 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Neural Processes with Stochastic Attention: Paying more attention to the context dataset
Apr 11, 2022
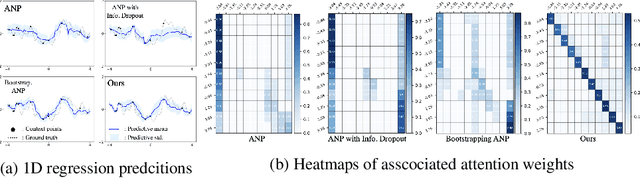
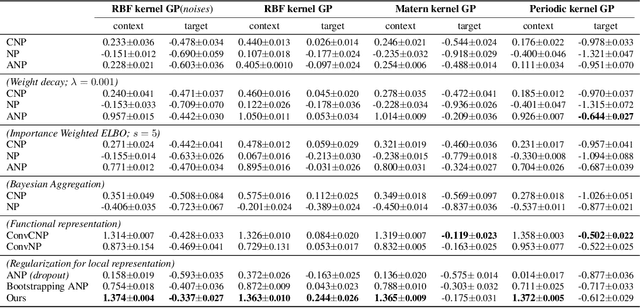
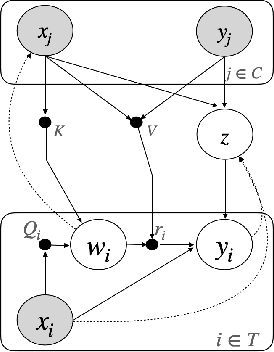
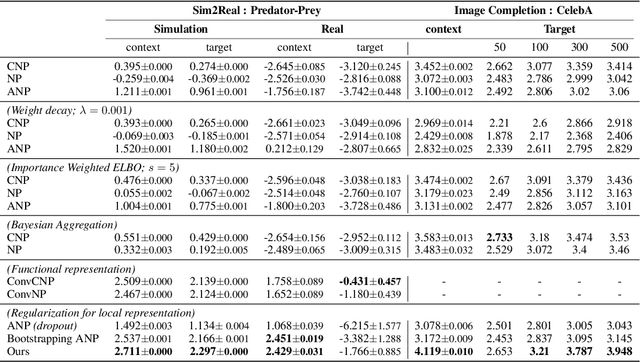
Neural processes (NPs) aim to stochastically complete unseen data points based on a given context dataset. NPs essentially leverage a given dataset as a context representation to derive a suitable identifier for a novel task. To improve the prediction accuracy, many variants of NPs have investigated context embedding approaches that generally design novel network architectures and aggregation functions satisfying permutation invariant. In this work, we propose a stochastic attention mechanism for NPs to capture appropriate context information. From the perspective of information theory, we demonstrate that the proposed method encourages context embedding to be differentiated from a target dataset, allowing NPs to consider features in a target dataset and context embedding independently. We observe that the proposed method can appropriately capture context embedding even under noisy data sets and restricted task distributions, where typical NPs suffer from a lack of context embeddings. We empirically show that our approach substantially outperforms conventional NPs in various domains through 1D regression, predator-prey model, and image completion. Moreover, the proposed method is also validated by MovieLens-10k dataset, a real-world problem.
