 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarginalized Generalized IoU (MGIoU): A Unified Objective Function for Optimizing Any Convex Parametric Shapes
Apr 24, 2025Optimizing the similarity between parametric shapes is crucial for numerous computer vision tasks, where Intersection over Union (IoU) stands as the canonical measure. However, existing optimization methods exhibit significant shortcomings: regression-based losses like L1/L2 lack correlation with IoU, IoU-based losses are unstable and limited to simple shapes, and task-specific methods are computationally intensive and not generalizable accross domains. As a result, the current landscape of parametric shape objective functions has become scattered, with each domain proposing distinct IoU approximations. To address this, we unify the parametric shape optimization objective functions by introducing Marginalized Generalized IoU (MGIoU), a novel loss function that overcomes these challenges by projecting structured convex shapes onto their unique shape Normals to compute one-dimensional normalized GIoU. MGIoU offers a simple, efficient, fully differentiable approximation strongly correlated with IoU. We then extend MGIoU to MGIoU+ that supports optimizing unstructured convex shapes. Together, MGIoU and MGIoU+ unify parametric shape optimization across diverse applications. Experiments on standard benchmarks demonstrate that MGIoU and MGIoU+ consistently outperform existing losses while reducing loss computation latency by 10-40x. Additionally, MGIoU and MGIoU+ satisfy metric properties and scale-invariance, ensuring robustness as an objective function. We further propose MGIoU- for minimizing overlaps in tasks like collision-free trajectory prediction. Code is available at https://ldtho.github.io/MGIoU
DifFUSER: Diffusion Model for Robust Multi-Sensor Fusion in 3D Object Detection and BEV Segmentation
Apr 06, 2024Diffusion models have recently gained prominence as powerful deep generative models, demonstrating unmatched performance across various domains. However, their potential in multi-sensor fusion remains largely unexplored. In this work, we introduce DifFUSER, a novel approach that leverages diffusion models for multi-modal fusion in 3D object detection and BEV map segmentation. Benefiting from the inherent denoising property of diffusion, DifFUSER is able to refine or even synthesize sensor features in case of sensor malfunction, thereby improving the quality of the fused output. In terms of architecture, our DifFUSER blocks are chained together in a hierarchical BiFPN fashion, termed cMini-BiFPN, offering an alternative architecture for latent diffusion. We further introduce a Gated Self-conditioned Modulated (GSM) latent diffusion module together with a Progressive Sensor Dropout Training (PSDT) paradigm, designed to add stronger conditioning to the diffusion process and robustness to sensor failures. Our extensive evaluations on the Nuscenes dataset reveal that DifFUSER not only achieves state-of-the-art performance with a 69.1% mIOU in BEV map segmentation tasks but also competes effectively with leading transformer-based fusion techniques in 3D object detection.
JRDB-PanoTrack: An Open-world Panoptic Segmentation and Tracking Robotic Dataset in Crowded Human Environments
Apr 02, 2024



Autonomous robot systems have attracted increasing research attention in recent years, where environment understanding is a crucial step for robot navigation, human-robot interaction, and decision. Real-world robot systems usually collect visual data from multiple sensors and are required to recognize numerous objects and their movements in complex human-crowded settings. Traditional benchmarks, with their reliance on single sensors and limited object classes and scenarios, fail to provide the comprehensive environmental understanding robots need for accurate navigation, interaction, and decision-making. As an extension of JRDB dataset, we unveil JRDB-PanoTrack, a novel open-world panoptic segmentation and tracking benchmark, towards more comprehensive environmental perception. JRDB-PanoTrack includes (1) various data involving indoor and outdoor crowded scenes, as well as comprehensive 2D and 3D synchronized data modalities; (2) high-quality 2D spatial panoptic segmentation and temporal tracking annotations, with additional 3D label projections for further spatial understanding; (3) diverse object classes for closed- and open-world recognition benchmarks, with OSPA-based metrics for evaluation. Extensive evaluation of leading methods shows significant challenges posed by our dataset.
PiFeNet: Pillar-Feature Network for Real-Time 3D Pedestrian Detection from Point Cloud
Dec 31, 2021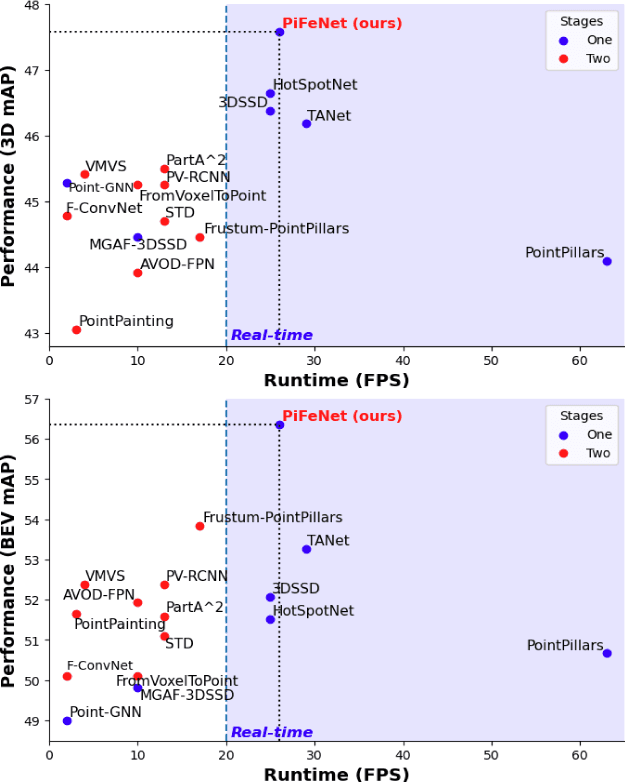
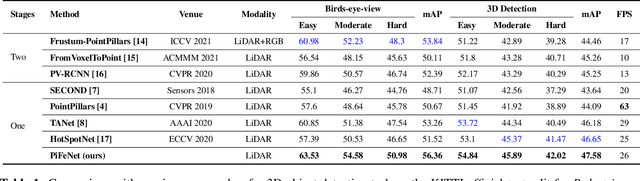
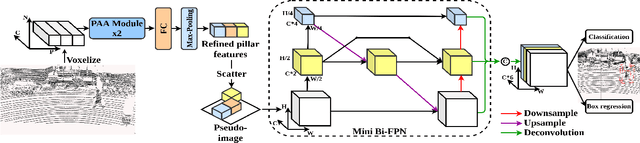

We present PiFeNet, an efficient and accurate real-time 3D detector for pedestrian detection from point clouds. We address two challenges that 3D object detection frameworks encounter when detecting pedestrians: low expressiveness of pillar features and small occupation areas of pedestrians in point clouds. Firstly, we introduce a stackable Pillar Aware Attention (PAA) module for enhanced pillar features extraction while suppressing noises in the point clouds. By integrating multi-point-aware-pooling, point-wise, channel-wise, and task-aware attention into a simple module, the representation capabilities are boosted while requiring little additional computing resources. We also present Mini-BiFPN, a small yet effective feature network that creates bidirectional information flow and multi-level cross-scale feature fusion to better integrate multi-resolution features. Our approach is ranked 1st in KITTI pedestrian BEV and 3D leaderboards while running at 26 frames per second (FPS), and achieves state-of-the-art performance on Nuscenes detection benchmark.