 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture-of-Modality-Experts with Holistic Token Learning for Fine-Grained Multimodal Visual Analytics in Driver Action Recognition
Apr 07, 2026Robust multimodal visual analytics remains challenging when heterogeneous modalities provide complementary but input-dependent evidence for decision-making.Existing multimodal learning methods mainly rely on fixed fusion modules or predefined cross-modal interactions, which are often insufficient to adapt to changing modality reliability and to capture fine-grained action cues. To address this issue, we propose a Mixture-of-Modality-Experts (MoME) framework with a Holistic Token Learning (HTL) strategy. MoME enables adaptive collaboration among modality-specific experts, while HTL improves both intra-expert refinement and inter-expert knowledge transfer through class tokens and spatio-temporal tokens. In this way, our method forms a knowledge-centric multimodal learning framework that improves expert specialization while reducing ambiguity in multimodal fusion.We validate the proposed framework on driver action recognition as a representative multimodal understanding taskThe experimental results on the public benchmark show that the proposed MoME framework and the HTL strategy jointly outperform representative single-modal and multimodal baselines. Additional ablation, validation, and visualization results further verify that the proposed HTL strategy improves subtle multimodal understanding and offers better interpretability.
Accelerating Diffusion-based Video Editing via Heterogeneous Caching: Beyond Full Computing at Sampled Denoising Timestep
Mar 25, 2026Diffusion-based video editing has emerged as an important paradigm for high-quality and flexible content generation. However, despite their generality and strong modeling capacity, Diffusion Transformers (DiT) remain computationally expensive due to the iterative denoising process, posing challenges for practical deployment. Existing video diffusion acceleration methods primarily exploit denoising timestep-level feature reuse, which mitigates the redundancy in denoising process, but overlooks the architectural redundancy within the DiT that many attention operations over spatio-temporal tokens are redundantly executed, offering little to no incremental contribution to the model output. This work introduces HetCache, a training-free diffusion acceleration framework designed to exploit the inherent heterogeneity in diffusion-based masked video-to-video (MV2V) generation and editing. Instead of uniformly reuse or randomly sampling tokens, HetCache assesses the contextual relevance and interaction strength among various types of tokens in designated computing steps. Guided by spatial priors, it divides the spatial-temporal tokens in DiT model into context and generative tokens, and selectively caches the context tokens that exhibit the strongest correlation and most representative semantics with generative ones. This strategy reduces redundant attention operations while maintaining editing consistency and fidelity. Experiments show that HetCache achieves a noticeable acceleration, including a 2.67$\times$ latency speedup and FLOPs reduction over commonly used foundation models, with negligible degradation in editing quality.
DAOS: A Multimodal In-cabin Behavior Monitoring with Driver Action-Object Synergy Dataset
Jan 17, 2026In driver activity monitoring, movements are mostly limited to the upper body, which makes many actions look similar. To tell these actions apart, human often rely on the objects the driver is using, such as holding a phone compared with gripping the steering wheel. However, most existing driver-monitoring datasets lack accurate object-location annotations or do not link objects to their associated actions, leaving a critical gap for reliable action recognition. To address this, we introduce the Driver Action with Object Synergy (DAOS) dataset, comprising 9,787 video clips annotated with 36 fine-grained driver actions and 15 object classes, totaling more than 2.5 million corresponding object instances. DAOS offers multi-modal, multi-view data (RGB, IR, and depth) from front, face, left, and right perspectives. Although DAOS captures a wide range of cabin objects, only a few are directly relevant to each action for prediction, so focusing on task-specific human-object relations is essential. To tackle this challenge, we propose the Action-Object-Relation Network (AOR-Net). AOR-Net comprehends complex driver actions through multi-level reasoning and a chain-of-action prompting mechanism that models the logical relationships among actions, objects, and their relations. Additionally, the Mixture of Thoughts module is introduced to dynamically select essential knowledge at each stage, enhancing robustness in object-rich and object-scarce conditions. Extensive experiments demonstrate that our model outperforms other state-of-the-art methods on various datasets.