Ontological Learning from Weak Labels
Mar 04, 2022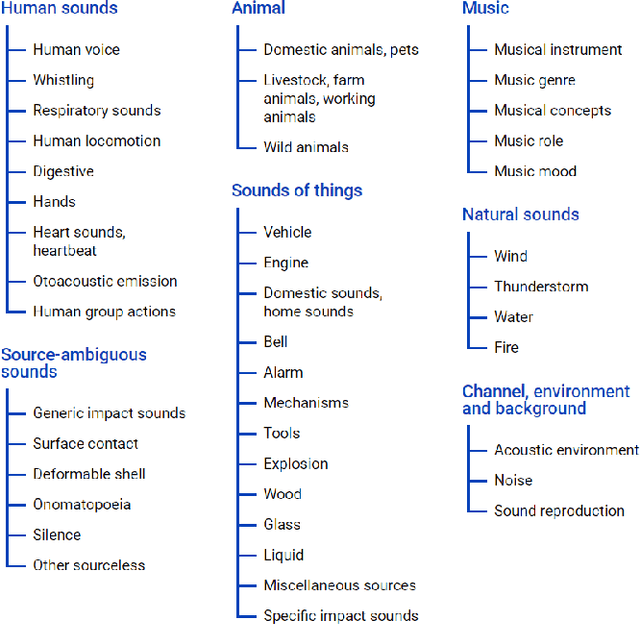

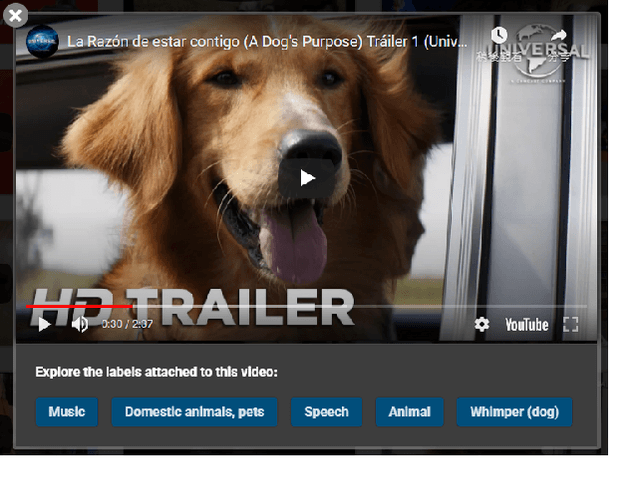

Ontologies encompass a formal representation of knowledge through the definition of concepts or properties of a domain, and the relationships between those concepts. In this work, we seek to investigate whether using this ontological information will improve learning from weakly labeled data, which are easier to collect since it requires only the presence or absence of an event to be known. We use the AudioSet ontology and dataset, which contains audio clips weakly labeled with the ontology concepts and the ontology providing the "Is A" relations between the concepts. We first re-implemented the model proposed by soundevent_ontology with modification to fit the multi-label scenario and then expand on that idea by using a Graph Convolutional Network (GCN) to model the ontology information to learn the concepts. We find that the baseline Siamese does not perform better by incorporating ontology information in the weak and multi-label scenario, but that the GCN does capture the ontology knowledge better for weak, multi-labeled data. In our experiments, we also investigate how different modules can tolerate noises introduced from weak labels and better incorporate ontology information. Our best Siamese-GCN model achieves mAP=0.45 and AUC=0.87 for lower-level concepts and mAP=0.72 and AUC=0.86 for higher-level concepts, which is an improvement over the baseline Siamese but about the same as our models that do not use ontology information.
Do Deep Learning Models and News Headlines Outperform Conventional Prediction Techniques on Forex Data?
May 22, 2022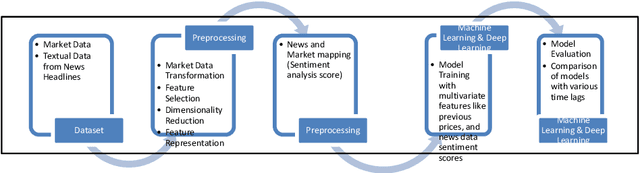

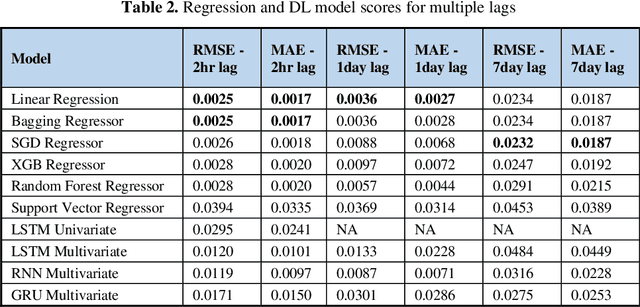
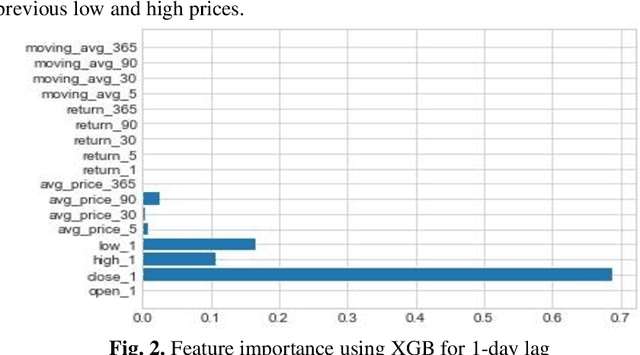
Foreign Exchange (FOREX) is a decentralised global market for exchanging currencies. The Forex market is enormous, and it operates 24 hours a day. Along with country-specific factors, Forex trading is influenced by cross-country ties and a variety of global events. Recent pandemic scenarios such as COVID19 and local elections can also have a significant impact on market pricing. We tested and compared various predictions with external elements such as news items in this work. Additionally, we compared classical machine learning methods to deep learning algorithms. We also added sentiment features from news headlines using NLP-based word embeddings and compared the performance. Our results indicate that simple regression model like linear, SGD, and Bagged performed better than deep learning models such as LSTM and RNN for single-step forecasting like the next two hours, the next day, and seven days. Surprisingly, news articles failed to improve the predictions indicating domain-based and relevant information only adds value. Among the text vectorization techniques, Word2Vec and SentenceBERT perform better.
