 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AST-Probe: Recovering abstract syntax trees from hidden representations of pre-trained language models
Jun 23, 2022
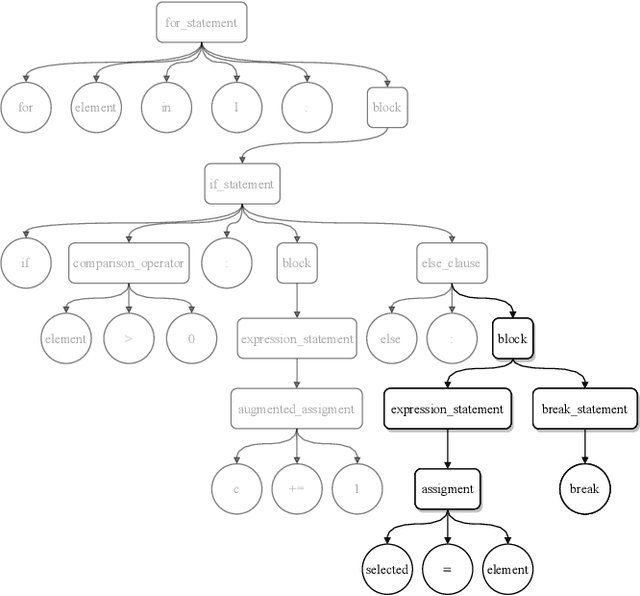
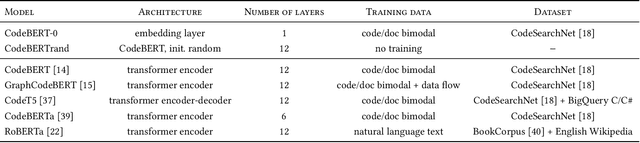
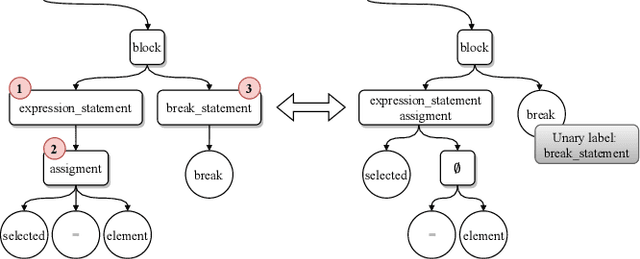
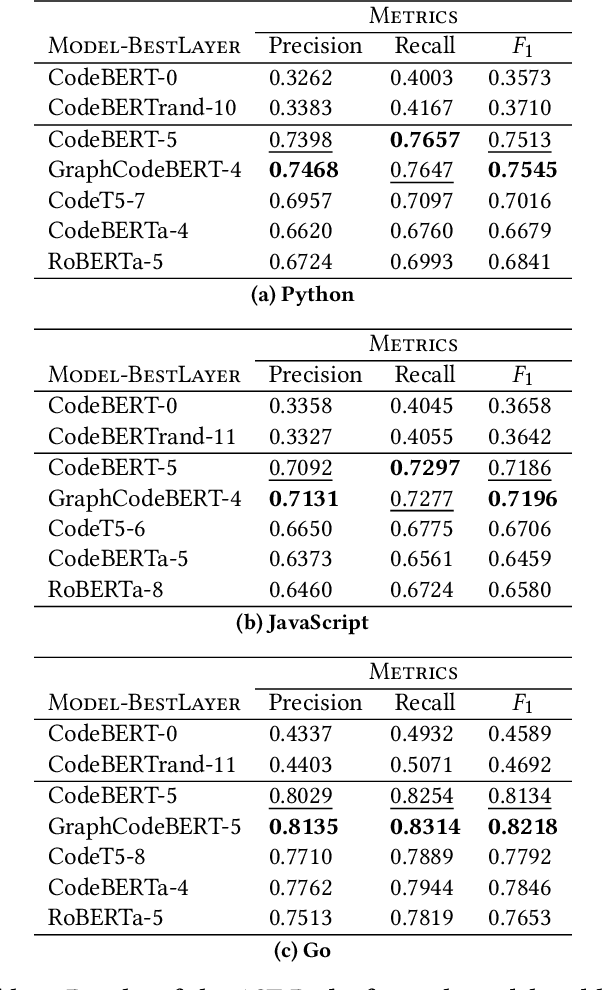
The objective of pre-trained language models is to learn contextual representations of textual data. Pre-trained language models have become mainstream in natural language processing and code modeling. Using probes, a technique to study the linguistic properties of hidden vector spaces, previous works have shown that these pre-trained language models encode simple linguistic properties in their hidden representations. However, none of the previous work assessed whether these models encode the whole grammatical structure of a programming language. In this paper, we prove the existence of a \textit{syntactic subspace}, lying in the hidden representations of pre-trained language models, which contain the syntactic information of the programming language. We show that this subspace can be extracted from the models' representations and define a novel probing method, the AST-Probe, that enables recovering the whole abstract syntax tree (AST) of an input code snippet. In our experimentations, we show that this syntactic subspace exists in five state-of-the-art pre-trained language models. In addition, we highlight that the middle layers of the models are the ones that encode most of the AST information. Finally, we estimate the optimal size of this syntactic subspace and show that its dimension is substantially lower than those of the models' representation spaces. This suggests that pre-trained language models use a small part of their representation spaces to encode syntactic information of the programming languages.
