 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fourier Document Restoration for Robust Document Dewarping and Recognition
Mar 18, 2022

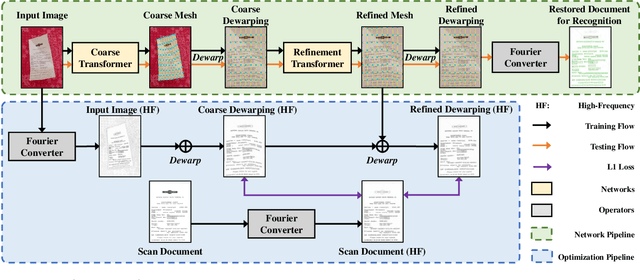
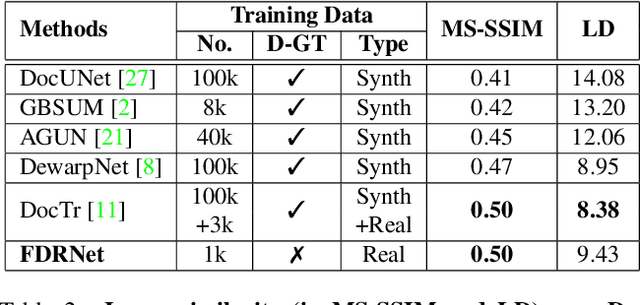
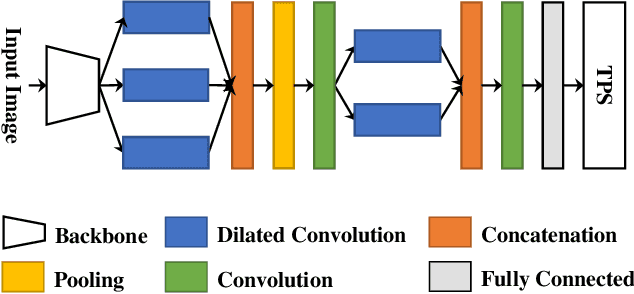
State-of-the-art document dewarping techniques learn to predict 3-dimensional information of documents which are prone to errors while dealing with documents with irregular distortions or large variations in depth. This paper presents FDRNet, a Fourier Document Restoration Network that can restore documents with different distortions and improve document recognition in a reliable and simpler manner. FDRNet focuses on high-frequency components in the Fourier space that capture most structural information but are largely free of degradation in appearance. It dewarps documents by a flexible Thin-Plate Spline transformation which can handle various deformations effectively without requiring deformation annotations in training. These features allow FDRNet to learn from a small amount of simply labeled training images, and the learned model can dewarp documents with complex geometric distortion and recognize the restored texts accurately. To facilitate document restoration research, we create a benchmark dataset consisting of over one thousand camera documents with different types of geometric and photometric distortion. Extensive experiments show that FDRNet outperforms the state-of-the-art by large margins on both dewarping and text recognition tasks. In addition, FDRNet requires a small amount of simply labeled training data and is easy to deploy.
