 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Supervised Contrastive CSI Representation Learning for Massive MIMO Positioning
Apr 27, 2022
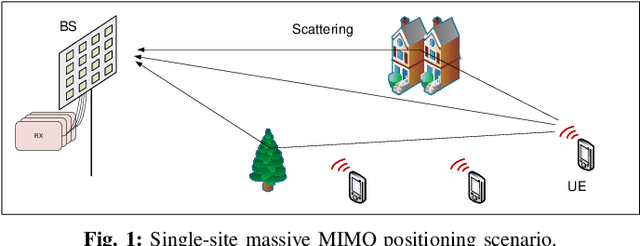
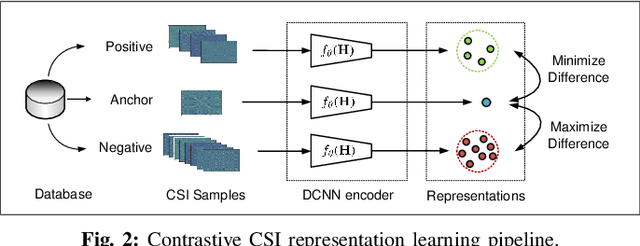
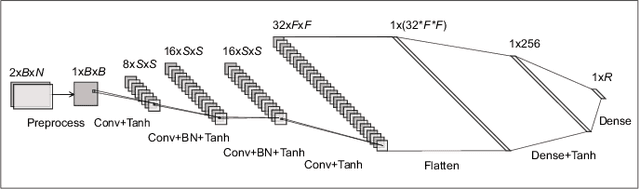
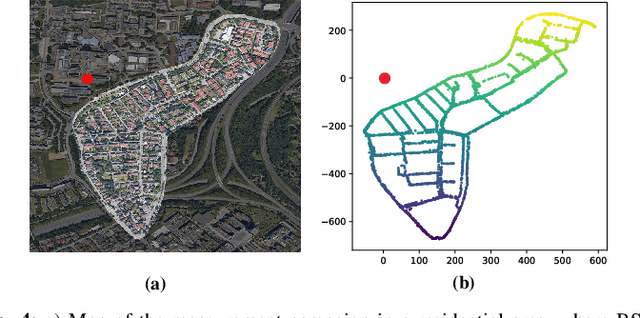
Similarity metric is crucial for massive MIMO positioning utilizing channel state information~(CSI). In this letter, we propose a novel massive MIMO CSI similarity learning method via deep convolutional neural network~(DCNN) and contrastive learning. A contrastive loss function is designed considering multiple positive and negative CSI samples drawn from a training dataset. The DCNN encoder is trained using the loss so that positive samples are mapped to points close to the anchor's encoding, while encodings of negative samples are kept away from the anchor's in the representation space. Evaluation results of fingerprint-based positioning on a real-world CSI dataset show that the learned similarity metric improves positioning accuracy significantly compared with other known state-of-the-art methods.
V4D: Voxel for 4D Novel View Synthesis
May 28, 2022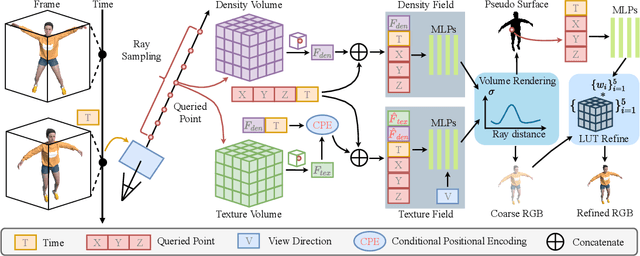
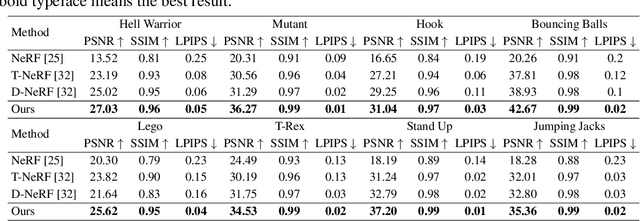
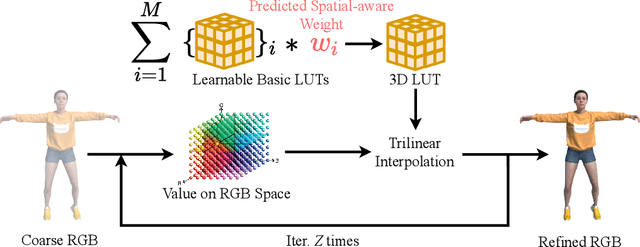
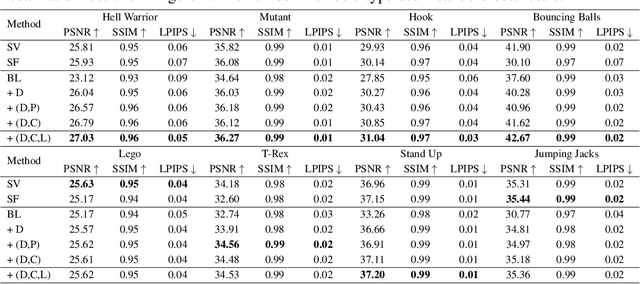
Neural radiance fields have made a remarkable breakthrough in the novel view synthesis task at the 3D static scene. However, for the 4D circumstance (e.g., dynamic scene), the performance of the existing method is still limited by the capacity of the neural network, typically in a multilayer perceptron network (MLP). In this paper, we present the method to model the 4D neural radiance field by the 3D voxel, short as V4D, where the 3D voxel has two formats. The first one is to regularly model the bounded 3D space and then use the sampled local 3D feature with the time index to model the density field and the texture field. The second one is in look-up tables (LUTs) format that is for the pixel-level