 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Visual Prompts for Guiding the Attention of Vision Transformers
Jun 05, 2024



Visual prompting infuses visual information into the input image to adapt models toward specific predictions and tasks. Recently, manually crafted markers such as red circles are shown to guide the model to attend to a target region on the image. However, these markers only work on models trained with data containing those markers. Moreover, finding these prompts requires guesswork or prior knowledge of the domain on which the model is trained. This work circumvents manual design constraints by proposing to learn the visual prompts for guiding the attention of vision transformers. The learned visual prompt, added to any input image would redirect the attention of the pre-trained vision transformer to its spatial location on the image. Specifically, the prompt is learned in a self-supervised manner without requiring annotations and without fine-tuning the vision transformer. Our experiments demonstrate the effectiveness of the proposed optimization-based visual prompting strategy across various pre-trained vision encoders.
Glot500: Scaling Multilingual Corpora and Language Models to 500 Languages
May 26, 2023



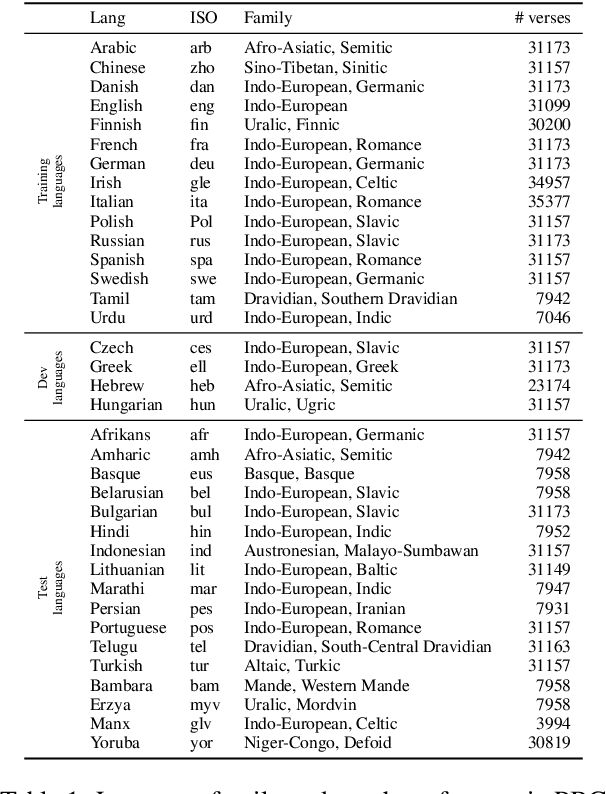
The NLP community has mainly focused on scaling Large Language Models (LLMs) vertically, i.e., making them better for about 100 languages. We instead scale LLMs horizontally: we create, through continued pretraining, Glot500-m, an LLM that covers 511 predominantly low-resource languages. An important part of this effort is to collect and clean Glot500-c, a corpus that covers these 511 languages and allows us to train Glot500-m. We evaluate Glot500-m on five diverse tasks across these languages. We observe large improvements for both high-resource and low-resource languages compared to an XLM-R baseline. Our analysis shows that no single factor explains the quality of multilingual LLM representations. Rather, a combination of factors determines quality including corpus size, script, "help" from related languages and the total capacity of the model. Our work addresses an important goal of NLP research: we should not limit NLP to a small fraction of the world's languages and instead strive to support as many languages as possible to bring the benefits of NLP technology to all languages and cultures. Code, data and models are available at https://github.com/cisnlp/Glot500.
