 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information Extraction From Co-Occurring Similar Entities
Feb 11, 2021

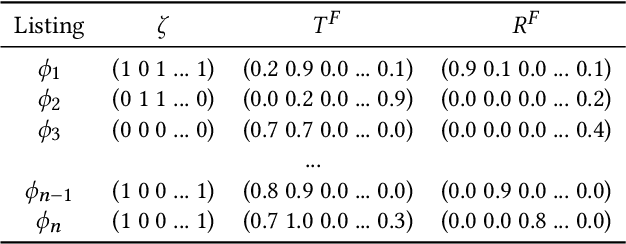
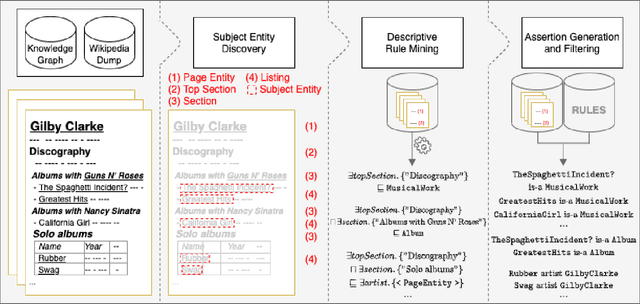
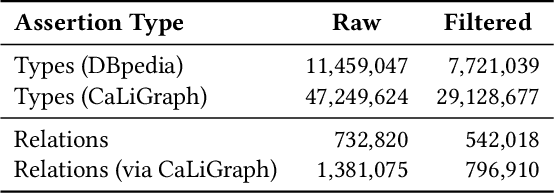
Knowledge about entities and their interrelations is a crucial factor of success for tasks like question answering or text summarization. Publicly available knowledge graphs like Wikidata or DBpedia are, however, far from being complete. In this paper, we explore how information extracted from similar entities that co-occur in structures like tables or lists can help to increase the coverage of such knowledge graphs. In contrast to existing approaches, we do not focus on relationships within a listing (e.g., between two entities in a table row) but on the relationship between a listing's subject entities and the context of the listing. To that end, we propose a descriptive rule mining approach that uses distant supervision to derive rules for these relationships based on a listing's context. Extracted from a suitable data corpus, the rules can be used to extend a knowledge graph with novel entities and assertions. In our experiments we demonstrate that the approach is able to extract up to 3M novel entities and 30M additional assertions from listings in Wikipedia. We find that the extracted information is of high quality and thus suitable to extend Wikipedia-based knowledge graphs like DBpedia, YAGO, and CaLiGraph. For the case of DBpedia, this would result in an increase of covered entities by roughly 50%.
Difficulty in estimating visual information from randomly sampled images
Dec 16, 2020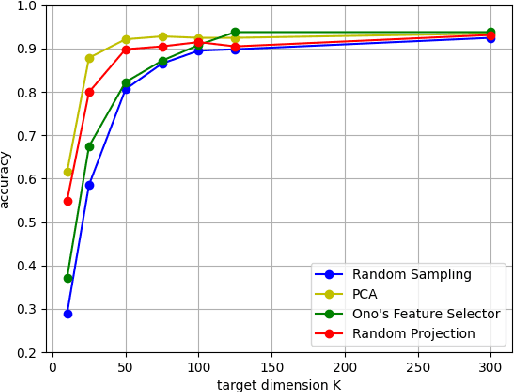
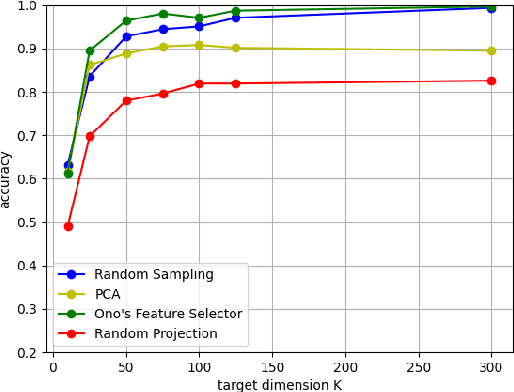
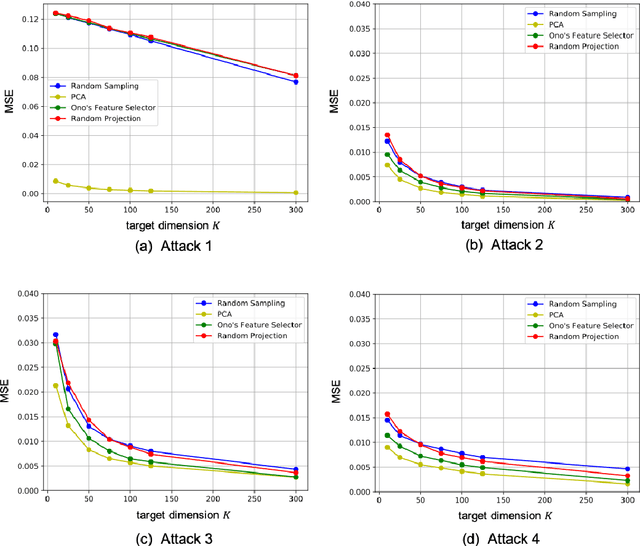
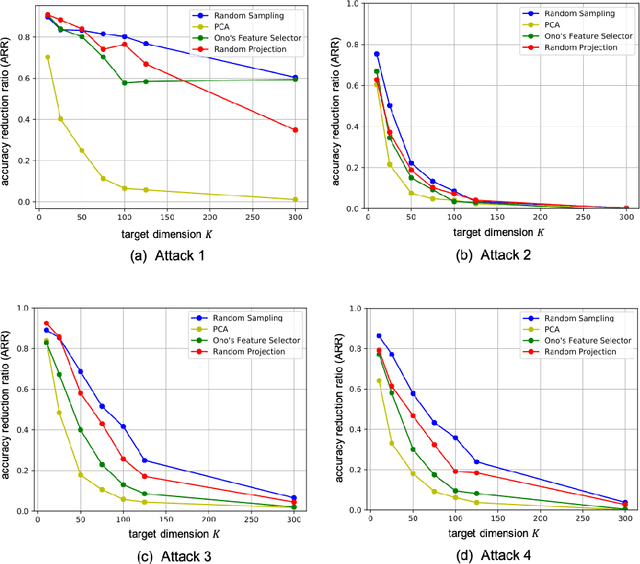
