 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Empirical Investigation of 3D Anomaly Detection and Segmentation
Mar 10, 2022
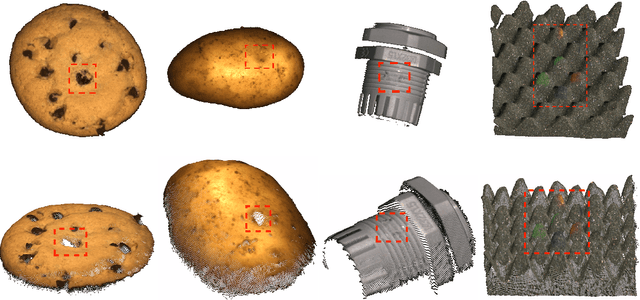

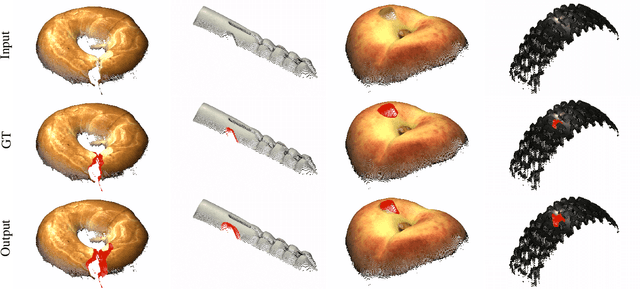
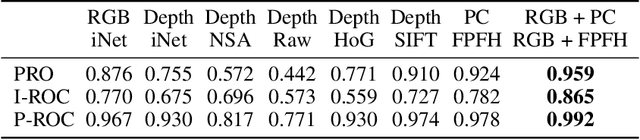
Anomaly detection and segmentation in images has made tremendous progress in recent years while 3D information has often been ignored. The objective of this paper is to further understand the benefit and role of 3D as opposed to color in image anomaly detection. Our study begins by presenting a surprising finding: standard color-only anomaly segmentation methods, when applied to 3D datasets, significantly outperform all current methods. On the other hand, we observe that color-only methods are insufficient for images containing geometric anomalies where shape cannot be unambiguously inferred from 2D. This suggests that better 3D methods are needed. We investigate different representations for 3D anomaly detection and discover that handcrafted orientation-invariant representations are unreasonably effective on this task. We uncover a simple 3D-only method that outperforms all recent approaches while not using deep learning, external pretraining datasets, or color information. As the 3D-only method cannot detect color and texture anomalies, we combine it with 2D color features, granting us the best current results by a large margin (Pixel-wise ROCAUC: 99.2%, PRO: 95.9% on MVTec 3D-AD). We conclude by discussing future challenges for 3D anomaly detection and segmentation.
Hyperbolic Neural Networks for Molecular Generation
Jan 30, 2022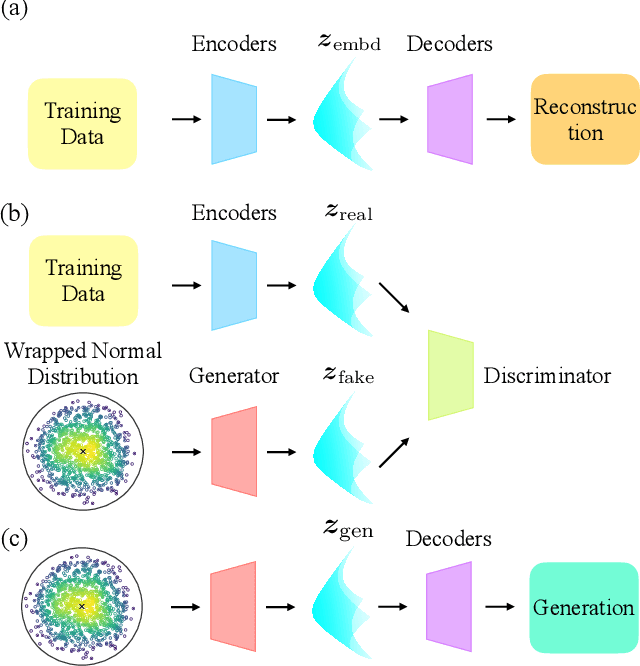
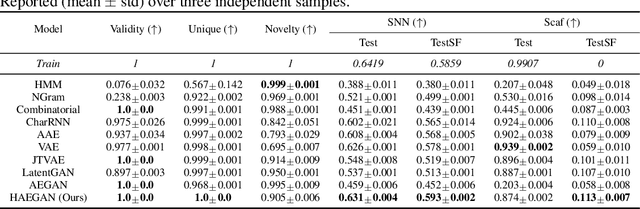
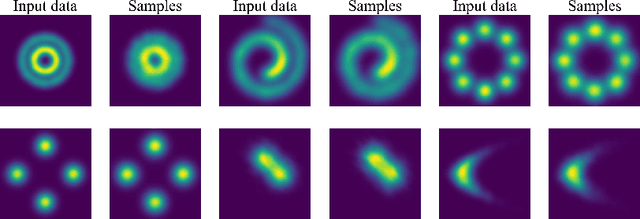

With the recent advance of deep learning, neural networks have been extensively used for the task of molecular generation. Many deep generators extract atomic relations from molecular graphs and ignore hierarchical information at both atom and molecule levels. In order to extract such hierarchical information, we propose a novel hyperbolic generative model. Our model contains three parts: first, a fully hyperbolic junction-tree encoder-decoder that embeds the hierarchical information of the molecules in the latent hyperbolic space; second, a latent generative adversarial network for generating the latent embeddings; third, a molecular generator that inherits the decoders from the first part and the latent generator from the second part. We evaluate our model on the ZINC dataset using the MOSES benchmarking platform and achieve competitive results, especially in metrics about structural similarity.
