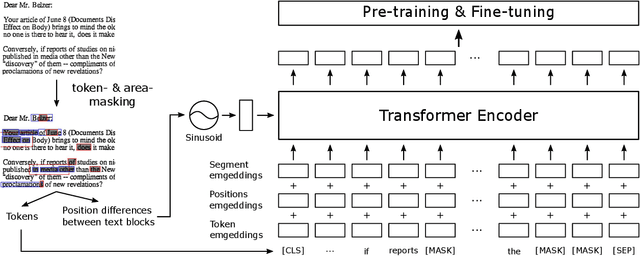

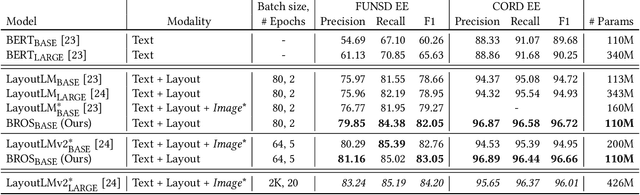
Understanding documents from their visual snapshots is an emerging problem that requires both advanced computer vision and NLP methods. The recent advance in OCR enables the accurate recognition of text blocks, yet it is still challenging to extract key information from documents due to the diversity of their layouts. Although recent studies on pre-trained language models show the importance of incorporating layout information on this task, the conjugation of texts and their layouts still follows the style of BERT optimized for understanding the 1D text. This implies there is room for further improvement considering the 2D nature of text layouts. This paper introduces a pre-trained language model, BERT Relying On Spatiality (BROS), which effectively utilizes the information included in individual text blocks and their layouts. Specifically, BROS encodes spatial information by utilizing relative positions and learns spatial dependencies between OCR blocks with a novel area-masking strategy. These two novel approaches lead to an efficient encoding of spatial layout information highlighted by the robust performance of BROS under low-resource environments. We also introduce a general-purpose parser that can be combined with BROS to extract key information even when there is no order information between text blocks. BROS shows its superiority on four public benchmarks -- FUNSD, SROIE*, CORD, and SciTSR -- and its robustness in practical cases where order information of text blocks is not available. Further experiments with a varying number of training examples demonstrate the high training efficiency of our approach. Our code will be open to the public.
Importance Estimation from Multiple Perspectives for Keyphrase Extraction
Nov 11, 2021
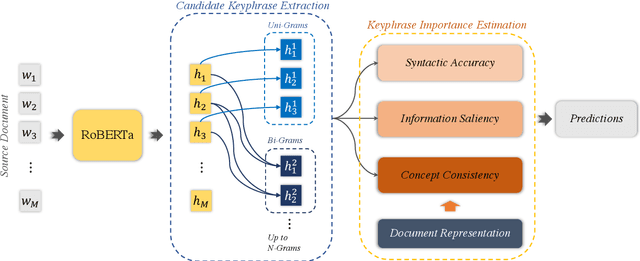

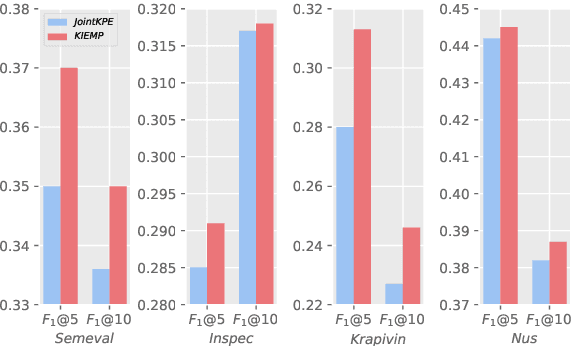
Keyphrase extraction is a fundamental task in Natural Language Processing, which usually contains two main parts: candidate keyphrase extraction and keyphrase importance estimation. From the view of human understanding documents, we typically measure the importance of phrase according to its syntactic accuracy, information saliency, and concept consistency simultaneously. However, most existing keyphrase extraction approaches only focus on the part of them, which leads to biased results. In this paper, we propose a new approach to estimate the importance of keyphrase from multiple perspectives (called as \textit{KIEMP}) and further improve the performance of keyphrase extraction. Specifically, \textit{KIEMP} estimates the importance of phrase with three modules: a chunking module to measure its syntactic accuracy, a ranking module to check its information saliency, and a matching module to judge the concept (i.e., topic) consistency between phrase and the whole document. These three modules are seamlessly jointed together via an end-to-end multi-task learning model, which is helpful for three parts to enhance each other and balance the effects of three perspectives. Experimental results on six benchmark datasets show that \textit{KIEMP} outperforms the existing state-of-the-art keyphrase extraction approaches in most cases.