 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Flowformer: Linearizing Transformers with Conservation Flows
Feb 13, 2022
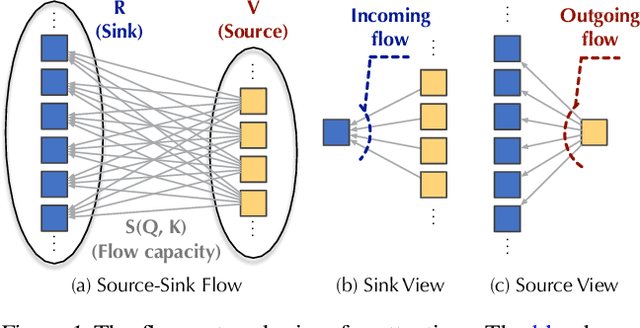
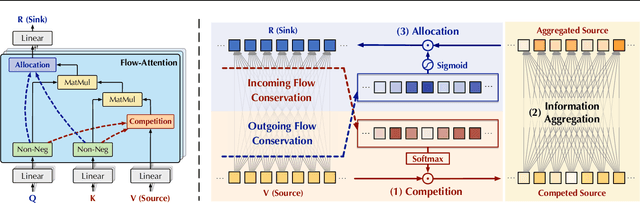
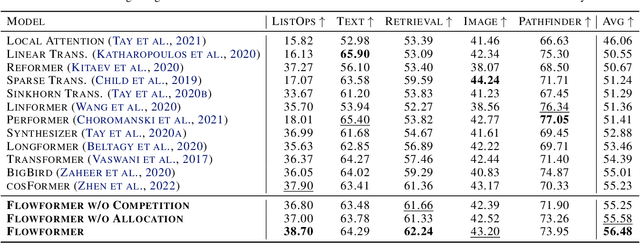
Transformers based on the attention mechanism have achieved impressive success in various areas. However, the attention mechanism has a quadratic complexity, significantly impeding Transformers from dealing with numerous tokens and scaling up to bigger models. Previous methods mainly utilize the similarity decomposition and the associativity of matrix multiplication to devise linear-time attention mechanisms. They avoid degeneration of attention to a trivial distribution by reintroducing inductive biases such as the locality, thereby at the expense of model generality and expressiveness. In this paper, we linearize Transformers free from specific inductive biases based on the flow network theory. We cast attention as the information flow aggregated from the sources (values) to the sinks (results) through the learned flow capacities (attentions). Within this framework, we apply the property of flow conservation with attention and propose the Flow-Attention mechanism of linear complexity. By respectively conserving the incoming flow of sinks for source competition and the outgoing flow of sources for sink allocation, Flow-Attention inherently generates informative attentions without using specific inductive biases. Empowered by the Flow-Attention, Flowformer yields strong performance in linear time for wide areas, including long sequence, time series, vision, natural language, and reinforcement learning.
Efficient Natural Gradient Descent Methods for Large-Scale Optimization Problems
Feb 13, 2022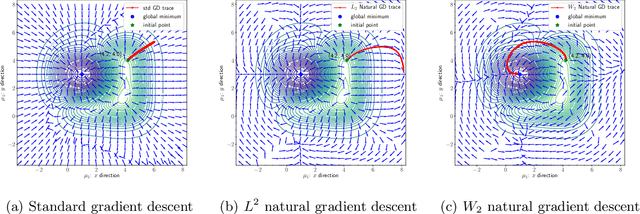
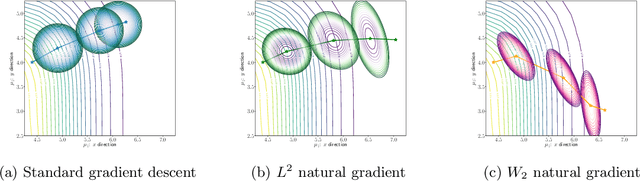
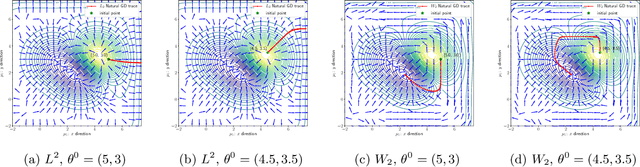
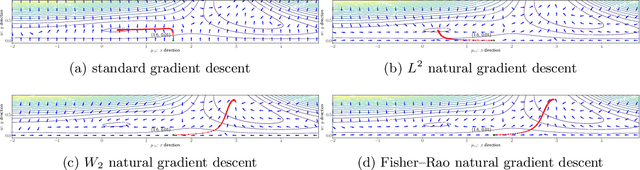
We propose an efficient numerical method for computing natural gradient descent directions with respect to a generic metric in the state space. Our technique relies on representing the natural gradient direction as a solution to a standard least-squares problem. Hence, instead of calculating, storing, or inverting the information matrix directly, we apply efficient methods from numerical linear algebra to solve this least-squares problem. We treat both scenarios where the derivative of the state variable with respect to the parameter is either explicitly known or implicitly given through constraints. We apply the QR decomposition to solve the least-squares problem in the former case and utilize the adjoint-state method to compute the natural gradient descent direction in the latter case. As a result, we can reliably compute several natural gradient descents, including the Wasserstein natural gradient, for a large-scale parameter space with thousands of dimensions, which was believed to be out of reach. Finally, our numerical results shed light on the qualitative differences among the standard gradient descent method and various natural gradient descent methods based on different metric spaces in large-scale nonconvex optimization problems.
