 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards the Probabilistic Fusion of Learned Priors into Standard Pipelines for 3D Reconstruction
Jul 27, 2022
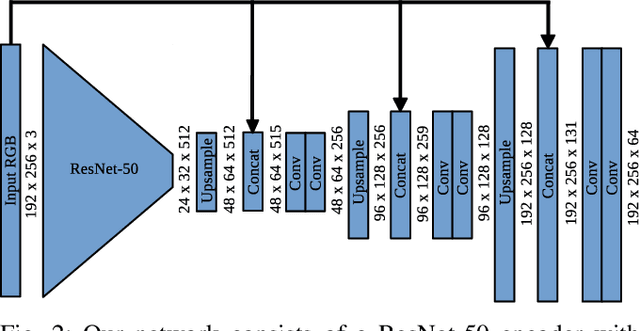
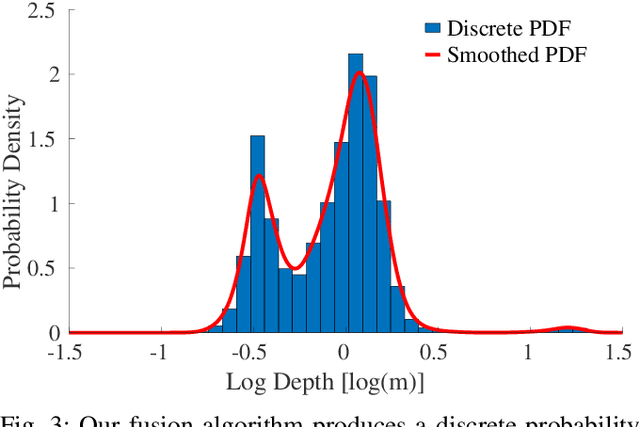

The best way to combine the results of deep learning with standard 3D reconstruction pipelines remains an open problem. While systems that pass the output of traditional multi-view stereo approaches to a network for regularisation or refinement currently seem to get the best results, it may be preferable to treat deep neural networks as separate components whose results can be probabilistically fused into geometry-based systems. Unfortunately, the error models required to do this type of fusion are not well understood, with many different approaches being put forward. Recently, a few systems have achieved good results by having their networks predict probability distributions rather than single values. We propose using this approach to fuse a learned single-view depth prior into a standard 3D reconstruction system. Our system is capable of incrementally producing dense depth maps for a set of keyframes. We train a deep neural network to predict discrete, nonparametric probability distributions for the depth of each pixel from a single image. We then fuse this "probability volume" with another probability volume based on the photometric consistency between subsequent frames and the keyframe image. We argue that combining the probability volumes from these two sources will result in a volume that is better conditioned. To extract depth maps from the volume, we minimise a cost function that includes a regularisation term based on network predicted surface normals and occlusion boundaries. Through a series of experiments, we demonstrate that each of these components improves the overall performance of the system.
DeepFusion: Real-Time Dense 3D Reconstruction for Monocular SLAM using Single-View Depth and Gradient Predictions
Jul 25, 2022



While the keypoint-based maps created by sparse monocular simultaneous localisation and mapping (SLAM) systems are useful for camera tracking, dense 3D reconstructions may be desired for many robotic tasks. Solutions involving depth cameras are limited in range and to indoor spaces, and dense reconstruction systems based on minimising the photometric error between frames are typically poorly constrained and suffer from scale ambiguity. To address these issues, we propose a 3D reconstruction system that leverages the output of a convolutional neural network (CNN) to produce fully dense depth maps for keyframes that include metric scale. Our system, DeepFusion, is capable of producing real-time dense reconstructions on a GPU. It fuses the output of a semi-dense multiview stereo algorithm with the depth and gradient predictions of a CNN in a probabilistic fashion, using learned uncertainties produced by the network. While the network only needs to be run once per keyframe, we are able to optimise for the depth map with each new frame so as to constantly make use of new geometric constraints. Based on its performance on synthetic and real-world datasets, we demonstrate that DeepFusion is capable of performing at least as well as other comparable systems.
