 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePARHAF, a human-authored corpus of clinical reports for fictitious patients in French
Mar 20, 2026The development of clinical natural language processing (NLP) systems is severely hampered by the sensitive nature of medical records, which restricts data sharing under stringent privacy regulations, particularly in France and the broader European Union. To address this gap, we introduce PARHAF, a large open-source corpus of clinical documents in French. PARHAF comprises expert-authored clinical reports describing realistic yet entirely fictitious patient cases, making it anonymous and freely shareable by design. The corpus was developed using a structured protocol that combined clinician expertise with epidemiological guidance from the French National Health Data System (SNDS), ensuring broad clinical coverage. A total of 104 medical residents across 18 specialties authored and peer-reviewed the reports following predefined clinical scenarios and document templates. The corpus contains 7394 clinical reports covering 5009 patient cases across a wide range of medical and surgical specialties. It includes a general-purpose component designed to approximate real-world hospitalization distributions, and four specialized subsets that support information-extraction use cases in oncology, infectious diseases, and diagnostic coding. Documents are released under a CC-BY open license, with a portion temporarily embargoed to enable future benchmarking under controlled conditions. PARHAF provides a valuable resource for training and evaluating French clinical language models in a fully privacy-preserving setting, and establishes a replicable methodology for building shareable synthetic clinical corpora in other languages and health systems.
Learning structures of the French clinical language:development and validation of word embedding models using 21 million clinical reports from electronic health records
Jul 26, 2022
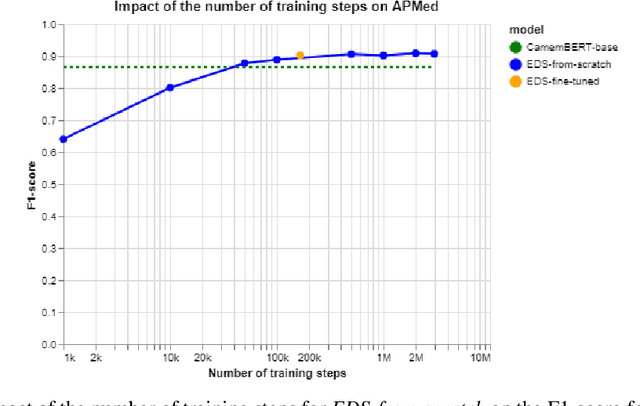

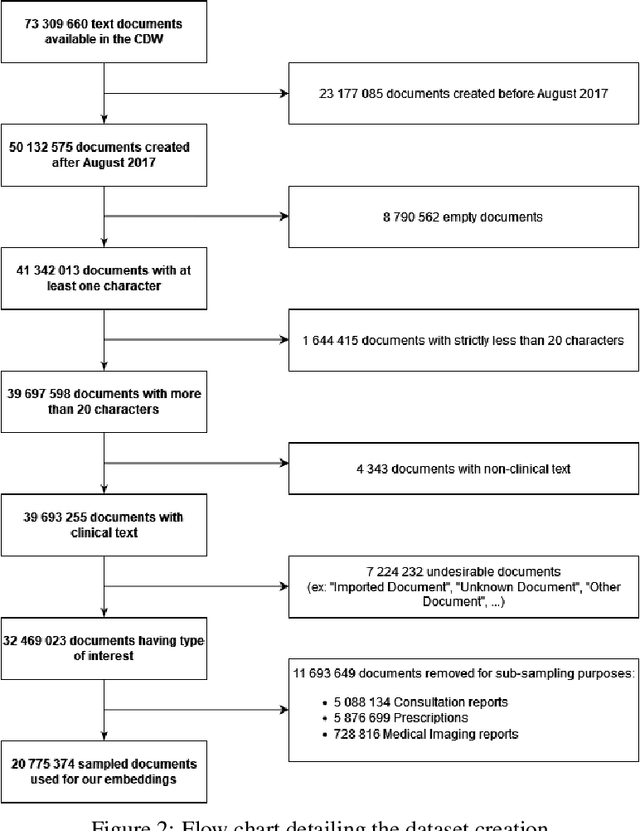
Background Clinical studies using real-world data may benefit from exploiting clinical reports, a particularly rich albeit unstructured medium. To that end, natural language processing can extract relevant information. Methods based on transfer learning using pre-trained language models have achieved state-of-the-art results in most NLP applications; however, publicly available models lack exposure to speciality-languages, especially in the medical field. Objective We aimed to evaluate the impact of adapting a language model to French clinical reports on downstream medical NLP tasks. Methods We leveraged a corpus of 21M clinical reports collected from August 2017 to July 2021 at the Greater Paris University Hospitals (APHP) to produce two CamemBERT architectures on speciality language: one retrained from scratch and the other using CamemBERT as its initialisation. We used two French annotated medical datasets to compare our language models to the original CamemBERT network, evaluating the statistical significance of improvement with the Wilcoxon test. Results Our models pretrained on clinical reports increased the average F1-score on APMed (an APHP-specific task) by 3 percentage points to 91%, a statistically significant improvement. They also achieved performance comparable to the original CamemBERT on QUAERO. These results hold true for the fine-tuned and from-scratch versions alike, starting from very few pre-training samples. Conclusions We confirm previous literature showing that adapting generalist pre-train language models such as CamenBERT on speciality corpora improves their performance for downstream clinical NLP tasks. Our results suggest that retraining from scratch does not induce a statistically significant performance gain compared to fine-tuning.