 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLieSolver: A PDE-constrained solver for IBVPs using Lie symmetries
Oct 29, 2025We introduce a method for efficiently solving initial-boundary value problems (IBVPs) that uses Lie symmetries to enforce the associated partial differential equation (PDE) exactly by construction. By leveraging symmetry transformations, the model inherently incorporates the physical laws and learns solutions from initial and boundary data. As a result, the loss directly measures the model's accuracy, leading to improved convergence. Moreover, for well-posed IBVPs, our method enables rigorous error estimation. The approach yields compact models, facilitating an efficient optimization. We implement LieSolver and demonstrate its application to linear homogeneous PDEs with a range of initial conditions, showing that it is faster and more accurate than physics-informed neural networks (PINNs). Overall, our method improves both computational efficiency and the reliability of predictions for PDE-constrained problems.
Attribution-guided Pruning for Compression, Circuit Discovery, and Targeted Correction in LLMs
Jun 16, 2025Large Language Models (LLMs) are central to many contemporary AI applications, yet their extensive parameter counts pose significant challenges for deployment in memory- and compute-constrained environments. Recent works in eXplainable AI (XAI), particularly on attribution methods, suggest that interpretability can also enable model compression by identifying and removing components irrelevant to inference. In this paper, we leverage Layer-wise Relevance Propagation (LRP) to perform attribution-guided pruning of LLMs. While LRP has shown promise in structured pruning for vision models, we extend it to unstructured pruning in LLMs and demonstrate that it can substantially reduce model size with minimal performance loss. Our method is especially effective in extracting task-relevant subgraphs -- so-called ``circuits'' -- which can represent core functions (e.g., indirect object identification). Building on this, we introduce a technique for model correction, by selectively removing circuits responsible for spurious behaviors (e.g., toxic outputs). All in all, we gather these techniques as a uniform holistic framework and showcase its effectiveness and limitations through extensive experiments for compression, circuit discovery and model correction on Llama and OPT models, highlighting its potential for improving both model efficiency and safety. Our code is publicly available at https://github.com/erfanhatefi/SparC3.
Optimizing Learned Image Compression on Scalar and Entropy-Constraint Quantization
Jun 10, 2025The continuous improvements on image compression with variational autoencoders have lead to learned codecs competitive with conventional approaches in terms of rate-distortion efficiency. Nonetheless, taking the quantization into account during the training process remains a problem, since it produces zero derivatives almost everywhere and needs to be replaced with a differentiable approximation which allows end-to-end optimization. Though there are different methods for approximating the quantization, none of them model the quantization noise correctly and thus, result in suboptimal networks. Hence, we propose an additional finetuning training step: After conventional end-to-end training, parts of the network are retrained on quantized latents obtained at the inference stage. For entropy-constraint quantizers like Trellis-Coded Quantization, the impact of the quantizer is particularly difficult to approximate by rounding or adding noise as the quantized latents are interdependently chosen through a trellis search based on both the entropy model and a distortion measure. We show that retraining on correctly quantized data consistently yields additional coding gain for both uniform scalar and especially for entropy-constraint quantization, without increasing inference complexity. For the Kodak test set, we obtain average savings between 1% and 2%, and for the TecNick test set up to 2.2% in terms of Bj{\o}ntegaard-Delta bitrate.