Automated Audio Captioning using Audio Event Clues
Apr 18, 2022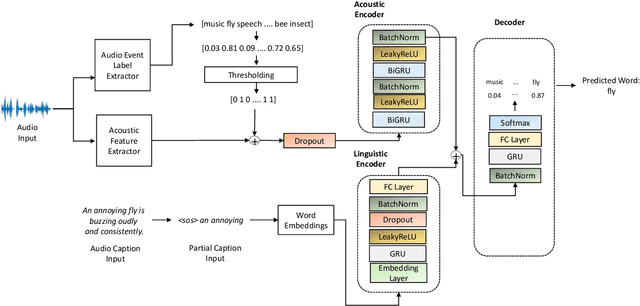
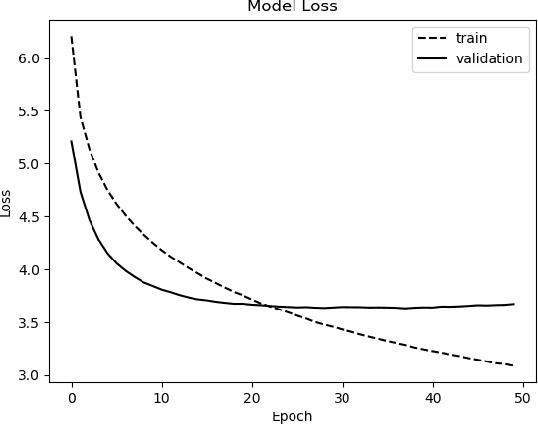
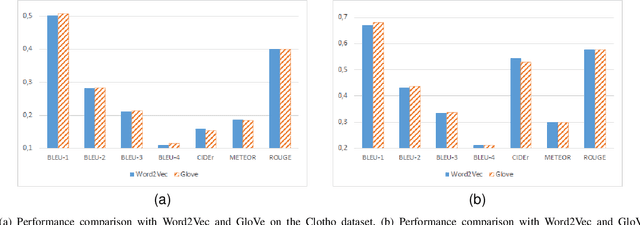

Audio captioning is an important research area that aims to generate meaningful descriptions for audio clips. Most of the existing research extracts acoustic features of audio clips as input to encoder-decoder and transformer architectures to produce the captions in a sequence-to-sequence manner. Due to data insufficiency and the architecture's inadequate learning capacity, additional information is needed to generate natural language sentences, as well as acoustic features. To address these problems, an encoder-decoder architecture is proposed that learns from both acoustic features and extracted audio event labels as inputs. The proposed model is based on pre-trained acoustic features and audio event detection. Various experiments used different acoustic features, word embedding models, audio event label extraction methods, and implementation configurations to show which combinations have better performance on the audio captioning task. Results of the extensive experiments on multiple datasets show that using audio event labels with the acoustic features improves the recognition performance and the proposed method either outperforms or achieves competitive results with the state-of-the-art models.