End-to-end Speech-to-Punctuated-Text Recognition
Jul 07, 2022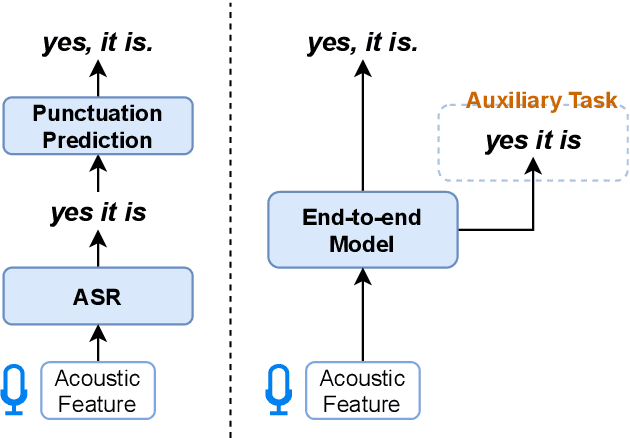
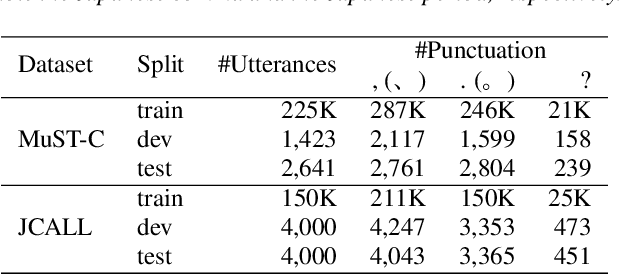

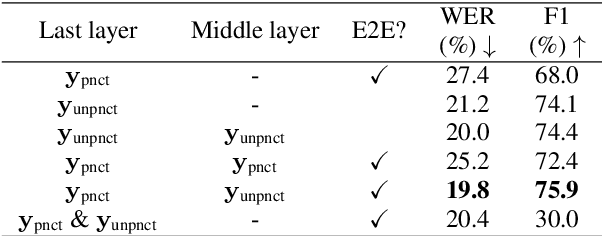
Conventional automatic speech recognition systems do not produce punctuation marks which are important for the readability of the speech recognition results. They are also needed for subsequent natural language processing tasks such as machine translation. There have been a lot of works on punctuation prediction models that insert punctuation marks into speech recognition results as post-processing. However, these studies do not utilize acoustic information for punctuation prediction and are directly affected by speech recognition errors. In this study, we propose an end-to-end model that takes speech as input and outputs punctuated texts. This model is expected to predict punctuation robustly against speech recognition errors while using acoustic information. We also propose to incorporate an auxiliary loss to train the model using the output of the intermediate layer and unpunctuated texts. Through experiments, we compare the performance of the proposed model to that of a cascaded system. The proposed model achieves higher punctuation prediction accuracy than the cascaded system without sacrificing the speech recognition error rate. It is also demonstrated that the multi-task learning using the intermediate output against the unpunctuated text is effective. Moreover, the proposed model has only about 1/7th of the parameters compared to the cascaded system.