In this paper, we evaluate dimensionality reduction methods in terms of difficulty in estimating visual information on original images from dimensionally reduced ones. Recently, dimensionality reduction has been receiving attention as the process of not only reducing the number of random variables, but also protecting visual information for privacy-preserving machine learning. For such a reason, difficulty in estimating visual information is discussed. In particular, the random sampling method that was proposed for privacy-preserving machine learning, is compared with typical dimensionality reduction methods. In an image classification experiment, the random sampling method is demonstrated not only to have high difficulty, but also to be comparable to other dimensionality reduction methods, while maintaining the property of spatial information invariant.
Comparison of Speech Representations for the MOS Prediction System
Jun 28, 2022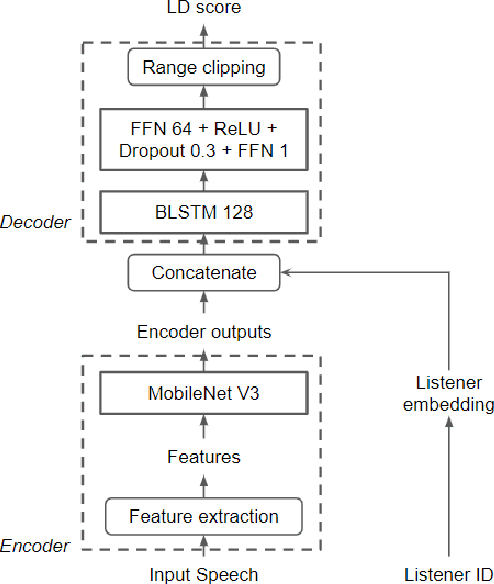
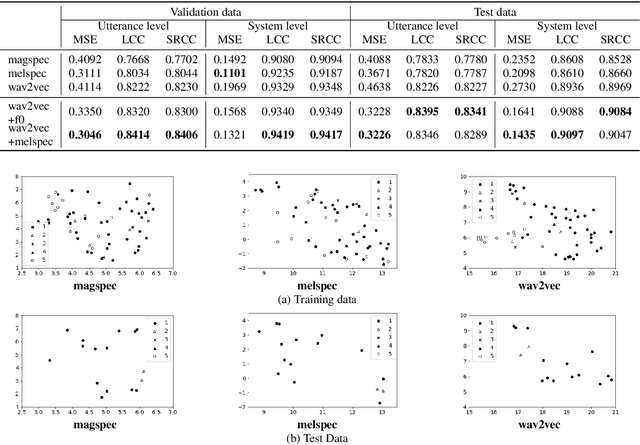
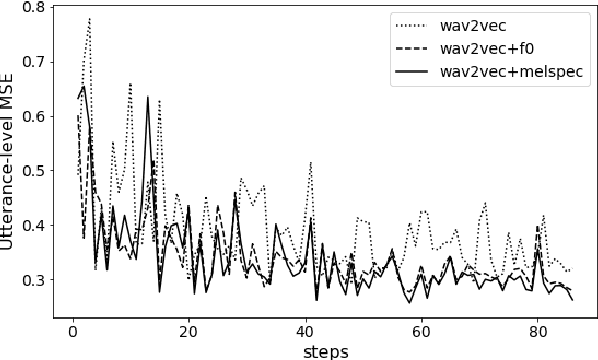
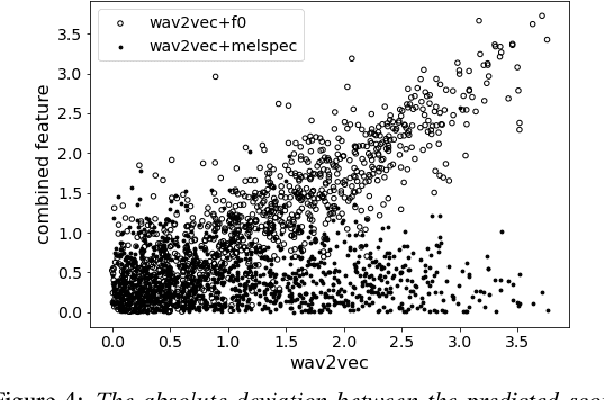
Automatic methods to predict Mean Opinion Score (MOS) of listeners have been researched to assure the quality of Text-to-Speech systems. Many previous studies focus on architectural advances (e.g. MBNet, LDNet, etc.) to capture relations between spectral features and MOS in a more effective way and achieved high accuracy. However, the optimal representation in terms of generalization capability still largely remains unknown. To this end, we compare the performance of Self-Supervised Learning (SSL) features obtained by the wav2vec framework to that of spectral features such as magnitude of spectrogram and melspectrogram. Moreover, we propose to combine the SSL features and features which we believe to retain essential information to the automatic MOS to compensate each other for their drawbacks. We conduct comprehensive