GCFSR: a Generative and Controllable Face Super Resolution Method Without Facial and GAN Priors
Mar 14, 2022
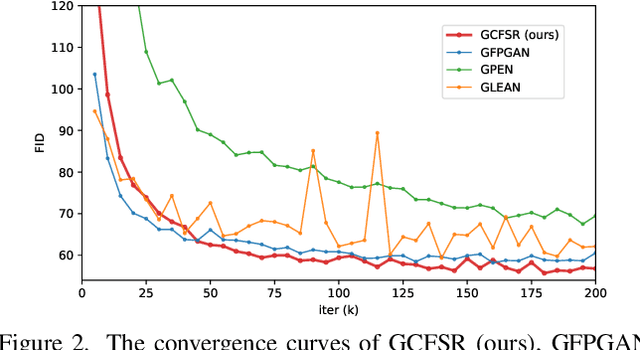

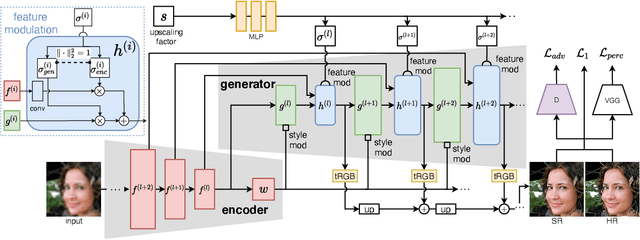
Face image super resolution (face hallucination) usually relies on facial priors to restore realistic details and preserve identity information. Recent advances can achieve impressive results with the help of GAN prior. They either design complicated modules to modify the fixed GAN prior or adopt complex training strategies to finetune the generator. In this work, we propose a generative and controllable face SR framework, called GCFSR, which can reconstruct images with faithful identity information without any additional priors. Generally, GCFSR has an encoder-generator architecture. Two modules called style modulation and feature modulation are designed for the multi-factor SR task. The style modulation aims to generate realistic face details and the feature modulation dynamically fuses the multi-level encoded features and the generated ones conditioned on the upscaling factor. The simple and elegant architecture can be trained from scratch in an end-to-end manner. For small upscaling factors (<=8), GCFSR can produce surprisingly good results with only adversarial loss. After adding L1 and perceptual losses, GCFSR can outperform state-of-the-art methods for large upscaling factors (16, 32, 64). During the test phase, we can modulate the generative strength via feature modulation by changing the conditional upscaling factor continuously to achieve various generative effects.
Counterfactual Learning To Rank for Utility-Maximizing Query Autocompletion
Apr 22, 2022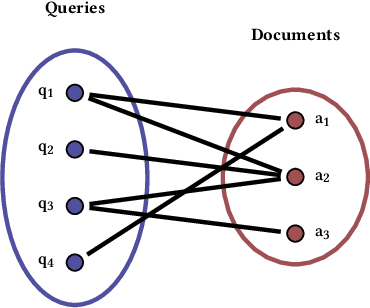

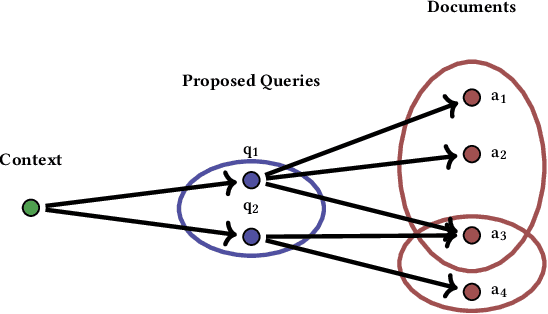
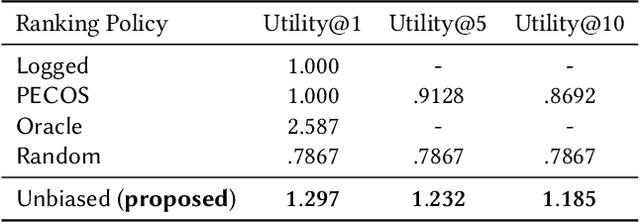
Conventional methods for query autocompletion aim to predict which completed query a user will select from a list. A shortcoming of this approach is that users often do not know which query will provide the best retrieval performance on the current information retrieval system, meaning that any query autocompletion methods trained to mimic user behavior can lead to suboptimal query suggestions. To overcome this limitation, we propose a new approach that explicitly optimizes the query suggestions for downstream retrieval performance. We formulate this as a problem of ranking a set of rankings, where each query suggestion is represented by the downstream item ranking it produces. We then present a learning method that ranks query suggestions by the quality of their item rankings. The algorithm is based on a counterfactual learning approach that is able to leverage feedback on the items (e.g., clicks, purchases) to evaluate query suggestions through an unbiased estimator, thus avoiding the assumption that users write or select optimal queries. We establish theoretical support for the proposed approach and provide learning-theoretic guarantees. We also present empirical results on publicly available datasets, and demonstrate real-world applicability using data from an online shopping store.
