 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Scalable and Robust Structured Bandits: A Meta-Learning Framework
Feb 26, 2022
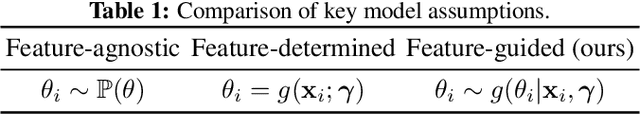
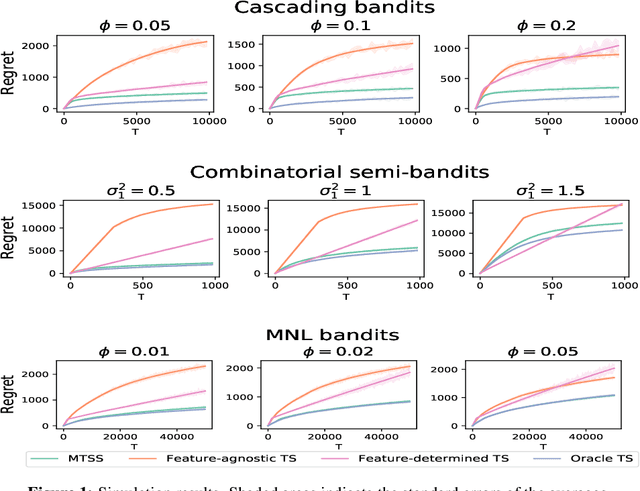
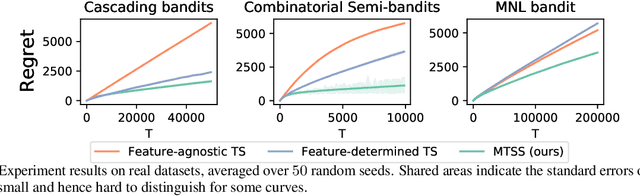
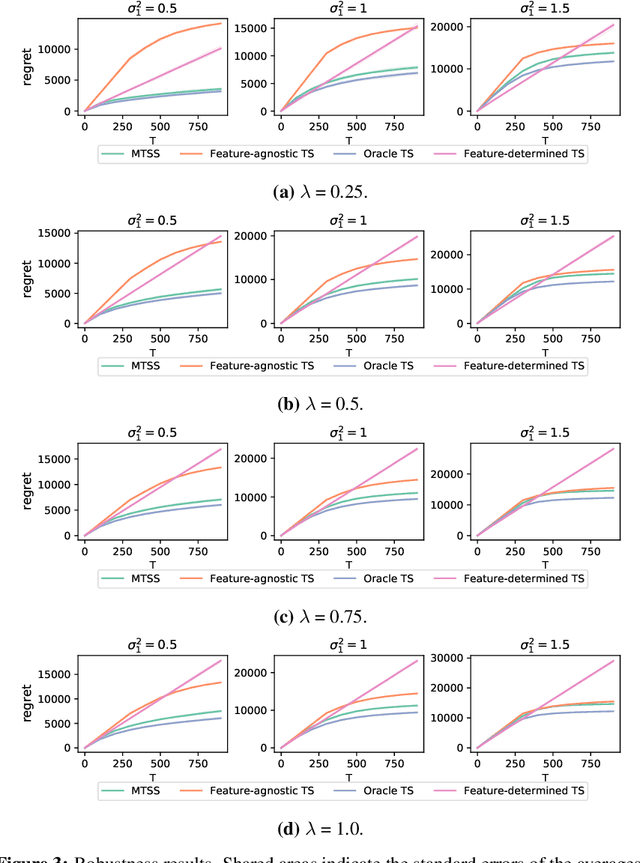
Online learning in large-scale structured bandits is known to be challenging due to the curse of dimensionality. In this paper, we propose a unified meta-learning framework for a general class of structured bandit problems where the parameter space can be factorized to item-level. The novel bandit algorithm is general to be applied to many popular problems,scalable to the huge parameter and action spaces, and robust to the specification of the generalization model. At the core of this framework is a Bayesian hierarchical model that allows information sharing among items via their features, upon which we design a meta Thompson sampling algorithm. Three representative examples are discussed thoroughly. Both theoretical analysis and numerical results support the usefulness of the proposed method.
