 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Concentration of Data Encoding in Parameterized Quantum Circuits
Jun 16, 2022
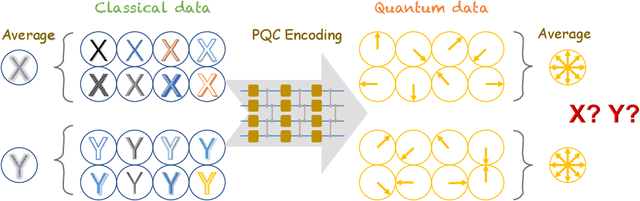

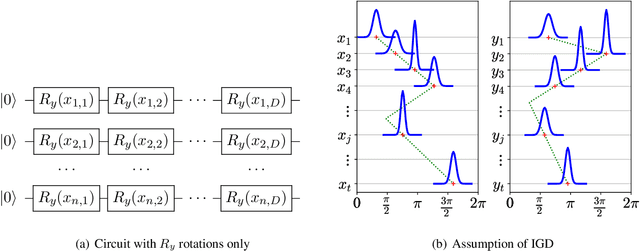
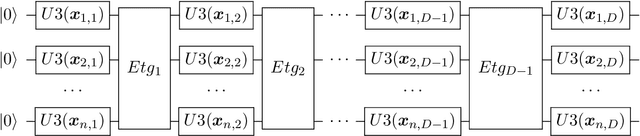
Variational quantum algorithms have been acknowledged as a leading strategy to realize near-term quantum advantages in meaningful tasks, including machine learning and combinatorial optimization. When applied to tasks involving classical data, such algorithms generally begin with quantum circuits for data encoding and then train quantum neural networks (QNNs) to minimize target functions. Although QNNs have been widely studied to improve these algorithms' performance on practical tasks, there is a gap in systematically understanding the influence of data encoding on the eventual performance. In this paper, we make progress in filling this gap by considering the common data encoding strategies based on parameterized quantum circuits. We prove that, under reasonable assumptions, the distance between the average encoded state and the maximally mixed state could be explicitly upper-bounded with respect to the width and depth of the encoding circuit. This result in particular implies that the average encoded state will concentrate on the maximally mixed state at an exponential speed on depth. Such concentration seriously limits the capabilities of quantum classifiers, and strictly restricts the distinguishability of encoded states from a quantum information perspective. We further support our findings by numerically verifying these results on both synthetic and public data sets. Our results highlight the significance of quantum data encoding in machine learning tasks and may shed light on future encoding strategies.
Rank Diminishing in Deep Neural Networks
Jun 13, 2022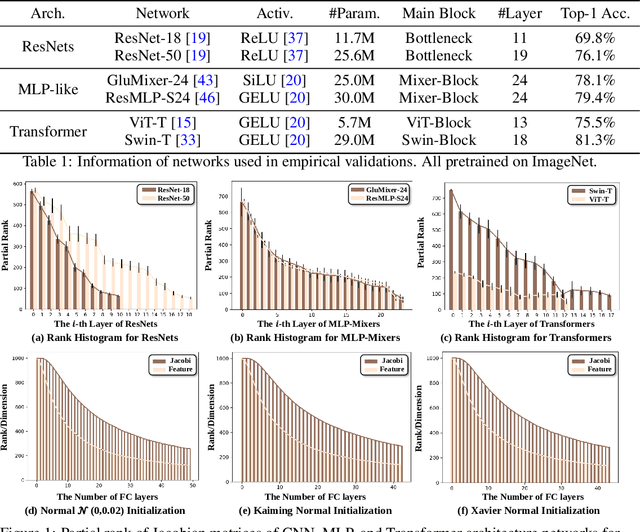
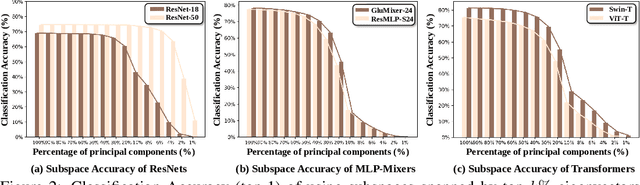
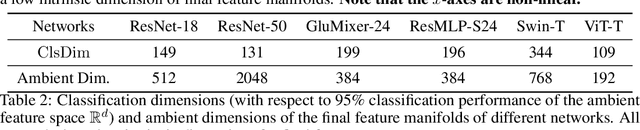
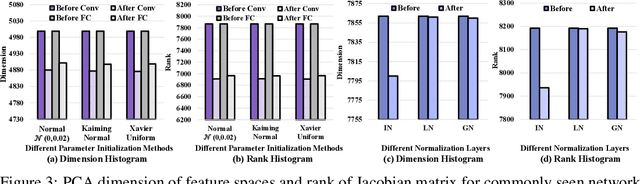