NMPC-based Motion Planning with Adaptive Weighting for Dynamic Object Interception
Nov 19, 2025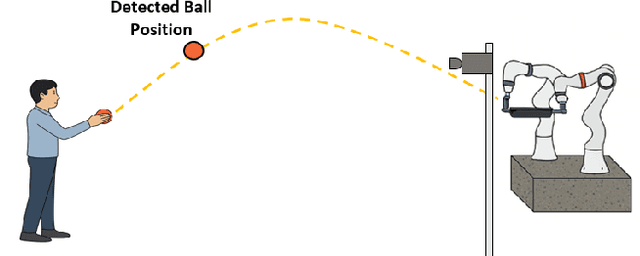

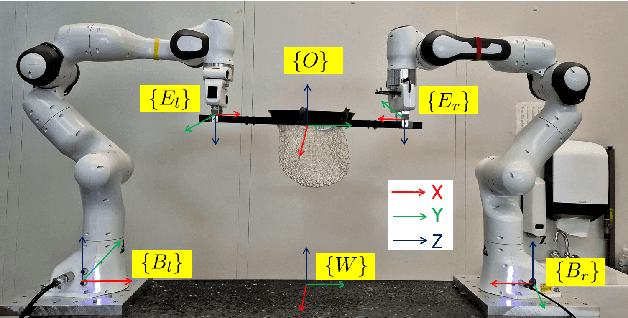
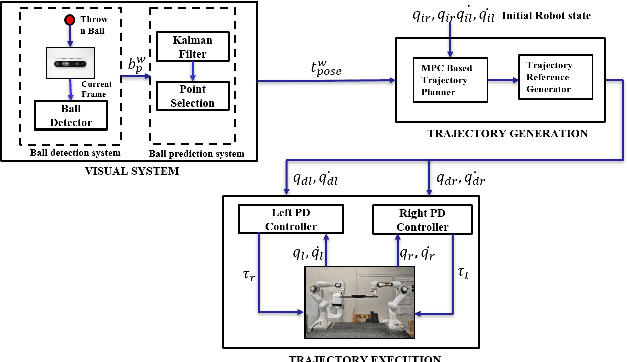
Catching fast-moving objects serves as a benchmark for robotic agility, posing significant coordination challenges for cooperative manipulator systems holding a catcher, particularly due to inherent closed-chain constraints. This paper presents a nonlinear model predictive control (MPC)-based motion planner that bridges high-level interception planning with real-time joint space control, enabling dynamic object interception for systems comprising two cooperating arms. We introduce an Adaptive- Terminal (AT) MPC formulation featuring cost shaping, which contrasts with a simpler Primitive-Terminal (PT) approach relying heavily on terminal penalties for rapid convergence. The proposed AT formulation is shown to effectively mitigate issues related to actuator power limit violations frequently encountered with the PT strategy, yielding trajectories and significantly reduced control effort. Experimental results on a robotic platform with two cooperative arms, demonstrating excellent real time performance, with an average planner cycle computation time of approximately 19 ms-less than half the 40 ms system sampling time. These results indicate that the AT formulation achieves significantly improved motion quality and robustness with minimal computational overhead compared to the PT baseline, making it well-suited for dynamic, cooperative interception tasks.
Towards Blind Bitstream-corrupted Video Recovery via a Visual Foundation Model-driven Framework
Jul 30, 2025Video signals are vulnerable in multimedia communication and storage systems, as even slight bitstream-domain corruption can lead to significant pixel-domain degradation. To recover faithful spatio-temporal content from corrupted inputs, bitstream-corrupted video recovery has recently emerged as a challenging and understudied task. However, existing methods require time-consuming and labor-intensive annotation of corrupted regions for each corrupted video frame, resulting in a large workload in practice. In addition, high-quality recovery remains difficult as part of the local residual information in corrupted frames may mislead feature completion and successive content recovery. In this paper, we propose the first blind bitstream-corrupted video recovery framework that integrates visual foundation models with a recovery model, which is adapted to different types of corruption and bitstream-level prompts. Within the framework, the proposed Detect Any Corruption (DAC) model leverages the rich priors of the visual foundation model while incorporating bitstream and corruption knowledge to enhance corruption localization and blind recovery. Additionally, we introduce a novel Corruption-aware Feature Completion (CFC) module, which adaptively processes residual contributions based on high-level corruption understanding. With VFM-guided hierarchical feature augmentation and high-level coordination in a mixture-of-residual-experts (MoRE) structure, our method suppresses artifacts and enhances informative residuals. Comprehensive evaluations show that the proposed method achieves outstanding performance in bitstream-corrupted video recovery without requiring a manually labeled mask sequence. The demonstrated effectiveness will help to realize improved user experience, wider application scenarios, and more reliable multimedia communication and storage systems.
CL-HOI: Cross-Level Human-Object Interaction Distillation from Vision Large Language Models
Oct 21, 2024Human-object interaction (HOI) detection has seen advancements with Vision Language Models (VLMs), but these methods often depend on extensive manual annotations. Vision Large Language Models (VLLMs) can inherently recognize and reason about interactions at the image level but are computationally heavy and not designed for instance-level HOI detection. To overcome these limitations, we propose a Cross-Level HOI distillation (CL-HOI) framework, which distills instance-level HOIs from VLLMs image-level understanding without the need for manual annotations. Our approach involves two stages: context distillation, where a Visual Linguistic Translator (VLT) converts visual information into linguistic form, and interaction distillation, where an Interaction Cognition Network (ICN) reasons about spatial, visual, and context relations. We design contrastive distillation losses to transfer image-level context and interaction knowledge from the teacher to the student model, enabling instance-level HOI detection. Evaluations on HICO-DET and V-COCO datasets demonstrate that our CL-HOI surpasses existing weakly supervised methods and VLLM supervised methods, showing its efficacy in detecting HOIs without manual labels.