Graph-Based Multilingual Label Propagation for Low-Resource Part-of-Speech Tagging
Oct 18, 2022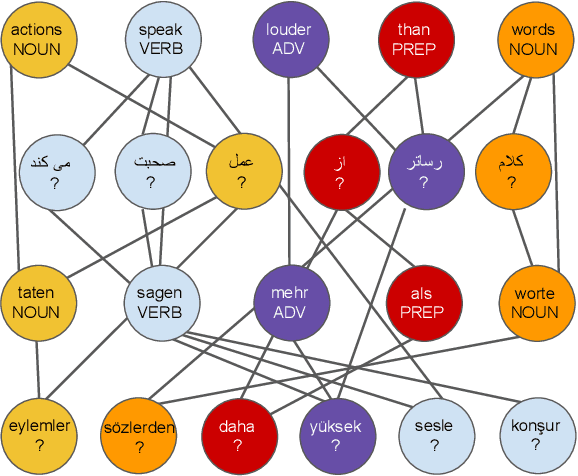
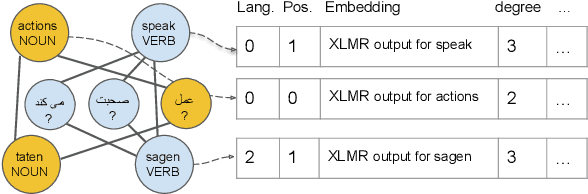

Part-of-Speech (POS) tagging is an important component of the NLP pipeline, but many low-resource languages lack labeled data for training. An established method for training a POS tagger in such a scenario is to create a labeled training set by transferring from high-resource languages. In this paper, we propose a novel method for transferring labels from multiple high-resource source to low-resource target languages. We formalize POS tag projection as graph-based label propagation. Given translations of a sentence in multiple languages, we create a graph with words as nodes and alignment links as edges by aligning words for all language pairs. We then propagate node labels from source to target using a Graph Neural Network augmented with transformer layers. We show that our propagation creates training sets that allow us to train POS taggers for a diverse set of languages. When combined with enhanced contextualized embeddings, our method achieves a new state-of-the-art for unsupervised POS tagging of low-resource languages.
Don't Forget Cheap Training Signals Before Building Unsupervised Bilingual Word Embeddings
May 31, 2022
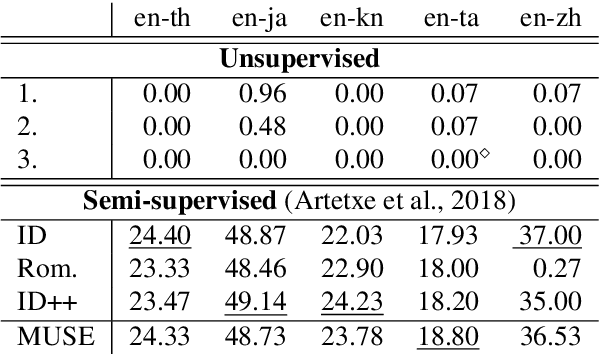
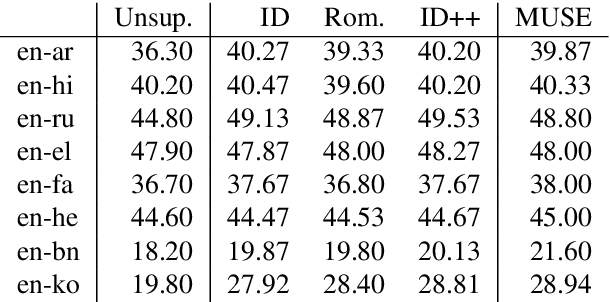
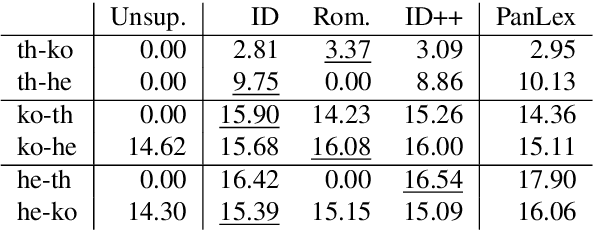
Bilingual Word Embeddings (BWEs) are one of the cornerstones of cross-lingual transfer of NLP models. They can be built using only monolingual corpora without supervision leading to numerous works focusing on unsupervised BWEs. However, most of the current approaches to build unsupervised BWEs do not compare their results with methods based on easy-to-access cross-lingual signals. In this paper, we argue that such signals should always be considered when developing unsupervised BWE methods. The two approaches we find most effective are: 1) using identical words as seed lexicons (which unsupervised approaches incorrectly assume are not available for orthographically distinct language pairs) and 2) combining such lexicons with pairs extracted by matching romanized versions of words with an edit distance threshold. We experiment on thirteen non-Latin languages (and English) and show that such cheap signals work well and that they outperform using more complex unsupervised methods on distant language pairs such as Chinese, Japanese, Kannada, Tamil, and Thai. In addition, they are even competitive with the use of high-quality lexicons in supervised approaches. Our results show that these training signals should not be neglected when building BWEs, even for distant languages.
