 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MNet: Rethinking 2D/3D Networks for Anisotropic Medical Image Segmentation
May 10, 2022
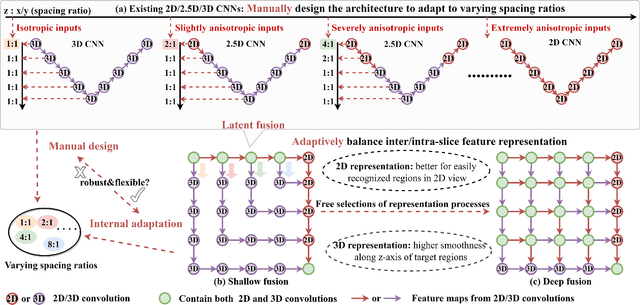
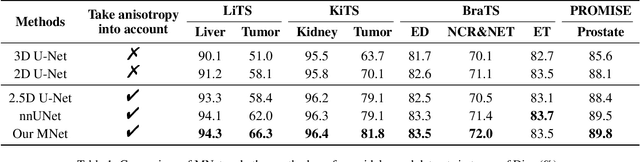
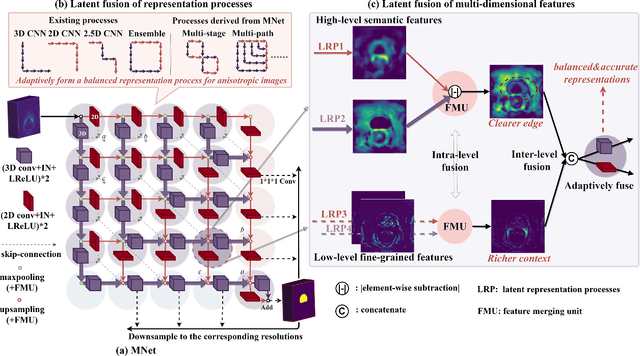

The nature of thick-slice scanning causes severe inter-slice discontinuities of 3D medical images, and the vanilla 2D/3D convolutional neural networks (CNNs) fail to represent sparse inter-slice information and dense intra-slice information in a balanced way, leading to severe underfitting to inter-slice features (for vanilla 2D CNNs) and overfitting to noise from long-range slices (for vanilla 3D CNNs). In this work, a novel mesh network (MNet) is proposed to balance the spatial representation inter axes via learning. 1) Our MNet latently fuses plenty of representation processes by embedding multi-dimensional convolutions deeply into basic modules, making the selections of representation processes flexible, thus balancing representation for sparse inter-slice information and dense intra-slice information adaptively. 2) Our MNet latently fuses multi-dimensional features inside each basic module, simultaneously taking the advantages of 2D (high segmentation accuracy of the easily recognized regions in 2D view) and 3D (high smoothness of 3D organ contour) representations, thus obtaining more accurate modeling for target regions. Comprehensive experiments are performed on four public datasets (CT\&MR), the results consistently demonstrate the proposed MNet outperforms the other methods. The code and datasets are available at: https://github.com/zfdong-code/MNet
Local Byte Fusion for Neural Machine Translation
May 23, 2022
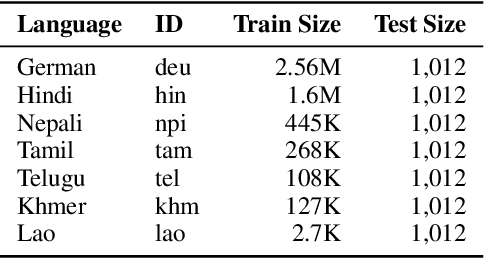
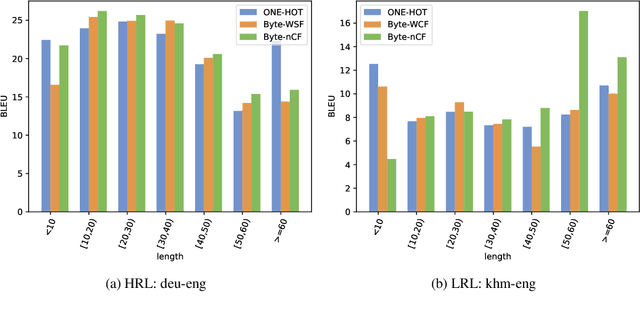
Subword tokenization schemes are the dominant technique used in current NLP models. However, such schemes can be rigid and tokenizers built on one corpus do not adapt well to other parallel corpora. It has also been observed that in multilingual corpora, subword tokenization schemes over-segment low-resource languages leading to a drop in translation performance. A simple alternative to subword tokenizers is byte-based methods i.e. tokenization into byte sequences using encoding schemes such as UTF-8. Byte tokens often represent inputs at a sub-character granularity i.e. one character can be represented by a sequence of multiple byte