Differentiable Control Barrier Functions for Vision-based End-to-End Autonomous Driving
Mar 04, 2022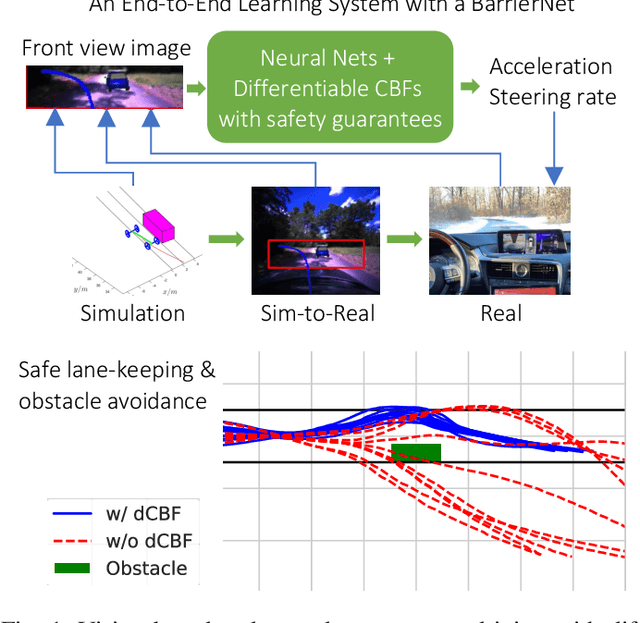

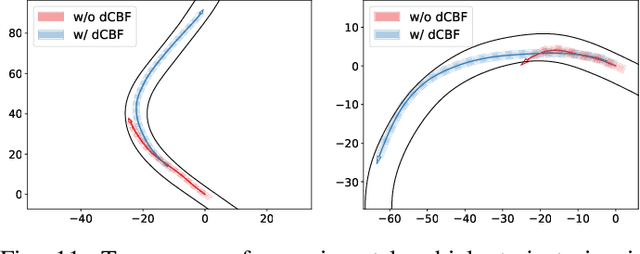
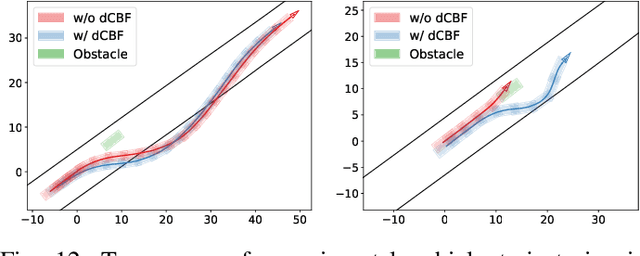
Guaranteeing safety of perception-based learning systems is challenging due to the absence of ground-truth state information unlike in state-aware control scenarios. In this paper, we introduce a safety guaranteed learning framework for vision-based end-to-end autonomous driving. To this end, we design a learning system equipped with differentiable control barrier functions (dCBFs) that is trained end-to-end by gradient descent. Our models are composed of conventional neural network architectures and dCBFs. They are interpretable at scale, achieve great test performance under limited training data, and are safety guaranteed in a series of autonomous driving scenarios such as lane keeping and obstacle avoidance. We evaluated our framework in a sim-to-real environment, and tested on a real autonomous car, achieving safe lane following and obstacle avoidance via Augmented Reality (AR) and real parked vehicles.