The rank of neural networks measures information flowing across layers. It is an instance of a key structural condition that applies across broad domains of machine learning. In particular, the assumption of low-rank feature representations leads to algorithmic developments in many architectures. For neural networks, however, the intrinsic mechanism that yields low-rank structures remains vague and unclear. To fill this gap, we perform a rigorous study on the behavior of network rank, focusing particularly on the notion of rank deficiency. We theoretically establish a universal monotonic decreasing property of network rank from the basic rules of differential and algebraic composition, and uncover rank deficiency of network blocks and deep function coupling. By virtue of our numerical tools, we provide the first empirical analysis of the per-layer behavior of network rank in practical settings, i.e., ResNets, deep MLPs, and Transformers on ImageNet. These empirical results are in direct accord with our theory. Furthermore, we reveal a novel phenomenon of independence deficit caused by the rank deficiency of deep networks, where classification confidence of a given category can be linearly decided by the confidence of a handful of other categories. The theoretical results of this work, together with the empirical findings, may advance understanding of the inherent principles of deep neural networks.
TridentNetV2: Lightweight Graphical Global Plan Representations for Dynamic Trajectory Generation
Mar 26, 2022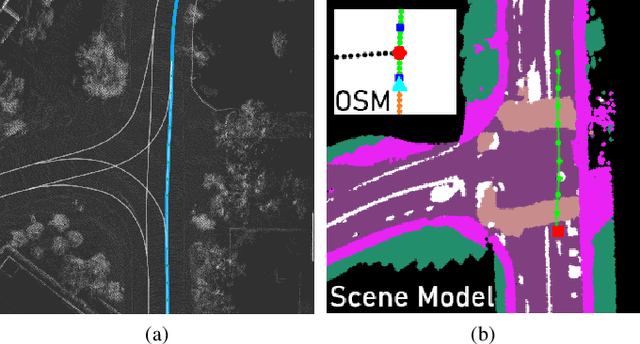
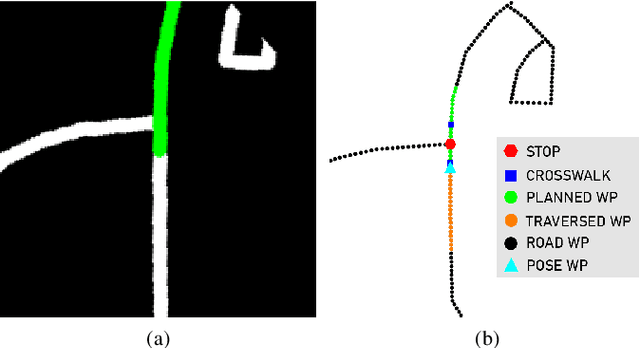
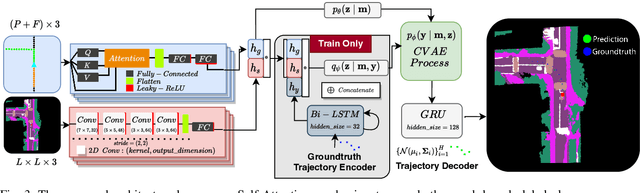
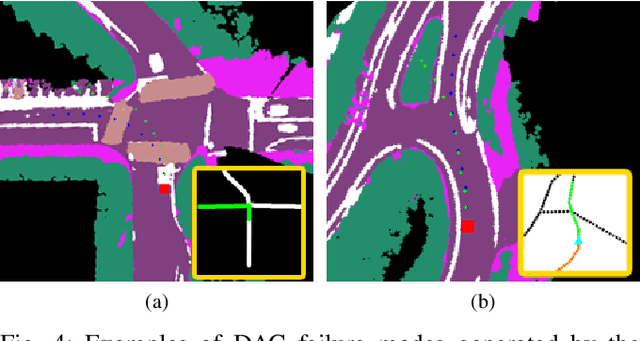
We present a framework for dynamic trajectory generation for autonomous navigation, which does not rely on HD maps as the underlying representation. High Definition (HD) maps have become a key component in most autonomous driving frameworks, which include complete road network information annotated at a centimeter-level that include traversable waypoints, lane information, and traffic signals. Instead, the presented approach models the distributions of feasible ego-centric trajectories in real-time given a nominal graph-based global plan and a lightweight scene representation. By embedding contextual information, such as crosswalks, stop signs, and traffic signals, our approach achieves low errors across multiple urban navigation datasets that include diverse intersection maneuvers, while maintaining real-time performance and reducing network complexity. Underlying datasets introduced are available online.