Show Me What and Tell Me How: Video Synthesis via Multimodal Conditioning
Mar 04, 2022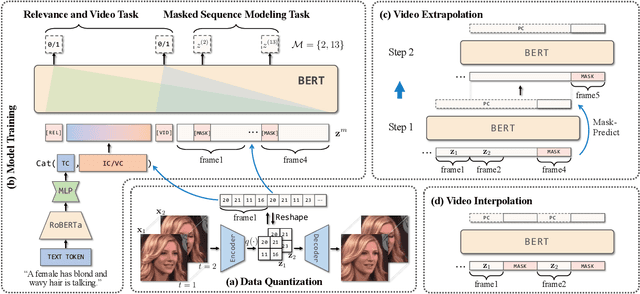
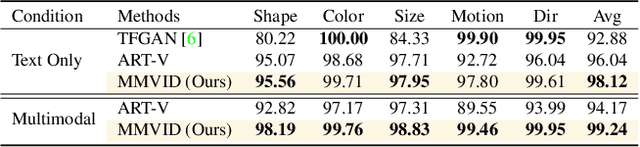


Most methods for conditional video synthesis use a single modality as the condition. This comes with major limitations. For example, it is problematic for a model conditioned on an image to generate a specific motion trajectory desired by the user since there is no means to provide motion information. Conversely, language information can describe the desired motion, while not precisely defining the content of the video. This work presents a multimodal video generation framework that benefits from text and images provided jointly or separately. We leverage the recent progress in quantized representations for videos and apply a bidirectional transformer with multiple modalities as inputs to predict a discrete video representation. To improve video quality and consistency, we propose a new video token trained with self-learning and an improved mask-prediction algorithm for sampling video tokens. We introduce text augmentation to improve the robustness of the textual representation and diversity of generated videos. Our framework can incorporate various visual modalities, such as segmentation masks, drawings, and partially occluded images. It can generate much longer sequences than the one used for training. In addition, our model can extract visual information as suggested by the text prompt, e.g., "an object in image one is moving northeast", and generate corresponding videos. We run evaluations on three public datasets and a newly collected dataset labeled with facial attributes, achieving state-of-the-art generation results on all four.
Identifying Scenarios in Field Data to Enable Validation of Highly Automated Driving Systems
Mar 09, 2022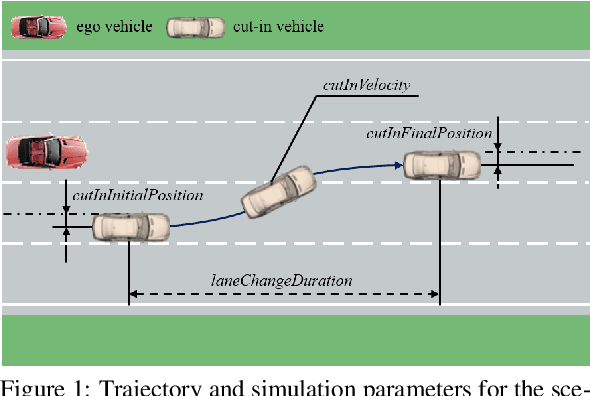
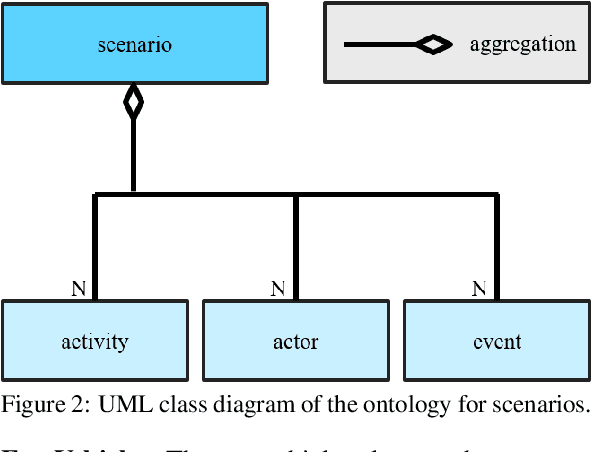

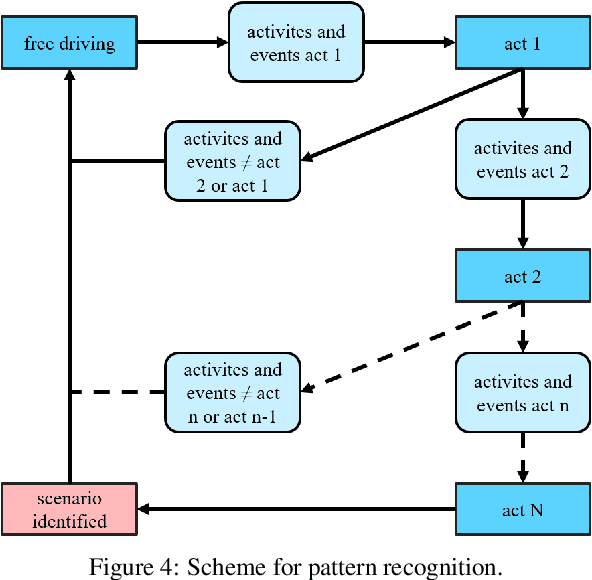
Scenario-based approaches for the validation of highly automated driving functions are based on the search for safety-critical characteristics of driving scenarios using software-in-the-loop simulations. This search requires information about the shape and probability of scenarios in real-world traffic. The scope of this work is to develop a method that identifies redefined logical driving scenarios in field data, so that this information can be derived subsequently. More precisely, a suitable approach is developed, implemented and validated using a traffic scenario as an example. The presented methodology is based on qualitative modelling of scenarios, which can be detected in abstracted field data. The abstraction is achieved by using universal elements of an ontology represented by a domain model. Already published approaches for such an abstraction are discussed and concretised with regard to the given application. By examining a first set of test data, it is shown that the developed method is a suitable approach for the identification of further driving scenarios.