Same Neurons, Different Languages: Probing Morphosyntax in Multilingual Pre-trained Models
May 08, 2022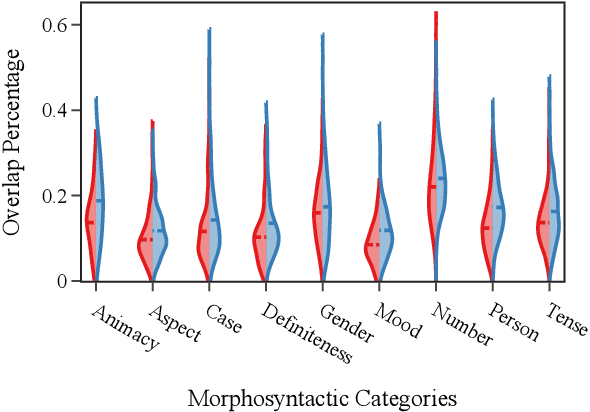
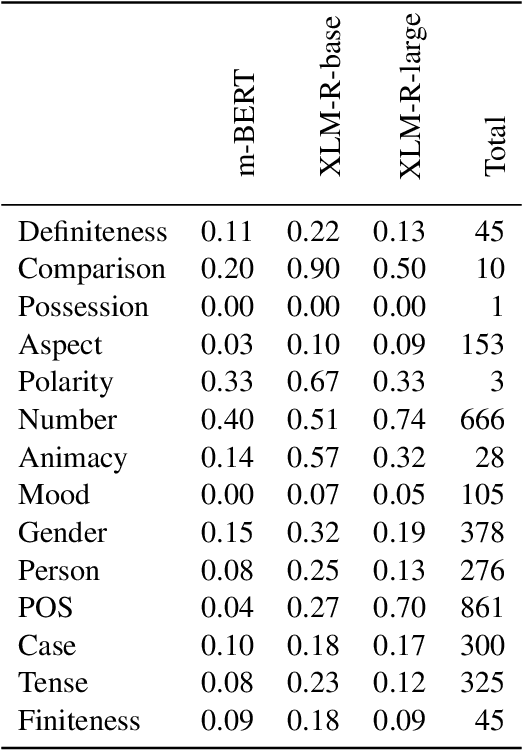
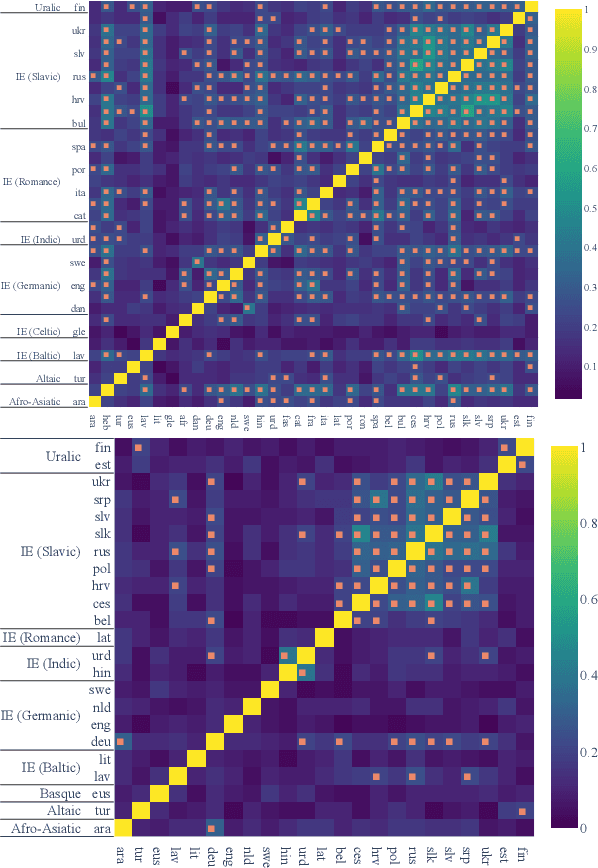
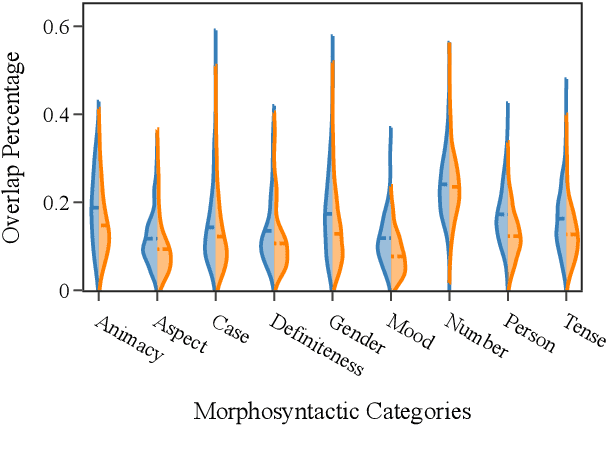
The success of multilingual pre-trained models is underpinned by their ability to learn representations shared by multiple languages even in absence of any explicit supervision. However, it remains unclear how these models learn to generalise across languages. In this work, we conjecture that multilingual pre-trained models can derive language-universal abstractions about grammar. In particular, we investigate whether morphosyntactic information is encoded in the same subset of neurons in different languages. We conduct the first large-scale empirical study over 43 languages and 14 morphosyntactic categories with a state-of-the-art neuron-level probe. Our findings show that the cross-lingual overlap between neurons is significant, but its extent may vary across categories and depends on language proximity and pre-training data size.
Geometric Synthesis: A Free lunch for Large-scale Palmprint Recognition Model Pretraining
Apr 11, 2022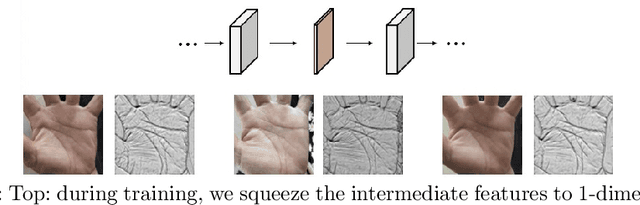

