 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Processes with Sample Paths in Reproducing Kernel Banach Spaces
May 27, 2026We investigate the connection between Gaussian processes and Gaussian random elements in reproducing kernel Banach spaces. We show that the covariance operator of a weak second-order Radon probability measure on such a space is uniquely determined by a positive definite function. In the Gaussian case, we characterize those positive definite functions that arise from covariance operators in terms of $γ$-radonifying operators. Building on these results, we extend the classical Driscoll theorem to the Banach space setting.
Safe learning-based control via function-based uncertainty quantification
Apr 01, 2026Uncertainty quantification is essential when deploying learning-based control methods in safety-critical systems. This is commonly realized by constructing uncertainty tubes that enclose the unknown function of interest, e.g., the reward and constraint functions or the underlying dynamics model, with high probability. However, existing approaches for uncertainty quantification typically rely on restrictive assumptions on the unknown function, such as known bounds on functional norms or Lipschitz constants, and struggle with discontinuities. In this paper, we model the unknown function as a random function from which independent and identically distributed realizations can be generated, and construct uncertainty tubes via the scenario approach that hold with high probability and rely solely on the sampled realizations. We integrate these uncertainty tubes into a safe Bayesian optimization algorithm, which we then use to safely tune control parameters on a real Furuta pendulum.
Bayesian Quadrature: Gaussian Processes for Integration
Feb 18, 2026Bayesian quadrature is a probabilistic, model-based approach to numerical integration, the estimation of intractable integrals, or expectations. Although Bayesian quadrature was popularised already in the 1980s, no systematic and comprehensive treatment has been published. The purpose of this survey is to fill this gap. We review the mathematical foundations of Bayesian quadrature from different points of view; present a systematic taxonomy for classifying different Bayesian quadrature methods along the three axes of modelling, inference, and sampling; collect general theoretical guarantees; and provide a controlled numerical study that explores and illustrates the effect of different choices along the axes of the taxonomy. We also provide a realistic assessment of practical challenges and limitations to application of Bayesian quadrature methods and include an up-to-date and nearly exhaustive bibliography that covers not only machine learning and statistics literature but all areas of mathematics and engineering in which Bayesian quadrature or equivalent methods have seen use.
BayesSum: Bayesian Quadrature in Discrete Spaces
Dec 18, 2025This paper addresses the challenging computational problem of estimating intractable expectations over discrete domains. Existing approaches, including Monte Carlo and Russian Roulette estimators, are consistent but often require a large number of samples to achieve accurate results. We propose a novel estimator, \emph{BayesSum}, which is an extension of Bayesian quadrature to discrete domains. It is more sample efficient than alternatives due to its ability to make use of prior information about the integrand through a Gaussian process. We show this through theory, deriving a convergence rate significantly faster than Monte Carlo in a broad range of settings. We also demonstrate empirically that our proposed method does indeed require fewer samples on several synthetic settings as well as for parameter estimation for Conway-Maxwell-Poisson and Potts models.
Stationary MMD Points for Cubature
May 27, 2025Approximation of a target probability distribution using a finite set of points is a problem of fundamental importance, arising in cubature, data compression, and optimisation. Several authors have proposed to select points by minimising a maximum mean discrepancy (MMD), but the non-convexity of this objective precludes global minimisation in general. Instead, we consider \emph{stationary} points of the MMD which, in contrast to points globally minimising the MMD, can be accurately computed. Our main theoretical contribution is the (perhaps surprising) result that, for integrands in the associated reproducing kernel Hilbert space, the cubature error of stationary MMD points vanishes \emph{faster} than the MMD. Motivated by this \emph{super-convergence} property, we consider discretised gradient flows as a practical strategy for computing stationary points of the MMD, presenting a refined convergence analysis that establishes a novel non-asymptotic finite-particle error bound, which may be of independent interest.