ME-GCN: Multi-dimensional Edge-Embedded Graph Convolutional Networks for Semi-supervised Text Classification
Apr 10, 2022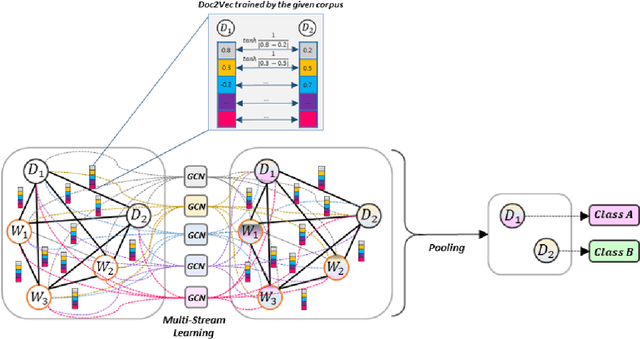
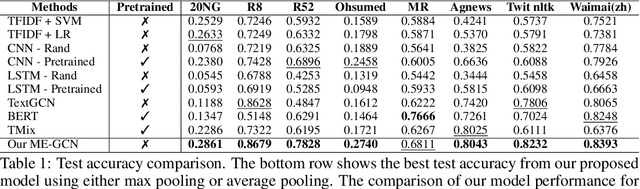
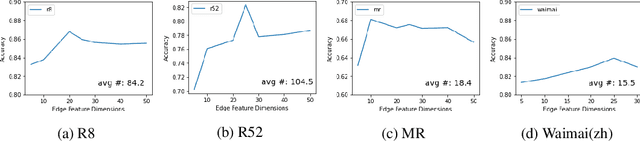

Compared to sequential learning models, graph-based neural networks exhibit excellent ability in capturing global information and have been used for semi-supervised learning tasks. Most Graph Convolutional Networks are designed with the single-dimensional edge feature and failed to utilise the rich edge information about graphs. This paper introduces the ME-GCN (Multi-dimensional Edge-enhanced Graph Convolutional Networks) for semi-supervised text classification. A text graph for an entire corpus is firstly constructed to describe the undirected and multi-dimensional relationship of word-to-word, document-document, and word-to-document. The graph is initialised with corpus-trained multi-dimensional word and document node representation, and the relations are represented according to the distance of those words/documents nodes. Then, the generated graph is trained with ME-GCN, which considers the edge features as multi-stream signals, and each stream performs a separate graph convolutional operation. Our ME-GCN can integrate a rich source of graph edge information of the entire text corpus. The results have demonstrated that our proposed model has significantly outperformed the state-of-the-art methods across eight benchmark datasets.