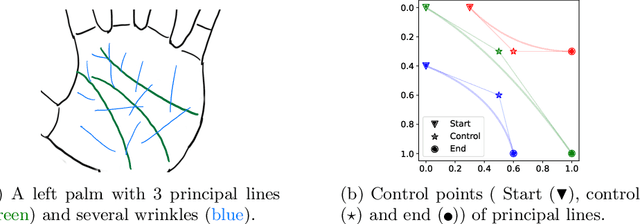
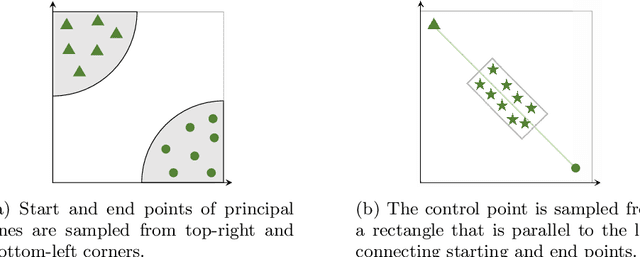
Palmprints are private and stable information for biometric recognition. In the deep learning era, the development of palmprint recognition is limited by the lack of sufficient training data. In this paper, by observing that palmar creases are the key information to deep-learning-based palmprint recognition, we propose to synthesize training data by manipulating palmar creases. Concretely, we introduce an intuitive geometric model which represents palmar creases with parameterized B\'ezier curves. By randomly sampling B\'ezier parameters, we can synthesize massive training samples of diverse identities, which enables us to pretrain large-scale palmprint recognition models. Experimental results demonstrate that such synthetically pretrained models have a very strong generalization ability: they can be efficiently transferred to real datasets, leading to significant performance improvements on palmprint recognition. For example, under the open-set protocol, our method improves the strong ArcFace baseline by more than 10\% in terms of TAR@1e-6. And under the closed-set protocol, our method reduces the equal error rate (EER) by an order of magnitude.