Dense RGB-D-Inertial SLAM with Map Deformations
Jul 22, 2022
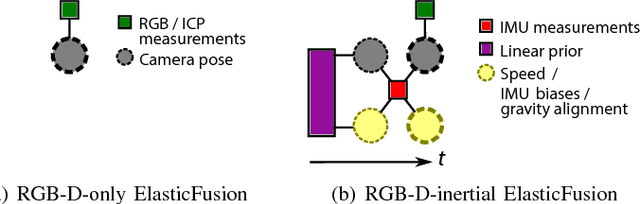
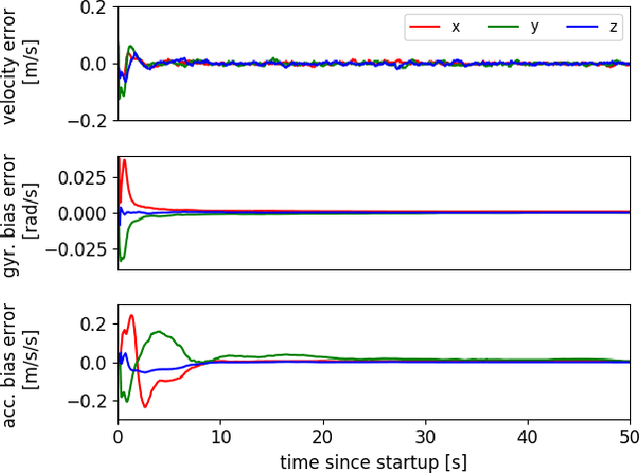
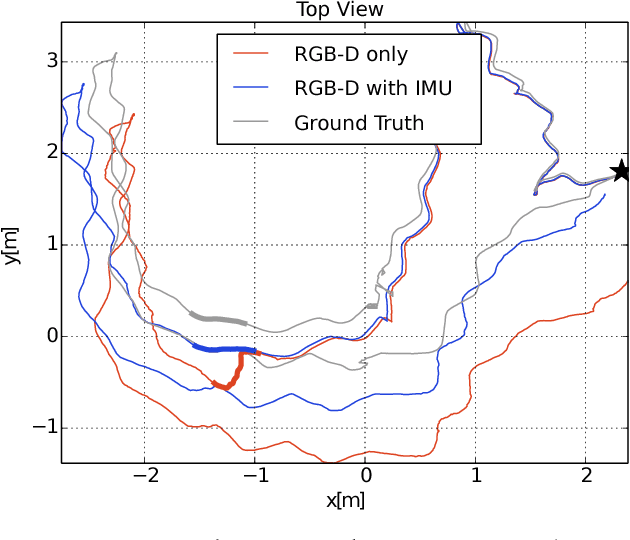
While dense visual SLAM methods are capable of estimating dense reconstructions of the environment, they suffer from a lack of robustness in their tracking step, especially when the optimisation is poorly initialised. Sparse visual SLAM systems have attained high levels of accuracy and robustness through the inclusion of inertial measurements in a tightly-coupled fusion. Inspired by this performance, we propose the first tightly-coupled dense RGB-D-inertial SLAM system. Our system has real-time capability while running on a GPU. It jointly optimises for the camera pose, velocity, IMU biases and gravity direction while building up a globally consistent, fully dense surfel-based 3D reconstruction of the environment. Through a series of experiments on both synthetic and real world datasets, we show that our dense visual-inertial SLAM system is more robust to fast motions and periods of low texture and low geometric variation than a related RGB-D-only SLAM system.