XYLayoutLM: Towards Layout-Aware Multimodal Networks For Visually-Rich Document Understanding
Mar 15, 2022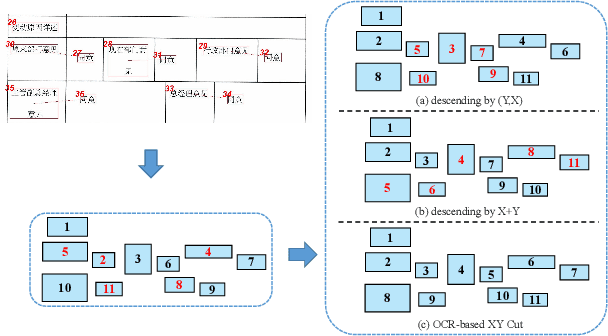
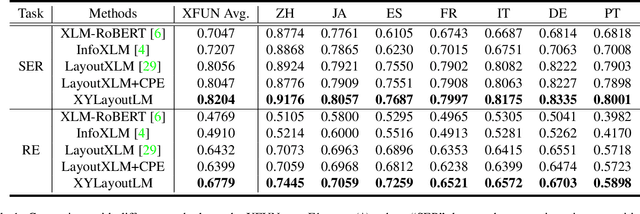
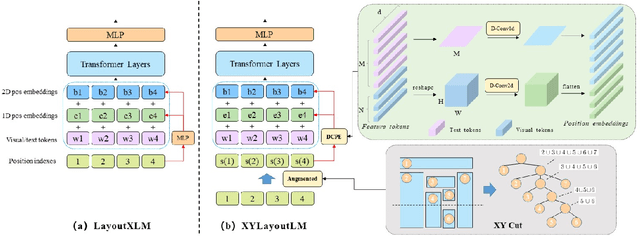
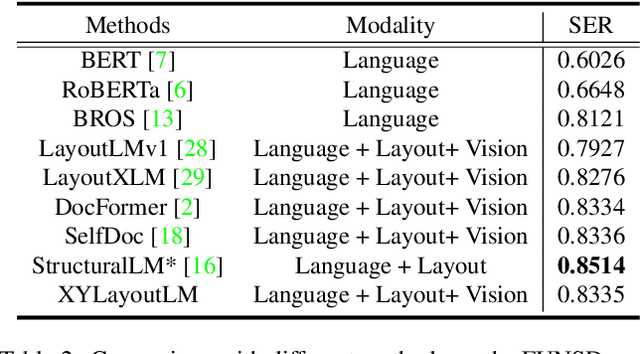
Recently, various multimodal networks for Visually-Rich Document Understanding(VRDU) have been proposed, showing the promotion of transformers by integrating visual and layout information with the text embeddings. However, most existing approaches utilize the position embeddings to incorporate the sequence information, neglecting the noisy improper reading order obtained by OCR tools. In this paper, we propose a robust layout-aware multimodal network named XYLayoutLM to capture and leverage rich layout information from proper reading orders produced by our Augmented XY Cut. Moreover, a Dilated Conditional Position Encoding module is proposed to deal with the input sequence of variable lengths, and it additionally extracts local layout information from both textual and visual modalities while generating position embeddings. Experiment results show that our XYLayoutLM achieves competitive results on document understanding tasks.
Towards Generalizable Person Re-identification with a Bi-stream Generative Model
Jun 19, 2022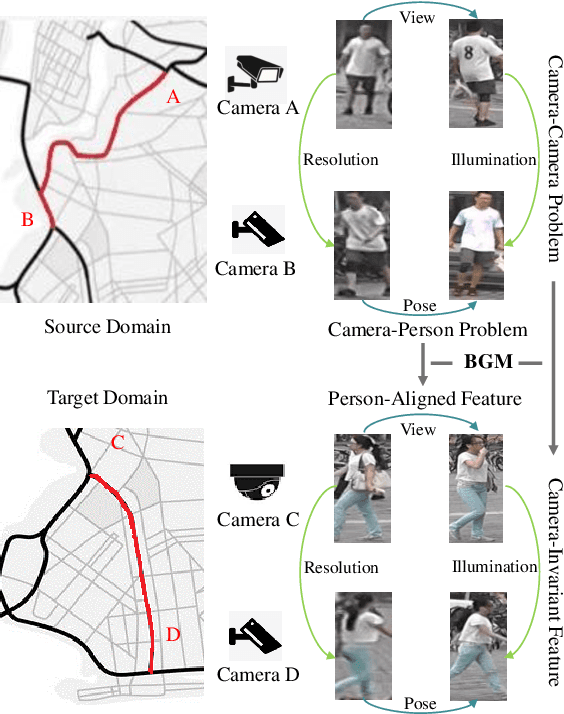
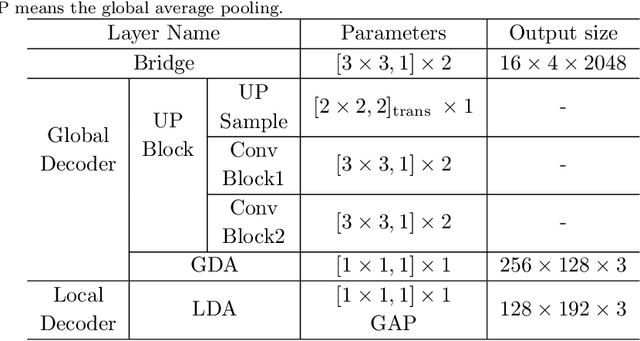
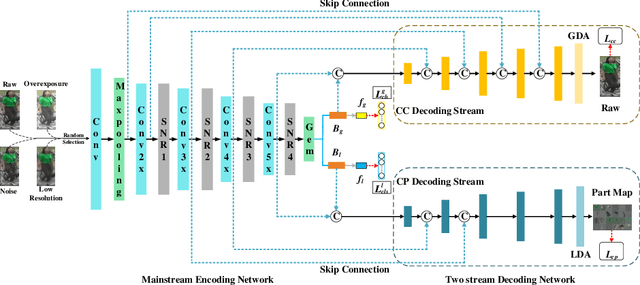
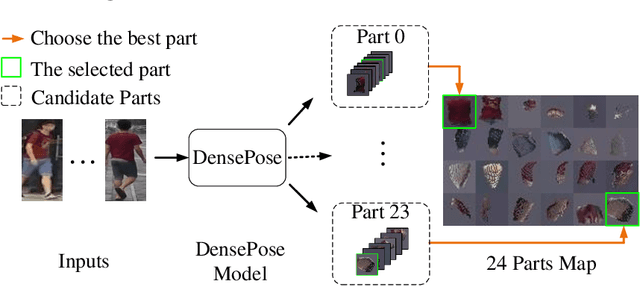