experiments on a large-scale listening test corpus collected from past Blizzard and Voice Conversion Challenges. We found that the wav2vec feature set showed the best generalization even though the given ground-truth was not always reliable. Furthermore, we found that the combinations performed the best and analyzed how they bridged the gap between spectral and the wav2vec feature sets.
STAU: A SpatioTemporal-Aware Unit for Video Prediction and Beyond
Apr 20, 2022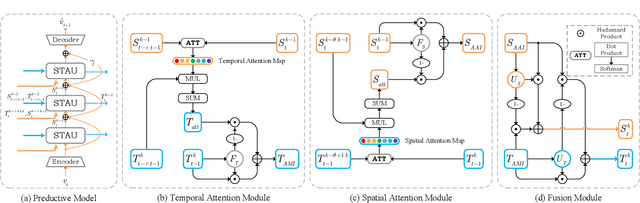


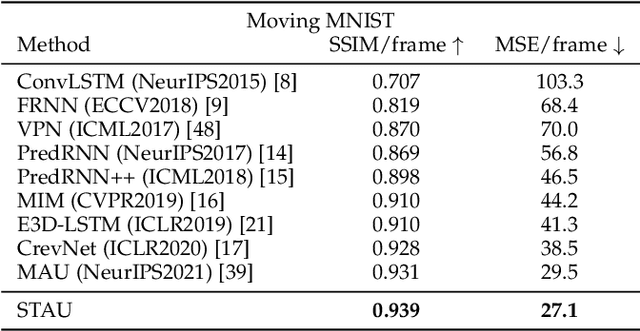
Video prediction aims to predict future frames by modeling the complex spatiotemporal dynamics in videos. However, most of the existing methods only model the temporal information and the spatial information for videos in an independent manner but haven't fully explored the correlations between both terms. In this paper, we propose a SpatioTemporal-Aware Unit (STAU) for video prediction and beyond by exploring the significant spatiotemporal correlations in videos. On the one hand, the motion-aware attention weights are learned from the spatial states to help aggregate the temporal states in the temporal domain. On the other hand, the appearance-aware attention weights are learned from the temporal states to help aggregate the spatial states in the spatial domain. In this way, the temporal information and the spatial information can be greatly aware of each other in both domains, during which, the spatiotemporal receptive field can also be greatly broadened for more reliable spatiotemporal modeling. Experiments are not only conducted on traditional video prediction tasks but also other tasks beyond video prediction, including the early action recognition and object detection tasks. Experimental results show that our STAU can outperform other methods on all tasks in terms of performance and computation efficiency.