A Dictionary of Closed-Form Kernel Mean Embeddings
Apr 26, 2025
Kernel mean embeddings -- integrals of a kernel with respect to a probability distribution -- are essential in Bayesian quadrature, but also widely used in other computational tools for numerical integration or for statistical inference based on the maximum mean discrepancy. These methods often require, or are enhanced by, the availability of a closed-form expression for the kernel mean embedding. However, deriving such expressions can be challenging, limiting the applicability of kernel-based techniques when practitioners do not have access to a closed-form embedding. This paper addresses this limitation by providing a comprehensive dictionary of known kernel mean embeddings, along with practical tools for deriving new embeddings from known ones. We also provide a Python library that includes minimal implementations of the embeddings.
Maximum mean discrepancies of Farey sequences
Jul 14, 2024

We identify a large class of positive-semidefinite kernels for which a certain polynomial rate of convergence of maximum mean discrepancies of Farey sequences is equivalent to the Riemann hypothesis. This class includes all Mat\'ern kernels of order at least one-half.
Orthonormal Expansions for Translation-Invariant Kernels
Jun 17, 2022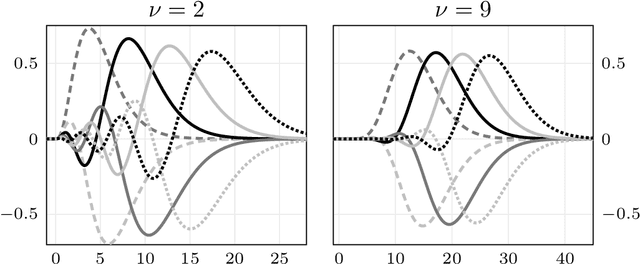
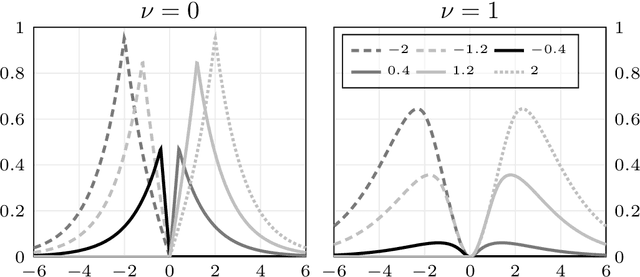
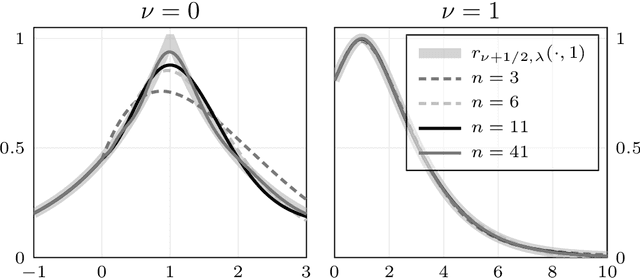
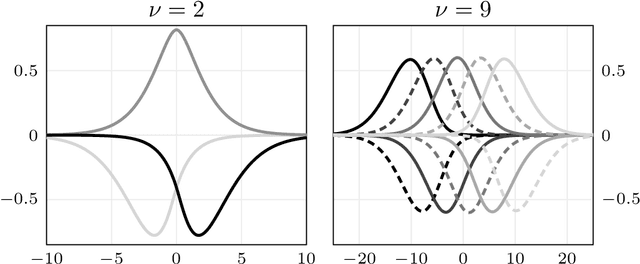
We present a general Fourier analytic technique for constructing orthonormal basis expansions of translation-invariant kernels from orthonormal bases of $\mathscr{L}_2(\mathbb{R})$. This allows us to derive explicit expansions on the real line for (i) Mat\'ern kernels of all half-integer orders in terms of associated Laguerre functions, (ii) the Cauchy kernel in terms of rational functions, and (iii) the Gaussian kernel in terms of Hermite functions.