nigam@COLIEE-22: Legal Case Retrieval and Entailment using Cascading of Lexical and Semantic-based models
Apr 16, 2022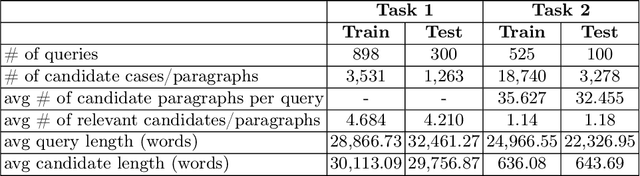
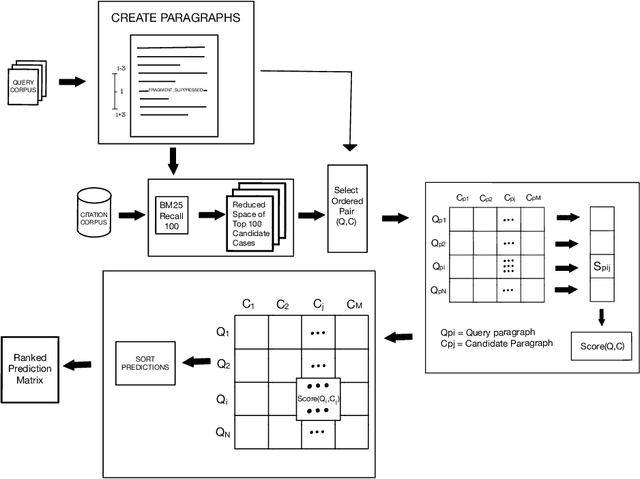
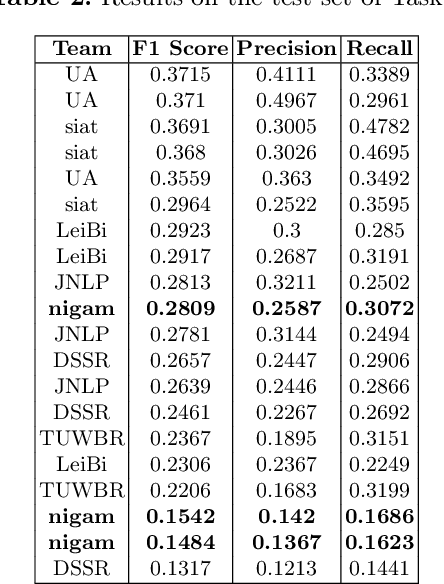
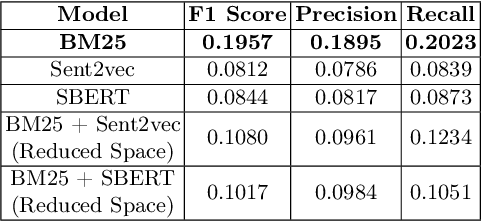
This paper describes our submission to the Competition on Legal Information Extraction/Entailment 2022 (COLIEE-2022) workshop on case law competition for tasks 1 and 2. Task 1 is a legal case retrieval task, which involves reading a new case and extracting supporting cases from the provided case law corpus to support the decision. Task 2 is the legal case entailment task, which involves the identification of a paragraph from existing cases that entails the decision in a relevant case. We employed the neural models Sentence-BERT and Sent2Vec for semantic understanding and the traditional retrieval model BM25 for exact matching in both tasks. As a result, our team ("nigam") ranked 5th among all the teams in Tasks 1 and 2. Experimental results indicate that the traditional retrieval model BM25 still outperforms neural network-based models.