Masked Surfel Prediction for Self-Supervised Point Cloud Learning
Jul 07, 2022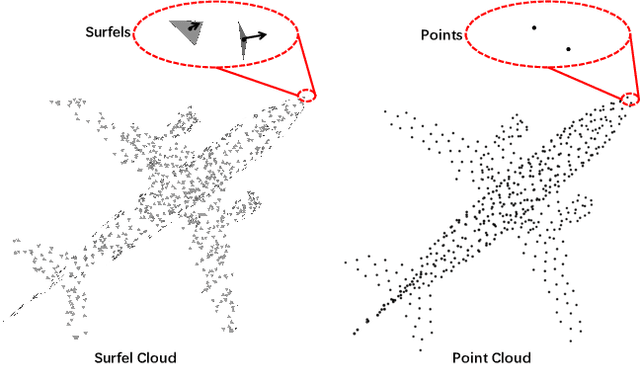
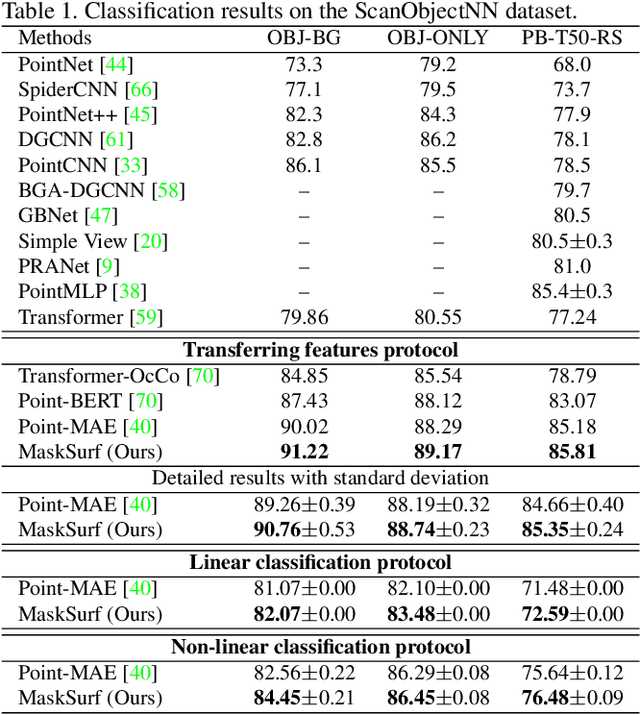

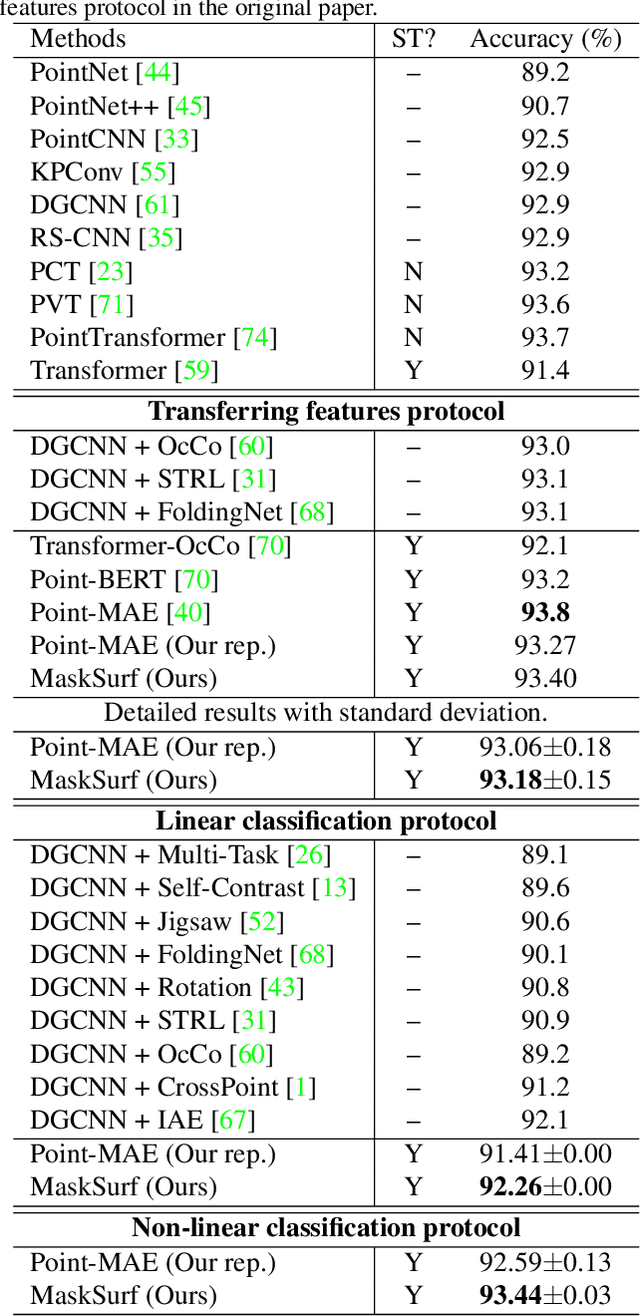
Masked auto-encoding is a popular and effective self-supervised learning approach to point cloud learning. However, most of the existing methods reconstruct only the masked points and overlook the local geometry information, which is also important to understand the point cloud data. In this work, we make the first attempt, to the best of our knowledge, to consider the local geometry information explicitly into the masked auto-encoding, and propose a novel Masked Surfel Prediction (MaskSurf) method. Specifically, given the input point cloud masked at a high ratio, we learn a transformer-based encoder-decoder network to estimate the underlying masked surfels by simultaneously predicting the surfel positions (i.e., points) and per-surfel orientations (i.e., normals). The predictions of points and normals are supervised by the Chamfer Distance and a newly introduced Position-Indexed Normal Distance in a set-to-set manner. Our MaskSurf is validated on six downstream tasks under three fine-tuning strategies. In particular, MaskSurf outperforms its closest competitor, Point-MAE, by 1.2\% on the real-world dataset of ScanObjectNN under the OBJ-BG setting, justifying the advantages of masked surfel prediction over masked point cloud reconstruction. Codes will be available at https://github.com/YBZh/MaskSurf.