* Accepted at ICIP2024, the IEEE International Conference on Image Processing
From What to How: Attributing CLIP's Latent Components Reveals Unexpected Semantic Reliance
May 26, 2025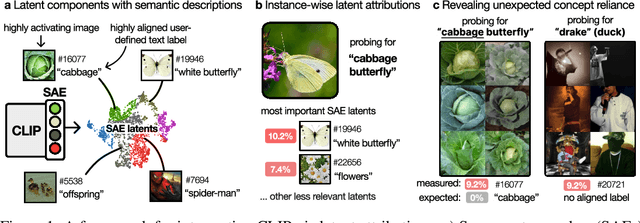
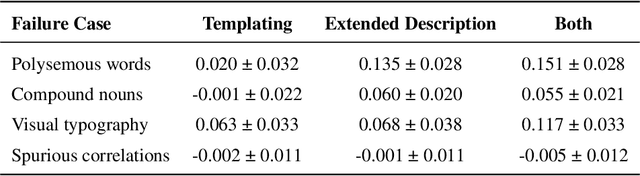
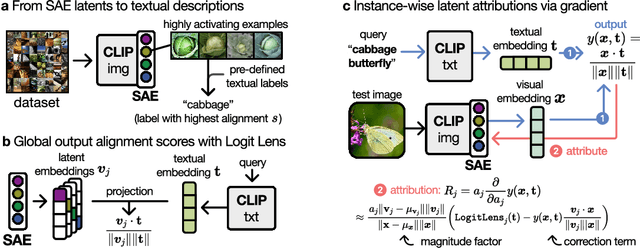
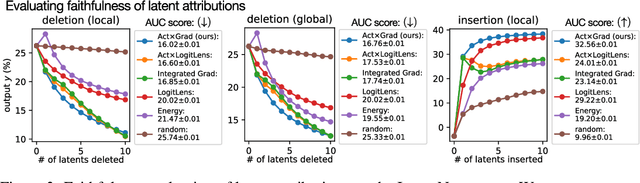
Transformer-based CLIP models are widely used for text-image probing and feature extraction, making it relevant to understand the internal mechanisms behind their predictions. While recent works show that Sparse Autoencoders (SAEs) yield interpretable latent components, they focus on what these encode and miss how they drive predictions. We introduce a scalable framework that reveals what latent components activate for, how they align with expected semantics, and how important they are to predictions. To achieve this, we adapt attribution patching for instance-wise component attributions in CLIP and highlight key faithfulness limitations of the widely used Logit Lens technique. By combining attributions with semantic alignment scores, we can automatically uncover reliance on components that encode semantically unexpected or spurious concepts. Applied across multiple CLIP variants, our method uncovers hundreds of surprising components linked to polysemous words, compound nouns, visual typography and dataset artifacts. While text embeddings remain prone to semantic ambiguity, they are more robust to spurious correlations compared to linear classifiers trained on image embeddings. A case study on skin lesion detection highlights how such classifiers can amplify hidden shortcuts, underscoring the need for holistic, mechanistic interpretability. We provide code at https://github.com/maxdreyer/attributing-clip.
The Atlas of In-Context Learning: How Attention Heads Shape In-Context Retrieval Augmentation
May 21, 2025Large language models are able to exploit in-context learning to access external knowledge beyond their training data through retrieval-augmentation. While promising, its inner workings remain unclear. In this work, we shed light on the mechanism of in-context retrieval augmentation for question answering by viewing a prompt as a composition of informational components. We propose an attribution-based method to identify specialized attention heads, revealing in-context heads that comprehend instructions and retrieve relevant contextual information, and parametric heads that store entities' relational knowledge. To better understand their roles, we extract function vectors and modify their attention weights to show how they can influence the answer generation process. Finally, we leverage the gained insights to trace the sources of knowledge used during inference, paving the way towards more safe and transparent language models.
FADE: Why Bad Descriptions Happen to Good Features
Feb 24, 2025Recent advances in mechanistic interpretability have highlighted the potential of automating interpretability pipelines in analyzing the latent representations within LLMs. While they may enhance our understanding of internal mechanisms, the field lacks standardized evaluation methods for assessing the validity of discovered features. We attempt to bridge this gap by introducing FADE: Feature Alignment to Description Evaluation, a scalable model-agnostic framework for evaluating feature-description alignment. FADE evaluates alignment across four key metrics - Clarity, Responsiveness, Purity, and Faithfulness - and systematically quantifies the causes for the misalignment of feature and their description. We apply FADE to analyze existing open-source feature descriptions, and assess key components of automated interpretability pipelines, aiming to enhance the quality of descriptions. Our findings highlight fundamental challenges in generating feature descriptions, particularly for SAEs as compared to MLP neurons, providing insights into the limitations and future directions of automated interpretability. We release FADE as an open-source package at: https://github.com/brunibrun/FADE.