Exploiting Temporal Relations on Radar Perception for Autonomous Driving
Apr 03, 2022
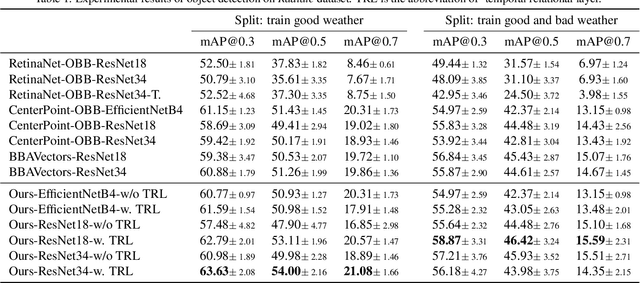
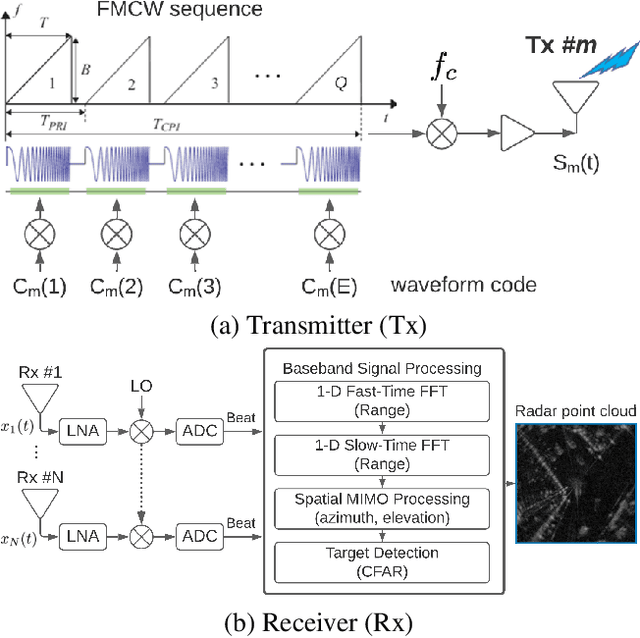

We consider the object recognition problem in autonomous driving using automotive radar sensors. Comparing to Lidar sensors, radar is cost-effective and robust in all-weather conditions for perception in autonomous driving. However, radar signals suffer from low angular resolution and precision in recognizing surrounding objects. To enhance the capacity of automotive radar, in this work, we exploit the temporal information from successive ego-centric bird-eye-view radar image frames for radar object recognition. We leverage the consistency of an object's existence and attributes (size, orientation, etc.), and propose a temporal relational layer to explicitly model the relations between objects within successive radar images. In both object detection and multiple object tracking, we show the superiority of our method compared to several baseline approaches.
Augmenting Neural Networks with Priors on Function Values
Feb 10, 2022



The need for function estimation in label-limited settings is common in the natural sciences. At the same time, prior knowledge of function values is often available in these domains. For example, data-free biophysics-based models can be informative on protein properties, while quantum-based computations can be informative on small molecule properties. How can we coherently leverage such prior knowledge to help improve a neural network model that is quite accurate in some regions of input space -- typically near the training data -- but wildly wrong in other regions? Bayesian neural networks (BNN) enable the user to specify prior information only on the neural network weights, not directly on the function values. Moreover, there is in general no clear mapping between these. Herein, we tackle this problem by developing an approach to augment BNNs with prior information on the function values themselves. Our probabilistic approach yields predictions that rely more heavily on the prior information when the epistemic uncertainty is large, and more heavily on the neural network when the epistemic uncertainty is small.