refinement, where the pseudo-surface produced by the volume rendering is utilized as the guidance information to learn a 2D pixel-level refinement mapping. The proposed LUTs-based refinement module achieves the performance gain with a little computational cost and could serve as the plug-and-play module in the novel view synthesis task. Moreover, we propose a more effective conditional positional encoding toward the 4D data that achieves performance gain with negligible computational burdens. Extensive experiments demonstrate that the proposed method achieves state-of-the-art performance by a large margin. At last, the proposed V4D is also a computational-friendly method in both the training and testing phase, where we achieve 2 times faster in the training phase and 10 times faster in the inference phase compared with the state-of-the-art method.
BodySLAM: Joint Camera Localisation, Mapping, and Human Motion Tracking
May 04, 2022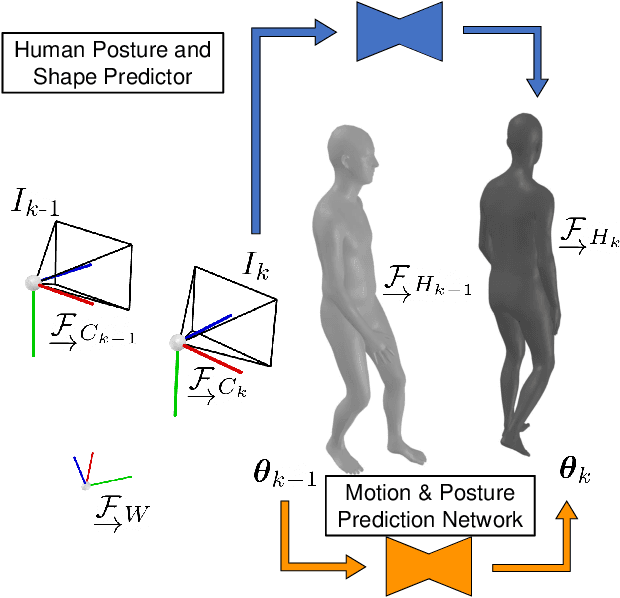
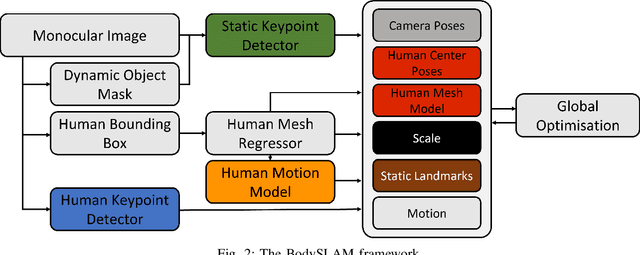
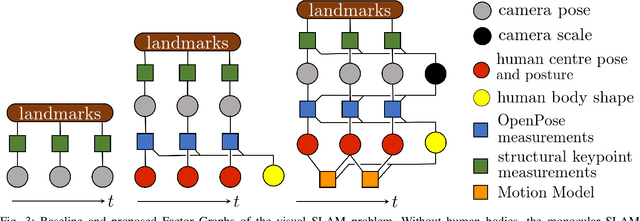
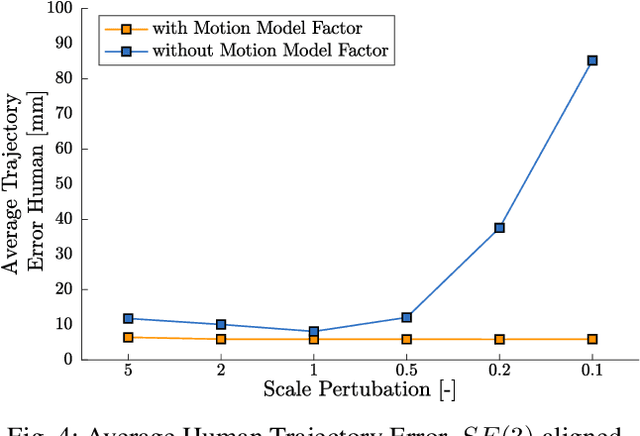
Estimating human motion from video is an active research area due to its many potential applications. Most state-of-the-art methods predict human shape and posture estimates for individual images and do not leverage the temporal information available in video. Many "in the wild" sequences of human motion are captured by a moving camera, which adds the complication of conflated camera and human motion to the estimation. We therefore present BodySLAM, a monocular SLAM system that jointly estimates the position, shape, and posture of human bodies, as well as the camera trajectory. We also introduce a novel human motion model to constrain sequential body postures and observe the scale of the scene. Through a series of experiments on video sequences of human motion captured by a moving monocular camera, we demonstrate that BodySLAM improves estimates of all human body parameters and camera poses when compared to estimating these separately.
