 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Partially latent factors based multi-view subspace learning
Jan 06, 2022
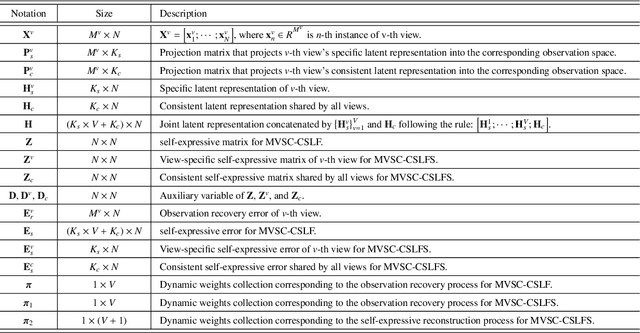
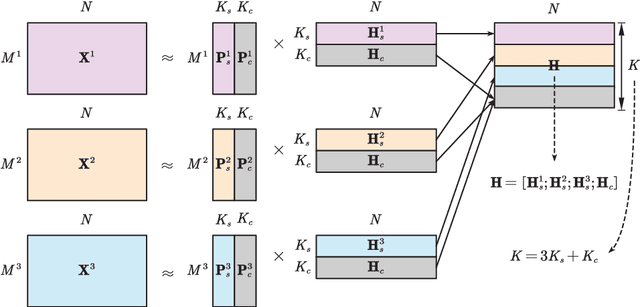
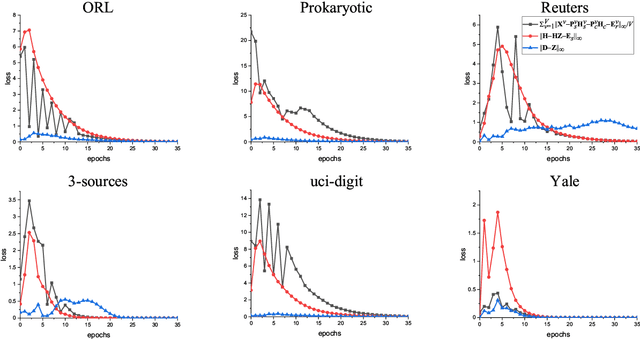

Multi-view subspace clustering always performs well in high-dimensional data analysis, but is sensitive to the quality of data representation. To this end, a two stage fusion strategy is proposed to embed representation learning into the process of multi-view subspace clustering. This paper first propose a novel matrix factorization method that can separate the coupling consistent and complementary information from observations of multiple views. Based on the obtained latent representations, we further propose two subspace clustering strategies: feature-level fusion and subspace-level hierarchical strategy. Feature-level method concatenates all kinds of latent representations from multiple views, and the original problem therefore degenerates to a single-view subspace clustering process. Subspace-level hierarchical method performs different self-expressive reconstruction processes on the corresponding complementary and consistent latent representations coming from each view, i.e. the prior constraints imposed on different types of subspace representations are related to the appropriate input factors. Finally, extensive experimental results on real-world datasets demonstrate the superiority of our proposed methods by comparing against some state-of-the-art subspace clustering algorithms.
Emotion-based Modeling of Mental Disorders on Social Media
Jan 24, 2022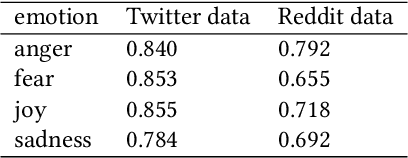
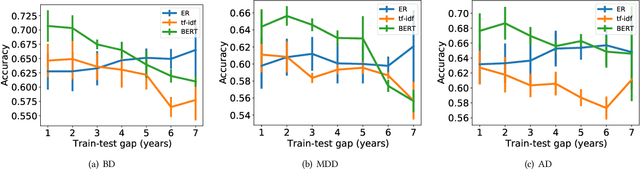

According to the World Health Organization (WHO), one in four people will be affected by mental disorders at some point in their lives. However, in many parts of the world, patients do not actively seek professional diagnosis because of stigma attached to mental illness, ignorance of mental health and its associated symptoms. In this paper, we propose a model for passively detecting mental disorders using conversations on Reddit. Specifically, we focus on a subset of mental disorders that are characterized by distinct emotional patterns (henceforth called emotional disorders): major depressive, anxiety, and bipolar disorders. Through passive (i.e., unprompted) detection, we can encourage patients to seek diagnosis and treatment for mental disorders. Our proposed model is different from other work in this area in that our model is based entirely on the emotional states, and the transition between these states of users on Reddit, whereas prior work is typically based on content-based representations (e.g., n-grams, language model embeddings, etc). We show that content-based representation is affected by domain and topic bias and thus does not generalize, while our model, on the other hand, suppresses topic-specific information and thus generalizes well across different topics and times. We conduct experiments on our model's ability to detect different emotional disorders and on the generalizability of our model. Our experiments show that while our model performs comparably to content-based models, such as BERT, it generalizes much better across time and topic.