I Can Read Your Mind: Control Mechanism Secrecy of Networked Dynamical Systems under Inference Attacks
May 07, 2022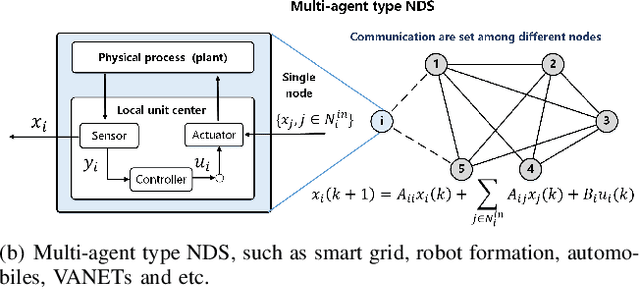
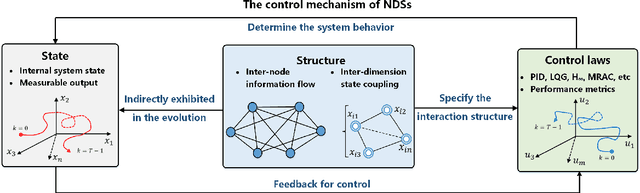

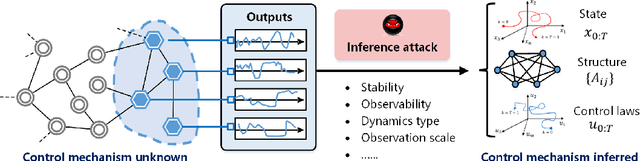
Recent years have witnessed the fast advance of security research for networked dynamical system (NDS). Considering the latest inference attacks that enable stealthy and precise attacks into NDSs with observation-based learning, this article focuses on a new security aspect, i.e., how to protect control mechanism secrets from inference attacks, including state information, interaction structure and control laws. We call this security property as control mechanism secrecy, which provides protection of the vulnerabilities in the control process and fills the defense gap that traditional cyber security cannot handle. Since the knowledge of control mechanism defines the capabilities to implement attacks, ensuring control mechanism secrecy needs to go beyond the conventional data privacy to cover both transmissible data and intrinsic models in NDSs. The prime goal of this article is to summarize recent results of both inference attacks on control mechanism secrets and countermeasures. We first introduce the basic inference attack methods on the state and structure of NDSs, respectively, along with their inference performance bounds. Then, the corresponding countermeasures and performance metrics are given to illustrate how to preserve the control mechanism secrecy. Necessary conditions are derived to guide the secrecy design. Finally, thorough discussions on the control laws and open issues are presented, beckoning future investigation on reliable countermeasure design and tradeoffs between the secrecy and control performance.