A Reinforcement Learning Approach to Age of Information in Multi-User Networks with HARQ
Feb 19, 2021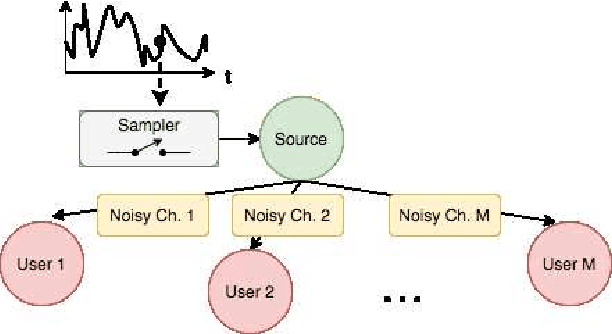
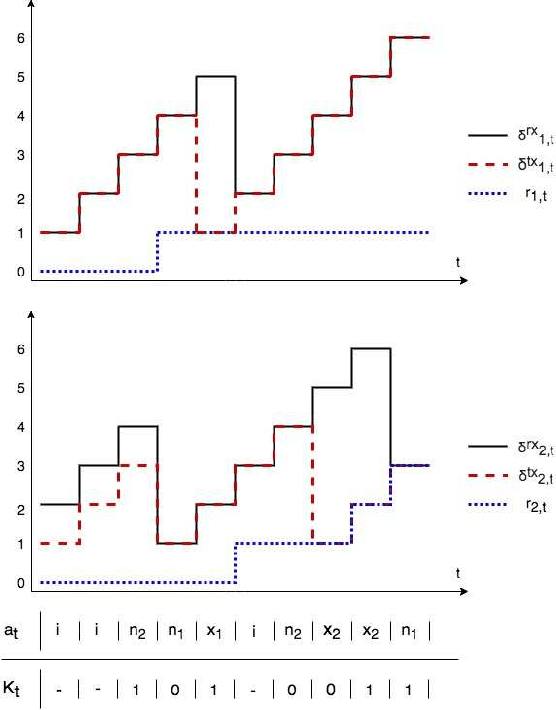
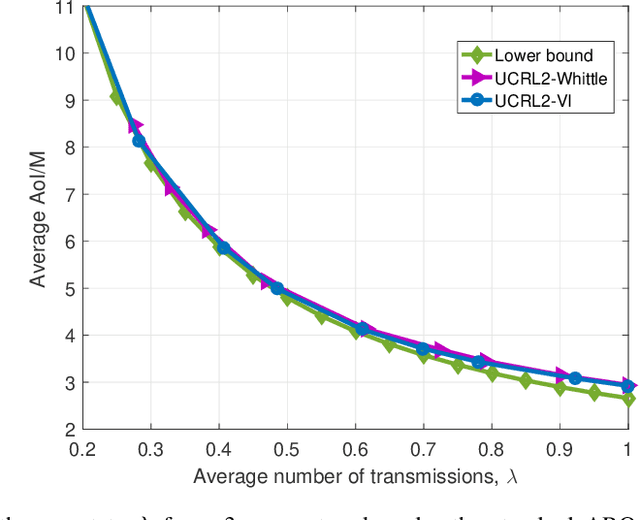
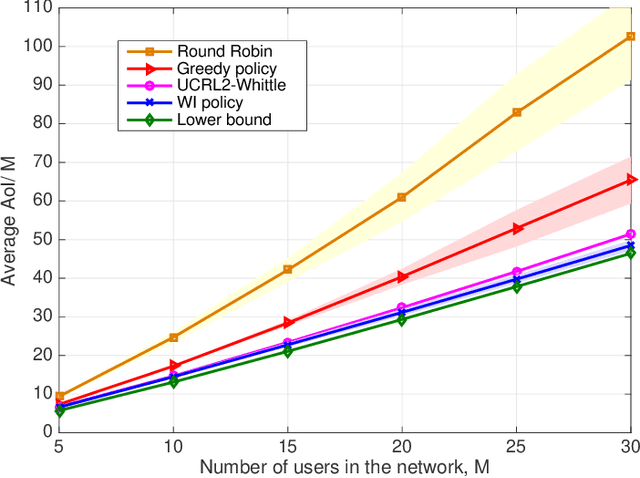
Scheduling the transmission of time-sensitive information from a source node to multiple users over error-prone communication channels is studied with the goal of minimizing the long-term average age of information (AoI) at the users. A long-term average resource constraint is imposed on the source, which limits the average number of transmissions. The source can transmit only to a single user at each time slot, and after each transmission, it receives an instantaneous ACK/NACK feedback from the intended receiver, and decides when and to which user to transmit the next update. Assuming the channel statistics are known, the optimal scheduling policy is studied for both the standard automatic repeat request (ARQ) and hybrid ARQ (HARQ) protocols. Then, a reinforcement learning(RL) approach is introduced to find a near-optimal policy, which does not assume any a priori information on the random processes governing the channel states. Different RL methods including average-cost SARSAwith linear function approximation (LFA), upper confidence reinforcement learning (UCRL2), and deep Q-network (DQN) are applied and compared through numerical simulations