Learning Diverse Tone Styles for Image Retouching
Jul 12, 2022


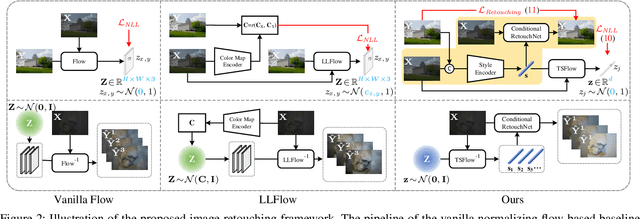
Image retouching, aiming to regenerate the visually pleasing renditions of given images, is a subjective task where the users are with different aesthetic sensations. Most existing methods deploy a deterministic model to learn the retouching style from a specific expert, making it less flexible to meet diverse subjective preferences. Besides, the intrinsic diversity of an expert due to the targeted processing on different images is also deficiently described. To circumvent such issues, we propose to learn diverse image retouching with normalizing flow-based architectures. Unlike current flow-based methods which directly generate the output image, we argue that learning in a style domain could (i) disentangle the retouching styles from the image content, (ii) lead to a stable style presentation form, and (iii) avoid the spatial disharmony effects. For obtaining meaningful image tone style representations, a joint-training pipeline is delicately designed, which is composed of a style encoder, a conditional RetouchNet, and the image tone style normalizing flow (TSFlow) module. In particular, the style encoder predicts the target style representation of an input image, which serves as the conditional information in the RetouchNet for retouching, while the TSFlow maps the style representation vector into a Gaussian distribution in the forward pass. After training, the TSFlow can generate diverse image tone style vectors by sampling from the Gaussian distribution. Extensive experiments on MIT-Adobe FiveK and PPR10K datasets show that our proposed method performs favorably against state-of-the-art methods and is effective in generating diverse results to satisfy different human aesthetic preferences. Source code and pre-trained models are publicly available at https://github.com/SSRHeart/TSFlow.
BiTAT: Neural Network Binarization with Task-dependent Aggregated Transformation
Jul 04, 2022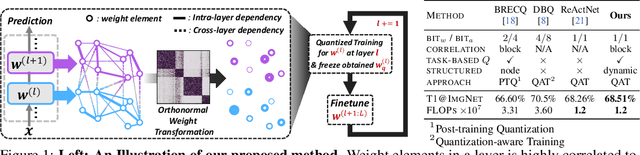
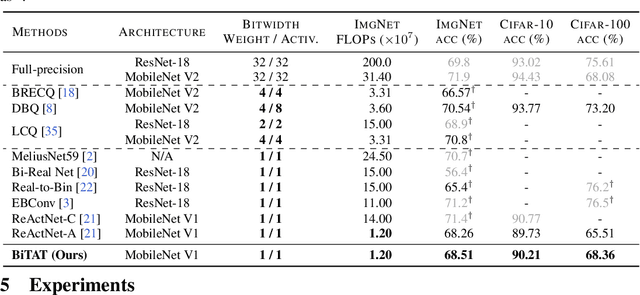