Discovering Nonlinear Relations with Minimum Predictive Information Regularization
Jan 07, 2020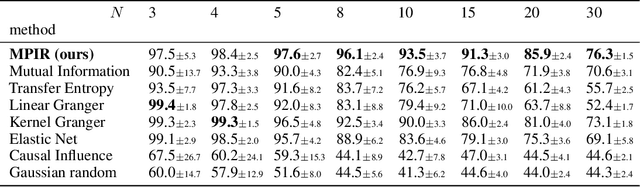
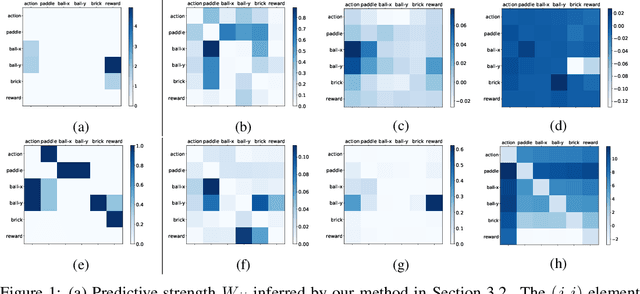
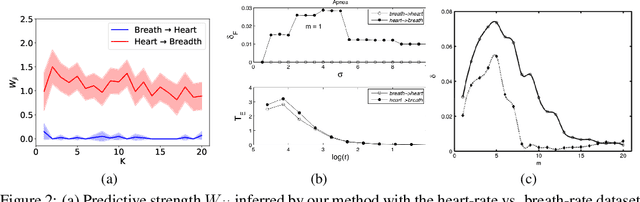
Identifying the underlying directional relations from observational time series with nonlinear interactions and complex relational structures is key to a wide range of applications, yet remains a hard problem. In this work, we introduce a novel minimum predictive information regularization method to infer directional relations from time series, allowing deep learning models to discover nonlinear relations. Our method substantially outperforms other methods for learning nonlinear relations in synthetic datasets, and discovers the directional relations in a video game environment and a heart-rate vs. breath-rate dataset.
Centralized and Distributed Power Allocation for Max-Min Fairness in Cell-Free Massive MIMO
Dec 31, 2021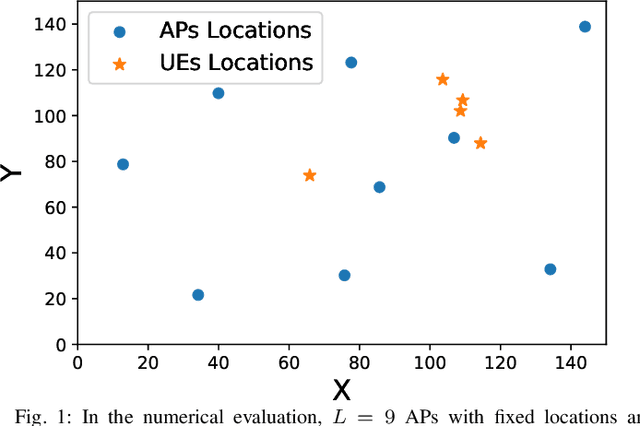
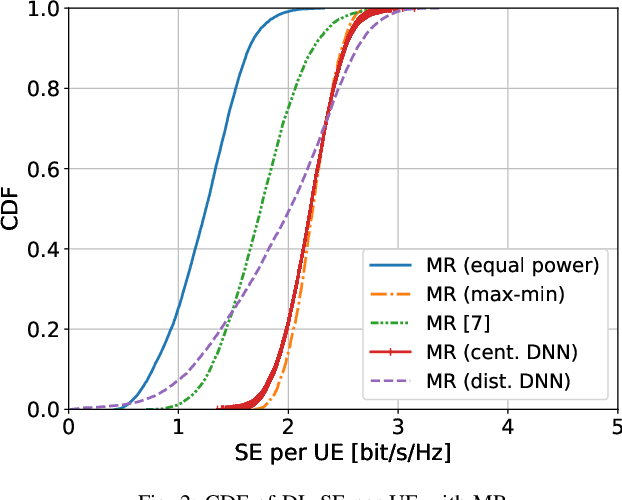
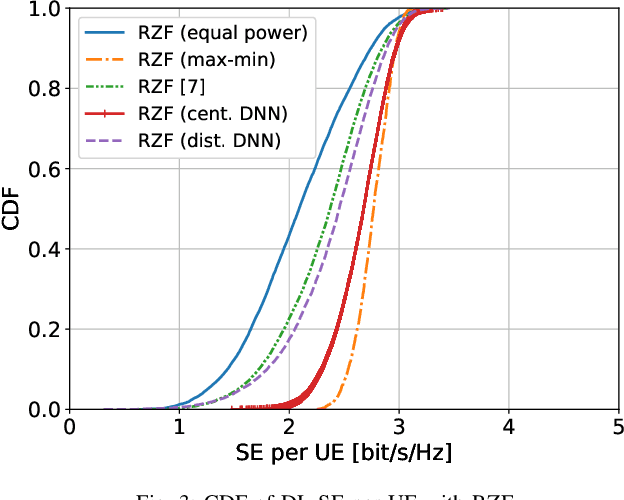

Cell-free Massive MIMO systems consist of a large number of geographically distributed access points (APs) that serve users by coherent joint transmission. Downlink power allocation is important in these systems, to determine which APs should transmit to which users and with what power. If the system is implemented correctly, it can deliver a more uniform user performance than conventional cellular networks. To this end, previous works have shown how to perform system-wide max-min fairness