Parametric Channel Model Estimation for Large Intelligent Surface-Based Transceiver-assisted Communication System
Apr 05, 2022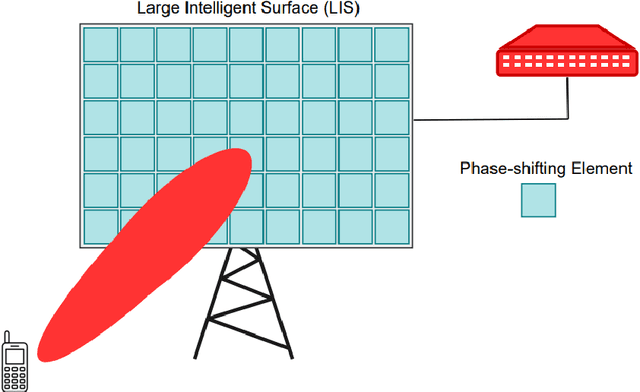
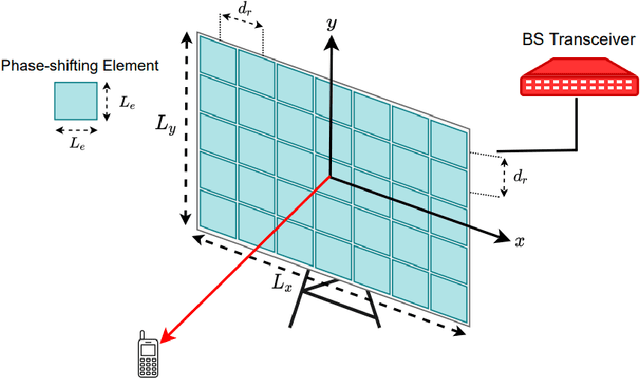
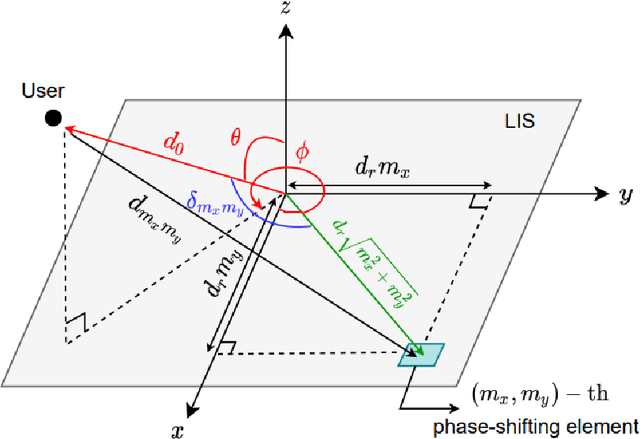

The number of connected mobile devices and the amount of data traffic through these devices are expected to grow many-fold in future communication networks. To support the scale of this huge data traffic, more and more base stations and wireless terminals are required to be deployed in existing networks. Nevertheless, practically deploying a large number of base stations having massive antenna arrays will substantially increase the hardware cost and power consumption of the network. A promising approach for enhancing the coverage and rate of wireless communication systems is the large intelligent surface-based transceiver (LISBT), which uses a spatially continuous surface for signal transmission and receiving. A typical LIS consists of a planar array having a large number of reflecting metamaterial elements (e.g., low-cost printed dipoles), each of which could act as a phase shift. It is also considered to be a cost effective and energy efficient solution. Accurate channel state information (CSI) in LISBT-assisted wireless communication systems is critical for achieving these goals. In this paper, we propose a channel estimation scheme based on the physical parameters of the system. that requires only five pilot signals to perfectly estimate the channel parameters assuming there is no noise at the receiver. In the presence of noise, we propose an iterative estimation algorithm that decreases the channel estimation error due to noise. The proposed scheme's training overhead and computational cost do not grow with the number of antennas, unlike previous work on enormous multiple-input multiple-output (MIMO). The channel estimate scheme based on the physical properties of the Large intelligent surface-based transceiver (LISBT)-assisted wireless communication systems is the subject of our future study.
Probabilistically Robust Optimization of IRS-aided SWIPT Under Coordinated Spectrum Underlay
Jan 31, 2022
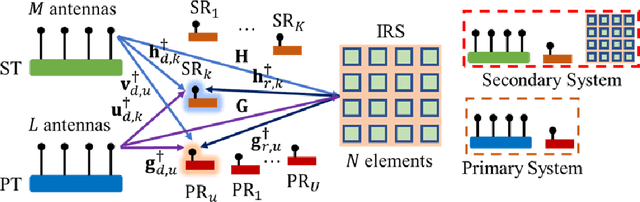
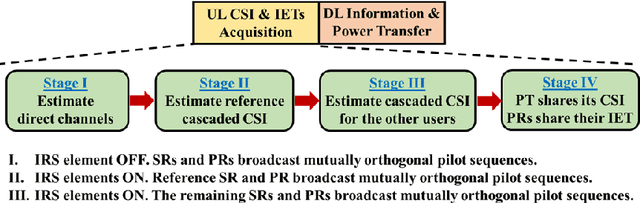
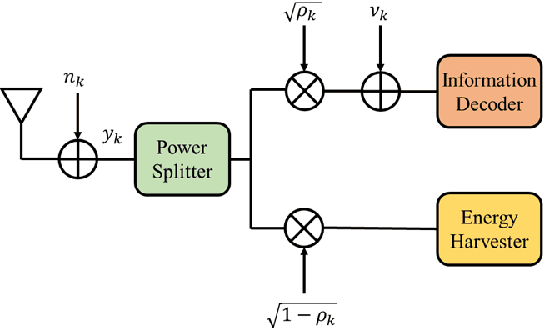
This study considers the Joint Transmit/Reflect Beamforming and Power Splitting (JTRBPS) optimization problem in a spectrum underlay setting, such that the transmit sum-energy of the intelligent reflecting surface (IRS)-aided secondary transmitter (ST) is minimized subject to the quality-of-service requirements of the PS-simultaneous wireless information and power transfer (SWIPT) secondary receivers and the interference constraints of the primary receivers (PR). The interference at the PRs caused by the reception of IRS-reflected signals sent by the primary transmitter is taken into account. A coordinated channel state information (CSI) acquisition protocol is proposed. Next, assuming availability at the ST of perfect CSI for all direct and IRS-cascaded transmitter--receiver channels, two penalty-based iterative algorithms are developed: an alternating minimization algorithm that involves semi-definite relaxation in JTBPS design and successive convex approximation in RB optimization, and a block coordinate descent algorithm that employs the Riemannian conjugate gradient algorithm in RB updates. Finally, an outage-constrained robust design under imperfect CSI is devised. Numerical simulations highlight the performance gains of the proposed strategies over benchmarks, corroborate the benefits of using an IRS, and provide valuable insights.