Graph Neural Networks for Multiparallel Word Alignment
Mar 16, 2022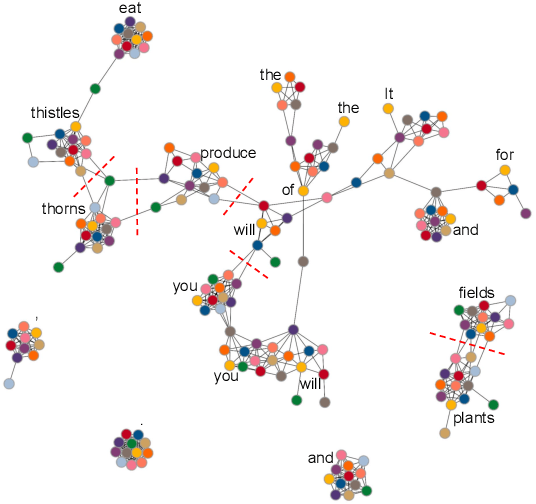
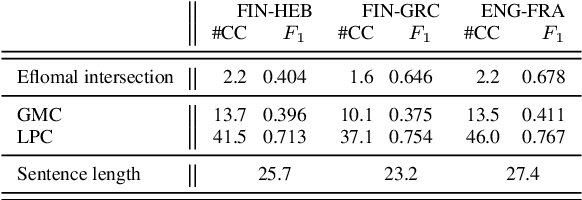
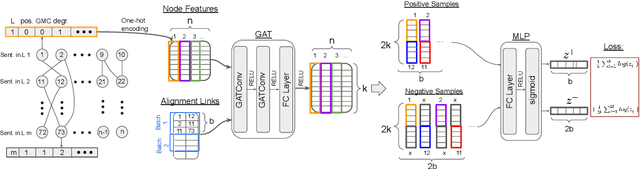
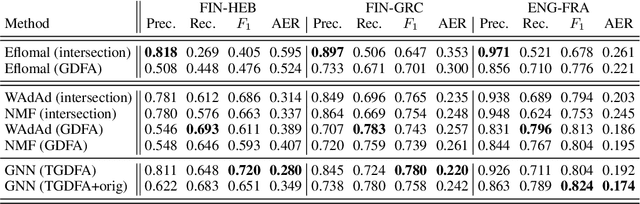
After a period of decrease, interest in word alignments is increasing again for their usefulness in domains such as typological research, cross-lingual annotation projection, and machine translation. Generally, alignment algorithms only use bitext and do not make use of the fact that many parallel corpora are multiparallel. Here, we compute high-quality word alignments between multiple language pairs by considering all language pairs together. First, we create a multiparallel word alignment graph, joining all bilingual word alignment pairs in one graph. Next, we use graph neural networks (GNNs) to exploit the graph structure. Our GNN approach (i) utilizes information about the meaning, position, and language of the input words, (ii) incorporates information from multiple parallel sentences, (iii) adds and removes edges from the initial alignments, and (iv) yields a prediction model that can generalize beyond the training sentences. We show that community detection provides valuable information for multiparallel word alignment. Our method outperforms previous work on three word-alignment datasets and on a downstream task.
Question-Driven Graph Fusion Network For Visual Question Answering
Apr 03, 2022
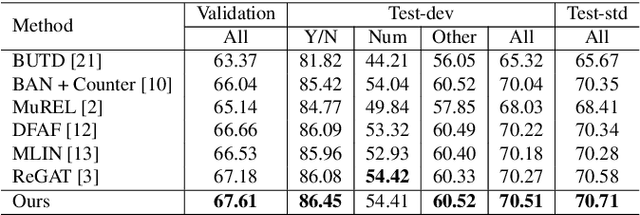
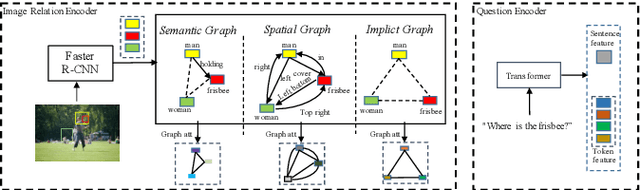
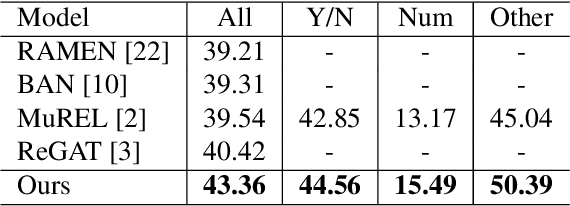
Existing Visual Question Answering (VQA) models have explored various visual relationships between objects in the image to answer complex questions, which inevitably introduces irrelevant information brought by inaccurate object detection and text grounding. To address the problem, we propose a Question-Driven Graph Fusion Network (QD-GFN). It first models semantic, spatial, and implicit visual relations in images by three graph attention networks, then question information is utilized to guide the aggregation process of the three graphs, further, our QD-GFN adopts an object filtering mechanism to remove question-irrelevant objects contained in the image. Experiment results demonstrate that our QD-GFN outperforms the prior state-of-the-art on both VQA 2.0 and VQA-CP v2 datasets. Further analysis shows that both the novel graph aggregation method and object filtering mechanism play a significant role in improving the performance of the model.