BodySLAM: Joint Camera Localisation, Mapping, and Human Motion Tracking
May 04, 2022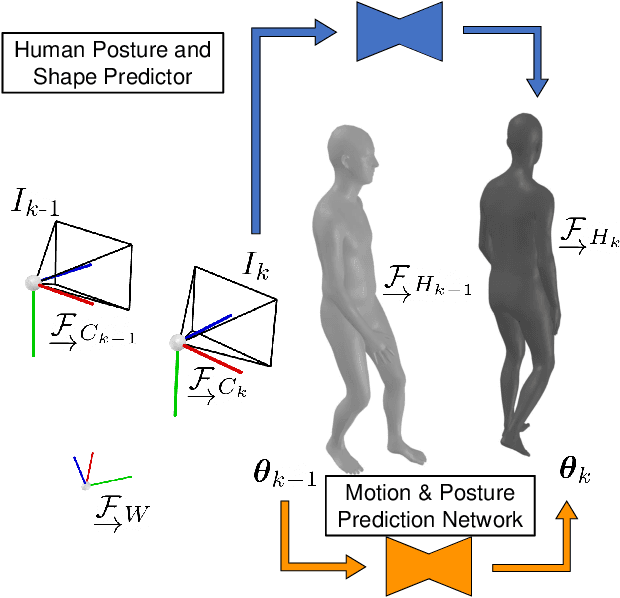
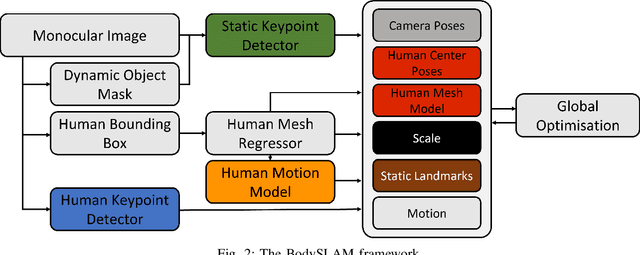
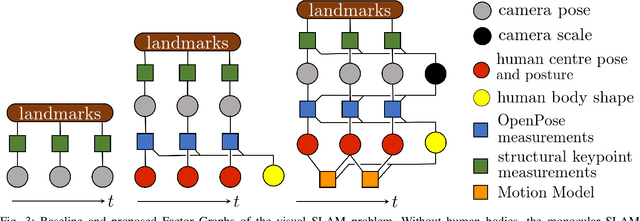
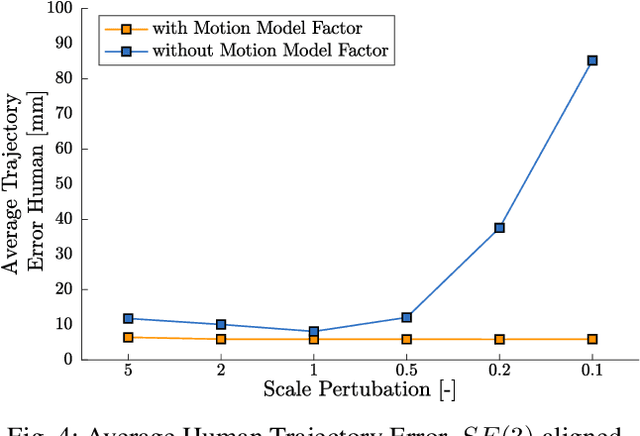
Estimating human motion from video is an active research area due to its many potential applications. Most state-of-the-art methods predict human shape and posture estimates for individual images and do not leverage the temporal information available in video. Many "in the wild" sequences of human motion are captured by a moving camera, which adds the complication of conflated camera and human motion to the estimation. We therefore present BodySLAM, a monocular SLAM system that jointly estimates the position, shape, and posture of human bodies, as well as the camera trajectory. We also introduce a novel human motion model to constrain sequential body postures and observe the scale of the scene. Through a series of experiments on video sequences of human motion captured by a moving monocular camera, we demonstrate that BodySLAM improves estimates of all human body parameters and camera poses when compared to estimating these separately.