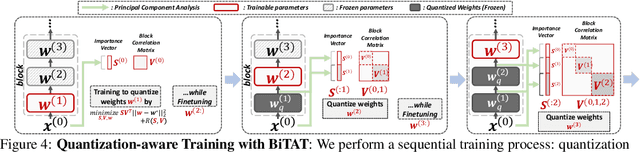
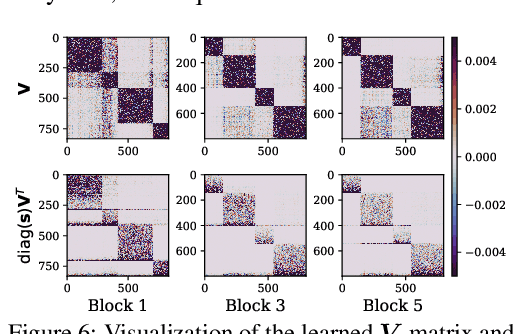
Neural network quantization aims to transform high-precision weights and activations of a given neural network into low-precision weights/activations for reduced memory usage and computation, while preserving the performance of the original model. However, extreme quantization (1-bit weight/1-bit activations) of compactly-designed backbone architectures (e.g., MobileNets) often used for edge-device deployments results in severe performance degeneration. This paper proposes a novel Quantization-Aware Training (QAT) method that can effectively alleviate performance degeneration even with extreme quantization by focusing on the inter-weight dependencies, between the weights within each layer and across consecutive layers. To minimize the quantization impact of each weight on others, we perform an orthonormal transformation of the weights at each layer by training an input-dependent correlation matrix and importance vector, such that each weight is disentangled from the others. Then, we quantize the weights based on their importance to minimize the loss of the information from the original weights/activations. We further perform progressive layer-wise quantization from the bottom layer to the top, so that quantization at each layer reflects the quantized distributions of weights and activations at previous layers. We validate the effectiveness of our method on various benchmark datasets against strong neural quantization baselines, demonstrating that it alleviates the performance degeneration on ImageNet and successfully preserves the full-precision model performance on CIFAR-100 with compact backbone networks.
Would You Ask it that Way? Measuring and Improving Question Naturalness for Knowledge Graph Question Answering
May 25, 2022
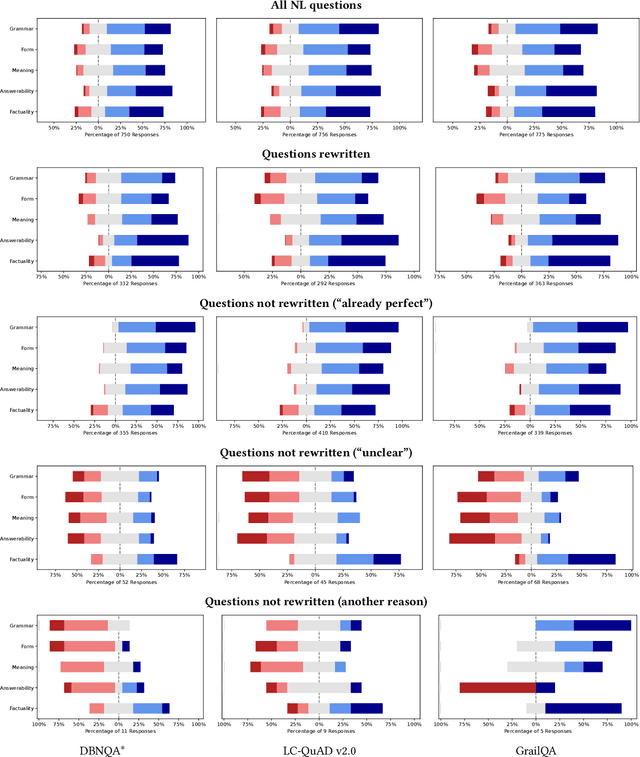
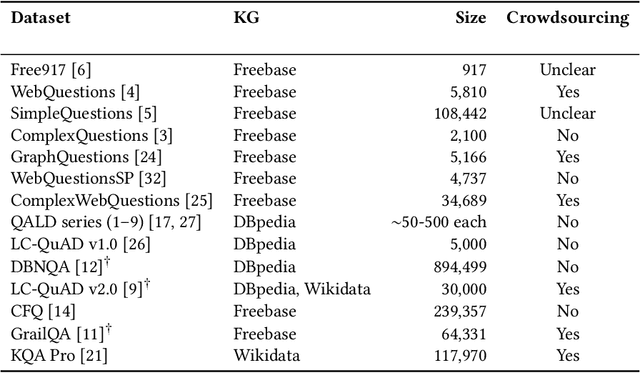
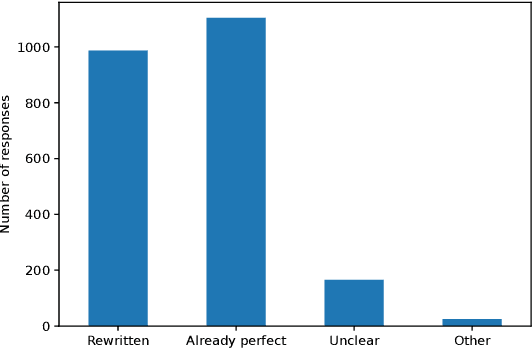