COIL: Revisit Exact Lexical Match in Information Retrieval with Contextualized Inverted List
Apr 15, 2021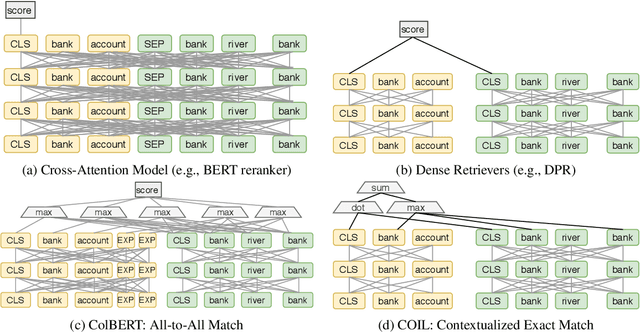
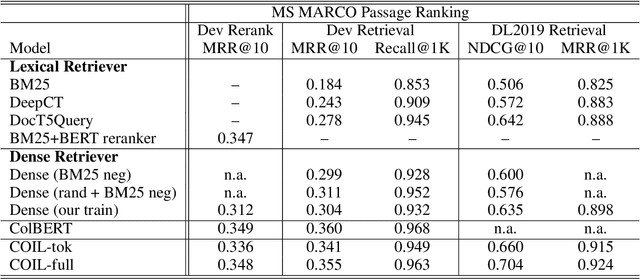
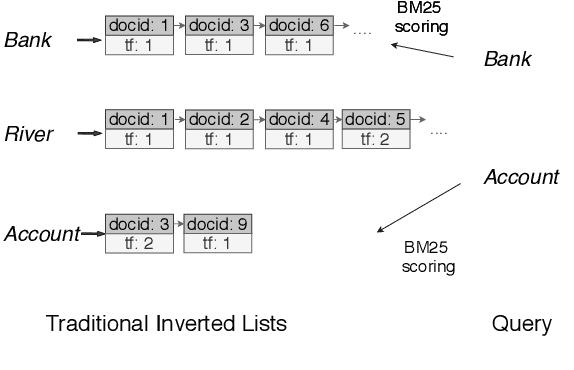
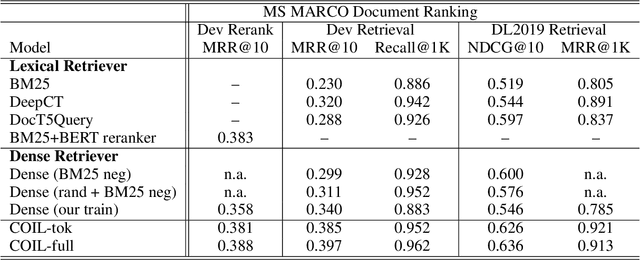
Classical information retrieval systems such as BM25 rely on exact lexical match and carry out search efficiently with inverted list index. Recent neural IR models shifts towards soft semantic matching all query document terms, but they lose the computation efficiency of exact match systems. This paper presents COIL, a contextualized exact match retrieval architecture that brings semantic lexical matching. COIL scoring is based on overlapping query document tokens' contextualized representations. The new architecture stores contextualized token representations in inverted lists, bringing together the efficiency of exact match and the representation power of deep language models. Our experimental results show COIL outperforms classical lexical retrievers and state-of-the-art deep LM retrievers with similar or smaller latency.