Domain Invariant Masked Autoencoders for Self-supervised Learning from Multi-domains
May 10, 2022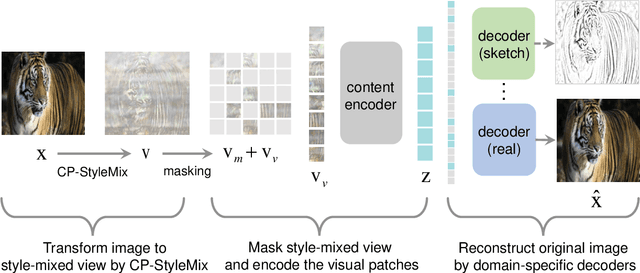
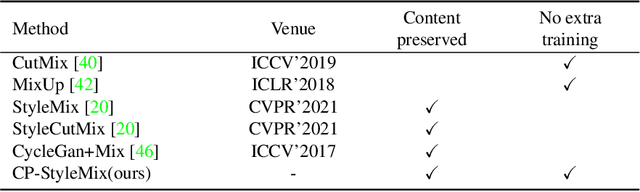

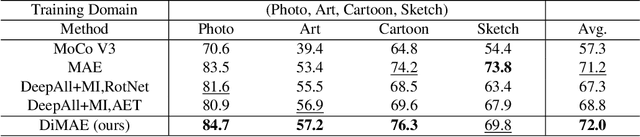
Generalizing learned representations across significantly different visual domains is a fundamental yet crucial ability of the human visual system. While recent self-supervised learning methods have achieved good performances with evaluation set on the same domain as the training set, they will have an undesirable performance decrease when tested on a different domain. Therefore, the self-supervised learning from multiple domains task is proposed to learn domain-invariant features that are not only suitable for evaluation on the same domain as the training set but also can be generalized to unseen domains. In this paper, we propose a Domain-invariant Masked AutoEncoder (DiMAE) for self-supervised learning from multi-domains, which designs a new pretext task, \emph{i.e.,} the cross-domain reconstruction task, to learn domain-invariant features. The core idea is to augment the input image with style noise from different domains and then reconstruct the image from the embedding of the augmented image, regularizing the encoder to learn domain-invariant features. To accomplish the idea, DiMAE contains two critical designs, 1) content-preserved style mix, which adds style information from other domains to input while persevering the content in a parameter-free manner, and 2) multiple domain-specific decoders, which recovers the corresponding domain style of input to the encoded domain-invariant features for reconstruction. Experiments on PACS and DomainNet illustrate that DiMAE achieves considerable gains compared with recent state-of-the-art methods.
VesNet-RL: Simulation-based Reinforcement Learning for Real-World US Probe Navigation
May 10, 2022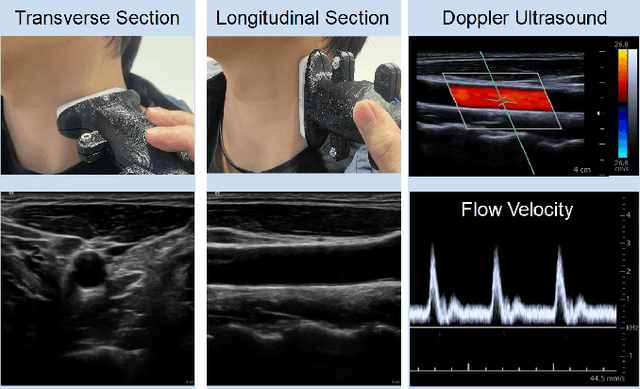
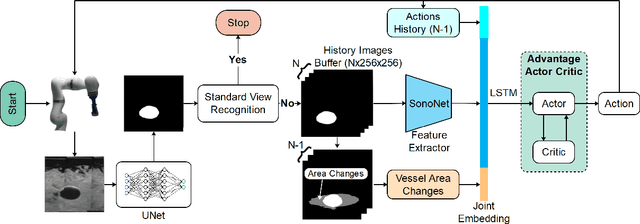
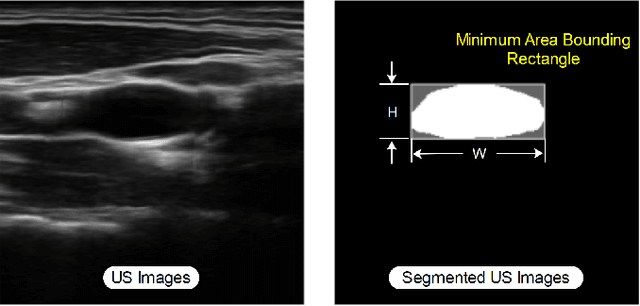
Ultrasound (US) is one of the most common medical imaging modalities since it is radiation-free, low-cost, and real-time. In freehand US examinations, sonographers often navigate a US probe to visualize standard examination planes with rich diagnostic information. However, reproducibility and stability of the resulting images often suffer from intra- and inter-operator variation. Reinforcement learning (RL), as an interaction-based learning method, has demonstrated its effectiveness in visual navigating tasks; however, RL is limited in terms of generalization. To address this challenge, we propose a simulation-based RL framework for real-world navigation of US probes towards the standard longitudinal views of vessels. A UNet is used to provide binary masks from US images; thereby, the RL agent trained on simulated binary vessel images can be applied in real scenarios without further training. To accurately characterize actual states, a multi-modality state representation structure is introduced to facilitate the understanding of environments. Moreover, considering the characteristics of vessels, a novel standard view recognition approach based on the minimum bounding rectangle is proposed to terminate the searching process. To evaluate the effectiveness of the proposed method, the trained policy is validated virtually on 3D volumes of a volunteer's in-vivo carotid artery, and physically on custom-designed gel phantoms using robotic US. The results demonstrate that proposed approach can effectively and accurately navigate the probe towards the longitudinal view of vessels.