Increasing the skill of short-term wind speed ensemble forecasts combining forecasts and observations via a new dynamic calibration
Jan 28, 2022
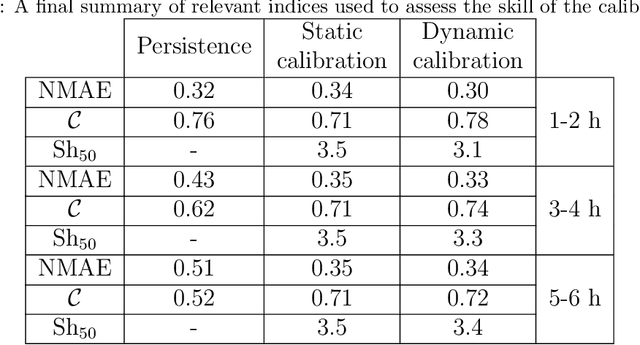
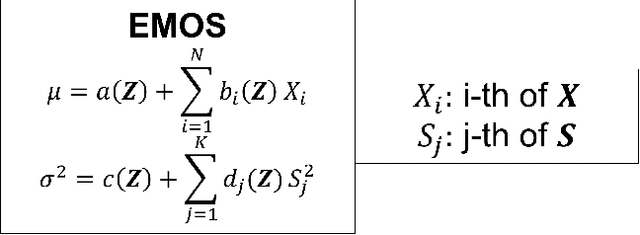
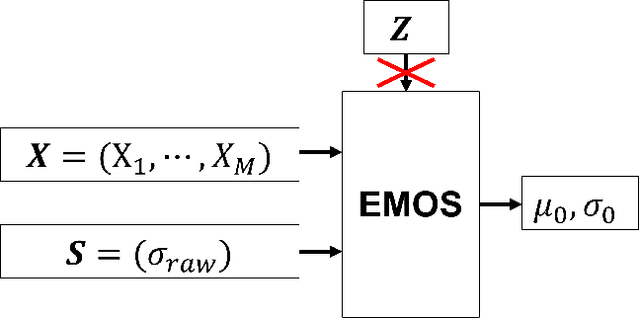
All numerical weather prediction models used for the wind industry need to produce their forecasts starting from the main synoptic hours 00, 06, 12, and 18 UTC, once the analysis becomes available. The six-hour latency time between two consecutive model runs calls for strategies to fill the gap by providing new accurate predictions having, at least, hourly frequency. This is done to accommodate the request of frequent, accurate and fresh information from traders and system regulators to continuously adapt their work strategies. Here, we propose a strategy where quasi-real time observed wind speed and weather model predictions are combined by means of a novel Ensemble Model Output Statistics (EMOS) strategy. The success of our strategy is measured by comparisons against observed wind speed from SYNOP stations over Italy in the years 2018 and 2019.