ShapeNet: Shape Constraint for Galaxy Image Deconvolution
Mar 14, 2022

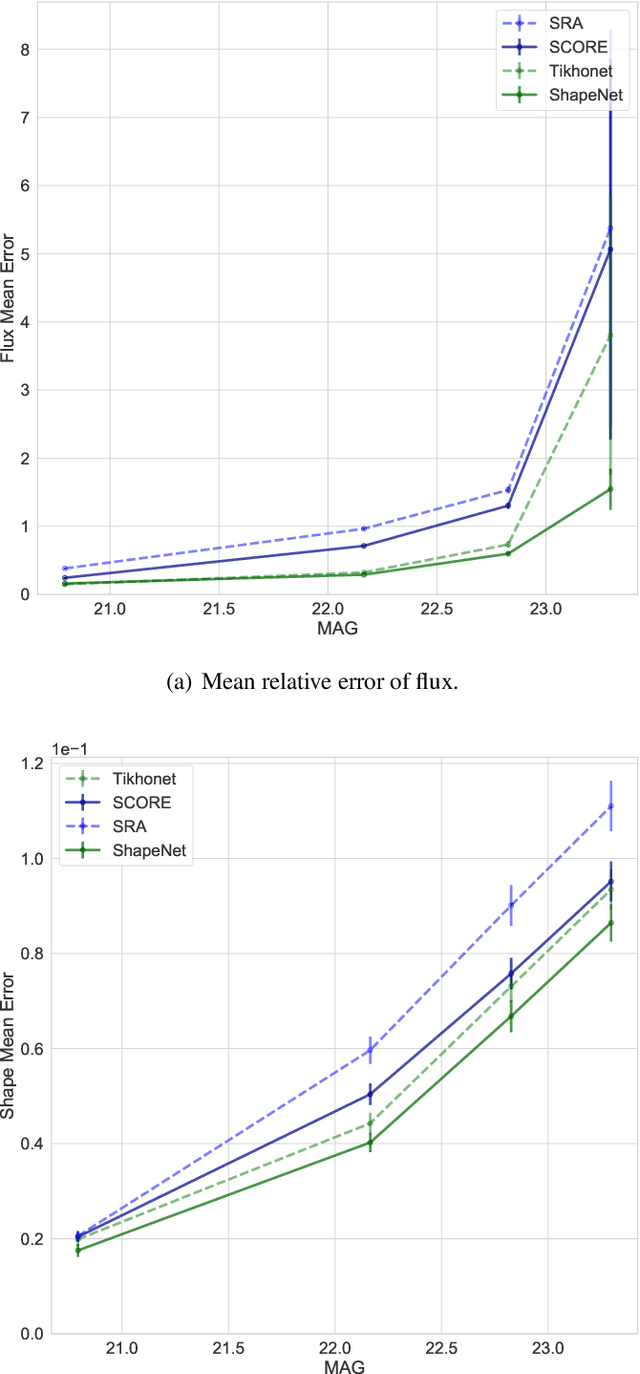
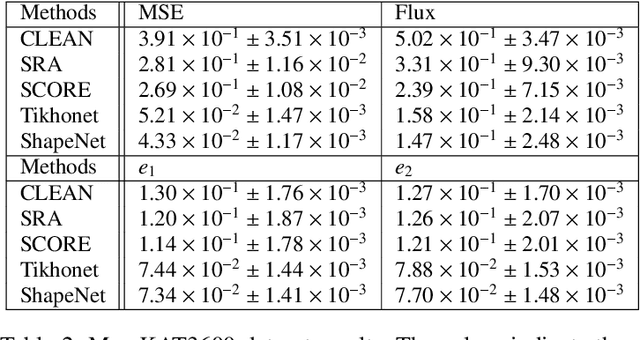
Deep Learning (DL) has shown remarkable results in solving inverse problems in various domains. In particular, the Tikhonet approach is very powerful to deconvolve optical astronomical images (Sureau et al. 2020). Yet, this approach only uses the $\ell_2$ loss, which does not guarantee the preservation of physical information (e.g. flux and shape) of the object reconstructed in the image. In Nammour et al. (2021), a new loss function was proposed in the framework of sparse deconvolution, which better preserves the shape of galaxies and reduces the pixel error. In this paper, we extend Tikhonet to take into account this shape constraint, and apply our new DL method, called ShapeNet, to optical and radio-interferometry simulated data set. The originality of the paper relies on i) the shape constraint we use in the neural network framework, ii) the application of deep learning to radio-interferometry image deconvolution for the first time, and iii) the generation of a simulated radio data set that we make available for the community. A range of examples illustrates the results.
RETE: Retrieval-Enhanced Temporal Event Forecasting on Unified Query Product Evolutionary Graph
Feb 12, 2022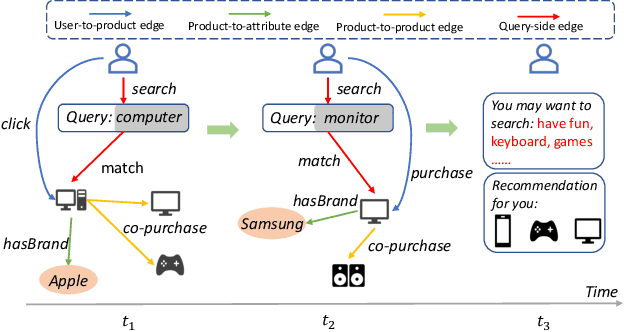
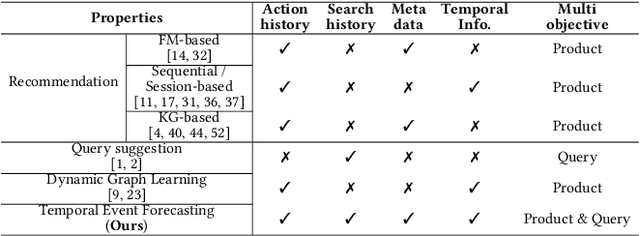
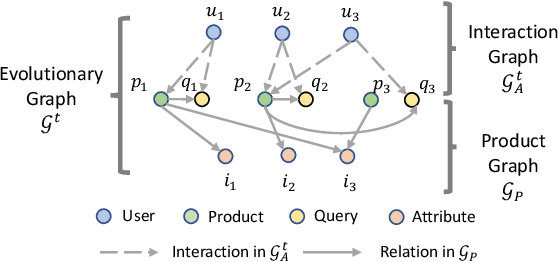
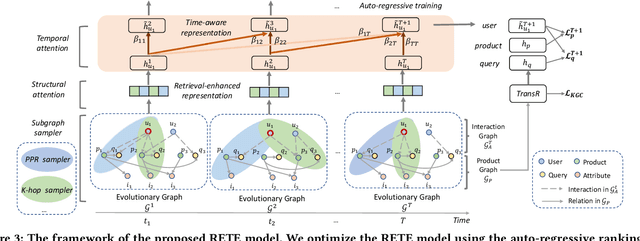
With the increasing demands on e-commerce platforms, numerous user action history is emerging. Those enriched action records are vital to understand users' interests and intents. Recently, prior works for user behavior prediction mainly focus on the interactions with product-side information. However, the interactions with search queries, which usually act as a bridge between users and products, are still under investigated. In this paper, we explore a new problem named temporal event forecasting, a generalized user behavior prediction task in a unified query product evolutionary graph, to embrace both query and product recommendation in a temporal manner. To fulfill this setting, there involves two challenges: (1) the action data for most users is scarce; (2) user preferences are dynamically evolving and shifting over time. To tackle those issues, we propose a novel Retrieval-Enhanced Temporal Event (RETE) forecasting framework. Unlike existing methods that enhance user representations via roughly absorbing information from connected entities in the whole graph, RETE efficiently and dynamically retrieves relevant entities centrally on each user as high-quality subgraphs, preventing the noise propagation from the densely evolutionary graph structures that incorporate abundant search queries. And meanwhile, RETE autoregressively accumulates retrieval-enhanced user representations from each time step, to capture evolutionary patterns for joint query and product prediction. Empirically, extensive experiments on both the public benchmark and four real-world industrial datasets demonstrate the effectiveness of the proposed RETE method.