Sim-to-Real Strategy for Spatially Aware Robot Navigation in Uneven Outdoor Environments
May 18, 2022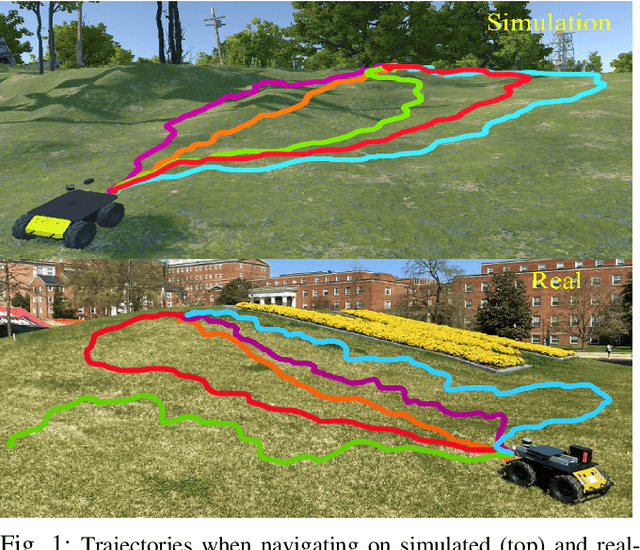
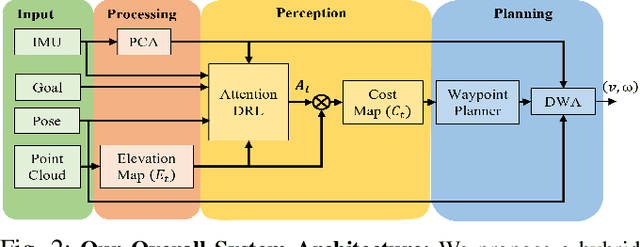
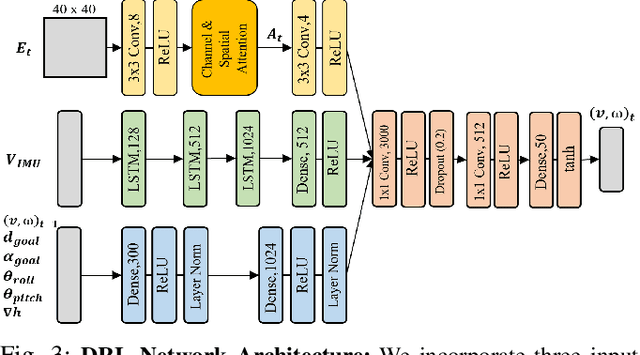
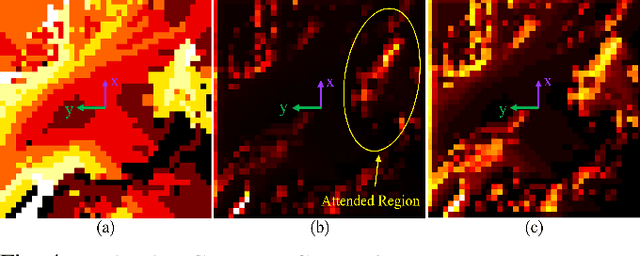
Deep Reinforcement Learning (DRL) is hugely successful due to the availability of realistic simulated environments. However, performance degradation during simulation to real-world transfer still remains a challenging problem for the policies trained in simulated environments. To close this sim-to-real gap, we present a novel hybrid architecture that utilizes an intermediate output from a fully trained attention DRL policy as a navigation cost map for outdoor navigation. Our attention DRL network incorporates a robot-centric elevation map, IMU data, the robot's pose, previous actions, and goal information as inputs to compute a navigation cost-map that highlights non-traversable regions. We compute least-cost waypoints on the cost map and utilize the Dynamic Window Approach (DWA) with velocity constraints on high cost regions to follow the waypoints in highly uneven outdoor environments. Our formulation generates dynamically feasible velocities along stable, traversable regions to reach the robot's goals. We observe an increase of 5% in terms of success rate, 13.09% of the decrease in average robot vibration, and a 19.33% reduction in average velocity compared to end-to-end DRL method and state-of-the-art methods in complex outdoor environments. We evaluate the benefits of our method using a Clearpath Husky robot in both simulated and real-world uneven environments.