Gaussian Process Self-triggered Policy Search in Weakly Observable Environments
May 07, 2022
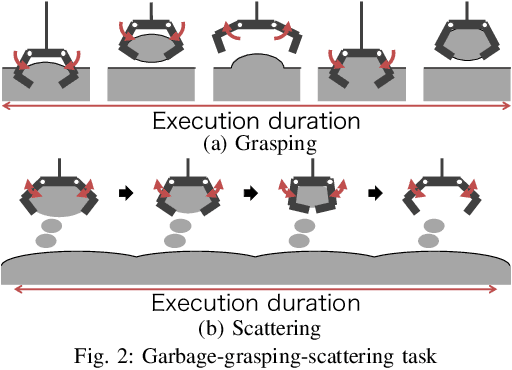
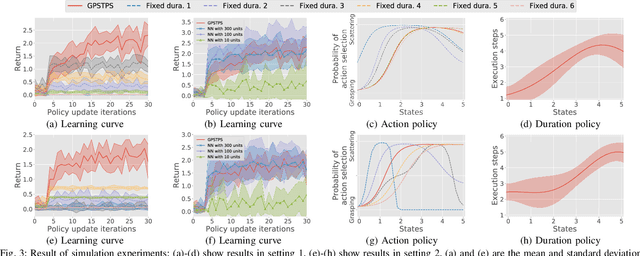

The environments of such large industrial machines as waste cranes in waste incineration plants are often weakly observable, where little information about the environmental state is contained in the observations due to technical difficulty or maintenance cost (e.g., no sensors for observing the state of the garbage to be handled). Based on the findings that skilled operators in such environments choose predetermined control strategies (e.g., grasping and scattering) and their durations based on sensor values, %thereby improving the robustness of their actions, we propose a novel non-parametric policy search algorithm: Gaussian process self-triggered policy search (GPSTPS). GPSTPS has two types of control policies: action and duration. A gating mechanism either maintains the action selected by the action policy for the duration specified by the duration policy or updates the action and duration by passing new observations to the policy; therefore, it is categorized as self-triggered. GPSTPS simultaneously learns both policies by trial and error based on sparse GP priors and variational learning to maximize the return. To verify the performance of our proposed method, we conducted experiments on garbage-grasping-scattering task for a waste crane with weak observations using a simulation and a robotic waste crane system. As experimental results, the proposed method acquired suitable policies to determine the action and duration based on the garbage's characteristics.