power allocation when using maximum ratio precoding. In this paper, we first generalize this method to arbitrary precoding, and then train a neural network to perform approximately the same power allocation but with reduced computational complexity. Finally, we train one neural network per AP to mimic system-wide max-min fairness power allocation, but using only local information. By learning the structure of the local propagation environment, this method outperforms the state-of-the-art distributed power allocation method from the Cell-free Massive MIMO literature.
Syntactic and Semantic-driven Learning for Open Information Extraction
Mar 05, 2021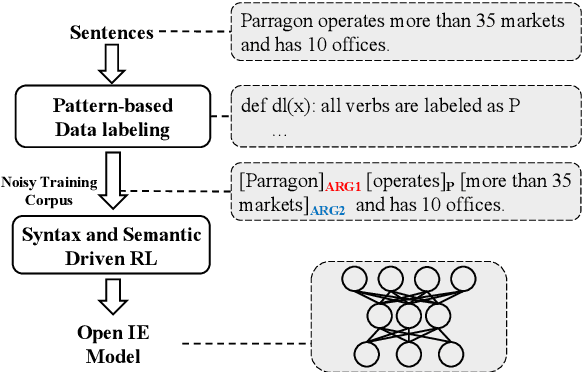
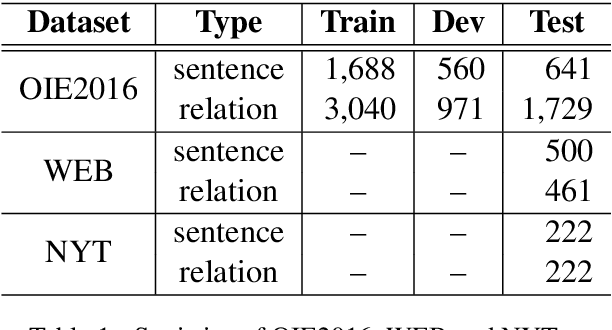

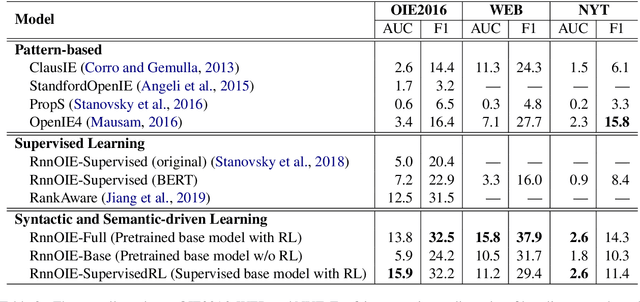
One of the biggest bottlenecks in building accurate, high coverage neural open IE systems is the need for large labelled corpora. The diversity of open domain corpora and the variety of natural language expressions further exacerbate this problem. In this paper, we propose a syntactic and semantic-driven learning approach, which can learn neural open IE models without any human-labelled data by leveraging syntactic and semantic knowledge as noisier, higher-level supervisions. Specifically, we first employ syntactic patterns as data labelling functions and pretrain a base model using the generated labels. Then we propose a syntactic and semantic-driven reinforcement learning algorithm, which can effectively generalize the base model to open situations with high accuracy. Experimental results show that our approach significantly outperforms the supervised counterparts, and can even achieve competitive performance to supervised state-of-the-art (SoA) model