Temporal Context Matters: Enhancing Single Image Prediction with Disease Progression Representations
Mar 31, 2022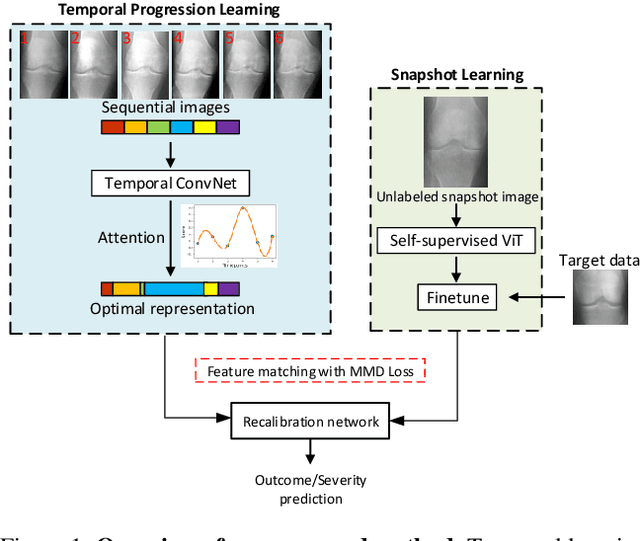
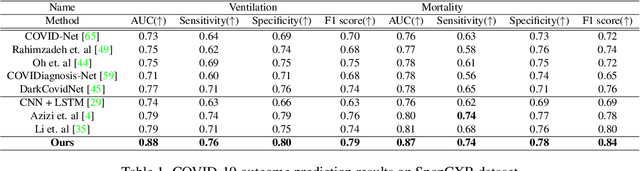
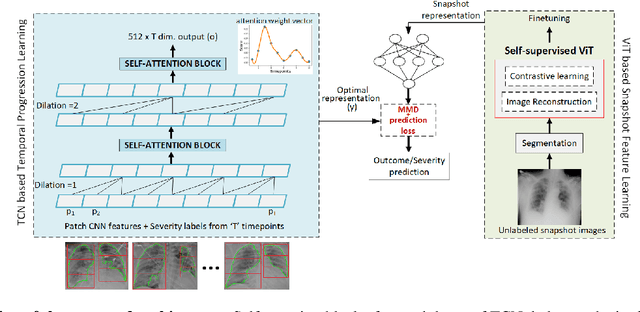
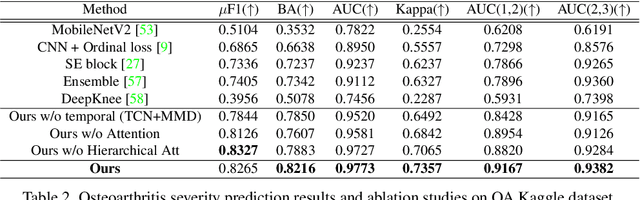
Clinical outcome or severity prediction from medical images has largely focused on learning representations from single-timepoint or snapshot scans. It has been shown that disease progression can be better characterized by temporal imaging. We therefore hypothesized that outcome predictions can be improved by utilizing the disease progression information from sequential images. We present a deep learning approach that leverages temporal progression information to improve clinical outcome predictions from single-timepoint images. In our method, a self-attention based Temporal Convolutional Network (TCN) is used to learn a representation that is most reflective of the disease trajectory. Meanwhile, a Vision Transformer is pretrained in a self-supervised fashion to extract features from single-timepoint images. The key contribution is to design a recalibration module that employs maximum mean discrepancy loss (MMD) to align distributions of the above two contextual representations. We train our system to predict clinical outcomes and severity grades from single-timepoint images. Experiments on chest and osteoarthritis radiography datasets demonstrate that our approach outperforms other state-of-the-art techniques.