Generalized Spectral Clustering for Directed and Undirected Graphs
Mar 14, 2022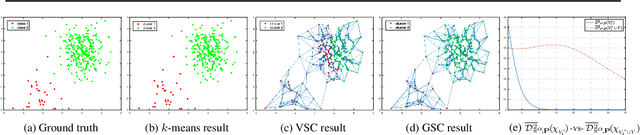
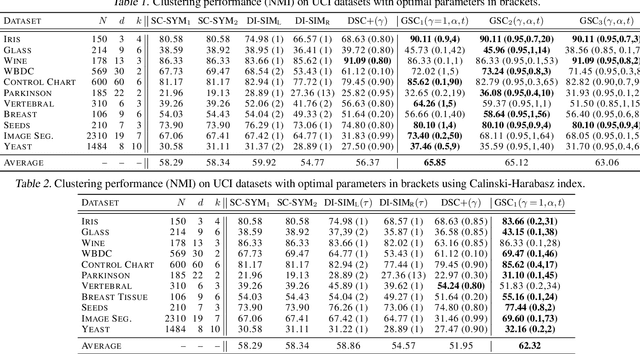
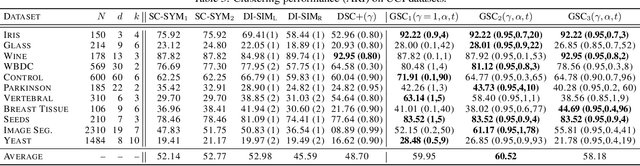
Spectral clustering is a popular approach for clustering undirected graphs, but its extension to directed graphs (digraphs) is much more challenging. A typical workaround is to naively symmetrize the adjacency matrix of the directed graph, which can however lead to discarding valuable information carried by edge directionality. In this paper, we present a generalized spectral clustering framework that can address both directed and undirected graphs. Our approach is based on the spectral relaxation of a new functional that we introduce as the generalized Dirichlet energy of a graph function, with respect to an arbitrary positive regularizing measure on the graph edges. We also propose a practical parametrization of the regularizing measure constructed from the iterated powers of the natural random walk on the graph. We present theoretical arguments to explain the efficiency of our framework in the challenging setting of unbalanced classes. Experiments using directed K-NN graphs constructed from real datasets show that our graph partitioning method performs consistently well in all cases, while outperforming existing approaches in most of them.
Teachable Reinforcement Learning via Advice Distillation
Mar 19, 2022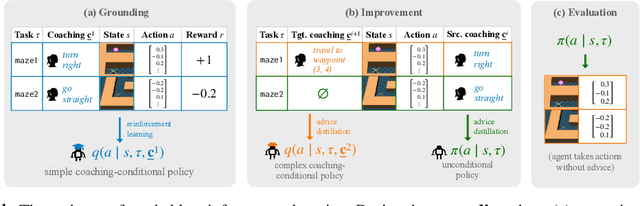
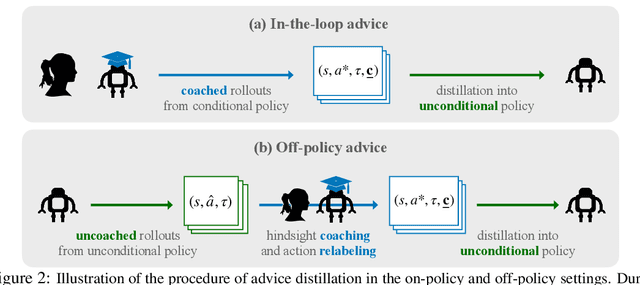
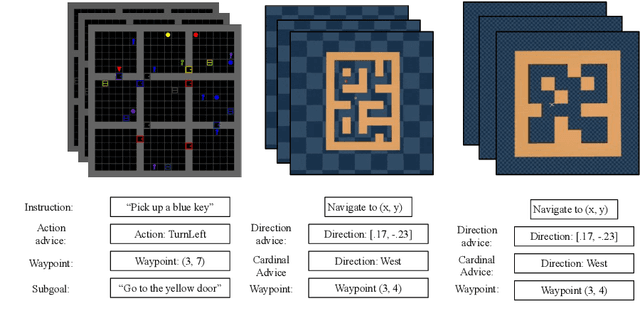
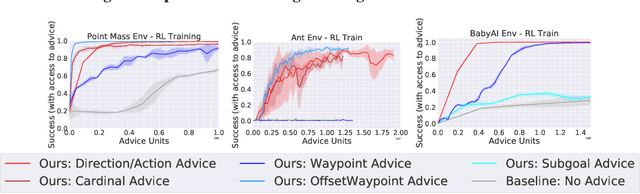
Training automated agents to complete complex tasks in interactive environments is challenging: reinforcement learning requires careful hand-engineering of reward functions, imitation learning requires specialized infrastructure and access to a human expert, and learning from intermediate forms of supervision (like binary preferences) is time-consuming and extracts little information from each human intervention. Can we overcome these challenges by