CaMEL: Case Marker Extraction without Labels
Mar 28, 2022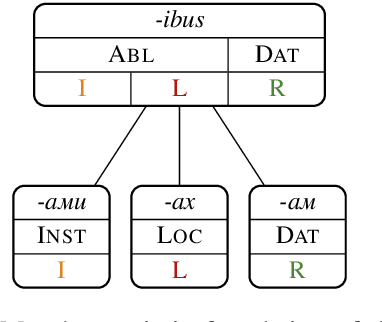

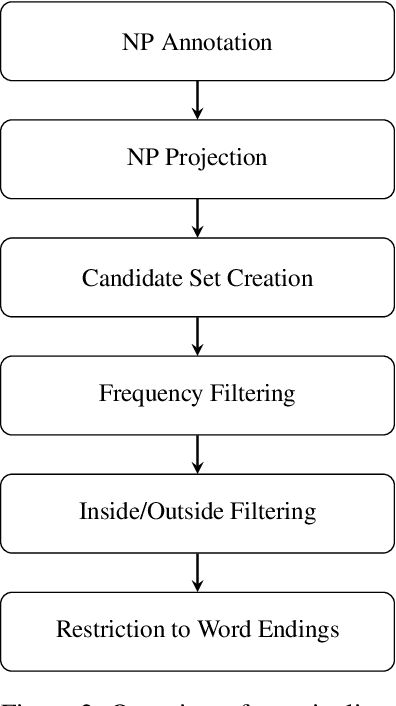
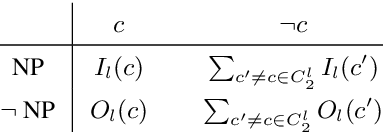
We introduce CaMEL (Case Marker Extraction without Labels), a novel and challenging task in computational morphology that is especially relevant for low-resource languages. We propose a first model for CaMEL that uses a massively multilingual corpus to extract case markers in 83 languages based only on a noun phrase chunker and an alignment system. To evaluate CaMEL, we automatically construct a silver standard from UniMorph. The case markers extracted by our model can be used to detect and visualise similarities and differences between the case systems of different languages as well as to annotate fine-grained deep cases in languages in which they are not overtly marked.