Generalizable person re-identification (re-ID) has attracted growing attention due to its powerful adaptation capability in the unseen data domain. However, existing solutions often neglect either crossing cameras (e.g., illumination and resolution differences) or pedestrian misalignments (e.g., viewpoint and pose discrepancies), which easily leads to poor generalization capability when adapted to the new domain. In this paper, we formulate these difficulties as: 1) Camera-Camera (CC) problem, which denotes the various human appearance changes caused by different cameras; 2) Camera-Person (CP) problem, which indicates the pedestrian misalignments caused by the same identity person under different camera viewpoints or changing pose. To solve the above issues, we propose a Bi-stream Generative Model (BGM) to learn the fine-grained representations fused with camera-invariant global feature and pedestrian-aligned local feature, which contains an encoding network and two stream decoding sub-networks. Guided by original pedestrian images, one stream is employed to learn a camera-invariant global feature for the CC problem via filtering cross-camera interference factors. For the CP problem, another stream learns a pedestrian-aligned local feature for pedestrian alignment using information-complete densely semantically aligned part maps. Moreover, a part-weighted loss function is presented to reduce the influence of missing parts on pedestrian alignment. Extensive experiments demonstrate that our method outperforms the state-of-the-art methods on the large-scale generalizable re-ID benchmarks, involving domain generalization setting and cross-domain setting.