Associative Learning Mechanism for Drug-Target Interaction Prediction
Jun 01, 2022

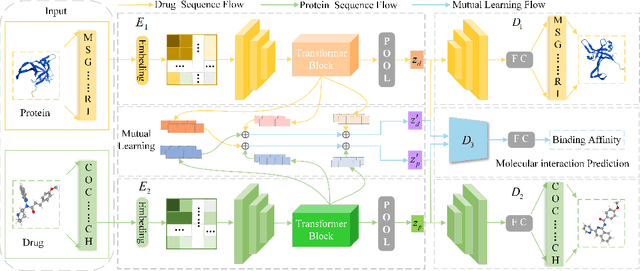
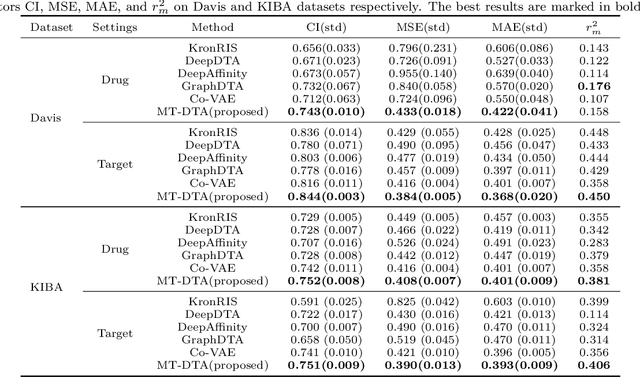
As a necessary process in drug development, finding a drug compound that can selectively bind to a specific protein is highly challenging and costly. Drug-target affinity (DTA), which represents the strength of drug-target interaction (DTI), has played an important role in the DTI prediction task over the past decade. Although deep learning has been applied to DTA-related research, existing solutions ignore fundamental correlations between molecular substructures in molecular representation learning of drug compound molecules/protein targets. Moreover, traditional methods lack the interpretability of the DTA prediction process. This results in missing feature information of intermolecular interactions, thereby affecting prediction performance. Therefore, this paper proposes a DTA prediction method with interactive learning and an autoencoder mechanism. The proposed model enhances the corresponding ability to capture the feature information of a single molecular sequence by the drug/protein molecular representation learning module and supplements the information interaction between molecular sequence pairs by the interactive information learning module. The DTA value prediction module fuses the drug-target pair interaction information to output the predicted value of DTA. Additionally, this paper theoretically proves that the proposed method maximizes evidence lower bound (ELBO) for the joint distribution of the DTA prediction model, which enhances the consistency of the probability distribution between the actual value and the predicted value. The experimental results confirm mutual transformer-drug target affinity (MT-DTA) achieves better performance than other comparative methods.