OpenHoldem: An Open Toolkit for Large-Scale Imperfect-Information Game Research
Dec 11, 2020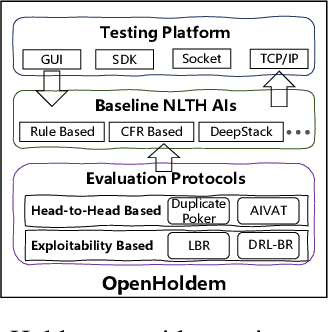


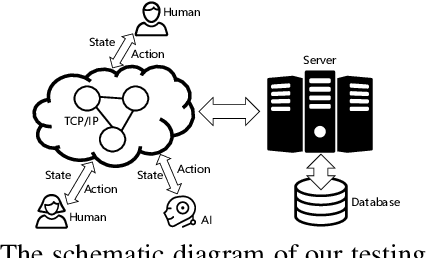
Owning to the unremitting efforts by a few institutes, significant progress has recently been made in designing superhuman AIs in No-limit Texas Hold'em (NLTH), the primary testbed for large-scale imperfect-information game research. However, it remains challenging for new researchers to study this problem since there are no standard benchmarks for comparing with existing methods, which seriously hinders further developments in this research area. In this work, we present OpenHoldem, an integrated toolkit for large-scale imperfect-information game research using NLTH. OpenHoldem makes three main contributions to this research direction: 1) a standardized evaluation protocol for thoroughly evaluating different NLTH AIs, 2) three publicly available strong baselines for NLTH AI, and 3) an online testing platform with easy-to-use APIs for public NLTH AI evaluation. We have released OpenHoldem at http://holdem.ia.ac.cn/, hoping it facilitates further studies on the unsolved theoretical and computational issues in this area and cultivate crucial research problems like opponent modeling, large-scale equilibrium-finding, and human-computer interactive learning.
Real-Time Limited-View CT Inpainting and Reconstruction with Dual Domain Based on Spatial Information
Jan 19, 2021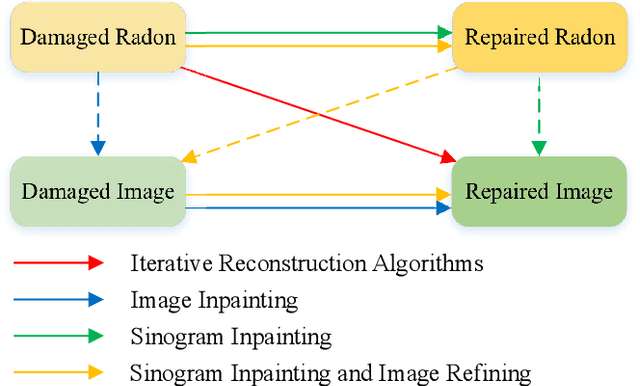
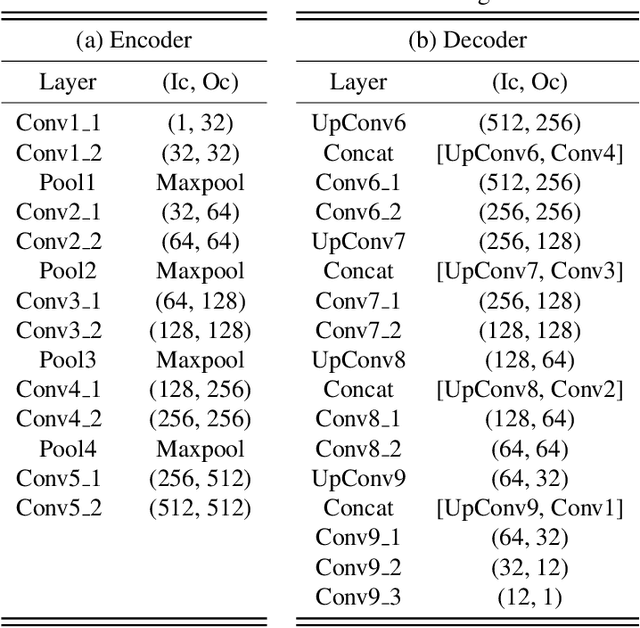
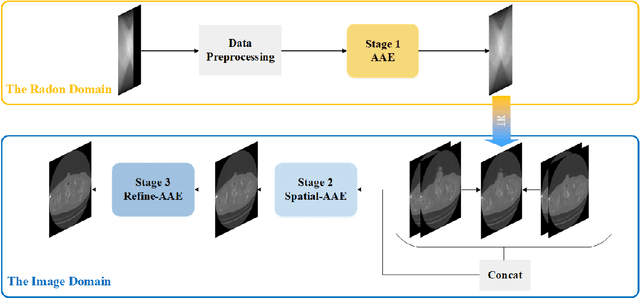
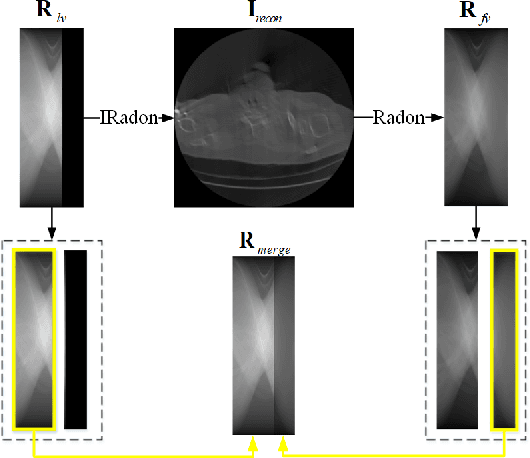
Low-dose Computed Tomography is a common issue in reality. Current reduction, sparse sampling and limited-view scanning can all cause it. Between them, limited-view CT is general in the industry due to inevitable mechanical and physical limitation. However, limited-view CT can cause serious imaging problem on account of its massive information loss. Thus, we should effectively utilize the scant prior information to perform completion. It is an undeniable fact that CT imaging slices are extremely dense, which leads to high continuity between successive images. We realized that fully exploit the spatial correlation between consecutive frames can significantly improve restoration results in video inpainting. Inspired by this, we propose a deep learning-based three-stage algorithm that hoist limited-view CT imaging quality based on spatial information. In stage one, to better utilize prior information in the Radon domain, we design an