Modeling Reservoir Release Using Pseudo-Prospective Learning and Physical Simulations to Predict Water Temperature
Feb 11, 2022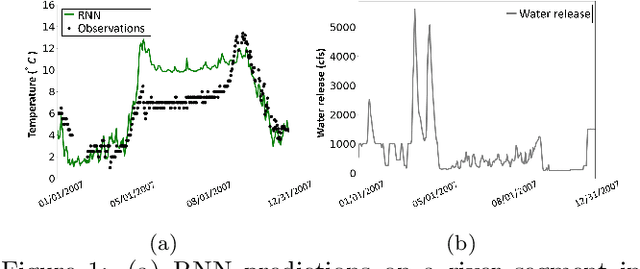
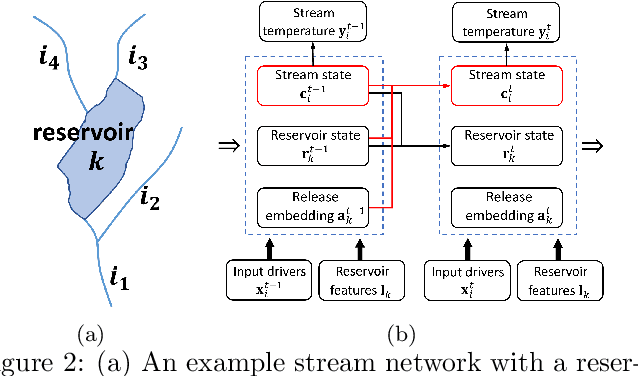

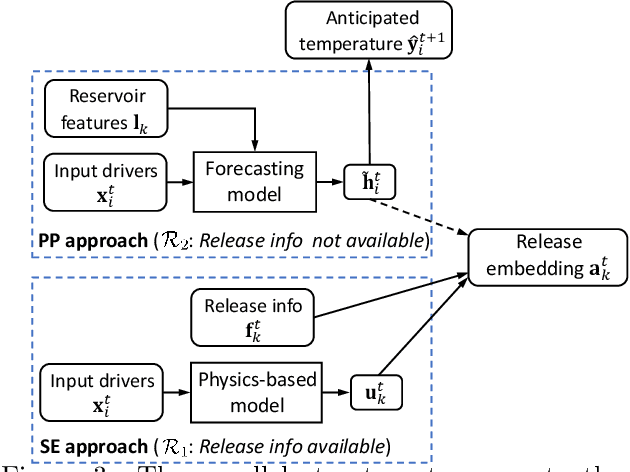
This paper proposes a new data-driven method for predicting water temperature in stream networks with reservoirs. The water flows released from reservoirs greatly affect the water temperature of downstream river segments. However, the information of released water flow is often not available for many reservoirs, which makes it difficult for data-driven models to capture the impact to downstream river segments. In this paper, we first build a state-aware graph model to represent the interactions amongst streams and reservoirs, and then propose a parallel learning structure to extract the reservoir release information and use it to improve the prediction. In particular, for reservoirs with no available release information, we mimic the water managers' release decision process through a pseudo-prospective learning method, which infers the release information from anticipated water temperature dynamics. For reservoirs with the release information, we leverage a physics-based model to simulate the water release temperature and transfer such information to guide the learning process for other reservoirs. The evaluation for the Delaware River Basin shows that the proposed method brings over 10\% accuracy improvement over existing data-driven models for stream temperature prediction when the release data is not available for any reservoirs. The performance is further improved after we incorporate the release data and physical simulations for a subset of reservoirs.
Active Source Free Domain Adaptation
May 22, 2022
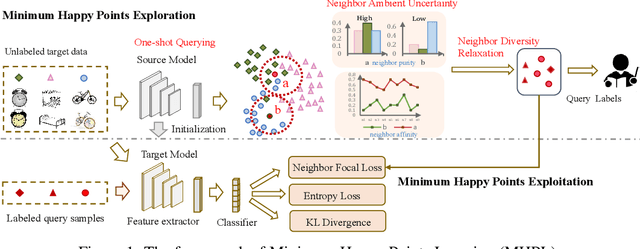

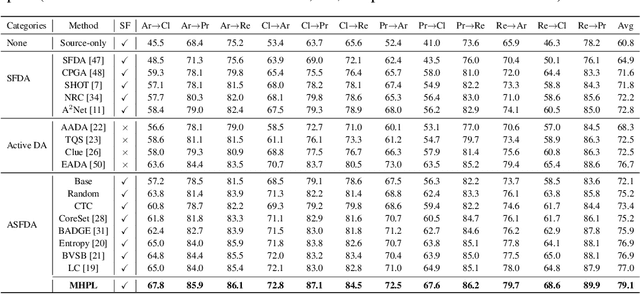
Source free domain adaptation (SFDA) aims to transfer a trained source model to the unlabeled target domain without accessing the source data. However, the SFDA setting faces an effect bottleneck due to the absence of source data and target supervised information, as evidenced by the limited performance gains of newest SFDA methods. In this paper, for the first time, we introduce a more practical scenario called active source free domain adaptation (ASFDA) that permits actively selecting a few target data to be labeled by experts. To achieve that, we first find that those satisfying the properties of neighbor-chaotic, individual-different, and target-like are the best points to select, and we define them as the minimum happy (MH) points. We then propose minimum happy points learning (MHPL) to actively explore and exploit MH points. We design three unique strategies: neighbor ambient uncertainty, neighbor diversity relaxation, and one-shot querying, to explore the MH points. Further, to fully exploit MH points in the learning process, we design a neighbor focal loss that assigns the weighted neighbor purity to the cross-entropy loss of MH points to make the model focus more on them. Extensive experiments verify that MHPL remarkably exceeds the various types of baselines and achieves significant performance gains at a small cost of labeling.