The Stanford Drone Dataset is More Complex than We Think: An Analysis of Key Characteristics
Mar 22, 2022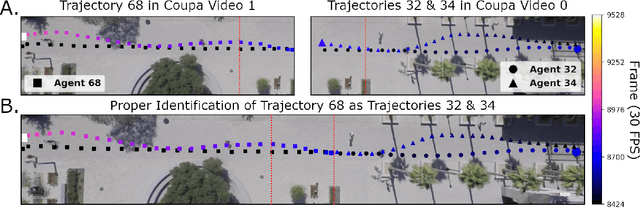
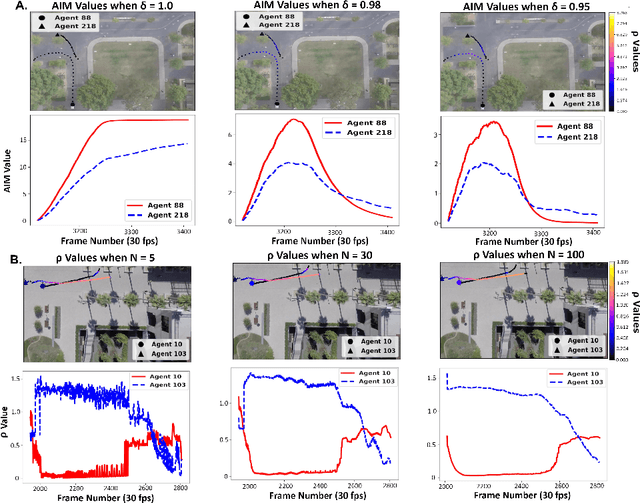
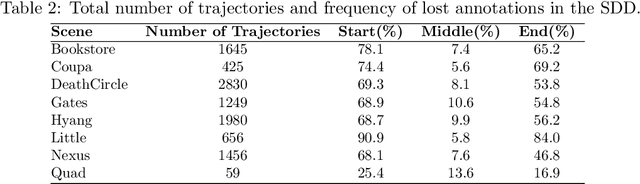
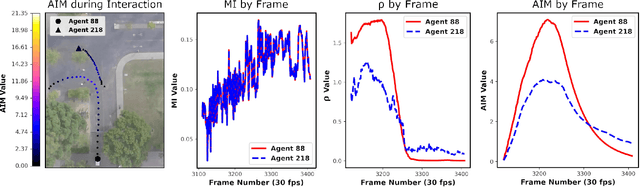
Several datasets exist which contain annotated information of individuals' trajectories. Such datasets are vital for many real-world applications, including trajectory prediction and autonomous navigation. One prominent dataset currently in use is the Stanford Drone Dataset (SDD). Despite its prominence, discussion surrounding the characteristics of this dataset is insufficient. We demonstrate how this insufficiency reduces the information available to users and can impact performance. Our contributions include the outlining of key characteristics in the SDD, employment of an information-theoretic measure and custom metric to clearly visualize those characteristics, the implementation of the PECNet and Y-Net trajectory prediction models to demonstrate the outlined characteristics' impact on predictive performance, and lastly we provide a comparison between the SDD and Intersection Drone (inD) Dataset. Our analysis of the SDD's key characteristics is important because without adequate information about available datasets a user's ability to select the most suitable dataset for their methods, to reproduce one another's results, and to interpret their own results are hindered. The observations we make through this analysis provide a readily accessible and interpretable source of information for those planning to use the SDD. Our intention is to increase the performance and reproducibility of methods applied to this dataset going forward, while also clearly detailing less obvious features of the dataset for new users.
Sensor Observability Index: Evaluating Sensor Alignment for Task-Space Observability in Robotic Manipulators