Simultaneous Localisation and Mapping with Quadric Surfaces
Mar 15, 2022
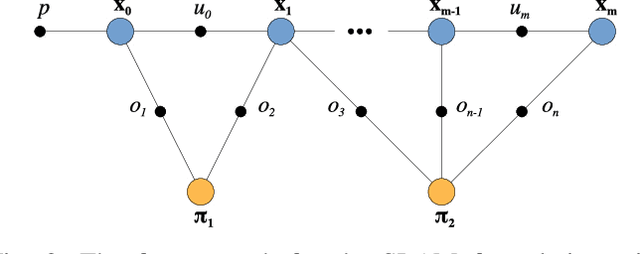
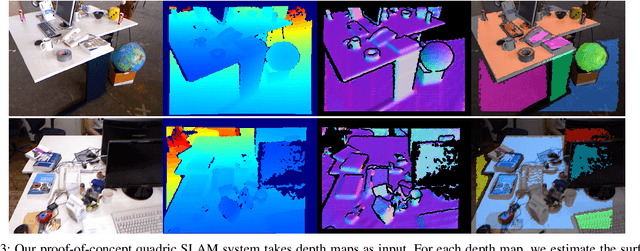

There are many possibilities for how to represent the map in simultaneous localisation and mapping (SLAM). While sparse, keypoint-based SLAM systems have achieved impressive levels of accuracy and robustness, their maps may not be suitable for many robotic tasks. Dense SLAM systems are capable of producing dense reconstructions, but can be computationally expensive and, like sparse systems, lack higher-level information about the structure of a scene. Human-made environments contain a lot of structure, and we seek to take advantage of this by enabling the use of quadric surfaces as features in SLAM systems. We introduce a minimal representation for quadric surfaces and show how this can be included in a least-squares formulation. We also show how our representation can be easily extended to include additional constraints on quadrics such as those found in quadrics of revolution. Finally, we introduce a proof-of-concept SLAM system using our representation, and provide some experimental results using an RGB-D dataset.
ILabel: Interactive Neural Scene Labelling
Dec 03, 2021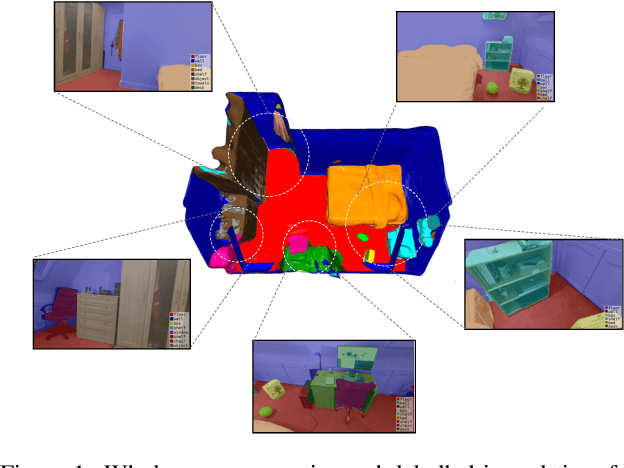
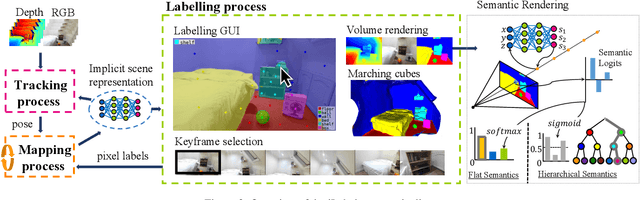
Joint representation of geometry, colour and semantics using a 3D neural field enables accurate dense labelling from ultra-sparse interactions as a user reconstructs a scene in real-time using a handheld RGB-D sensor. Our iLabel system requires no training data, yet can densely label scenes more accurately than standard methods trained on large, expensively labelled image datasets. Furthermore, it works in an 'open set' manner, with semantic classes defined on the fly by the user. ILabel's underlying model is a multilayer perceptron (MLP) trained from scratch in real-time to learn a joint neural scene representation. The scene model is updated and visualised in real-time, allowing the user to focus interactions to achieve efficient labelling. A room or similar scene can be accurately labelled into 10+ semantic categories with only a few tens of clicks. Quantitative labelling accuracy scales powerfully with the number of clicks, and rapidly surpasses standard pre-trained semantic segmentation methods. We also demonstrate a hierarchical labelling variant.