Knowledge graph question answering (KGQA) facilitates information access by leveraging structured data without requiring formal query language expertise from the user. Instead, users can express their information needs by simply asking their questions in natural language (NL). Datasets used to train KGQA models that would provide such a service are expensive to construct, both in terms of expert and crowdsourced labor. Typically, crowdsourced labor is used to improve template-based pseudo-natural questions generated from formal queries. However, the resulting datasets often fall short of representing genuinely natural and fluent language. In the present work, we investigate ways to characterize and remedy these shortcomings. We create the IQN-KGQA test collection by sampling questions from existing KGQA datasets and evaluating them with regards to five different aspects of naturalness. Then, the questions are rewritten to improve their fluency. Finally, the performance of existing KGQA models is compared on the original and rewritten versions of the NL questions. We find that some KGQA systems fare worse when presented with more realistic formulations of NL questions. The IQN-KGQA test collection is a resource to help evaluate KGQA systems in a more realistic setting. The construction of this test collection also sheds light on the challenges of constructing large-scale KGQA datasets with genuinely NL questions.
A Comprehensive Survey on Deep Gait Recognition: Algorithms, Datasets and Challenges
Jun 28, 2022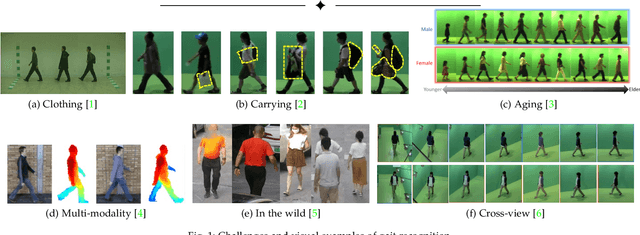
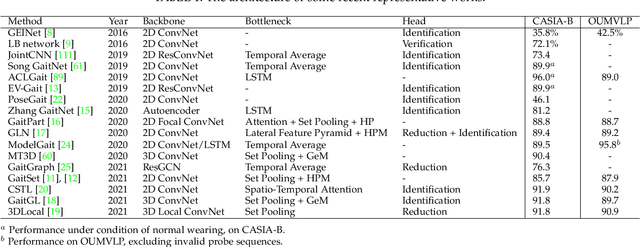
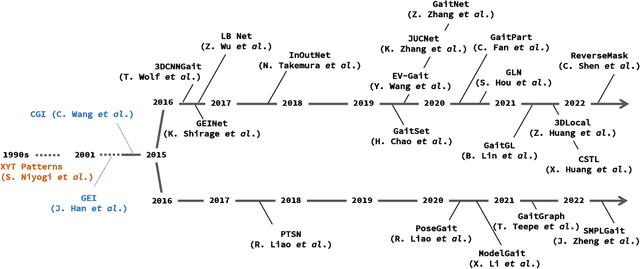
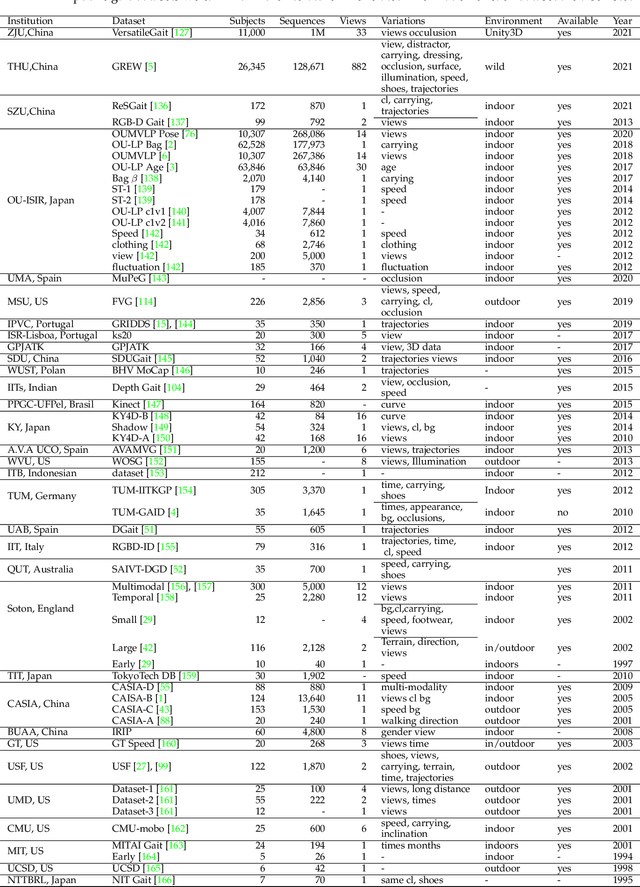
Gait recognition aims at identifying a person at a distance through visual cameras. With the emergence of deep learning, significant advancements in gait recognition have achieved inspiring success in many scenarios by utilizing deep learning techniques. Nevertheless, the increasing need for video surveillance introduces more challenges, including robust recognition under various variances, modeling motion information in gait sequences, unfair performance comparison due to protocol variances, biometrics security, and privacy prevention. This paper provides a comprehensive survey