* 11 pages
Reciprocal Adversarial Learning for Brain Tumor Segmentation: A Solution to BraTS Challenge 2021 Segmentation Task
Jan 11, 2022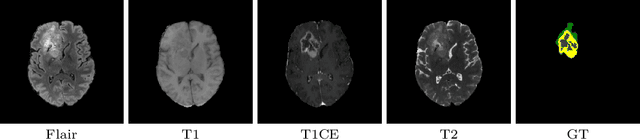
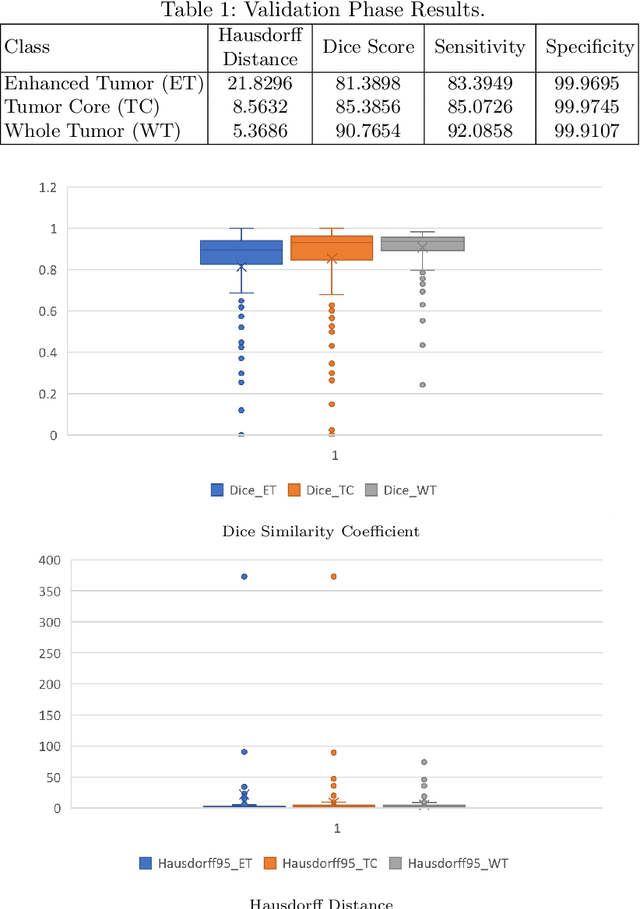
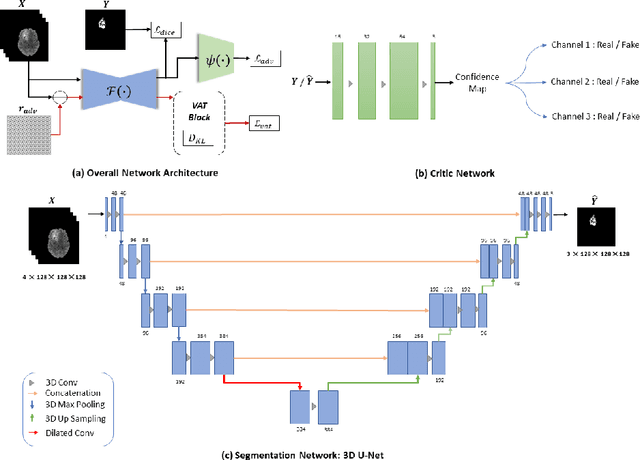
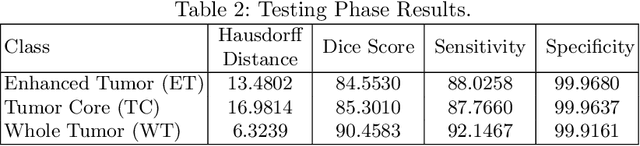
This paper proposes an adversarial learning based training approach for brain tumor segmentation task. In this concept, the 3D segmentation network learns from dual reciprocal adversarial learning approaches. To enhance the generalization across the segmentation predictions and to make the segmentation network robust, we adhere to the Virtual Adversarial Training approach by generating more adversarial examples via adding some noise on original patient data. By incorporating a critic that acts as a quantitative subjective referee, the segmentation network learns from the uncertainty information associated with segmentation results. We trained and evaluated network architecture on the RSNA-ASNR-MICCAI BraTS 2021 dataset. Our performance on the online validation dataset is as follows: Dice Similarity Score of 81.38%, 90.77% and 85.39%; Hausdorff Distance (95\%) of 21.83 mm, 5.37 mm, 8.56 mm for the enhancing tumor, whole tumor and tumor core, respectively. Similarly, our approach achieved a Dice Similarity Score of 84.55%, 90.46% and 85.30%, as well as Hausdorff Distance (95\%) of 13.48 mm, 6.32 mm and 16.98 mm on the final test dataset. Overall, our proposed approach yielded better performance in segmentation accuracy for each tumor sub-region. Our code implementation is publicly available at https://github.com/himashi92/vizviva_brats_2021
PiFeNet: Pillar-Feature Network for Real-Time 3D Pedestrian Detection from Point Cloud
Dec 31, 2021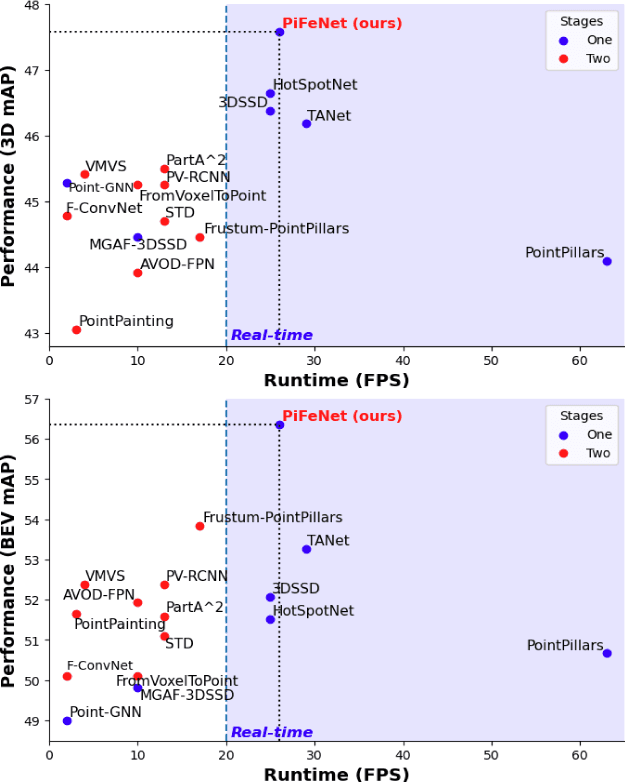
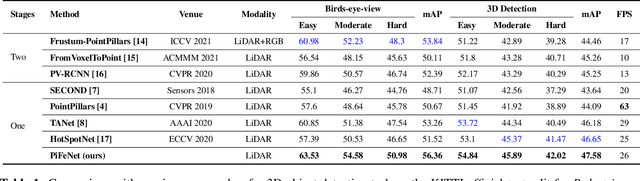
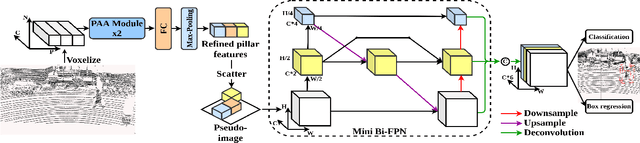

We present PiFeNet, an efficient and accurate real-time 3D detector for pedestrian detection from point clouds. We address two challenges that 3D object detection frameworks encounter when detecting pedestrians: low expressiveness of pillar features and small occupation areas of pedestrians in point clouds. Firstly, we introduce a stackable Pillar Aware Attention (PAA) module for enhanced pillar features extraction while suppressing noises in the point clouds. By integrating multi-point-aware-pooling, point-wise, channel-wise, and task-aware attention into a simple module, the representation capabilities are boosted while requiring little additional computing resources. We also present Mini-BiFPN, a small yet effective feature network that creates bidirectional information flow and multi-level cross-scale feature fusion to better integrate multi-resolution features. Our approach is ranked 1st in KITTI pedestrian BEV and 3D leaderboards while running at 26 frames per second (FPS), and achieves state-of-the-art performance on Nuscenes detection benchmark.