Graph Neural Networks for Multiparallel Word Alignment
Mar 16, 2022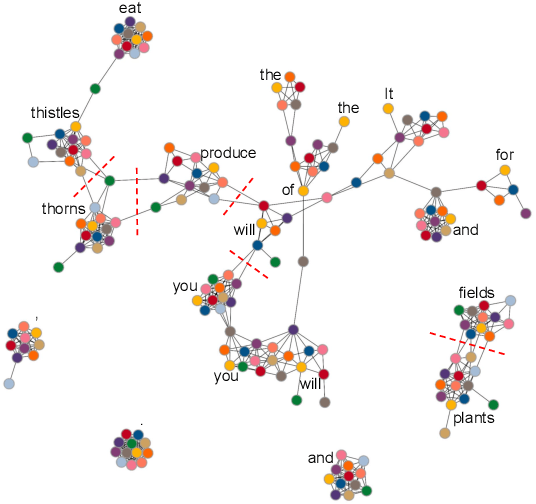
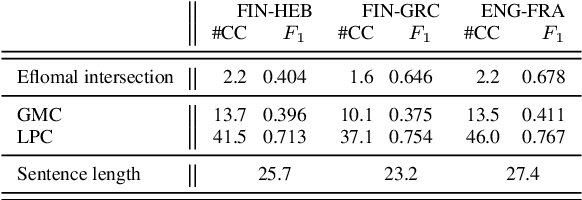
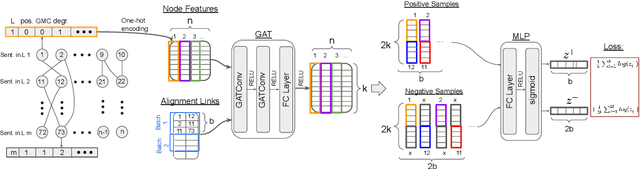
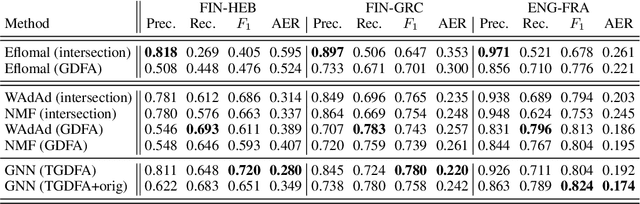
After a period of decrease, interest in word alignments is increasing again for their usefulness in domains such as typological research, cross-lingual annotation projection, and machine translation. Generally, alignment algorithms only use bitext and do not make use of the fact that many parallel corpora are multiparallel. Here, we compute high-quality word alignments between multiple language pairs by considering all language pairs together. First, we create a multiparallel word alignment graph, joining all bilingual word alignment pairs in one graph. Next, we use graph neural networks (GNNs) to exploit the graph structure. Our GNN approach (i) utilizes information about the meaning, position, and language of the input words, (ii) incorporates information from multiple parallel sentences, (iii) adds and removes edges from the initial alignments, and (iv) yields a prediction model that can generalize beyond the training sentences. We show that community detection provides valuable information for multiparallel word alignment. Our method outperforms previous work on three word-alignment datasets and on a downstream task.
Graph Algorithms for Multiparallel Word Alignment
Sep 13, 2021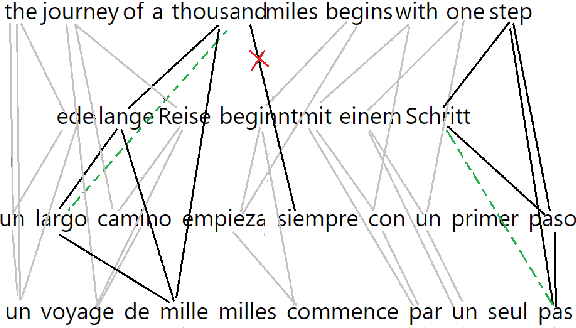


With the advent of end-to-end deep learning approaches in machine translation, interest in word alignments initially decreased; however, they have again become a focus of research more recently. Alignments are useful for typological research, transferring formatting like markup to translated texts, and can be used in the decoding of machine translation systems. At the same time, massively multilingual processing is becoming an important NLP scenario, and pretrained language and machine translation models that are truly multilingual are proposed. However, most alignment algorithms rely on bitexts only and do not leverage the fact that many parallel corpora are multiparallel. In this work, we exploit the multiparallelity of corpora by representing an initial set of bilingual alignments as a graph and then predicting additional edges in the graph. We present two graph algorithms for edge prediction: one inspired by recommender systems and one based on network link prediction. Our experimental results show absolute improvements in $F_1$ of up to 28% over the baseline bilingual word aligner in different datasets.