tokens. This results in byte sequences that are significantly longer than character sequences. Enforcing aggregation of local information in the lower layers can guide the model to build higher-level semantic information. We propose a Local Byte Fusion (LOBEF) method for byte-based machine translation -- utilizing byte $n$-gram and word boundaries -- to aggregate local semantic information. Extensive experiments on multilingual translation, zero-shot cross-lingual transfer, and domain adaptation reveal a consistent improvement over traditional byte-based models and even over subword techniques. Further analysis also indicates that our byte-based models are parameter-efficient and can be trained faster than subword models.
Learning structures of the French clinical language:development and validation of word embedding models using 21 million clinical reports from electronic health records
Jul 26, 2022
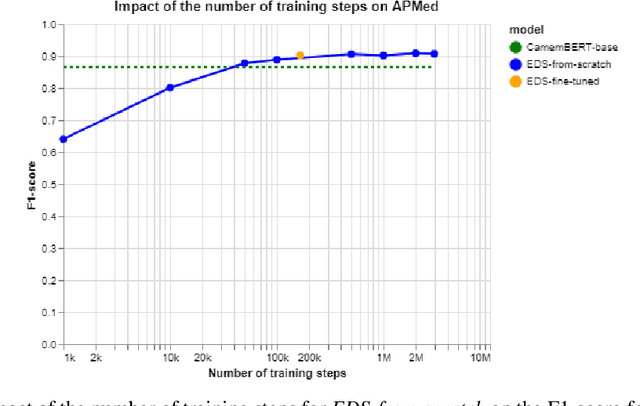

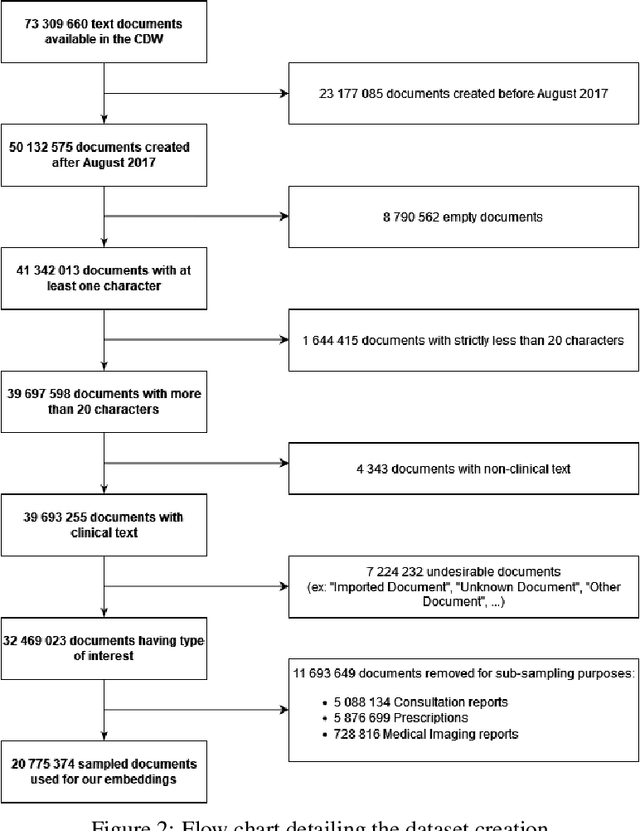
Background Clinical studies using real-world data may benefit from exploiting clinical reports, a particularly rich albeit unstructured medium. To that end, natural language processing can extract relevant information. Methods based on transfer learning using pre-trained language models have achieved state-of-the-art results in most NLP applications; however, publicly available models lack exposure to speciality-languages, especially in the medical field. Objective We aimed to evaluate the impact of adapting a language model to French clinical reports on downstream medical NLP tasks. Methods We leveraged a corpus of 21M clinical reports collected from August 2017 to July 2021 at the Greater Paris University Hospitals (APHP) to produce two CamemBERT architectures on speciality language: one retrained from scratch and the other using CamemBERT as its initialisation. We used two French annotated medical datasets to compare our language models to the original CamemBERT network, evaluating the statistical significance of improvement with the Wilcoxon test. Results Our models pretrained on clinical reports increased the average F1-score on APMed (an APHP-specific task) by 3 percentage points to 91%, a statistically significant improvement. They also achieved performance comparable to the original CamemBERT on QUAERO. These results hold true for the fine-tuned and from-scratch versions alike, starting from very few pre-training samples. Conclusions We confirm previous literature showing that adapting generalist pre-train language models such as CamenBERT on speciality corpora improves their performance for downstream clinical NLP tasks. Our results suggest that retraining from scratch does not induce a statistically significant performance gain compared to fine-tuning.