Coarse-to-Fine Q-attention: Efficient Learning for Visual Robotic Manipulation via Discretisation
Jun 23, 2021
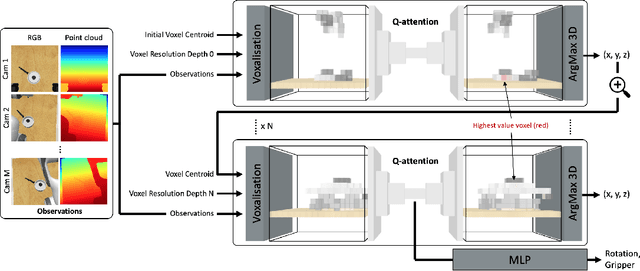
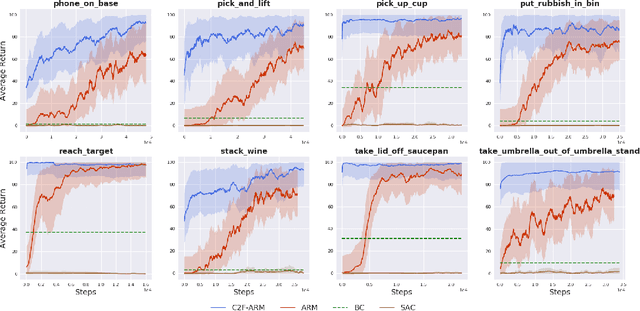
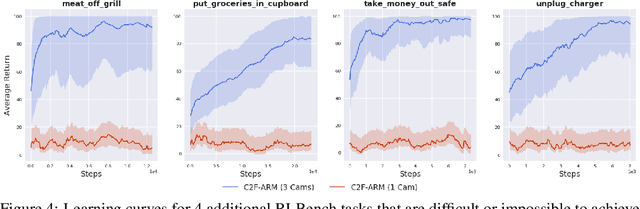
Reflecting on the last few years, the biggest breakthroughs in deep reinforcement learning (RL) have been in the discrete action domain. Robotic manipulation, however, is inherently a continuous control environment, but these continuous control reinforcement learning algorithms often depend on actor-critic methods that are sample-inefficient and inherently difficult to train, due to the joint optimisation of the actor and critic. To that end, we explore how we can bring the stability of discrete action RL algorithms to the robot manipulation domain. We extend the recently released ARM algorithm, by replacing the continuous next-best pose agent with a discrete next-best pose agent. Discretisation of rotation is trivial given its bounded nature, while translation is inherently unbounded, making discretisation difficult. We formulate the translation prediction as the voxel prediction problem by discretising the 3D space; however, voxelisation of a large workspace is memory intensive and would not work with a high density of voxels, crucial to obtaining the resolution needed for robotic manipulation. We therefore propose to apply this voxel prediction in a coarse-to-fine manner by gradually increasing the resolution. In each step, we extract the highest valued voxel as the predicted location, which is then used as the centre of the higher-resolution voxelisation in the next step. This coarse-to-fine prediction is applied over several steps, giving a near-lossless prediction of the translation. We show that our new coarse-to-fine algorithm is able to accomplish RLBench tasks much more efficiently than the continuous control equivalent, and even train some real-world tasks, tabular rasa, in less than 7 minutes, with only 3 demonstrations. Moreover, we show that by moving to a voxel representation, we are able to easily incorporate observations from multiple cameras.