TSAM: A Two-Stream Attention Model for Causal Emotion Entailment
Mar 02, 2022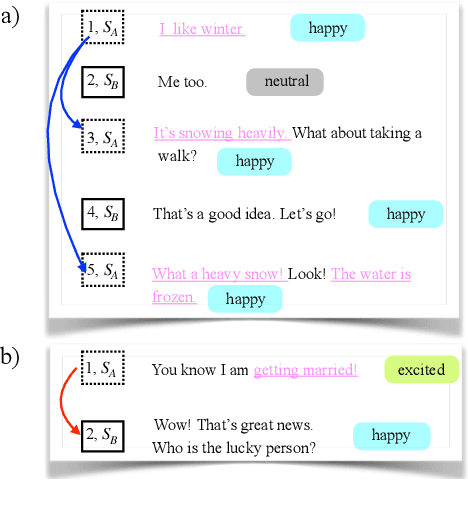
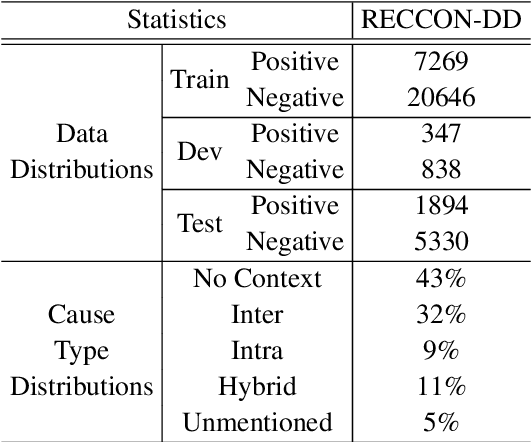
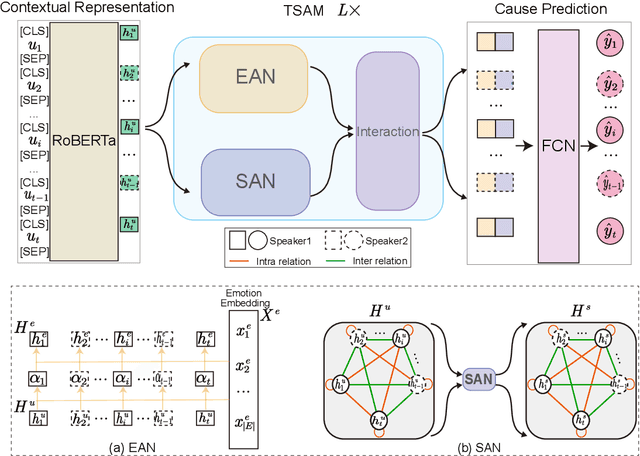
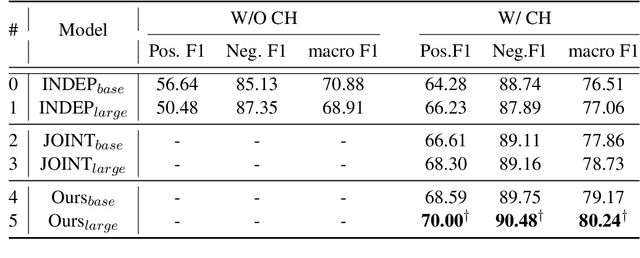
Causal Emotion Entailment (CEE) aims to discover the potential causes behind an emotion in a conversational utterance. Previous works formalize CEE as independent utterance pair classification problems, with emotion and speaker information neglected. From a new perspective, this paper considers CEE in a joint framework. We classify multiple utterances synchronously to capture the correlations between utterances in a global view and propose a Two-Stream Attention Model (TSAM) to effectively model the speaker's emotional influences in the conversational history. Specifically, the TSAM comprises three modules: Emotion Attention Network (EAN), Speaker Attention Network (SAN), and interaction module. The EAN and SAN incorporate emotion and speaker information in parallel, and the subsequent interaction module effectively interchanges relevant information between the EAN and SAN via a mutual BiAffine transformation. Experimental results on a benchmark dataset demonstrate that our model achieves new State-Of-The-Art (SOTA) performance and outperforms baselines remarkably.