 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeRun: Enabling Determinism in LLM Planning for Running
Jun 08, 2026Large Language Models enable flexible natural-language planning but remain unreliable in determinism-critical domains due to their probabilistic nature. This limitation is especially problematic in running planning, where violating safety rules can lead to safety risks. We propose SafeRun, a framework for deterministic LLM-based planning via a decoupled architecture. SafeRun separates soft interpretation by an LLM from hard constraint enforcement by a deterministic solver, ensuring strict safety constraints while preserving natural-language flexibility. To validate SafeRun, we build a comprehensive benchmark for running planning under realistic physiological and safety constraints. Experiments across five LLMs show that SafeRun achieves 100\% safety score (vs.\ 79.1\% PE average and 97.6\% CodeAct average) while maintaining competitive instruction-following scores. The SafeRun benchmark is publicly available at \href{https://huggingface.co/datasets/zzp-seeker/SafeRun-RunPlanning-Benchmark}{huggingface}.
Rewards as Labels: Revisiting RLVR from a Classification Perspective
Feb 05, 2026Reinforcement Learning with Verifiable Rewards has recently advanced the capabilities of Large Language Models in complex reasoning tasks by providing explicit rule-based supervision. Among RLVR methods, GRPO and its variants have achieved strong empirical performance. Despite their success, we identify that they suffer from Gradient Misassignment in Positives and Gradient Domination in Negatives, which lead to inefficient and suboptimal policy updates. To address these issues, we propose Rewards as Labels (REAL), a novel framework that revisits verifiable rewards as categorical labels rather than scalar weights, thereby reformulating policy optimization as a classification problem. Building on this, we further introduce anchor logits to enhance policy learning. Our analysis reveals that REAL induces a monotonic and bounded gradient weighting, enabling balanced gradient allocation across rollouts and effectively mitigating the identified mismatches. Extensive experiments on mathematical reasoning benchmarks show that REAL improves training stability and consistently outperforms GRPO and strong variants such as DAPO. On the 1.5B model, REAL improves average Pass@1 over DAPO by 6.7%. These gains further scale to 7B model, REAL continues to outperform DAPO and GSPO by 6.2% and 1.7%, respectively. Notably, even with a vanilla binary cross-entropy, REAL remains stable and exceeds DAPO by 4.5% on average.
Unbiased Evaluation of Large Language Models from a Causal Perspective
Feb 10, 2025



Benchmark contamination has become a significant concern in the LLM evaluation community. Previous Agents-as-an-Evaluator address this issue by involving agents in the generation of questions. Despite their success, the biases in Agents-as-an-Evaluator methods remain largely unexplored. In this paper, we present a theoretical formulation of evaluation bias, providing valuable insights into designing unbiased evaluation protocols. Furthermore, we identify two type of bias in Agents-as-an-Evaluator through carefully designed probing tasks on a minimal Agents-as-an-Evaluator setup. To address these issues, we propose the Unbiased Evaluator, an evaluation protocol that delivers a more comprehensive, unbiased, and interpretable assessment of LLMs.Extensive experiments reveal significant room for improvement in current LLMs. Additionally, we demonstrate that the Unbiased Evaluator not only offers strong evidence of benchmark contamination but also provides interpretable evaluation results.
UniHCP: A Unified Model for Human-Centric Perceptions
Mar 19, 2023



Human-centric perceptions (e.g., pose estimation, human parsing, pedestrian detection, person re-identification, etc.) play a key role in industrial applications of visual models. While specific human-centric tasks have their own relevant semantic aspect to focus on, they also share the same underlying semantic structure of the human body. However, few works have attempted to exploit such homogeneity and design a general-propose model for human-centric tasks. In this work, we revisit a broad range of human-centric tasks and unify them in a minimalist manner. We propose UniHCP, a Unified Model for Human-Centric Perceptions, which unifies a wide range of human-centric tasks in a simplified end-to-end manner with the plain vision transformer architecture. With large-scale joint training on 33 human-centric datasets, UniHCP can outperform strong baselines on several in-domain and downstream tasks by direct evaluation. When adapted to a specific task, UniHCP achieves new SOTAs on a wide range of human-centric tasks, e.g., 69.8 mIoU on CIHP for human parsing, 86.18 mA on PA-100K for attribute prediction, 90.3 mAP on Market1501 for ReID, and 85.8 JI on CrowdHuman for pedestrian detection, performing better than specialized models tailored for each task.
HumanBench: Towards General Human-centric Perception with Projector Assisted Pretraining
Mar 10, 2023