WaveMix-Lite: A Resource-efficient Neural Network for Image Analysis
Jun 01, 2022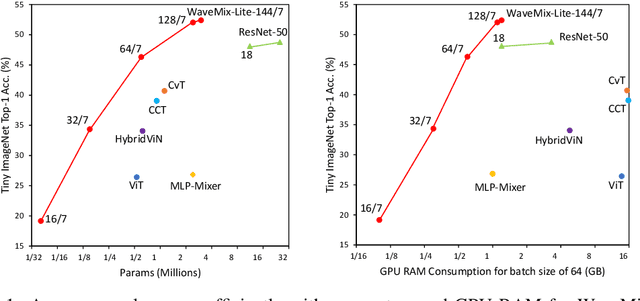
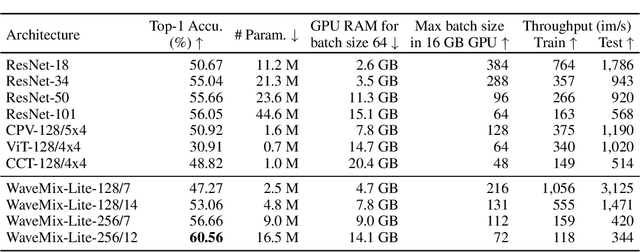
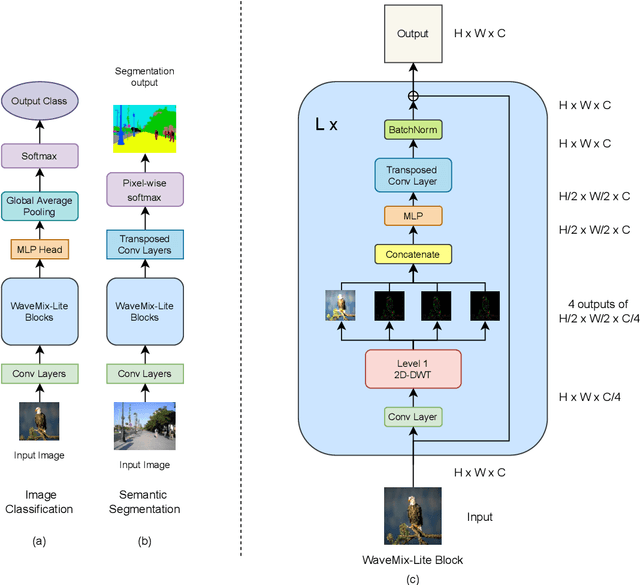
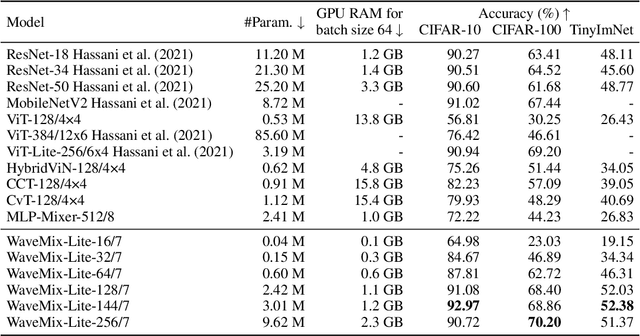
Gains in the ability to generalize on image analysis tasks for neural networks have come at the cost of increased number of parameters and layers, dataset sizes, training and test computations, and GPU RAM. We introduce a new architecture -- WaveMix-Lite -- that can generalize on par with contemporary transformers and convolutional neural networks (CNNs) while needing fewer resources. WaveMix-Lite uses 2D-discrete wavelet transform to efficiently mix spatial information from pixels. WaveMix-Lite seems to be a versatile and scalable architectural framework that can be used for multiple vision tasks, such as image classification and semantic segmentation, without requiring significant architectural changes, unlike transformers and CNNs. It is able to meet or exceed several accuracy benchmarks while training on a single GPU. For instance, it achieves state-of-the-art accuracy on five EMNIST datasets, outperforms CNNs and transformers in ImageNet-1K (64$\times$64 images), and achieves an mIoU of 75.32 % on Cityscapes validation set, while using less than one-fifth the number parameters and half the GPU RAM of comparable CNNs or transformers. Our experiments show that while the convolutional elements of neural architectures exploit the shift-invariance property of images, new types of layers (e.g., wavelet transform) can exploit additional properties of images, such as scale-invariance and finite spatial extents of objects.