Deep Learning Algorithm for Threat Detection in Hackers Forum (Deep Web)
Feb 03, 2022In our current society, the inter-connectivity of devices provides easy access for netizens to utilize cyberspace technology for illegal activities. The deep web platform is a consummative ecosystem shielded by boundaries of trust, information sharing, trade-off, and review systems. Domain knowledge is shared among experts in hacker's forums which contain indicators of compromise that can be explored for cyberthreat intelligence. Developing tools that can be deployed for threat detection is integral in securing digital communication in cyberspace. In this paper, we addressed the use of TOR relay nodes for anonymizing communications in deep web forums. We propose a novel approach for detecting cyberthreats using a deep learning algorithm Long Short-Term Memory (LSTM). The developed model outperformed the experimental results of other researchers in this problem domain with an accuracy of 94\% and precision of 90\%. Our model can be easily deployed by organizations in securing digital communications and detection of vulnerability exposure before cyberattack.
Real-World Graph Convolution Networks (RW-GCNs) for Action Recognition in Smart Video Surveillance
Jan 15, 2022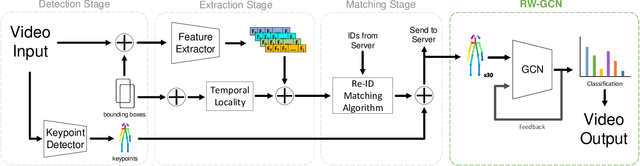
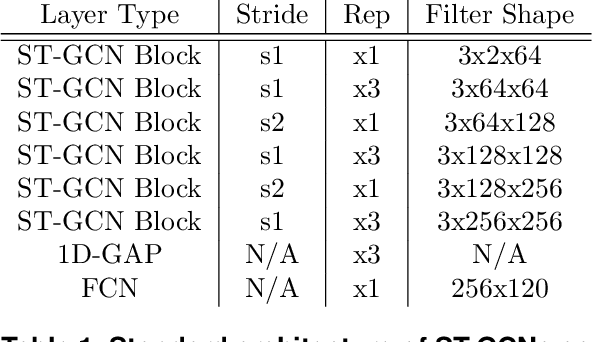

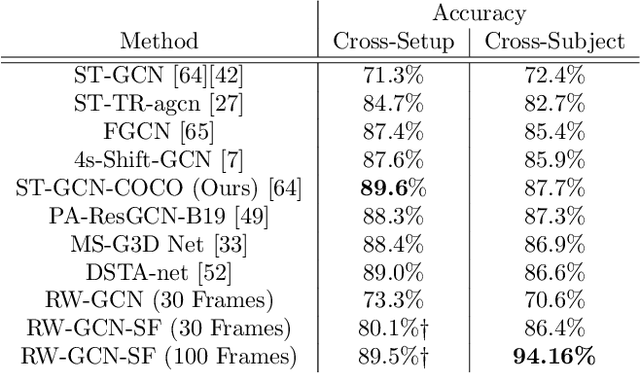
Action recognition is a key algorithmic part of emerging on-the-edge smart video surveillance and security systems. Skeleton-based action recognition is an attractive approach which, instead of using RGB pixel data, relies on human pose information to classify appropriate actions. However, existing algorithms often assume ideal conditions that are not representative of real-world limitations, such as noisy input, latency requirements, and edge resource constraints. To address the limitations of existing approaches, this paper presents Real-World Graph Convolution Networks (RW-GCNs), an architecture-level solution for meeting the domain constraints of Real World Skeleton-based Action Recognition. Inspired by the presence of feedback connections in the human visual cortex, RW-GCNs leverage attentive feedback augmentation on existing near state-of-the-art (SotA) Spatial-Temporal Graph Convolution Networks (ST-GCNs). The ST-GCNs' design choices are derived from information theory-centric principles to address both the spatial and temporal noise typically encountered in end-to-end real-time and on-the-edge smart video systems. Our results demonstrate RW-GCNs' ability to serve these applications by achieving a new SotA accuracy on the NTU-RGB-D-120 dataset at 94.1%, and achieving 32X less latency than baseline ST-GCN applications while still achieving 90.4% accuracy on the Northwestern UCLA dataset in the presence of spatial keypoint noise. RW-GCNs further show system scalability by running on the 10X cost effective NVIDIA Jetson Nano (as opposed to NVIDIA Xavier NX), while still maintaining a respectful range of throughput (15.6 to 5.5 Actions per Second) on the resource constrained device. The code is available here: https://github.com/TeCSAR-UNCC/RW-GCN.