Human-centric perceptions include a variety of vision tasks, which have widespread industrial applications, including surveillance, autonomous driving, and the metaverse. It is desirable to have a general pretrain model for versatile human-centric downstream tasks. This paper forges ahead along this path from the aspects of both benchmark and pretraining methods. Specifically, we propose a \textbf{HumanBench} based on existing datasets to comprehensively evaluate on the common ground the generalization abilities of different pretraining methods on 19 datasets from 6 diverse downstream tasks, including person ReID, pose estimation, human parsing, pedestrian attribute recognition, pedestrian detection, and crowd counting. To learn both coarse-grained and fine-grained knowledge in human bodies, we further propose a \textbf{P}rojector \textbf{A}ssis\textbf{T}ed \textbf{H}ierarchical pretraining method (\textbf{PATH}) to learn diverse knowledge at different granularity levels. Comprehensive evaluations on HumanBench show that our PATH achieves new state-of-the-art results on 17 downstream datasets and on-par results on the other 2 datasets. The code will be publicly at \href{https://github.com/OpenGVLab/HumanBench}{https://github.com/OpenGVLab/HumanBench}.
Saliency Guided Contrastive Learning on Scene Images
Feb 23, 2023



Self-supervised learning holds promise in leveraging large numbers of unlabeled data. However, its success heavily relies on the highly-curated dataset, e.g., ImageNet, which still needs human cleaning. Directly learning representations from less-curated scene images is essential for pushing self-supervised learning to a higher level. Different from curated images which include simple and clear semantic information, scene images are more complex and mosaic because they often include complex scenes and multiple objects. Despite being feasible, recent works largely overlooked discovering the most discriminative regions for contrastive learning to object representations in scene images. In this work, we leverage the saliency map derived from the model's output during learning to highlight these discriminative regions and guide the whole contrastive learning. Specifically, the saliency map first guides the method to crop its discriminative regions as positive pairs and then reweighs the contrastive losses among different crops by its saliency scores. Our method significantly improves the performance of self-supervised learning on scene images by +1.1, +4.3, +2.2 Top1 accuracy in ImageNet linear evaluation, Semi-supervised learning with 1% and 10% ImageNet labels, respectively. We hope our insights on saliency maps can motivate future research on more general-purpose unsupervised representation learning from scene data.
Learning Domain Adaptive Object Detection with Probabilistic Teacher
Jun 13, 2022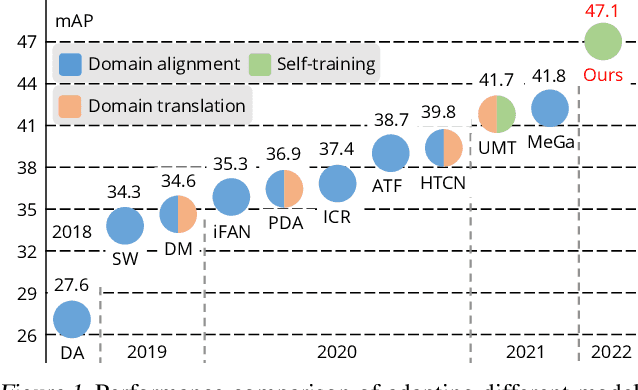
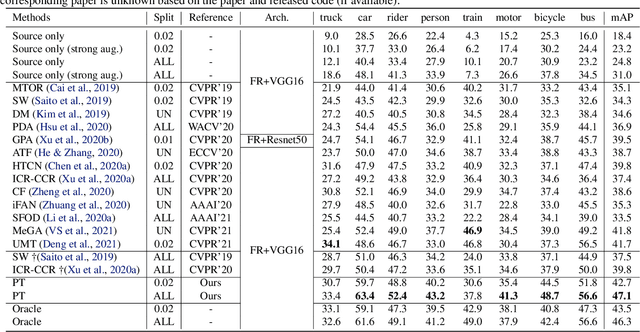
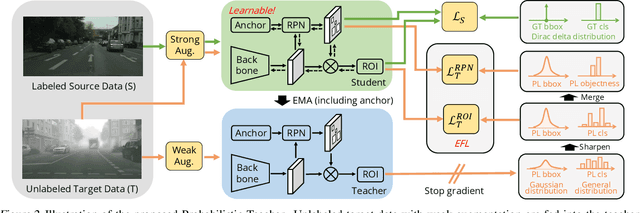
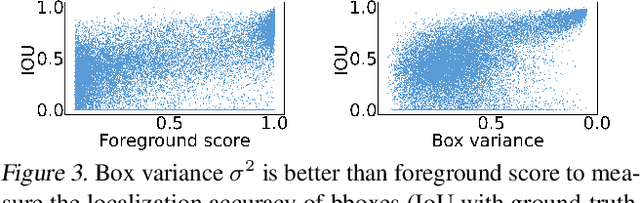
Self-training for unsupervised domain adaptive object detection is a challenging task, of which the performance depends heavily on the quality of pseudo boxes. Despite the promising results, prior works have largely overlooked the uncertainty of pseudo boxes during self-training. In this paper, we present a simple yet effective framework, termed as Probabilistic Teacher (PT), which aims to capture the uncertainty of unlabeled target data from a gradually evolving teacher and guides the learning of a student in a mutually beneficial manner. Specifically, we propose to leverage the uncertainty-guided consistency training to promote classification adaptation and localization adaptation, rather than filtering pseudo boxes via an elaborate confidence threshold. In addition, we conduct anchor adaptation in parallel with localization adaptation, since anchor can be regarded as a learnable parameter. Together with this framework, we also present a novel Entropy Focal Loss (EFL) to further facilitate the uncertainty-guided self-training. Equipped with EFL, PT outperforms all previous baselines by a large margin and achieve new state-of-the-arts.
* To appear in ICML 2022. Code is coming soon: https://github.com/hikvision-research/ProbabilisticTeacher
Domain Invariant Masked Autoencoders for Self-supervised Learning from Multi-domains
May 10, 2022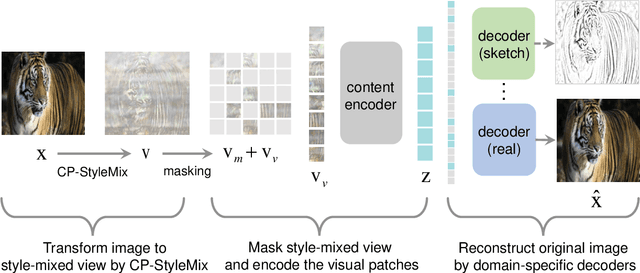
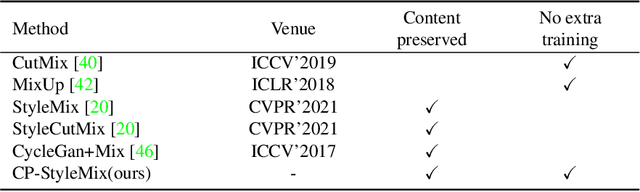