ProbNum: Probabilistic Numerics in Python
Dec 03, 2021


Probabilistic numerical methods (PNMs) solve numerical problems via probabilistic inference. They have been developed for linear algebra, optimization, integration and differential equation simulation. PNMs naturally incorporate prior information about a problem and quantify uncertainty due to finite computational resources as well as stochastic input. In this paper, we present ProbNum: a Python library providing state-of-the-art probabilistic numerical solvers. ProbNum enables custom composition of PNMs for specific problem classes via a modular design as well as wrappers for off-the-shelf use. Tutorials, documentation, developer guides and benchmarks are available online at www.probnum.org.
Stable and Compact Face Recognition via Unlabeled Data Driven Sparse Representation-Based Classification
Nov 04, 2021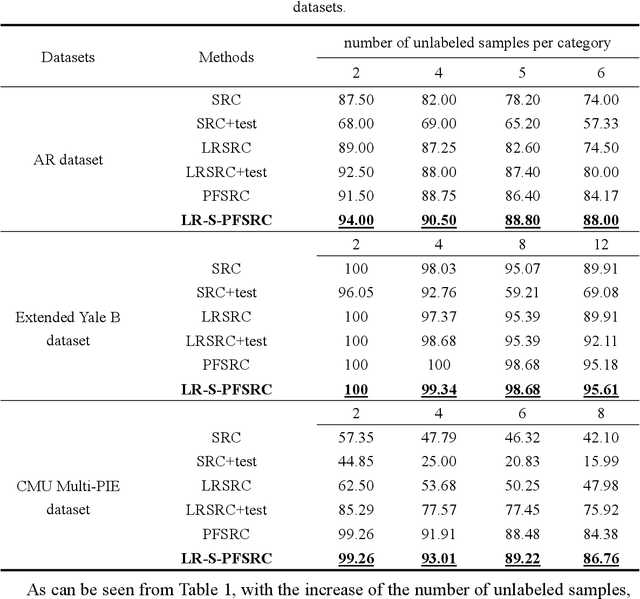
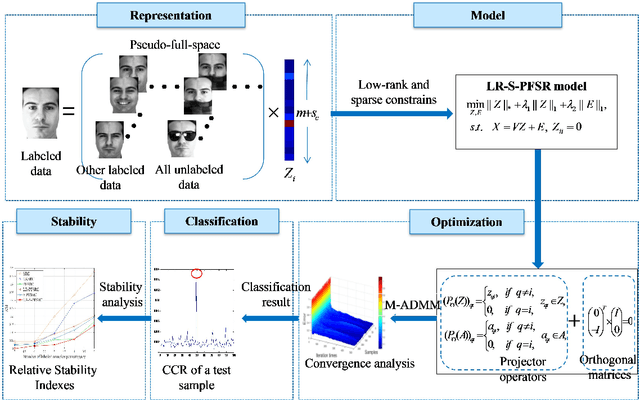
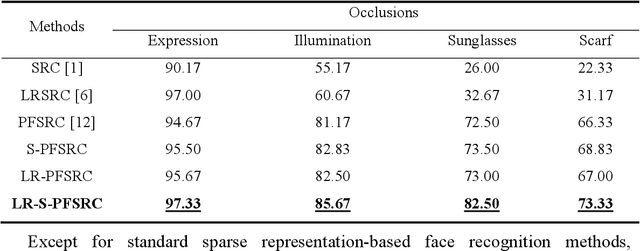

Sparse representation-based classification (SRC) has attracted much attention by casting the recognition problem as simple linear regression problem. SRC methods, however, still is limited to enough labeled samples per category, insufficient use of unlabeled samples, and instability of representation. For tackling these problems, an unlabeled data driven inverse projection pseudo-full-space representation-based classification model is proposed with low-rank sparse constraints. The proposed model aims to mine the hidden semantic information and intrinsic structure information of all available data, which is suitable for few labeled samples and proportion imbalance between labeled samples and unlabeled samples problems in frontal face recognition. The mixed Gauss-Seidel and Jacobian ADMM algorithm is introduced to solve the model. The convergence, representation capability and stability of the model are analyzed. Experiments on three public datasets show that the proposed LR-S-PFSRC model achieves stable results, especially for proportion imbalance of samples.