Design and Implementation of Electronic Infrastructure For Academic Establishment
Feb 08, 2022Most establishments including academic institutions under goes the lengthy process of study-based document handling such as direct mailing, indexing and tracking. This daily task is time consuming and resource-intensive. Using a private network dedicated for such document management would benefit the establishment increasing operational efficiency. In this study, the Information and Communication Engineering (ICE) Department was used as a model to determine the requirements needed to build the intranet network. A packet tracer simulator was used to build a virtual intranet architecture.Then the simulation report was examined to ensure optimum functionality. Upon establishing a stable behavior an intranet infrastructure building commenced using the available hardware components and software.The system architecture was based on Windows 2012R2 server to manage 3 separated sub-networks connected to three switches and one router. Running the intranet for one semester proved its success in providing a fast, cheap and simplified service for all department needs. The accomplished system is a step forward to achieve a full electronic department in scientific establishments.
Generative Coarse-Graining of Molecular Conformations
Jan 28, 2022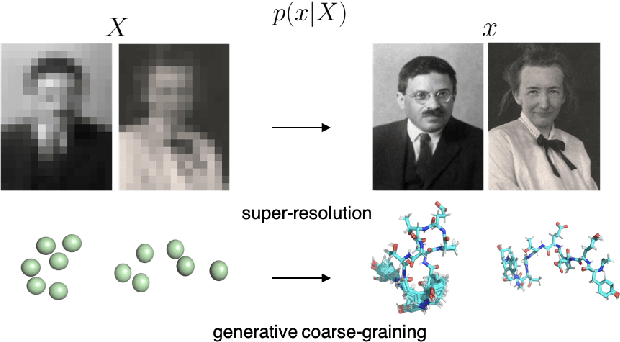

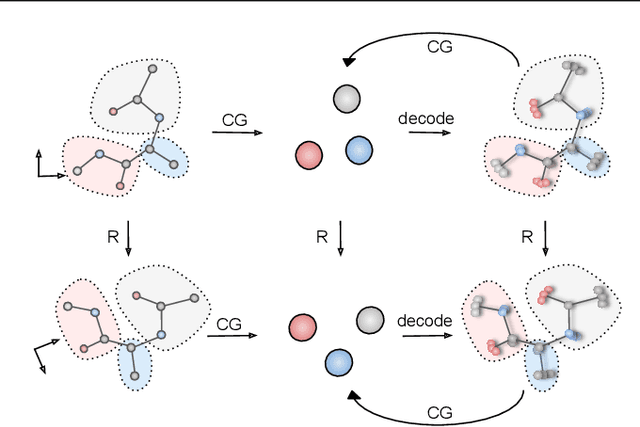
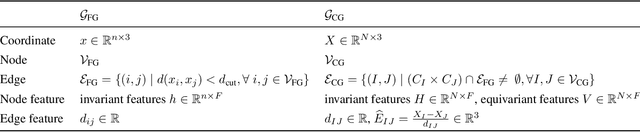
Coarse-graining (CG) of molecular simulations simplifies the particle representation by grouping selected atoms into pseudo-beads and therefore drastically accelerates simulation. However, such CG procedure induces information losses, which makes accurate backmapping, i.e., restoring fine-grained (FG) coordinates from CG coordinates, a long-standing challenge. Inspired by the recent progress in generative models and equivariant networks, we propose a novel model that rigorously embeds the vital probabilistic nature and geometric consistency requirements of the backmapping transformation. Our model encodes the FG uncertainties into an invariant latent space and decodes them back to FG geometries via equivariant convolutions. To standardize the evaluation of this domain, we further provide three comprehensive benchmarks based on molecular dynamics trajectories. Extensive experiments show that our approach always recovers more realistic structures and outperforms existing data-driven methods with a significant margin.