Jun 22, 2022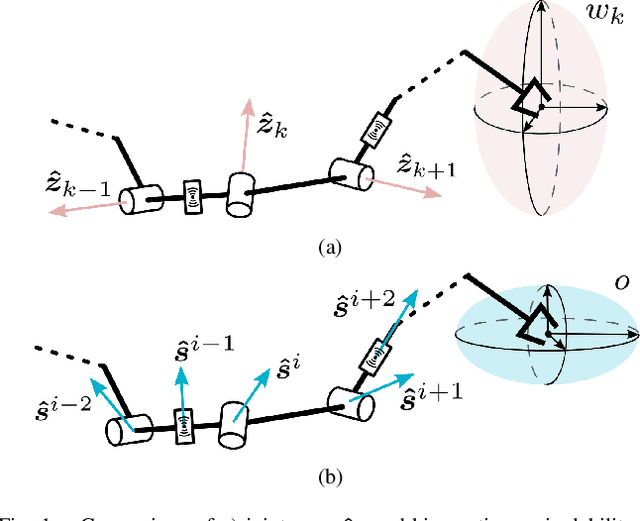
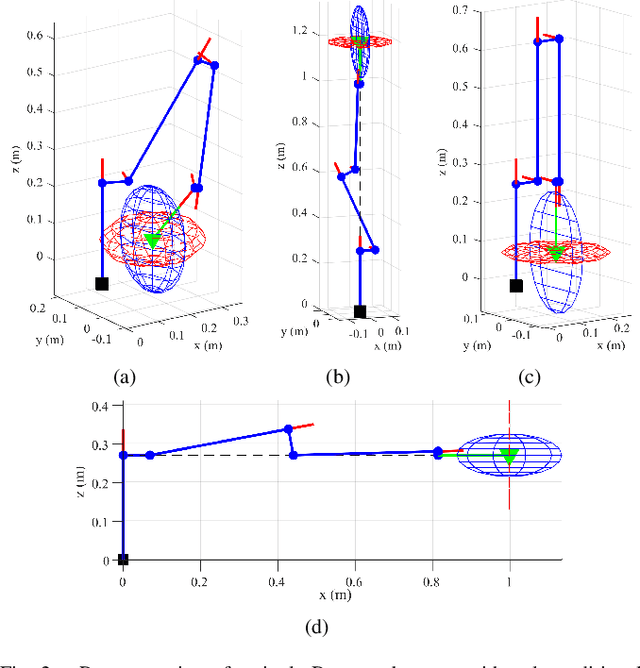
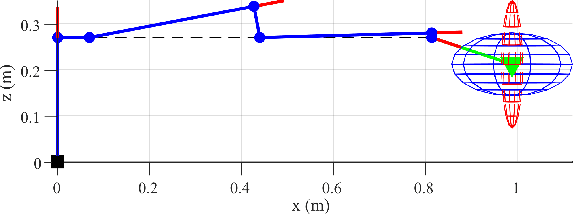
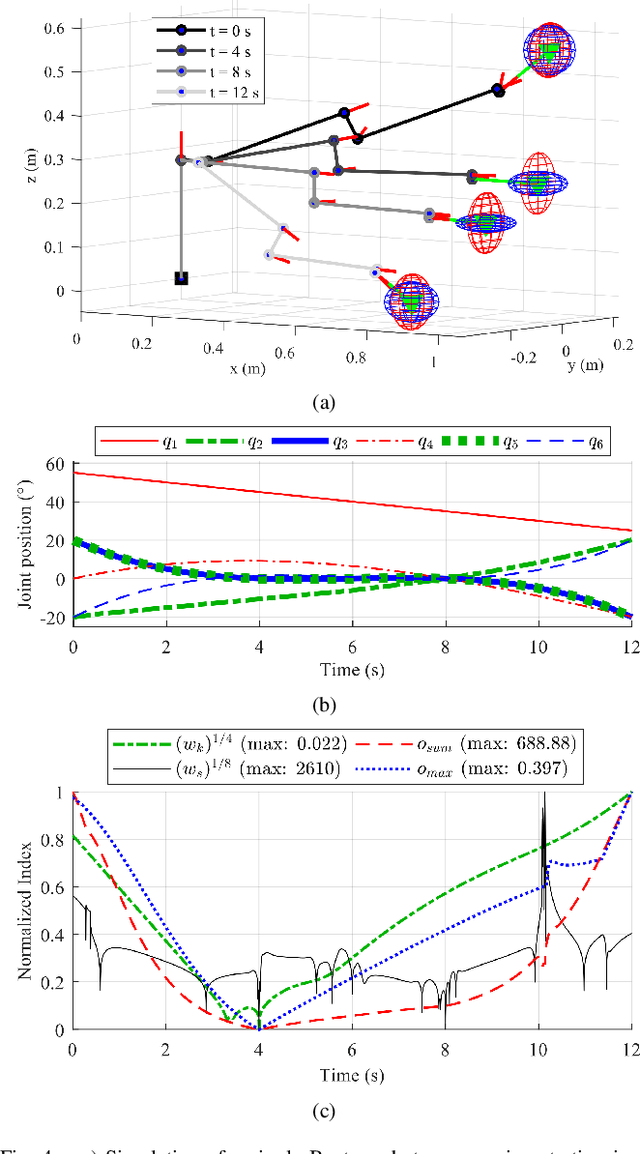
In this paper, we propose a preliminary definition and analysis of the novel concepts of sensor observability, sensor manipulability, and their respective indices. The goal is to analyse and evaluate the performance of distributed directional or axial-based sensors to observe specific axes in task space as a function of joint configuration in serial robot manipulators. For example, joint torque sensors are often used in serial robot manipulators and assumed to be perfectly capable of estimating end effector forces, but certain joint configurations may cause one or more task-space axes to be unobservable as a result of how the joint torque sensors are aligned. The proposed sensor observability provides a method to analyse the quality of the current robot configuration to observe the task space. Sensor manipulability, on the other hand, measures the robot's ability to increase or decrease that observational quality, analogous to end effector positional manoeuvrability as measured by the traditional kinematic manipulability. Parallels are drawn between sensor observability and the traditional kinematic Jacobian for the particular case of joint torque sensors in serial robot manipulators. Although similar information can be retrieved from kinematic analysis of the Jacobian transpose in serial manipulators, sensor observability is shown to be more generalizable in terms of analysing non-joint-mounted sensors and other sensor types. In addition, null-space analysis of the Jacobian transpose is susceptible to false observability singularities. Simulations and experiments using the robot Baxter demonstrate the importance of maintaining proper sensor observability in physical interactions.