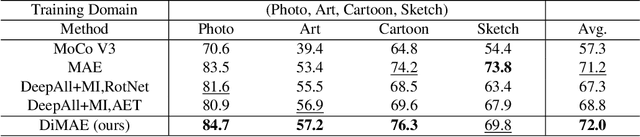
Generalizing learned representations across significantly different visual domains is a fundamental yet crucial ability of the human visual system. While recent self-supervised learning methods have achieved good performances with evaluation set on the same domain as the training set, they will have an undesirable performance decrease when tested on a different domain. Therefore, the self-supervised learning from multiple domains task is proposed to learn domain-invariant features that are not only suitable for evaluation on the same domain as the training set but also can be generalized to unseen domains. In this paper, we propose a Domain-invariant Masked AutoEncoder (DiMAE) for self-supervised learning from multi-domains, which designs a new pretext task, \emph{i.e.,} the cross-domain reconstruction task, to learn domain-invariant features. The core idea is to augment the input image with style noise from different domains and then reconstruct the image from the embedding of the augmented image, regularizing the encoder to learn domain-invariant features. To accomplish the idea, DiMAE contains two critical designs, 1) content-preserved style mix, which adds style information from other domains to input while persevering the content in a parameter-free manner, and 2) multiple domain-specific decoders, which recovers the corresponding domain style of input to the encoded domain-invariant features for reconstruction. Experiments on PACS and DomainNet illustrate that DiMAE achieves considerable gains compared with recent state-of-the-art methods.