Maximum Likelihood Estimation in Gaussian Process Regression is Ill-Posed
Mar 17, 2022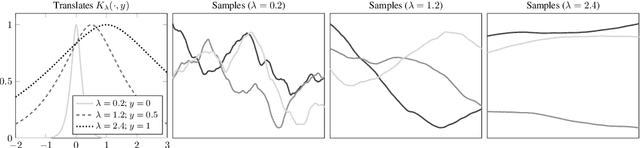
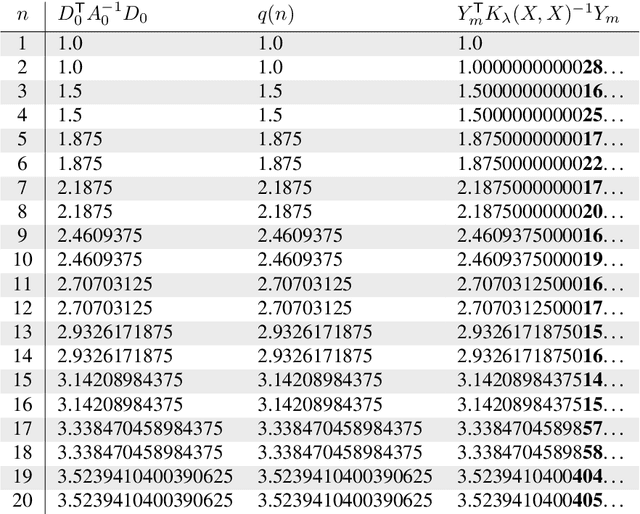
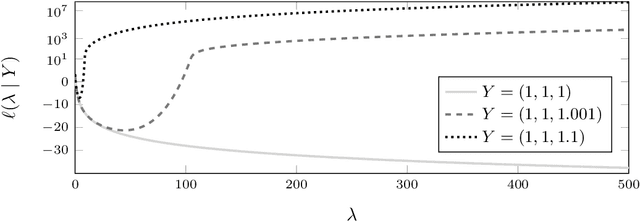
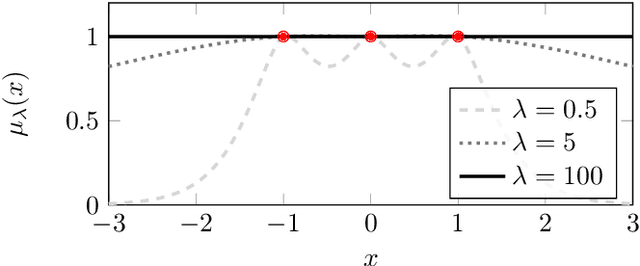
Gaussian process regression underpins countless academic and industrial applications of machine learning and statistics, with maximum likelihood estimation routinely used to select appropriate parameters for the covariance kernel. However, it remains an open problem to establish the circumstances in which maximum likelihood estimation is well-posed. That is, when the predictions of the regression model are continuous (or insensitive to small perturbations) in the training data. This article presents a rigorous proof that the maximum likelihood estimator fails to be well-posed in Hellinger distance in a scenario where the data are noiseless. The failure case occurs for any Gaussian process with a stationary covariance function whose lengthscale parameter is estimated using maximum likelihood. Although the failure of maximum likelihood estimation is informally well-known, these theoretical results appear to be the first of their kind, and suggest that well-posedness may need to be assessed post-hoc, on a case-by-case basis, when maximum likelihood estimation is used to train a Gaussian process model.
Asymptotic Bounds for Smoothness Parameter Estimates in Gaussian Process Regression
Mar 10, 2022It is common to model a deterministic response function, such as the output of a computer experiment, as a Gaussian process with a Mat\'ern covariance kernel. The smoothness parameter of a Mat\'ern kernel determines many important properties of the model in the large data limit, such as the rate of convergence of the conditional mean to the response function. We prove that the maximum likelihood and cross-validation estimates of the smoothness parameter cannot asymptotically undersmooth the truth when the data are obtained on a fixed bounded subset of $\mathbb{R}^d$. That is, if the data-generating response function has Sobolev smoothness $\nu_0 + d/2$, then the smoothness parameter estimates cannot remain below $\nu_0$ as more data are obtained. These results are based on a general theorem, proved using reproducing kernel Hilbert space techniques, about sets of values the parameter estimates cannot take and approximation theory in Sobolev spaces.