GTrans: Grouping and Fusing Transformer Layers for Neural Machine Translation
Jul 29, 2022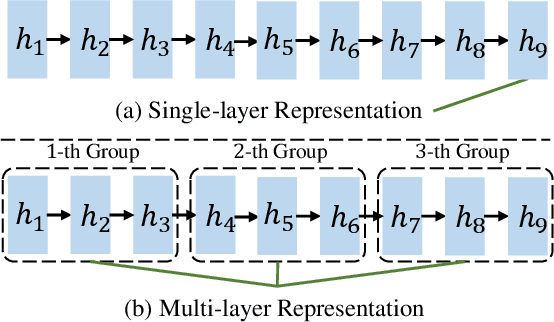
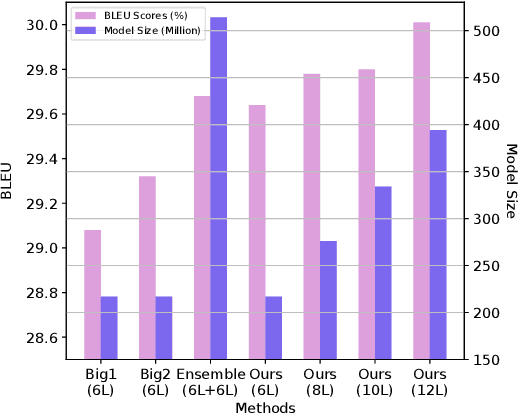
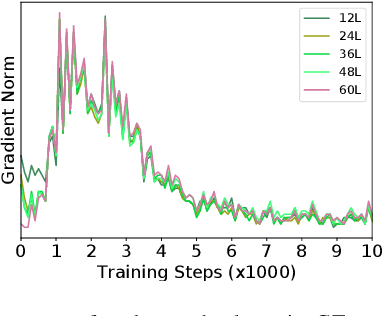
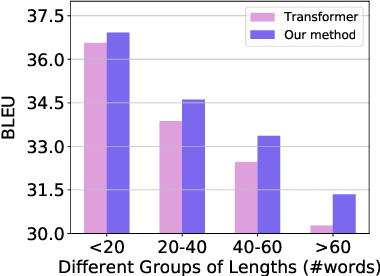
Transformer structure, stacked by a sequence of encoder and decoder network layers, achieves significant development in neural machine translation. However, vanilla Transformer mainly exploits the top-layer representation, assuming the lower layers provide trivial or redundant information and thus ignoring the bottom-layer feature that is potentially valuable. In this work, we propose the Group-Transformer model (GTrans) that flexibly divides multi-layer representations of both encoder and decoder into different groups and then fuses these group features to generate target words. To corroborate the effectiveness of the proposed method, extensive experiments and analytic experiments are conducted on three bilingual translation benchmarks and two multilingual translation tasks, including the IWLST-14, IWLST-17, LDC, WMT-14 and OPUS-100 benchmark. Experimental and analytical results demonstrate that our model outperforms its Transformer counterparts by a consistent gain. Furthermore, it can be successfully scaled up to 60 encoder layers and 36 decoder layers.
SSformer: A Lightweight Transformer for Semantic Segmentation
Aug 03, 2022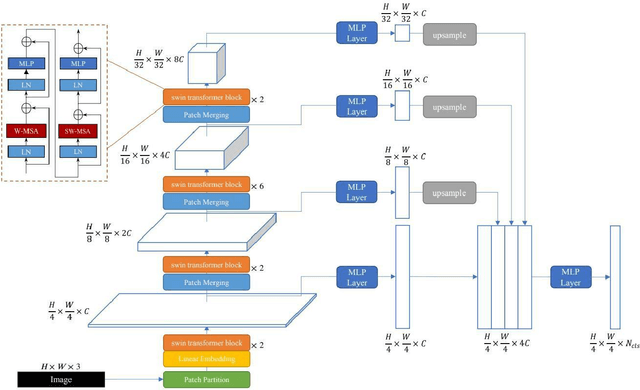


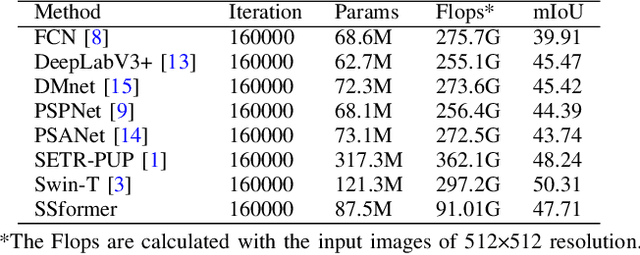
It is well believed that Transformer performs better in semantic segmentation compared to convolutional neural networks. Nevertheless, the original Vision Transformer may lack of inductive biases of local neighborhoods and possess a high time complexity. Recently, Swin Transformer sets a new record in various vision tasks by using hierarchical architecture and shifted windows while being more efficient. However, as Swin Transformer is specifically designed for image classification, it may achieve suboptimal performance on dense prediction-based segmentation task. Further, simply combing Swin Transformer with existing methods would lead to the boost of model size and parameters for the final segmentation model. In this paper, we rethink the Swin Transformer for semantic segmentation, and design a lightweight yet effective transformer model, called SSformer. In this model, considering the inherent hierarchical design of Swin Transformer, we propose a decoder to aggregate information from different layers, thus obtaining both local and global attentions. Experimental results show the proposed SSformer yields comparable mIoU performance with state-of-the-art models, while maintaining a smaller model size and lower compute.