ParCourE: A Parallel Corpus Explorer for a Massively Multilingual Corpus
Jul 15, 2021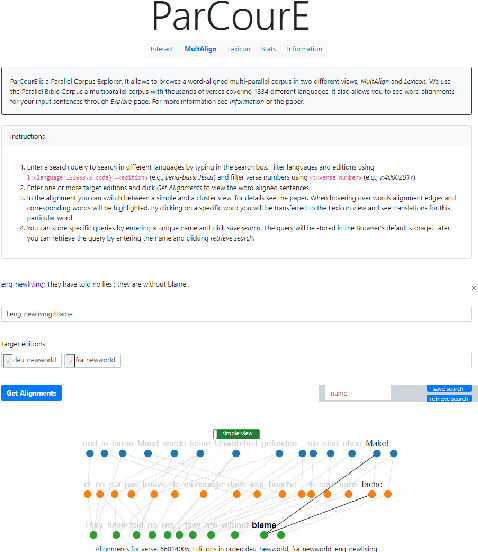

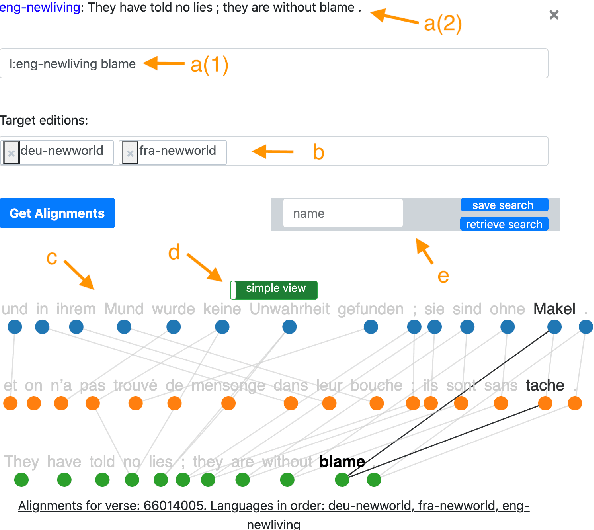

With more than 7000 languages worldwide, multilingual natural language processing (NLP) is essential both from an academic and commercial perspective. Researching typological properties of languages is fundamental for progress in multilingual NLP. Examples include assessing language similarity for effective transfer learning, injecting inductive biases into machine learning models or creating resources such as dictionaries and inflection tables. We provide ParCourE, an online tool that allows to browse a word-aligned parallel corpus, covering 1334 languages. We give evidence that this is useful for typological research. ParCourE can be set up for any parallel corpus and can thus be used for typological research on other corpora as well as for exploring their quality and properties.
Subword Sampling for Low Resource Word Alignment
Dec 21, 2020
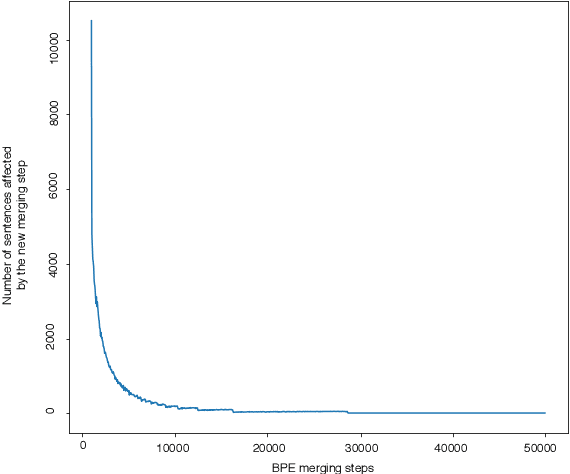
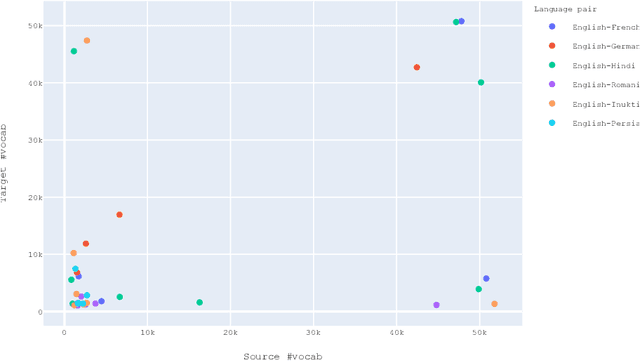
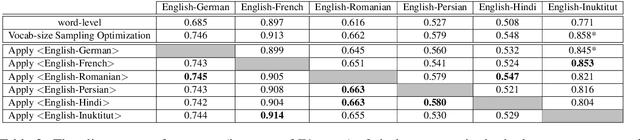
Annotation projection is an important area in NLP that can greatly contribute to creating language resources for low-resource languages. Word alignment plays a key role in this setting. However, most of the existing word alignment methods are designed for a high resource setting in machine translation where millions of parallel sentences are available. This amount reduces to a few thousands of sentences when dealing with low-resource languages failing the existing established IBM models. In this paper, we propose subword sampling-based alignment of text units. This method's hypothesis is that the aggregation of different granularities of text for certain language pairs can help word-level alignment. For certain languages for which gold-standard alignments exist, we propose an iterative Bayesian optimization framework to