of deep learning for gait recognition. We first present the odyssey of gait recognition from traditional algorithms to deep models, providing explicit knowledge of the whole workflow of a gait recognition system. Then deep learning for gait recognition is discussed from the perspective of deep representations and architecture with an in-depth summary. Specifically, deep gait representations are categorized into static and dynamic features, while deep architectures include single-stream and multi-stream architecture. Following our proposed taxonomy with novelty, it can be beneficial for providing inspiration and promoting the perception of deep gait recognition. Besides, we also present a comprehensive summary of all vision-based gait datasets and the performance analysis. Finally, the article discusses some open issues with significant potential prospects.
Voxel-MAE: Masked Autoencoders for Pre-training Large-scale Point Clouds
Jun 20, 2022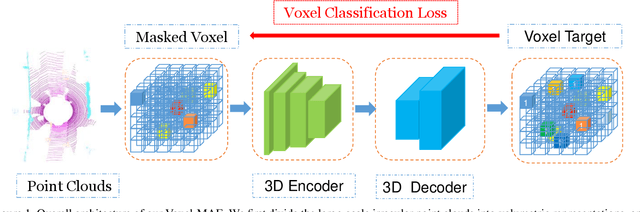
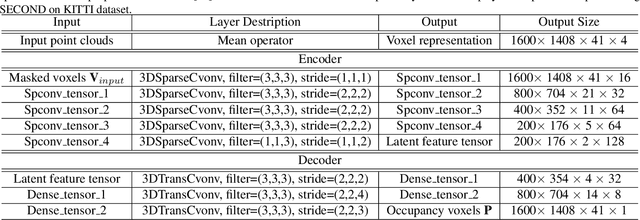
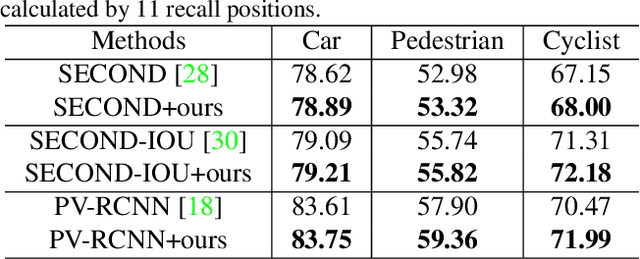
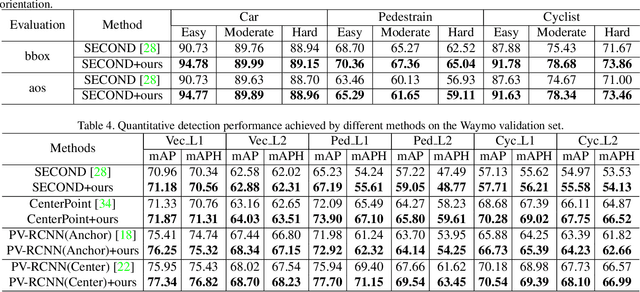
Mask-based pre-training has achieved great success for self-supervised learning in image, video and language, without manually annotated supervision. However, as information redundant data, it has not yet been studied in the field of 3D object detection. As the point clouds in 3D object detection is large-scale, it is impossible to reconstruct the input point clouds. In this paper, we propose a mask voxel classification network for large-scale point clouds pre-training. Our key idea is to divide the point clouds into voxel representations and classify whether the voxel contains point clouds. This simple strategy makes the network to be voxel-aware of the object shape, thus improving the performance of 3D object detection. Extensive experiments show great effectiveness of our pre-trained model with 3D object detectors (SECOND, CenterPoint, and PV-RCNN) on three popular datasets (KITTI, Waymo, and nuScenes). Codes are publicly available at https: //github.com/chaytonmin/Voxel-MAE.