SearchMorph:Multi-scale Correlation Iterative Network for Deformable Registration
Jun 27, 2022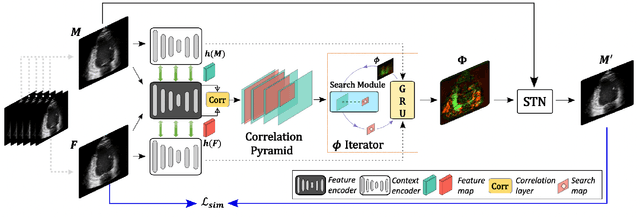
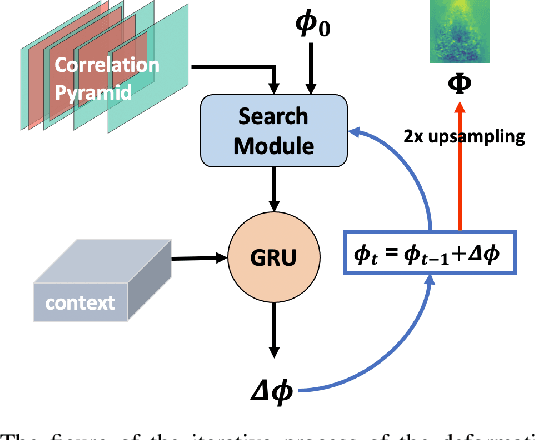
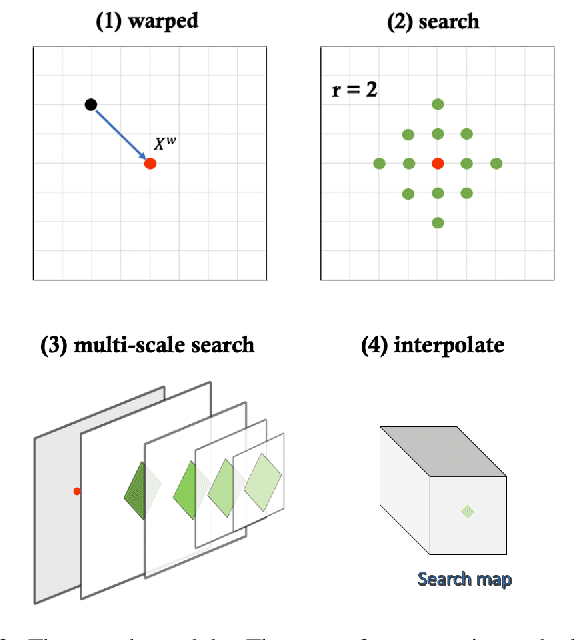
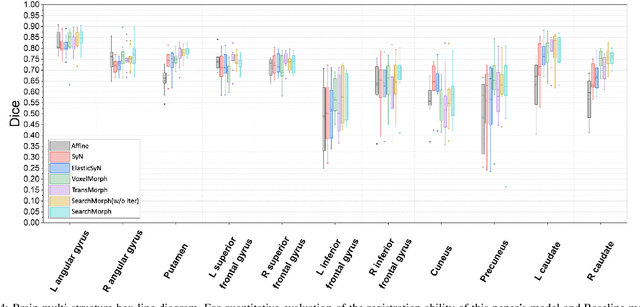
Deformable image registration provides dynamic information about the image and is essential in medical image analysis. However, due to the different characteristics of single-temporal brain MR images and multi-temporal echocardiograms, it is difficult to accurately register them using the same algorithm or model. We propose an unsupervised multi-scale correlation iterative registration network (SearchMorph), and the model has three highlights. (1)We introduced cost volumes to strengthen feature correlations and constructed correlation pyramids to complement multi-scale correlation information. (2) We designed the search module to search for the registration of features in multi-scale pyramids. (3) We use the GRU module for iterative refinement of the deformation field. The proposed network in this paper shows leadership in common single-temporal registration tasks and solves multi-temporal motion estimation tasks. The experimental results show that our proposed method achieves higher registration accuracy and a lower folding point ratio than the state-of-the-art methods.