Empowering Large Language Model for Continual Video Question Answering with Collaborative Prompting
Oct 01, 2024



In recent years, the rapid increase in online video content has underscored the limitations of static Video Question Answering (VideoQA) models trained on fixed datasets, as they struggle to adapt to new questions or tasks posed by newly available content. In this paper, we explore the novel challenge of VideoQA within a continual learning framework, and empirically identify a critical issue: fine-tuning a large language model (LLM) for a sequence of tasks often results in catastrophic forgetting. To address this, we propose Collaborative Prompting (ColPro), which integrates specific question constraint prompting, knowledge acquisition prompting, and visual temporal awareness prompting. These prompts aim to capture textual question context, visual content, and video temporal dynamics in VideoQA, a perspective underexplored in prior research. Experimental results on the NExT-QA and DramaQA datasets show that ColPro achieves superior performance compared to existing approaches, achieving 55.14\% accuracy on NExT-QA and 71.24\% accuracy on DramaQA, highlighting its practical relevance and effectiveness.
CM2-Net: Continual Cross-Modal Mapping Network for Driver Action Recognition
Jun 18, 2024Driver action recognition has significantly advanced in enhancing driver-vehicle interactions and ensuring driving safety by integrating multiple modalities, such as infrared and depth. Nevertheless, compared to RGB modality only, it is always laborious and costly to collect extensive data for all types of non-RGB modalities in car cabin environments. Therefore, previous works have suggested independently learning each non-RGB modality by fine-tuning a model pre-trained on RGB videos, but these methods are less effective in extracting informative features when faced with newly-incoming modalities due to large domain gaps. In contrast, we propose a Continual Cross-Modal Mapping Network (CM2-Net) to continually learn each newly-incoming modality with instructive prompts from the previously-learned modalities. Specifically, we have developed Accumulative Cross-modal Mapping Prompting (ACMP), to map the discriminative and informative features learned from previous modalities into the feature space of newly-incoming modalities. Then, when faced with newly-incoming modalities, these mapped features are able to provide effective prompts for which features should be extracted and prioritized. These prompts are accumulating throughout the continual learning process, thereby boosting further recognition performances. Extensive experiments conducted on the Drive&Act dataset demonstrate the performance superiority of CM2-Net on both uni- and multi-modal driver action recognition.
Local-to-global Perspectives on Graph Neural Networks
Jun 18, 2023



This thesis presents a local-to-global perspective on graph neural networks (GNN), the leading architecture to process graph-structured data. After categorizing GNN into local Message Passing Neural Networks (MPNN) and global Graph transformers, we present three pieces of work: 1) study the convergence property of a type of global GNN, Invariant Graph Networks, 2) connect the local MPNN and global Graph Transformer, and 3) use local MPNN for graph coarsening, a standard subroutine used in global modeling.
Top-Down Viewing for Weakly Supervised Grounded Image Captioning
Jun 15, 2023Weakly supervised grounded image captioning (WSGIC) aims to generate the caption and ground (localize) predicted object words in the input image without using bounding box supervision. Recent two-stage solutions mostly apply a bottom-up pipeline: (1) first apply an off-the-shelf object detector to encode the input image into multiple region features; (2) and then leverage a soft-attention mechanism for captioning and grounding. However, object detectors are mainly designed to extract object semantics (i.e., the object category). Besides, they break down the structural images into pieces of individual proposals. As a result, the subsequent grounded captioner is often overfitted to find the correct object words, while overlooking the relation between objects (e.g., what is the person doing?), and selecting incompatible proposal regions for grounding. To address these difficulties, we propose a one-stage weakly supervised grounded captioner that directly takes the RGB image as input to perform captioning and grounding at the top-down image level. In addition, we explicitly inject a relation module into our one-stage framework to encourage the relation understanding through multi-label classification. The relation semantics aid the prediction of relation words in the caption. We observe that the relation words not only assist the grounded captioner in generating a more accurate caption but also improve the grounding performance. We validate the effectiveness of our proposed method on two challenging datasets (Flick30k Entities captioning and MSCOCO captioning). The experimental results demonstrate that our method achieves state-of-the-art grounding performance.