SIMstack: A Generative Shape and Instance Model for Unordered Object Stacks
Mar 30, 2021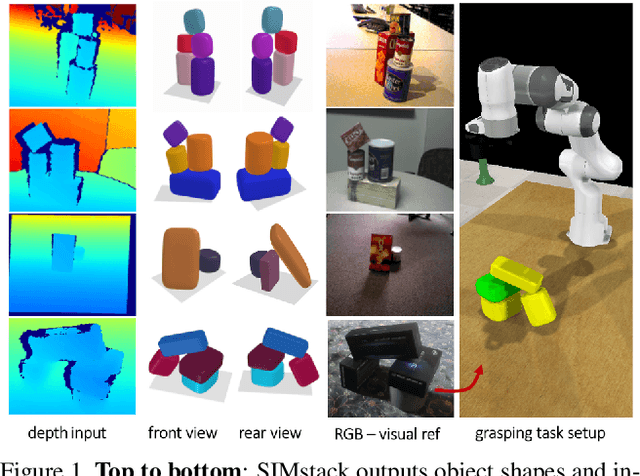
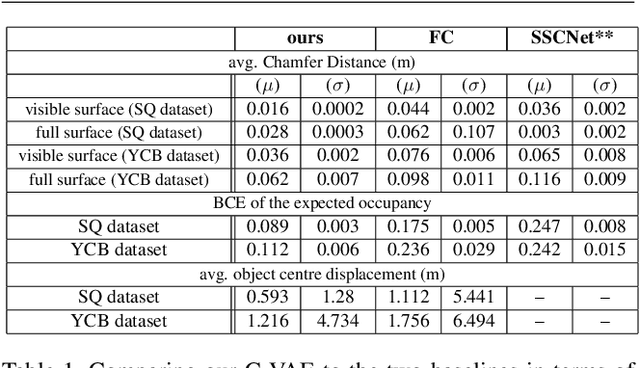
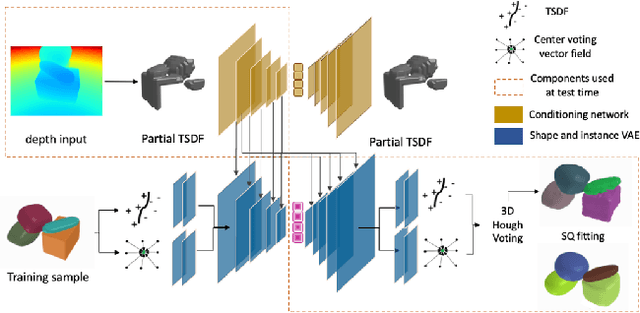

By estimating 3D shape and instances from a single view, we can capture information about an environment quickly, without the need for comprehensive scanning and multi-view fusion. Solving this task for composite scenes (such as object stacks) is challenging: occluded areas are not only ambiguous in shape but also in instance segmentation; multiple decompositions could be valid. We observe that physics constrains decomposition as well as shape in occluded regions and hypothesise that a latent space learned from scenes built under physics simulation can serve as a prior to better predict shape and instances in occluded regions. To this end we propose SIMstack, a depth-conditioned Variational Auto-Encoder (VAE), trained on a dataset of objects stacked under physics simulation. We formulate instance segmentation as a centre voting task which allows for class-agnostic detection and doesn't require setting the maximum number of objects in the scene. At test time, our model can generate 3D shape and instance segmentation from a single depth view, probabilistically sampling proposals for the occluded region from the learned latent space. Our method has practical applications in providing robots some of the ability humans have to make rapid intuitive inferences of partially observed scenes. We demonstrate an application for precise (non-disruptive) object grasping of unknown objects from a single depth view.