Electromagnetic Signal Injection Attacks on Differential Signaling
Jul 31, 2022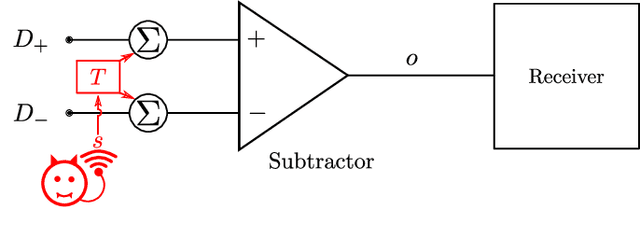
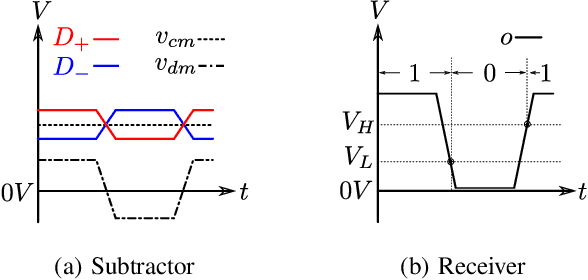
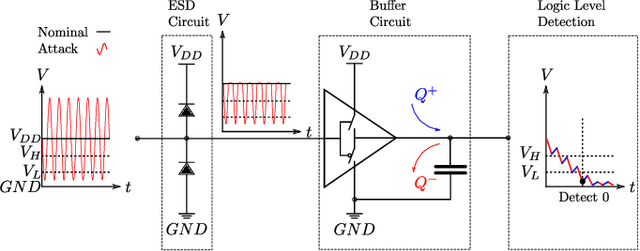
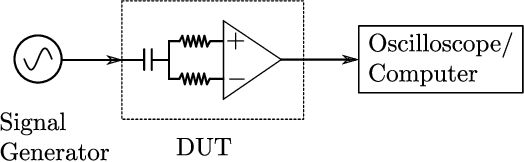
Differential signaling is a method of data transmission that uses two complementary electrical signals to encode information. This allows a receiver to reject any noise by looking at the difference between the two signals, assuming the noise affects both signals in the same way. Many protocols such as USB, Ethernet, and HDMI use differential signaling to achieve a robust communication channel in a noisy environment. This generally works well and has led many to believe that it is infeasible to remotely inject attacking signals into such a differential pair. In this paper we challenge this assumption and show that an adversary can in fact inject malicious signals from a distance, purely using common-mode injection, i.e., injecting into both wires at the same time. We show how this allows an attacker to inject bits or even arbitrary messages into a communication line. Such an attack is a significant threat to many applications, from home security and privacy to automotive systems, critical infrastructure, or implantable medical devices; in which incorrect data or unauthorized control could cause significant damage, or even fatal accidents. We show in detail the principles of how an electromagnetic signal can bypass the noise rejection of differential signaling, and eventually result in incorrect bits in the receiver. We show how an attacker can exploit this to achieve a successful injection of an arbitrary bit, and we analyze the success rate of injecting longer arbitrary messages. We demonstrate the attack on a real system and show that the success rate can reach as high as $90\%$. Finally, we present a case study where we wirelessly inject a message into a Controller Area Network (CAN) bus, which is a differential signaling bus protocol used in many critical applications, including the automotive and aviation sector.