VI-IKD: High-Speed Accurate Off-Road Navigation using Learned Visual-Inertial Inverse Kinodynamics
Mar 30, 2022
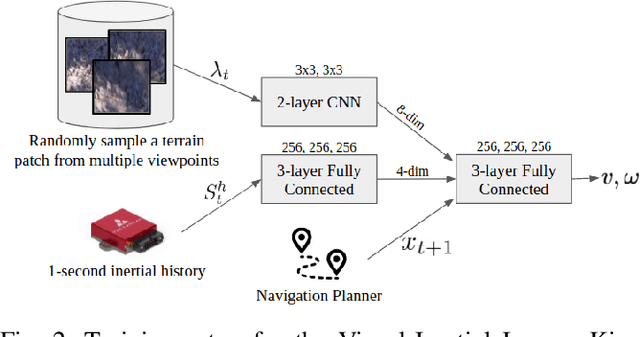


One of the key challenges in high speed off road navigation on ground vehicles is that the kinodynamics of the vehicle terrain interaction can differ dramatically depending on the terrain. Previous approaches to addressing this challenge have considered learning an inverse kinodynamics (IKD) model, conditioned on inertial information of the vehicle to sense the kinodynamic interactions. In this paper, we hypothesize that to enable accurate high-speed off-road navigation using a learned IKD model, in addition to inertial information from the past, one must also anticipate the kinodynamic interactions of the vehicle with the terrain in the future. To this end, we introduce Visual-Inertial Inverse Kinodynamics (VI-IKD), a novel learning based IKD model that is conditioned on visual information from a terrain patch ahead of the robot in addition to past inertial information, enabling it to anticipate kinodynamic interactions in the future. We validate the effectiveness of VI-IKD in accurate high-speed off-road navigation experimentally on a scale 1/5 UT-AlphaTruck off-road autonomous vehicle in both indoor and outdoor environments and show that compared to other state-of-the-art approaches, VI-IKD enables more accurate and robust off-road navigation on a variety of different terrains at speeds of up to 3.5 m/s.
Two Decades of Colorization and Decolorization for Images and Videos
Apr 28, 2022



Colorization is a computer-aided process, which aims to give color to a gray image or video. It can be used to enhance black-and-white images, including black-and-white photos, old-fashioned films, and scientific imaging results. On the contrary, decolorization is to convert a color image or video into a grayscale one. A grayscale image or video refers to an image or video with only brightness information without color information. It is the basis of some downstream image processing applications such as pattern recognition, image segmentation, and image enhancement. Different from image decolorization, video decolorization should not only consider the image contrast preservation in each video frame, but also respect the temporal and spatial consistency between video frames. Researchers were devoted to develop decolorization methods by balancing spatial-temporal consistency and algorithm efficiency. With the prevalance of the digital cameras and mobile phones, image and video colorization and decolorization have been paid more and more attention by researchers. This paper gives an overview of the progress of image and video colorization and decolorization methods in the last two decades.