Ensuring Medical AI Safety: Explainable AI-Driven Detection and Mitigation of Spurious Model Behavior and Associated Data
Jan 23, 2025



Deep neural networks are increasingly employed in high-stakes medical applications, despite their tendency for shortcut learning in the presence of spurious correlations, which can have potentially fatal consequences in practice. Detecting and mitigating shortcut behavior is a challenging task that often requires significant labeling efforts from domain experts. To alleviate this problem, we introduce a semi-automated framework for the identification of spurious behavior from both data and model perspective by leveraging insights from eXplainable Artificial Intelligence (XAI). This allows the retrieval of spurious data points and the detection of model circuits that encode the associated prediction rules. Moreover, we demonstrate how these shortcut encodings can be used for XAI-based sample- and pixel-level data annotation, providing valuable information for bias mitigation methods to unlearn the undesired shortcut behavior. We show the applicability of our framework using four medical datasets across two modalities, featuring controlled and real-world spurious correlations caused by data artifacts. We successfully identify and mitigate these biases in VGG16, ResNet50, and contemporary Vision Transformer models, ultimately increasing their robustness and applicability for real-world medical tasks.
Mechanistic understanding and validation of large AI models with SemanticLens
Jan 09, 2025

Unlike human-engineered systems such as aeroplanes, where each component's role and dependencies are well understood, the inner workings of AI models remain largely opaque, hindering verifiability and undermining trust. This paper introduces SemanticLens, a universal explanation method for neural networks that maps hidden knowledge encoded by components (e.g., individual neurons) into the semantically structured, multimodal space of a foundation model such as CLIP. In this space, unique operations become possible, including (i) textual search to identify neurons encoding specific concepts, (ii) systematic analysis and comparison of model representations, (iii) automated labelling of neurons and explanation of their functional roles, and (iv) audits to validate decision-making against requirements. Fully scalable and operating without human input, SemanticLens is shown to be effective for debugging and validation, summarizing model knowledge, aligning reasoning with expectations (e.g., adherence to the ABCDE-rule in melanoma classification), and detecting components tied to spurious correlations and their associated training data. By enabling component-level understanding and validation, the proposed approach helps bridge the "trust gap" between AI models and traditional engineered systems. We provide code for SemanticLens on https://github.com/jim-berend/semanticlens and a demo on https://semanticlens.hhi-research-insights.eu.
Opportunities and limitations of explaining quantum machine learning
Dec 19, 2024



A common trait of many machine learning models is that it is often difficult to understand and explain what caused the model to produce the given output. While the explainability of neural networks has been an active field of research in the last years, comparably little is known for quantum machine learning models. Despite a few recent works analyzing some specific aspects of explainability, as of now there is no clear big picture perspective as to what can be expected from quantum learning models in terms of explainability. In this work, we address this issue by identifying promising research avenues in this direction and lining out the expected future results. We additionally propose two explanation methods designed specifically for quantum machine learning models, as first of their kind to the best of our knowledge. Next to our pre-view of the field, we compare both existing and novel methods to explain the predictions of quantum learning models. By studying explainability in quantum machine learning, we can contribute to the sustainable development of the field, preventing trust issues in the future.
Quanda: An Interpretability Toolkit for Training Data Attribution Evaluation and Beyond
Oct 10, 2024

In recent years, training data attribution (TDA) methods have emerged as a promising direction for the interpretability of neural networks. While research around TDA is thriving, limited effort has been dedicated to the evaluation of attributions. Similar to the development of evaluation metrics for traditional feature attribution approaches, several standalone metrics have been proposed to evaluate the quality of TDA methods across various contexts. However, the lack of a unified framework that allows for systematic comparison limits trust in TDA methods and stunts their widespread adoption. To address this research gap, we introduce Quanda, a Python toolkit designed to facilitate the evaluation of TDA methods. Beyond offering a comprehensive set of evaluation metrics, Quanda provides a uniform interface for seamless integration with existing TDA implementations across different repositories, thus enabling systematic benchmarking. The toolkit is user-friendly, thoroughly tested, well-documented, and available as an open-source library on PyPi and under https://github.com/dilyabareeva/quanda.