Reinforcing Semantic-Symmetry for Document Summarization
Dec 14, 2021
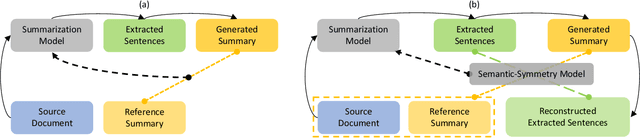
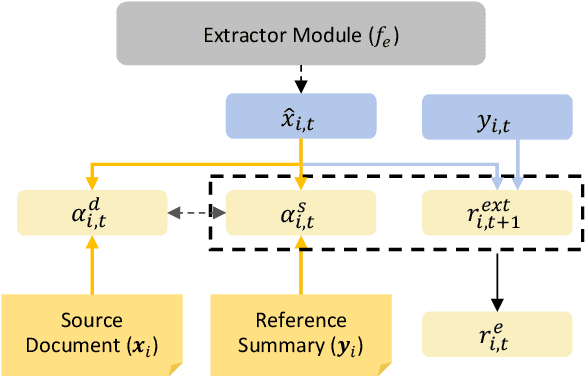
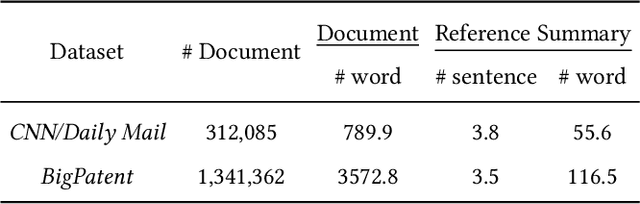
Document summarization condenses a long document into a short version with salient information and accurate semantic descriptions. The main issue is how to make the output summary semantically consistent with the input document. To reach this goal, recently, researchers have focused on supervised end-to-end hybrid approaches, which contain an extractor module and abstractor module. Among them, the extractor identifies the salient sentences from the input document, and the abstractor generates a summary from the salient sentences. This model successfully keeps the consistency between the generated summary and the reference summary via various strategies (e.g., reinforcement learning). There are two semantic gaps when training the hybrid model (one is between document and extracted sentences, and the other is between extracted sentences and summary). However, they are not explicitly considered in the existing methods, which usually results in a semantic bias of summary. To mitigate the above issue, in this paper, a new \textbf{r}einforcing s\textbf{e}mantic-\textbf{sy}mmetry learning \textbf{m}odel is proposed for document summarization (\textbf{ReSyM}). ReSyM introduces a semantic-consistency reward in the extractor to bridge the first gap. A semantic dual-reward is designed to bridge the second gap in the abstractor. The whole document summarization process is implemented via reinforcement learning with a hybrid reward mechanism (combining the above two rewards). Moreover, a comprehensive sentence representation learning method is presented to sufficiently capture the information from the original document. A series of experiments have been conducted on two wildly used benchmark datasets CNN/Daily Mail and BigPatent. The results have shown the superiority of ReSyM by comparing it with the state-of-the-art baselines in terms of various evaluation metrics.