building agents that learn from rich, interactive feedback instead? We propose a new supervision paradigm for interactive learning based on "teachable" decision-making systems that learn from structured advice provided by an external teacher. We begin by formalizing a class of human-in-the-loop decision making problems in which multiple forms of teacher-provided advice are available to a learner. We then describe a simple learning algorithm for these problems that first learns to interpret advice, then learns from advice to complete tasks even in the absence of human supervision. In puzzle-solving, navigation, and locomotion domains, we show that agents that learn from advice can acquire new skills with significantly less human supervision than standard reinforcement learning algorithms and often less than imitation learning.
MHTTS: Fast multi-head text-to-speech for spontaneous speech with imperfect transcription
Jan 19, 2022
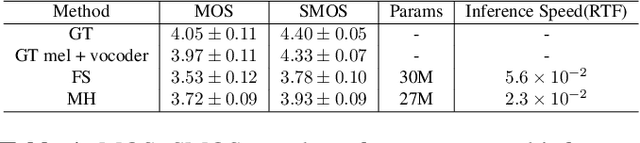
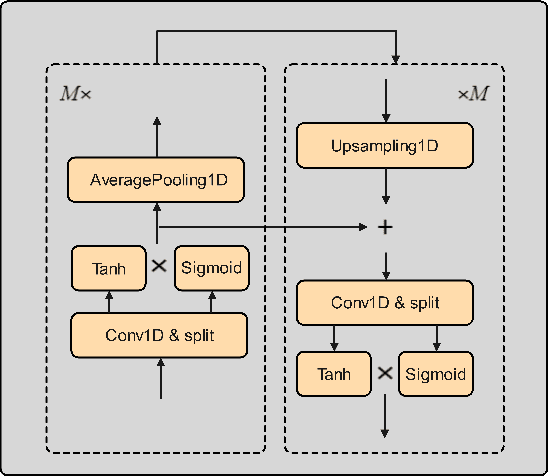
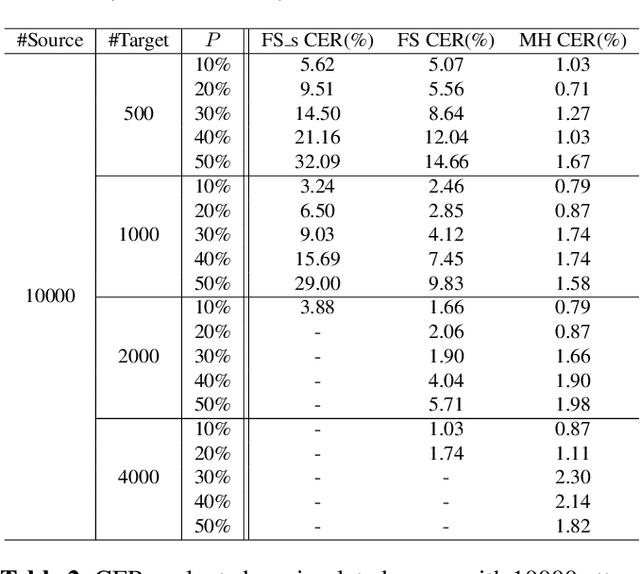
Neural network based end-to-end Text-to-Speech (TTS) has greatly improved the quality of synthesized speech. While how to use massive spontaneous speech without transcription efficiently still remains an open problem. In this paper, we propose MHTTS, a fast multi-speaker TTS system that is robust to transcription errors and speaking style speech data. Specifically, we introduce a multi-head model and transfer text information from high-quality corpus with manual transcription to spontaneous speech with imperfectly recognized transcription by jointly training them. MHTTS has three advantages: 1) Our system synthesizes better quality multi-speaker voice with faster inference speed. 2) Our system is capable of transferring correct text information to data with imperfect transcription, simulated using corruption, or provided by an Automatic Speech Recogniser (ASR). 3) Our system can utilize massive real spontaneous speech with imperfect transcription and synthesize expressive voice.