Disentanglement and Generalization Under Correlation Shifts
Dec 29, 2021
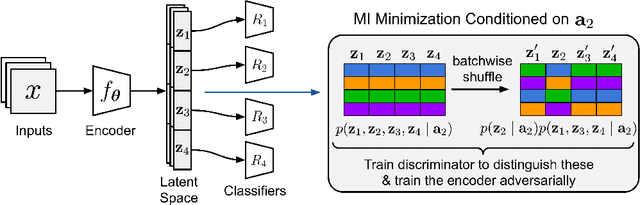
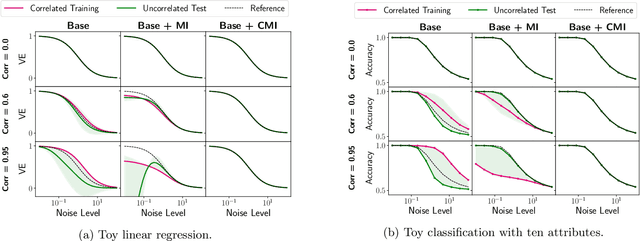

Correlations between factors of variation are prevalent in real-world data. Machine learning algorithms may benefit from exploiting such correlations, as they can increase predictive performance on noisy data. However, often such correlations are not robust (e.g., they may change between domains, datasets, or applications) and we wish to avoid exploiting them. Disentanglement methods aim to learn representations which capture different factors of variation in latent subspaces. A common approach involves minimizing the mutual information between latent subspaces, such that each encodes a single underlying attribute. However, this fails when attributes are correlated. We solve this problem by enforcing independence between subspaces conditioned on the available attributes, which allows us to remove only dependencies that are not due to the correlation structure present in the training data. We achieve this via an adversarial approach to minimize the conditional mutual information (CMI) between subspaces with respect to categorical variables. We first show theoretically that CMI minimization is a good objective for robust disentanglement on linear problems with Gaussian data. We then apply our method on real-world datasets based on MNIST and CelebA, and show that it yields models that are disentangled and robust under correlation shift, including in weakly supervised settings.
ERF: Explicit Radiance Field Reconstruction From Scratch
Feb 28, 2022

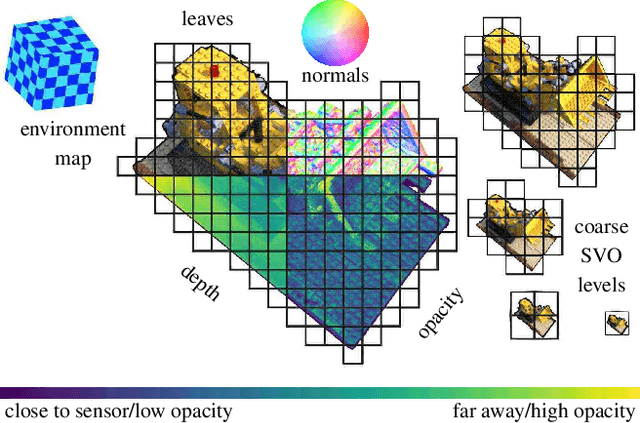
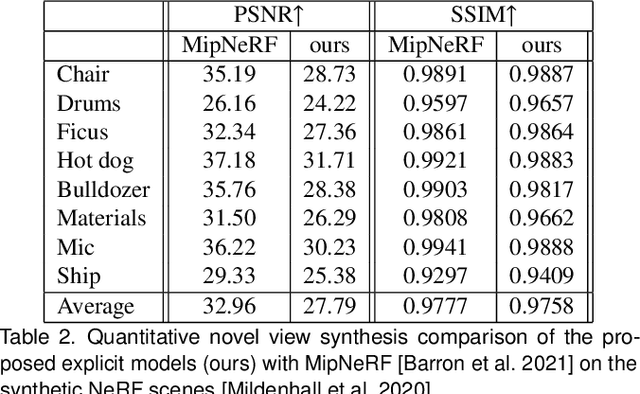
We propose a novel explicit dense 3D reconstruction approach that processes a set of images of a scene with sensor poses and calibrations and estimates a photo-real digital model. One of the key innovations is that the underlying volumetric representation is completely explicit in contrast to neural network-based (implicit) alternatives. We encode scenes explicitly using clear and understandable mappings of optimization variables to scene geometry and their outgoing surface radiance. We represent them using hierarchical volumetric fields stored in a sparse voxel octree. Robustly reconstructing such a volumetric scene model with millions of unknown variables from registered scene images only is a highly non-convex and complex optimization problem. To this end, we employ stochastic gradient descent (Adam) which is steered by an inverse differentiable renderer. We demonstrate that our method can reconstruct models of high quality that are comparable to state-of-the-art implicit methods. Importantly, we do not use a sequential reconstruction pipeline where individual steps suffer from incomplete or unreliable information from previous stages, but start our optimizations from uniformed initial solutions with scene geometry and radiance that is far off from the ground truth. We show that our method is general and practical. It does not require a highly controlled lab setup for capturing, but allows for reconstructing scenes with a vast variety of objects, including challenging ones, such as outdoor plants or furry toys. Finally, our reconstructed scene models are versatile thanks to their explicit design. They can be edited interactively which is computationally too costly for implicit alternatives.