Viko 2.0: A Hierarchical Gecko-inspired Adhesive Gripper with Visuotactile Sensor
Apr 21, 2022
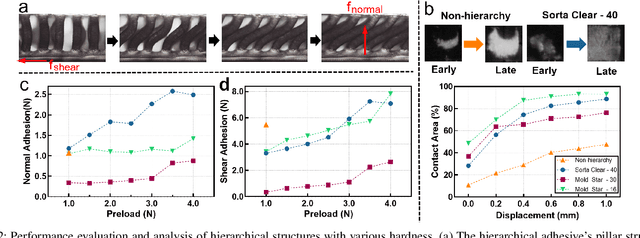
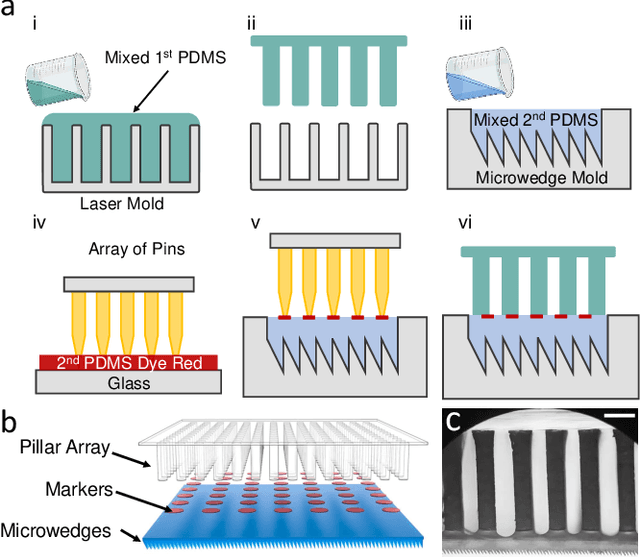
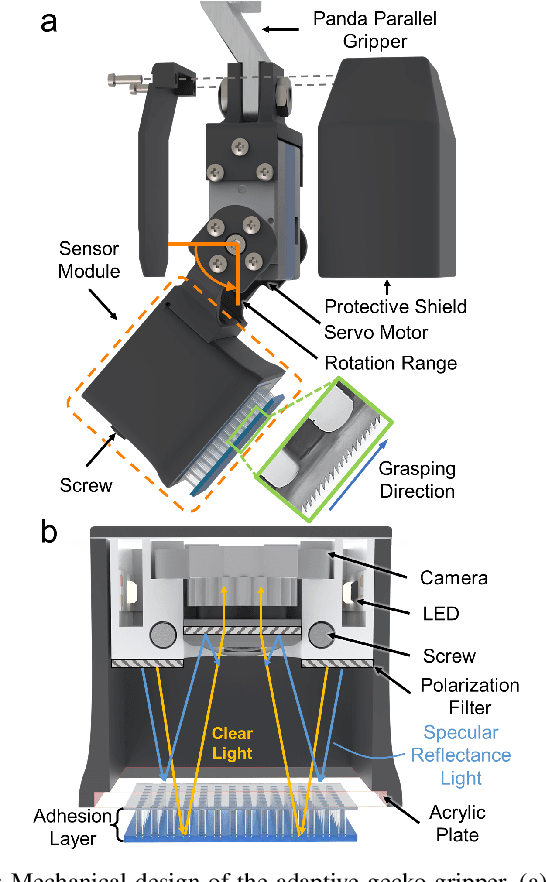
Robotic grippers with visuotactile sensors have access to rich tactile information for grasping tasks but encounter difficulty in partially encompassing large objects with sufficient grip force. While hierarchical gecko-inspired adhesives are a potential technique for bridging performance gaps, they require a large contact area for efficient usage. In this work, we present a new version of an adaptive gecko gripper called Viko 2.0 that effectively combines the advantage of adhesives and visuotactile sensors. Compared with a non-hierarchical structure, a hierarchical structure with a multimaterial design achieves approximately a 1.5 times increase in normal adhesion and double in contact area. The integrated visuotactile sensor captures a deformation image of the hierarchical structure and provides a real-time measurement of contact area, shear force, and incipient slip detection at 24 Hz. The gripper is implemented on a robotic arm to demonstrate an adaptive grasping pose based on contact area, and grasps objects with a wide range of geometries and textures.