adversarial autoencoder to complement the Radon data. In the second stage, a model is built to perform inpainting based on spatial continuity in the image domain. At this point, we have roughly restored the imaging, while its texture still needs to be finely repaired. Hence, we propose a model to accurately restore the image in stage three, and finally achieve an ideal inpainting result. In addition, we adopt FBP instead of SART-TV to make our algorithm more suitable for real-time use. In the experiment, we restore and reconstruct the Radon data that has been cut the rear one-third part, they achieve PSNR of 40.209, SSIM of 0.943, while precisely present the texture.
Learning 6-DoF Object Poses to Grasp Category-level Objects by Language Instructions
May 09, 2022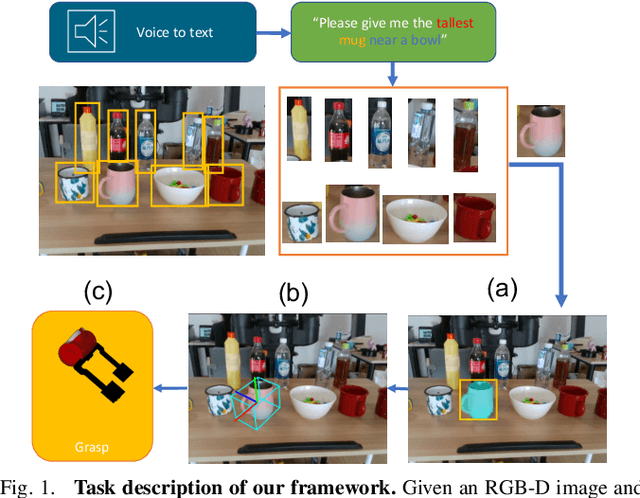

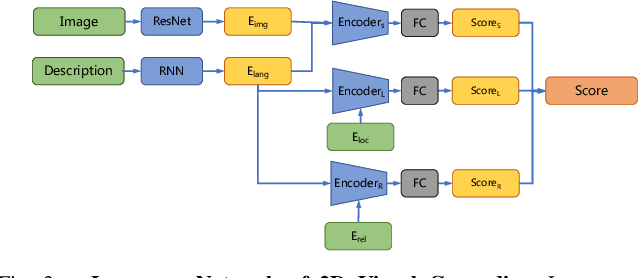

This paper studies the task of any objects grasping from the known categories by free-form language instructions. This task demands the technique in computer vision, natural language processing, and robotics. We bring these disciplines together on this open challenge, which is essential to human-robot interaction. Critically, the key challenge lies in inferring the category of objects from linguistic instructions and accurately estimating the 6-DoF information of unseen objects from the known classes. In contrast, previous works focus on inferring the pose of object candidates at the instance level. This significantly limits its applications in real-world scenarios.In this paper, we propose a language-guided 6-DoF category-level object localization model to achieve robotic grasping by comprehending human intention. To this end, we propose a novel two-stage method. Particularly, the first stage grounds the target in the RGB image through language description of names, attributes, and spatial relations of objects. The second stage extracts and segments point clouds from the cropped depth image and estimates the full 6-DoF object pose at category-level. Under such a manner, our approach can locate the specific object by following human instructions, and estimate the full 6-DoF pose of a category-known but unseen instance which is not utilized for training the model. Extensive experimental results show that our method is competitive with the state-of-the-art language-conditioned grasp method. Importantly, we deploy our approach on a physical robot to validate the usability of our framework in real-world applications. Please refer to the supplementary for the demo videos of our robot experiments.