Mask-based Latent Reconstruction for Reinforcement Learning
Jan 28, 2022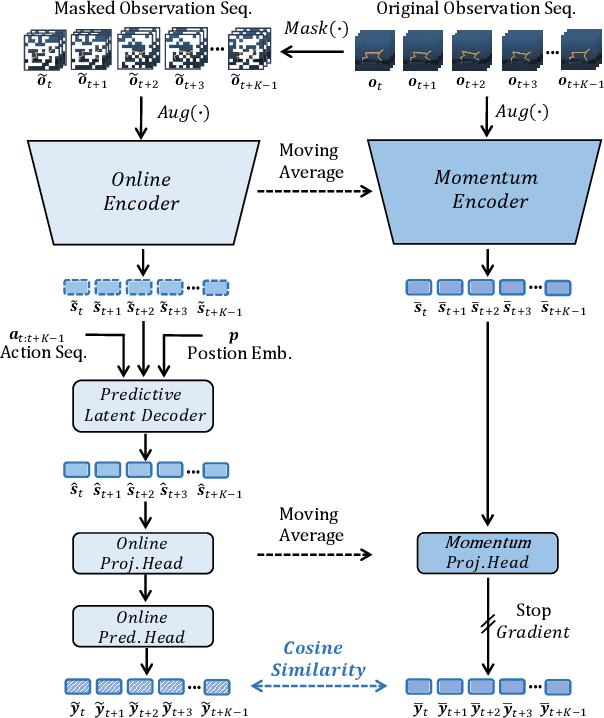
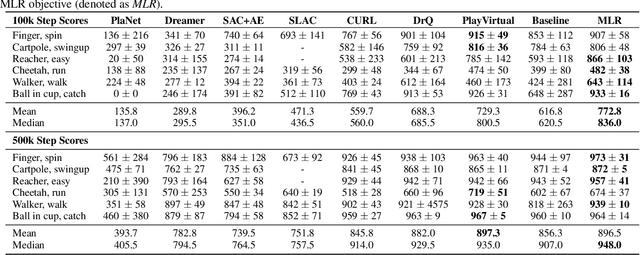
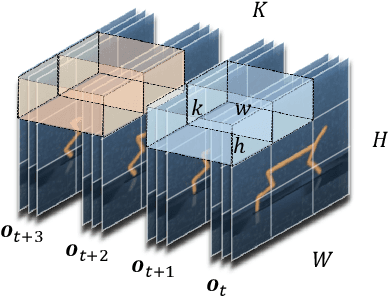
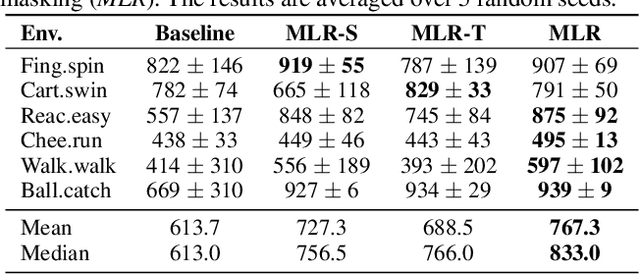
For deep reinforcement learning (RL) from pixels, learning effective state representations is crucial for achieving high performance. However, in practice, limited experience and high-dimensional input prevent effective representation learning. To address this, motivated by the success of masked modeling in other research fields, we introduce mask-based reconstruction to promote state representation learning in RL. Specifically, we propose a simple yet effective self-supervised method, Mask-based Latent Reconstruction (MLR), to predict the complete state representations in the latent space from the observations with spatially and temporally masked pixels. MLR enables the better use of context information when learning state representations to make them more informative, which facilitates RL agent training. Extensive experiments show that our MLR significantly improves the sample efficiency in RL and outperforms the state-of-the-art sample-efficient RL methods on multiple continuous benchmark environments.