NSNet: Non-saliency Suppression Sampler for Efficient Video Recognition
Jul 21, 2022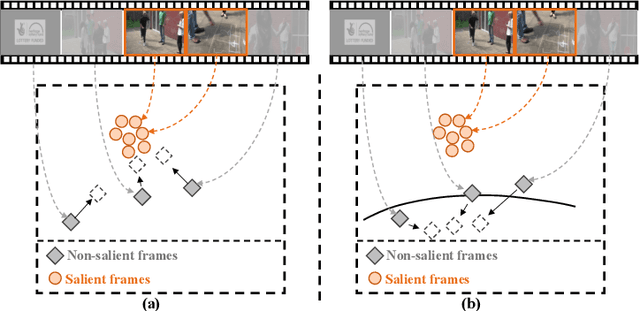
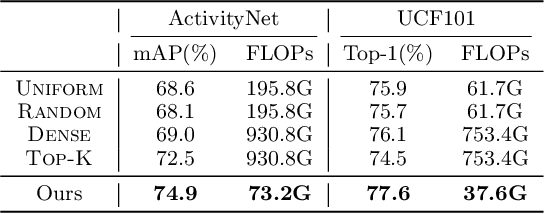

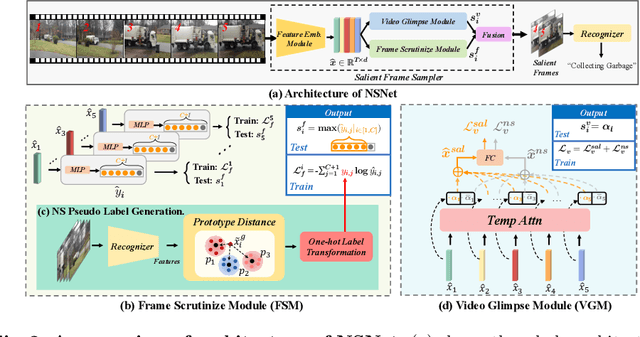
It is challenging for artificial intelligence systems to achieve accurate video recognition under the scenario of low computation costs. Adaptive inference based efficient video recognition methods typically preview videos and focus on salient parts to reduce computation costs. Most existing works focus on complex networks learning with video classification based objectives. Taking all frames as positive samples, few of them pay attention to the discrimination between positive samples (salient frames) and negative samples (non-salient frames) in supervisions. To fill this gap, in this paper, we propose a novel Non-saliency Suppression Network (NSNet), which effectively suppresses the responses of non-salient frames. Specifically, on the frame level, effective pseudo labels that can distinguish between salient and non-salient frames are generated to guide the frame saliency learning. On the video level, a temporal attention module is learned under dual video-level supervisions on both the salient and the non-salient representations. Saliency measurements from both two levels are combined for exploitation of multi-granularity complementary information. Extensive experiments conducted on four well-known benchmarks verify our NSNet not only achieves the state-of-the-art accuracy-efficiency trade-off but also present a significantly faster (2.4~4.3x) practical inference speed than state-of-the-art methods. Our project page is at https://lawrencexia2008.github.io/projects/nsnet .