In-Place Scene Labelling and Understanding with Implicit Scene Representation
Mar 29, 2021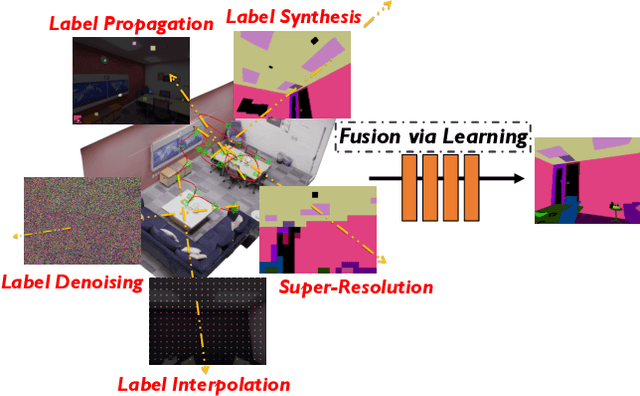
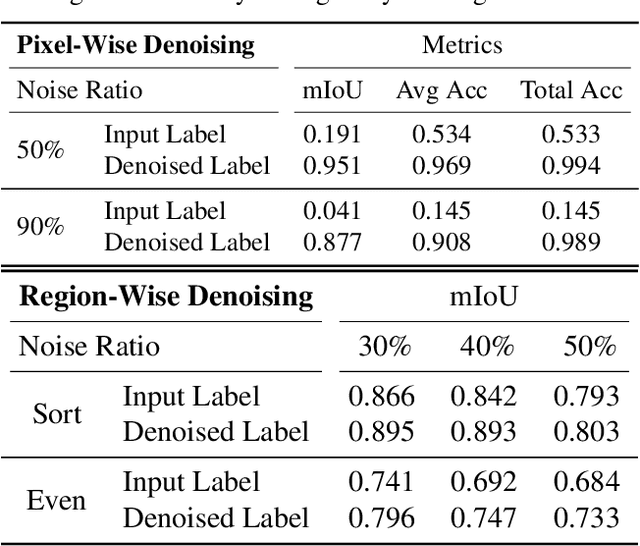
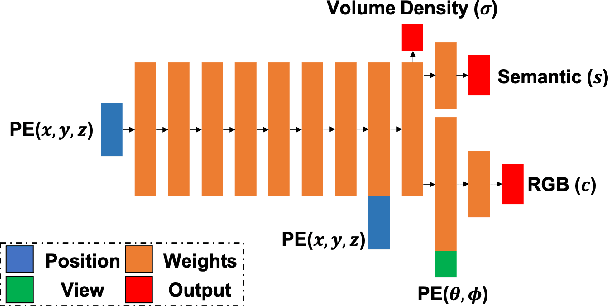
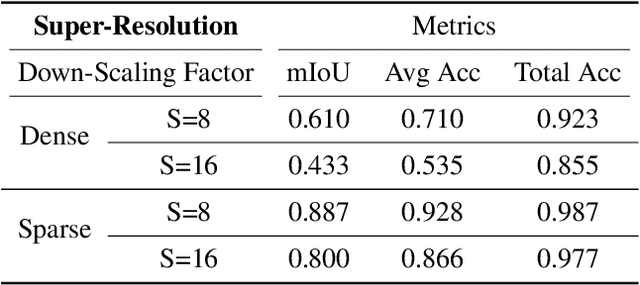
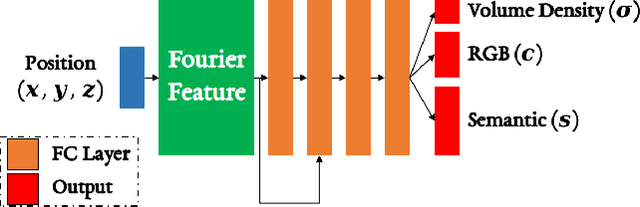
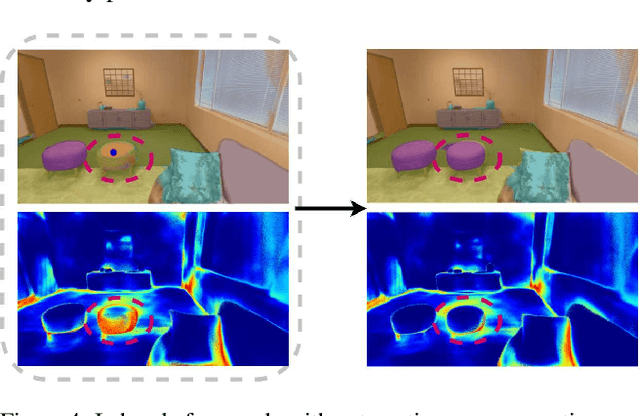
Semantic labelling is highly correlated with geometry and radiance reconstruction, as scene entities with similar shape and appearance are more likely to come from similar classes. Recent implicit neural reconstruction techniques are appealing as they do not require prior training data, but the same fully self-supervised approach is not possible for semantics because labels are human-defined properties. We extend neural radiance fields (NeRF) to jointly encode semantics with appearance and geometry, so that complete and accurate 2D semantic labels can be achieved using a small amount of in-place annotations specific to the scene. The intrinsic multi-view consistency and smoothness of NeRF benefit semantics by enabling sparse labels to efficiently propagate. We show the benefit of this approach when labels are either sparse or very noisy in room-scale scenes. We demonstrate its advantageous properties in various interesting applications such as an efficient scene labelling tool, novel semantic view synthesis, label denoising, super-resolution, label interpolation and multi-view semantic label fusion in visual semantic mapping systems.