Generalized BER of MCIK-OFDM with Imperfect CSI: Selection combining GD versus ML receivers
Jul 29, 2022



This paper analyzes the bit error rate (BER) of multicarrier index keying - orthogonal frequency division multiplexing (MCIK-OFDM) with selection combining (SC) diversity reception. Particularly, we propose a generalized framework to derive the BER for both the low-complexity greedy detector (GD) and maximum likelihood (ML) detector. Based on this, closedform expressions for the BERs of MCIK-OFDM with the SC using either the ML or the GD are derived in presence of the channel state information (CSI) imperfection. The asymptotic analysis is presented to gain helpful insights into effects of different CSI conditions on the BERs of these two detectors. More importantly, we theoretically provide opportunities for using the GD instead of the ML under each specific CSI uncertainty, which depend on the number of receiver antennas and the M-ary modulation size. Finally, extensive simulation results are provided in order to validate our theoretical expressions and analysis.
TabText: a Systematic Approach to Aggregate Knowledge Across Tabular Data Structures
Jun 21, 2022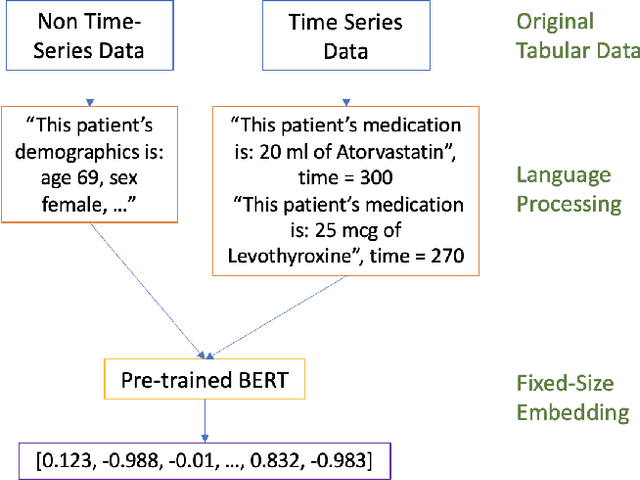
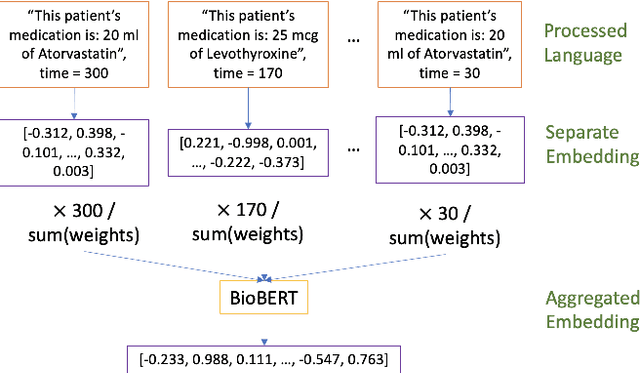
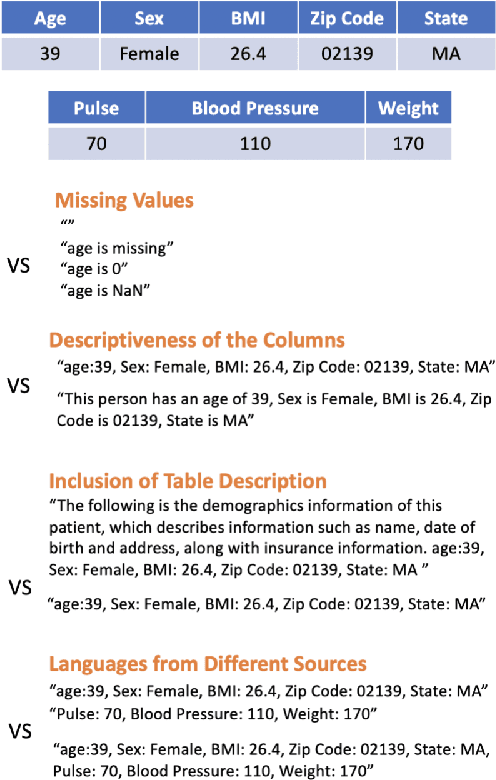
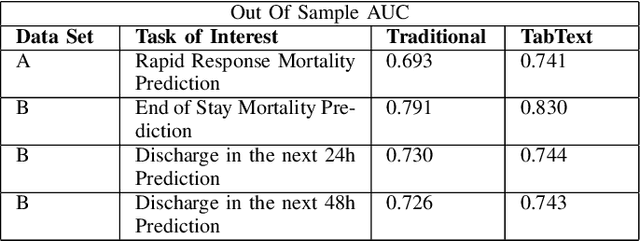
Processing and analyzing tabular data in a productive and efficient way is essential for building successful applications of machine learning in fields such as healthcare. However, the lack of a unified framework for representing and standardizing tabular information poses a significant challenge to researchers and professionals alike. In this work, we present TabText, a methodology that leverages the unstructured data format of language to encode tabular data from different table structures and time periods efficiently and accurately. We show using two healthcare datasets and four prediction tasks that features extracted via TabText outperform those extracted with traditional processing methods by 2-5%. Furthermore, we analyze the sensitivity of our framework against different choices for sentence representations of missing values, meta information and language descriptiveness, and provide insights into winning strategies that improve performance.