A Novel Underwater Image Enhancement and Improved Underwater Biological Detection Pipeline
May 20, 2022For aquaculture resource evaluation and ecological environment monitoring, automatic detection and identification of marine organisms is critical. However, due to the low quality of underwater images and the characteristics of underwater biological, a lack of abundant features may impede traditional hand-designed feature extraction approaches or CNN-based object detection algorithms, particularly in complex underwater environment. Therefore, the goal of this paper is to perform object detection in the underwater environment. This paper proposed a novel method for capturing feature information, which adds the convolutional block attention module (CBAM) to the YOLOv5 backbone. The interference of underwater creature characteristics on object characteristics is decreased, and the output of the backbone network to object information is enhanced. In addition, the self-adaptive global histogram stretching algorithm (SAGHS) is designed to eliminate the degradation problems such as low contrast and color loss caused by underwater environmental information to better restore image quality. Extensive experiments and comprehensive evaluation on the URPC2021 benchmark dataset demonstrate the effectiveness and adaptivity of our methods. Beyond that, this paper conducts an exhaustive analysis of the role of training data on performance.
Multimodal Dialogue State Tracking
Jun 16, 2022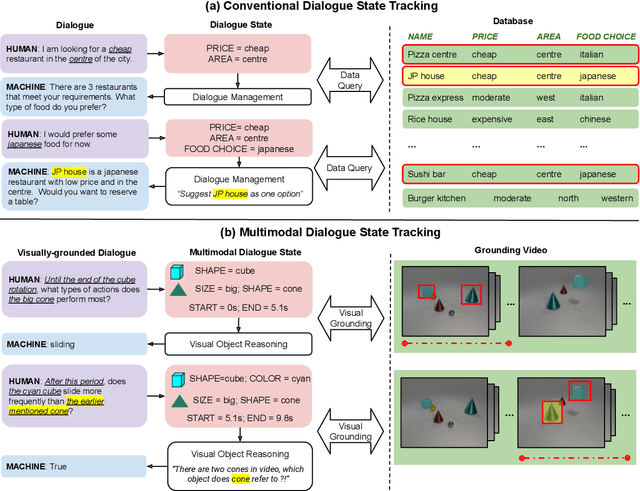
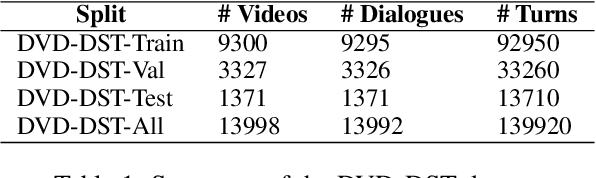
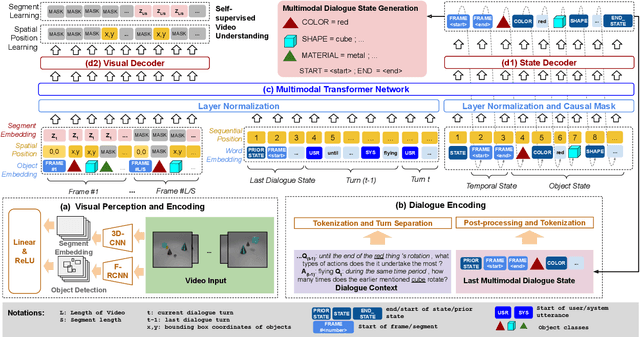
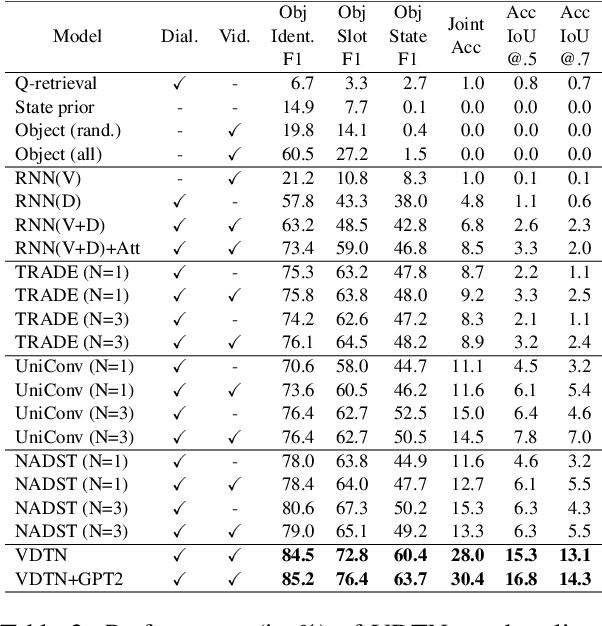
Designed for tracking user goals in dialogues, a dialogue state tracker is an essential component in a dialogue system. However, the research of dialogue state tracking has largely been limited to unimodality, in which slots and slot values are limited by knowledge domains (e.g. restaurant domain with slots of restaurant name and price range) and are defined by specific database schema. In this paper, we propose to extend the definition of dialogue state tracking to multimodality. Specifically, we introduce a novel dialogue state tracking task to track the information of visual objects that are mentioned in video-grounded dialogues. Each new dialogue utterance