Computer-aided Tuberculosis Diagnosis with Attribute Reasoning Assistance
Jul 01, 2022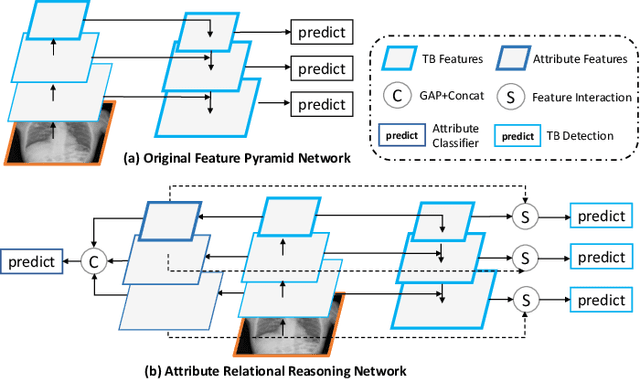
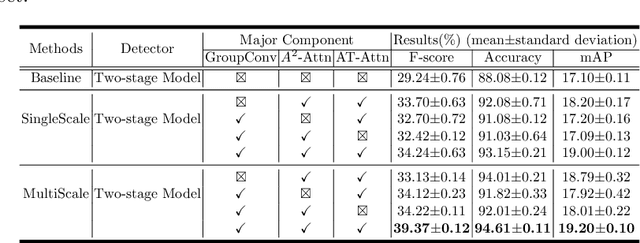
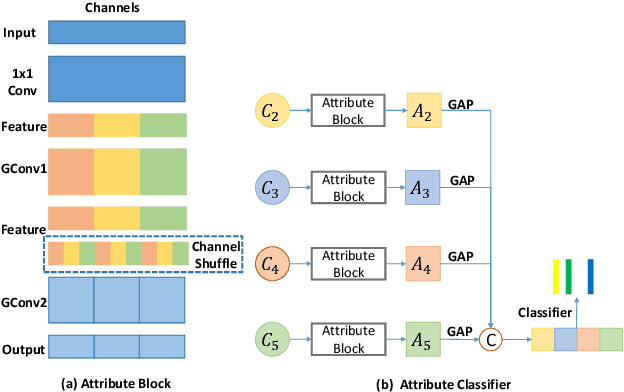
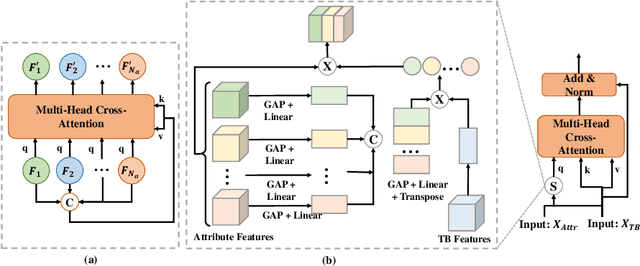
Although deep learning algorithms have been intensively developed for computer-aided tuberculosis diagnosis (CTD), they mainly depend on carefully annotated datasets, leading to much time and resource consumption. Weakly supervised learning (WSL), which leverages coarse-grained labels to accomplish fine-grained tasks, has the potential to solve this problem. In this paper, we first propose a new large-scale tuberculosis (TB) chest X-ray dataset, namely the tuberculosis chest X-ray attribute dataset (TBX-Att), and then establish an attribute-assisted weakly-supervised framework to classify and localize TB by leveraging the attribute information to overcome the insufficiency of supervision in WSL scenarios. Specifically, first, the TBX-Att dataset contains 2000 X-ray images with seven kinds of attributes for TB relational reasoning, which are annotated by experienced radiologists. It also includes the public TBX11K dataset with 11200 X-ray images to facilitate weakly supervised detection. Second, we exploit a multi-scale feature interaction model for TB area classification and detection with attribute relational reasoning. The proposed model is evaluated on the TBX-Att dataset and will serve as a solid baseline for future research. The code and data will be available at https://github.com/GangmingZhao/tb-attribute-weak-localization.