The Geometry of Multilingual Language Model Representations
May 22, 2022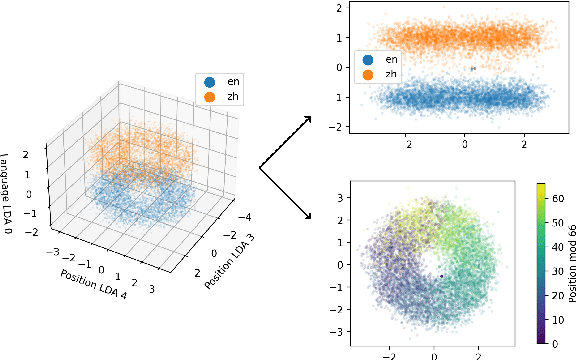
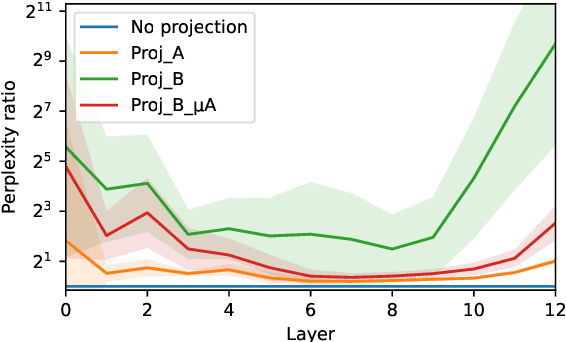
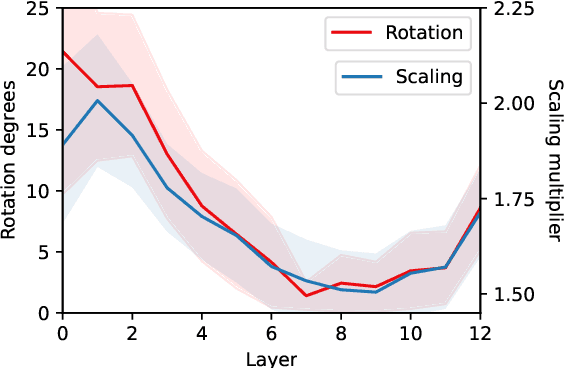
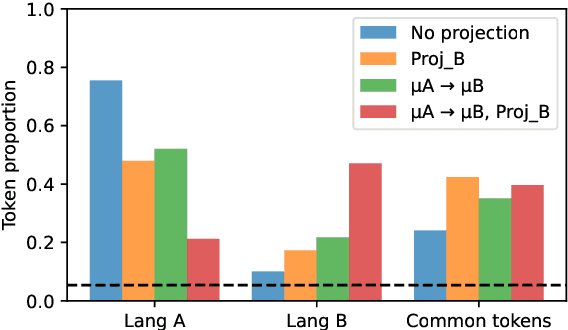
We assess how multilingual language models maintain a shared multilingual representation space while still encoding language-sensitive information in each language. Using XLM-R as a case study, we show that languages occupy similar linear subspaces after mean-centering, evaluated based on causal effects on language modeling performance and direct comparisons between subspaces for 88 languages. The subspace means differ along language-sensitive axes that are relatively stable throughout middle layers, and these axes encode information such as token vocabularies. Shifting representations by language means is sufficient to induce token predictions in different languages. However, we also identify stable language-neutral axes that encode information such as token positions and part-of-speech. We visualize representations projected onto language-sensitive and language-neutral axes, identifying language family and part-of-speech clusters, along with spirals, toruses, and curves representing token position information. These results demonstrate that multilingual language models encode information along orthogonal language-sensitive and language-neutral axes, allowing the models to extract a variety of features for downstream tasks and cross-lingual transfer learning.