BronchoPose: an analysis of data and model configuration for vision-based bronchoscopy pose estimation
Apr 25, 2022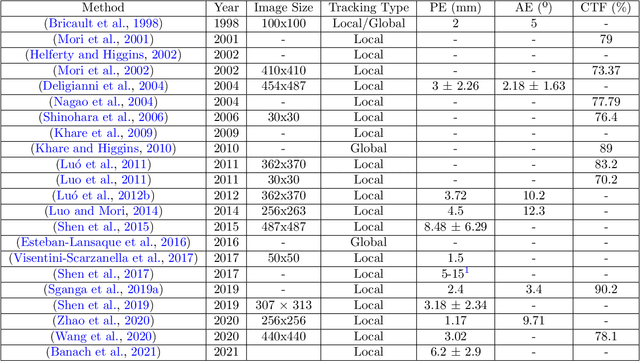
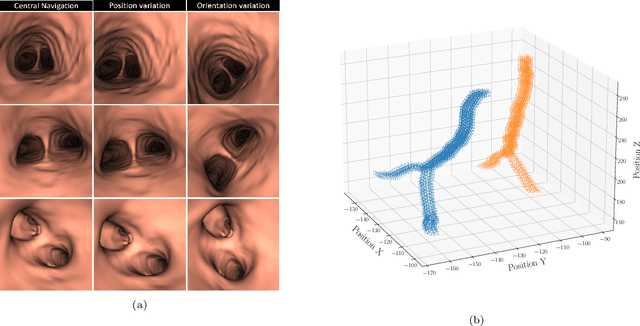
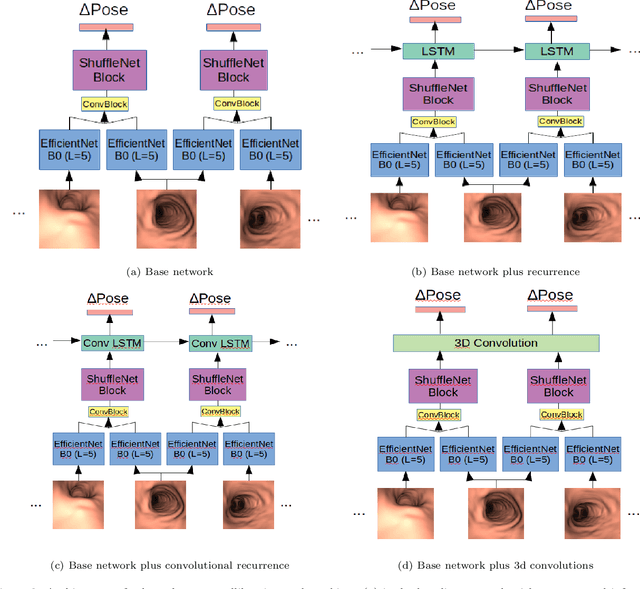
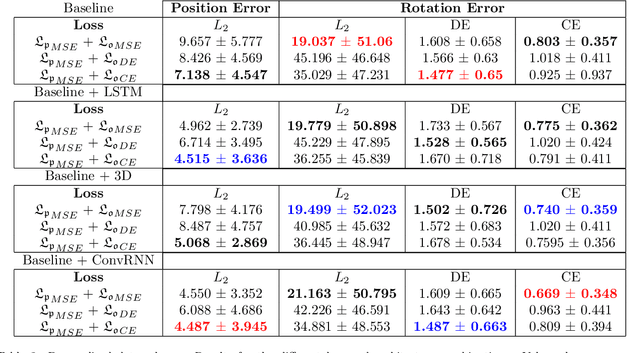
Vision-based bronchoscopy (VB) models require the registration of the virtual lung model with the frames from the video bronchoscopy to provide effective guidance during the biopsy. The registration can be achieved by either tracking the position and orientation of the bronchoscopy camera or by calibrating its deviation from the pose (position and orientation) simulated in the virtual lung model. Recent advances in neural networks and temporal image processing have provided new opportunities for guided bronchoscopy. However, such progress has been hindered by the lack of comparative experimental conditions. In the present paper, we share a novel synthetic dataset allowing for a fair comparison of methods. Moreover, this paper investigates several neural network architectures for the learning of temporal information at different levels of subject personalization. In order to improve orientation measurement, we also present a standardized comparison framework and a novel metric for camera orientation learning. Results on the dataset show that the proposed metric and architectures, as well as the standardized conditions, provide notable improvements to current state-of-the-art camera pose estimation in video bronchoscopy.