From "Where" to "What": Towards Human-Understandable Explanations through Concept Relevance Propagation
Jun 07, 2022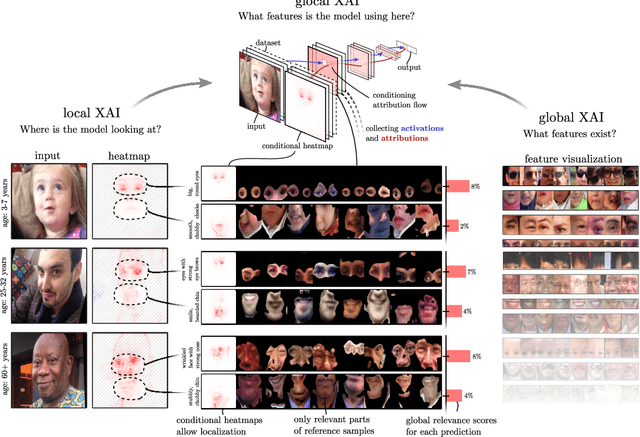
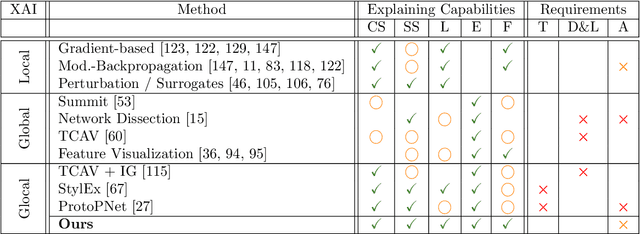
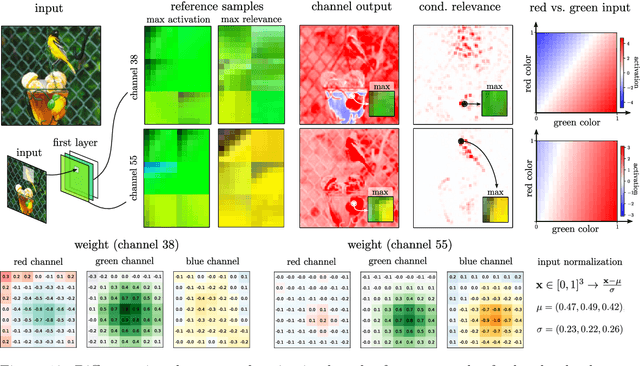

The emerging field of eXplainable Artificial Intelligence (XAI) aims to bring transparency to today's powerful but opaque deep learning models. While local XAI methods explain individual predictions in form of attribution maps, thereby identifying where important features occur (but not providing information about what they represent), global explanation techniques visualize what concepts a model has generally learned to encode. Both types of methods thus only provide partial insights and leave the burden of interpreting the model's reasoning to the user. Only few contemporary techniques aim at combining the principles behind both local and global XAI for obtaining more informative explanations. Those methods, however, are often limited to specific model architectures or impose additional requirements on training regimes or data and label availability, which renders the post-hoc application to arbitrarily pre-trained models practically impossible. In this work we introduce the Concept Relevance Propagation (CRP) approach, which combines the local and global perspectives of XAI and thus allows answering both the "where" and "what" questions for individual predictions, without additional constraints imposed. We further introduce the principle of Relevance Maximization for finding representative examples of encoded concepts based on their usefulness to the model. We thereby lift the dependency on the common practice of Activation Maximization and its limitations. We demonstrate the capabilities of our methods in various settings, showcasing that Concept Relevance Propagation and Relevance Maximization lead to more human interpretable explanations and provide deep insights into the model's representations and reasoning through concept atlases, concept composition analyses, and quantitative investigations of concept subspaces and their role in fine-grained decision making.