may introduce a new video segment, new visual objects, or new object attributes, and a state tracker is required to update these information slots accordingly. We created a new synthetic benchmark and designed a novel baseline, Video-Dialogue Transformer Network (VDTN), for this task. VDTN combines both object-level features and segment-level features and learns contextual dependencies between videos and dialogues to generate multimodal dialogue states. We optimized VDTN for a state generation task as well as a self-supervised video understanding task which recovers video segment or object representations. Finally, we trained VDTN to use the decoded states in a response prediction task. Together with comprehensive ablation and qualitative analysis, we discovered interesting insights towards building more capable multimodal dialogue systems.
Towards Privacy-Preserving Person Re-identification via Person Identify Shift
Jul 15, 2022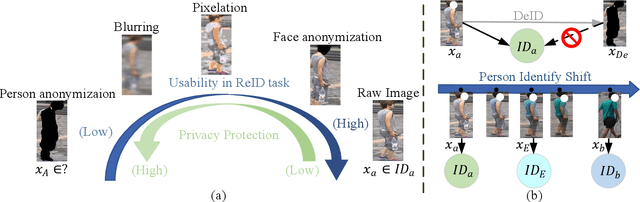
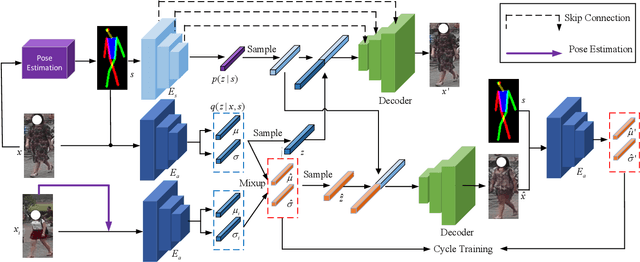


Recently privacy concerns of person re-identification (ReID) raise more and more attention and preserving the privacy of the pedestrian images used by ReID methods become essential. De-identification (DeID) methods alleviate privacy issues by removing the identity-related of the ReID data. However, most of the existing DeID methods tend to remove all personal identity-related information and compromise the usability of de-identified data on the ReID task. In this paper, we aim to develop a technique that can achieve a good trade-off between privacy protection and data usability for person ReID. To achieve this, we propose a novel de-identification method designed explicitly for person ReID, named Person Identify Shift (PIS). PIS removes the absolute identity in a pedestrian image while preserving the identity relationship between image pairs. By exploiting the interpolation property of variational auto-encoder, PIS shifts each pedestrian image from the current identity to another with a new identity, resulting in images still preserving the relative identities. Experimental results show that our method has a better trade-off between privacy-preserving and model performance than existing de-identification methods and can defend against human and model attacks for data privacy.