optimize selecting possible subwords from the space of possible subword representations of the source and target sentences. We show that the subword sampling method consistently outperforms word-level alignment on six language pairs: English-German, English-French, English-Romanian, English-Persian, English-Hindi, and English-Inuktitut. In addition, we show that the hyperparameters learned for certain language pairs can be applied to other languages at no supervision and consistently improve the alignment results. We observe that using $5K$ parallel sentences together with our proposed subword sampling approach, we obtain similar F1 scores to the use of $100K$'s of parallel sentences in existing word-level fast-align/eflomal alignment methods.
SimAlign: High Quality Word Alignments without Parallel Training Data using Static and Contextualized Embeddings
Apr 27, 2020
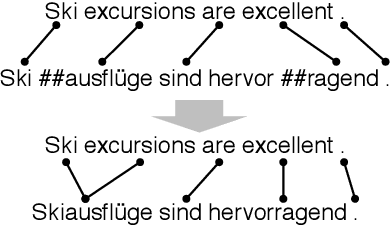
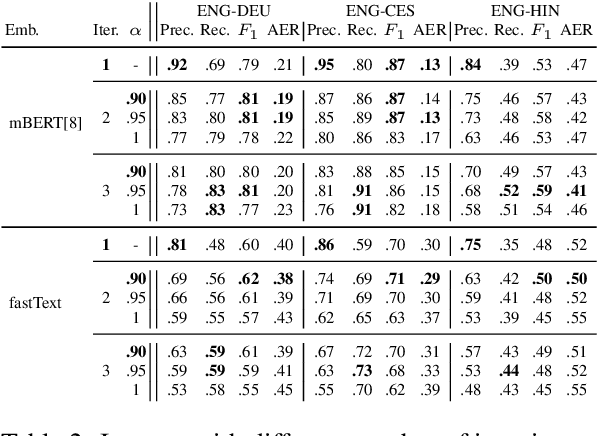
Word alignments are useful for tasks like statistical and neural machine translation (NMT) and annotation projection. Statistical word aligners perform well, as do methods that extract alignments jointly with translations in NMT. However, most approaches require parallel training data and quality decreases as less training data is available. We propose word alignment methods that require no parallel data. The key idea is to leverage multilingual word embeddings, both static and contextualized, for word alignment. Our multilingual embeddings are created from monolingual data only without relying on any parallel data or dictionaries. We find that alignments created from embeddings are competitive and mostly superior to traditional statistical aligners, even in scenarios with abundant parallel data. For example, for a set of 100k parallel sentences, contextualized embeddings achieve a word alignment F1 for English-German that is more than 5% higher (absolute) than eflomal, a high quality alignment model.