FairVFL: A Fair Vertical Federated Learning Framework with Contrastive Adversarial Learning
Jun 07, 2022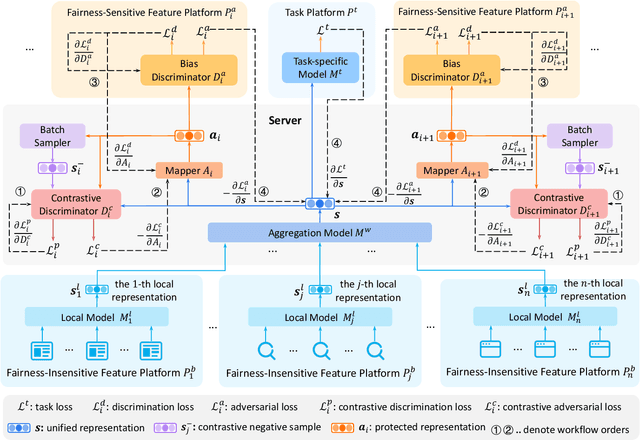
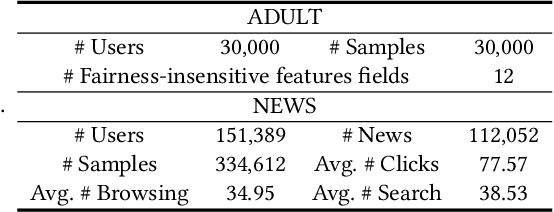
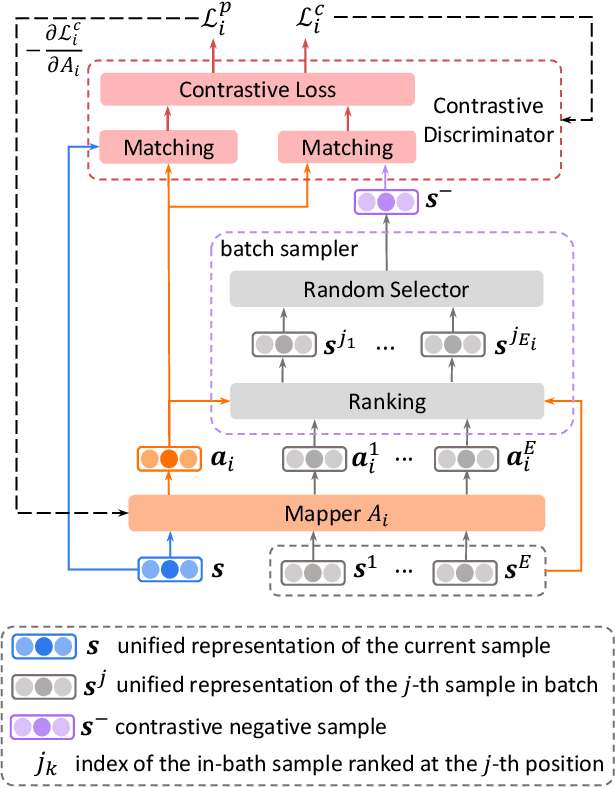
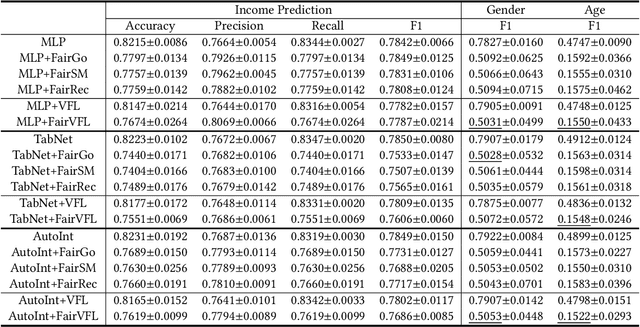
Vertical federated learning (VFL) is a privacy-preserving machine learning paradigm that can learn models from features distributed on different platforms in a privacy-preserving way. Since in real-world applications the data may contain bias on fairness-sensitive features (e.g., gender), VFL models may inherit bias from training data and become unfair for some user groups. However, existing fair ML methods usually rely on the centralized storage of fairness-sensitive features to achieve model fairness, which are usually inapplicable in federated scenarios. In this paper, we propose a fair vertical federated learning framework (FairVFL), which can improve the fairness of VFL models. The core idea of FairVFL is to learn unified and fair representations of samples based on the decentralized feature fields in a privacy-preserving way. Specifically, each platform with fairness-insensitive features first learns local data representations from local features. Then, these local representations are uploaded to a server and aggregated into a unified representation for the target task. In order to learn fair unified representations, we send them to each platform storing fairness-sensitive features and apply adversarial learning to remove bias from the unified representations inherited from the biased data. Moreover, for protecting user privacy, we further propose a contrastive adversarial learning method to remove privacy information from the unified representations in server before sending them to the platforms keeping fairness-sensitive features. Experiments on two real-world datasets validate that our method can effectively improve model fairness with user privacy well-protected.