Decentralized Collaborative Learning Framework for Next POI Recommendation
Mar 30, 2022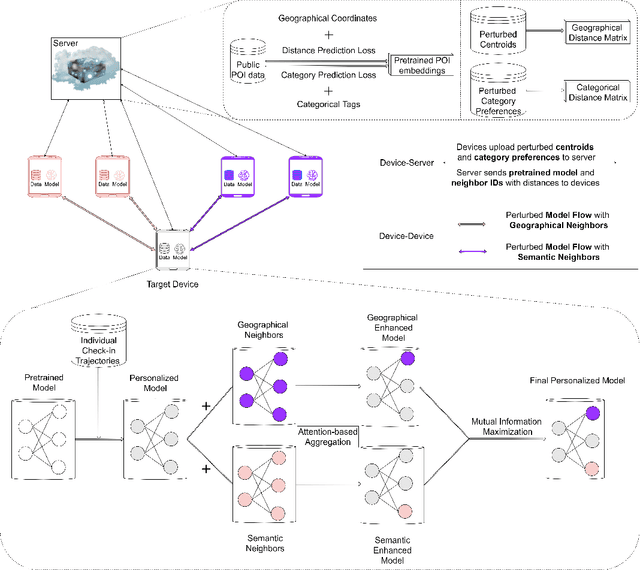
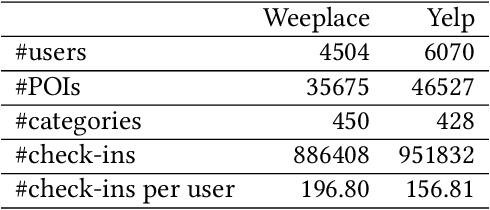
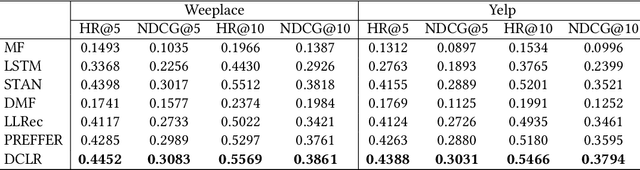
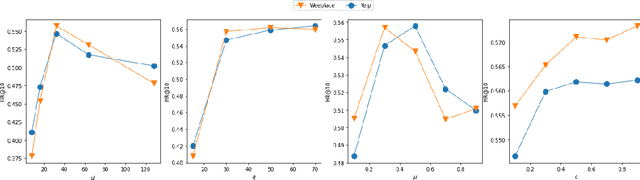
Next Point-of-Interest (POI) recommendation has become an indispensable functionality in Location-based Social Networks (LBSNs) due to its effectiveness in helping people decide the next POI to visit. However, accurate recommendation requires a vast amount of historical check-in data, thus threatening user privacy as the location-sensitive data needs to be handled by cloud servers. Although there have been several on-device frameworks for privacy-preserving POI recommendations, they are still resource-intensive when it comes to storage and computation, and show limited robustness to the high sparsity of user-POI interactions. On this basis, we propose a novel decentralized collaborative learning framework for POI recommendation (DCLR), which allows users to train their personalized models locally in a collaborative manner. DCLR significantly reduces the local models' dependence on the cloud for training, and can be used to expand arbitrary centralized recommendation models. To counteract the sparsity of on-device user data when learning each local model, we design two self-supervision signals to pretrain the POI representations on the server with geographical and categorical correlations of POIs. To facilitate collaborative learning, we innovatively propose to incorporate knowledge from either geographically or semantically similar users into each local model with attentive aggregation and mutual information maximization. The collaborative learning process makes use of communications between devices while requiring only minor engagement from the central server for identifying user groups, and is compatible with common privacy preservation mechanisms like differential privacy.