DeepFactors: Real-Time Probabilistic Dense Monocular SLAM
Jan 14, 2020
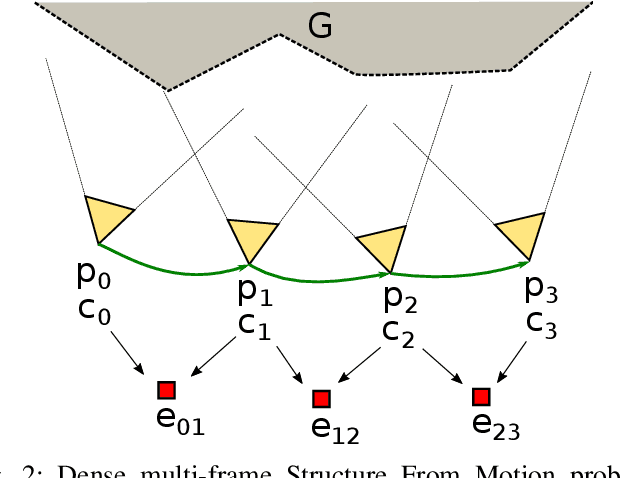

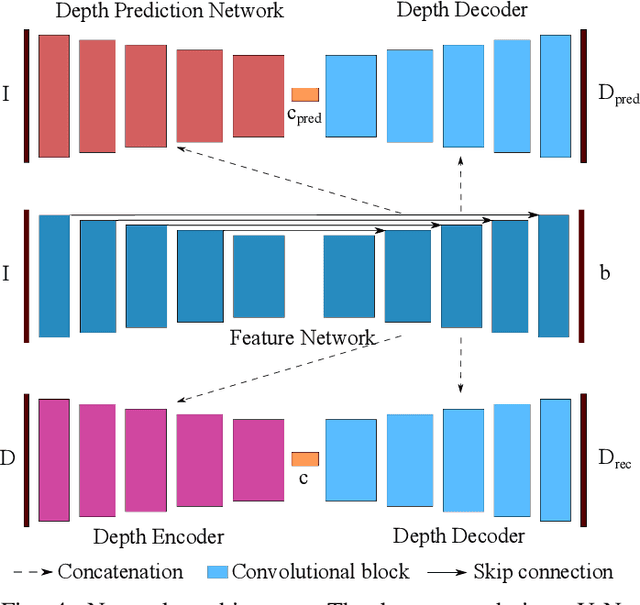
The ability to estimate rich geometry and camera motion from monocular imagery is fundamental to future interactive robotics and augmented reality applications. Different approaches have been proposed that vary in scene geometry representation (sparse landmarks, dense maps), the consistency metric used for optimising the multi-view problem, and the use of learned priors. We present a SLAM system that unifies these methods in a probabilistic framework while still maintaining real-time performance. This is achieved through the use of a learned compact depth map representation and reformulating three different types of errors: photometric, reprojection and geometric, which we make use of within standard factor graph software. We evaluate our system on trajectory estimation and depth reconstruction on real-world sequences and present various examples of estimated dense geometry.