ID-Agnostic User Behavior Pre-training for Sequential Recommendation
Jun 06, 2022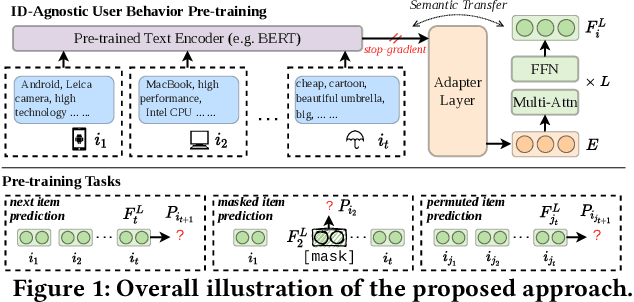
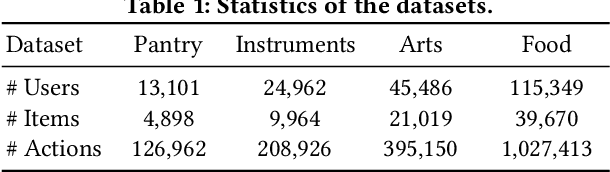
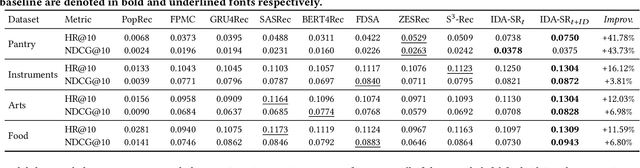
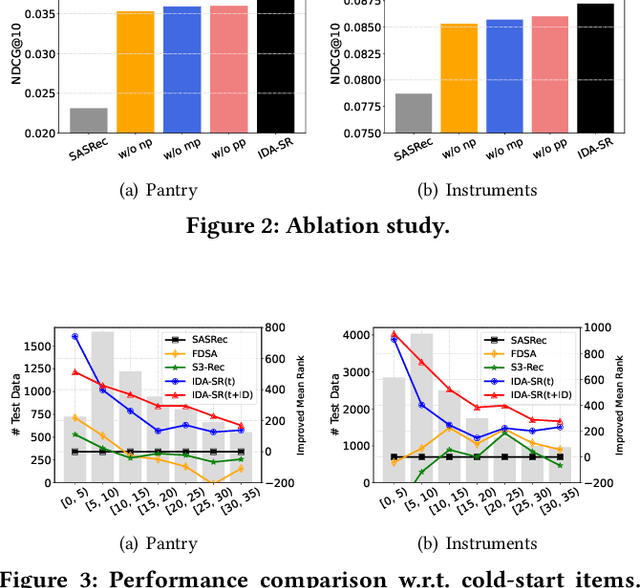
Recently, sequential recommendation has emerged as a widely studied topic. Existing researches mainly design effective neural architectures to model user behavior sequences based on item IDs. However, this kind of approach highly relies on user-item interaction data and neglects the attribute- or characteristic-level correlations among similar items preferred by a user. In light of these issues, we propose IDA-SR, which stands for ID-Agnostic User Behavior Pre-training approach for Sequential Recommendation. Instead of explicitly learning representations for item IDs, IDA-SR directly learns item representations from rich text information. To bridge the gap between text semantics and sequential user behaviors, we utilize the pre-trained language model as text encoder, and conduct a pre-training architecture on the sequential user behaviors. In this way, item text can be directly utilized for sequential recommendation without relying on item IDs. Extensive experiments show that the proposed approach can achieve comparable results when only using ID-agnostic item representations, and performs better than baselines by a large margin when fine-tuned with ID information.
"Why do so?" -- A Practical Perspective on Machine Learning Security
Jul 11, 2022

Despite the large body of academic work on machine learning security, little is known about the occurrence of attacks on machine learning systems in the wild. In this paper, we report on a quantitative study with 139 industrial practitioners. We analyze attack occurrence and concern and evaluate statistical hypotheses on factors influencing threat perception and exposure. Our results shed light on real-world attacks on deployed machine learning. On the organizational level, while we find no predictors for threat exposure in our sample, the amount of implement defenses depends on exposure to threats or expected likelihood to become a target. We also provide a detailed analysis of practitioners' replies on the relevance of individual machine learning attacks, unveiling complex concerns like unreliable decision making, business information leakage, and bias introduction into models. Finally, we find that on the individual level, prior knowledge about machine learning security influences threat perception. Our work paves the way for more research about adversarial machine learning in practice, but yields also insights for regulation and auditing.