 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCustomized Fusion: A Closed-Loop Dynamic Network for Adaptive Multi-Task-Aware Infrared-Visible Image Fusion
Apr 10, 2026Infrared-visible image fusion aims to integrate complementary information for robust visual understanding, but existing fusion methods struggle with simultaneously adapting to multiple downstream tasks. To address this issue, we propose a Closed-Loop Dynamic Network (CLDyN) that can adaptively respond to the semantic requirements of diverse downstream tasks for task-customized image fusion. Specifically, CLDyN introduces a closed-loop optimization mechanism that establishes a semantic transmission chain to achieve explicit feedback from downstream tasks to the fusion network through a Requirement-driven Semantic Compensation (RSC) module. The RSC module leverages a Basis Vector Bank (BVB) and an Architecture-Adaptive Semantic Injection (A2SI) block to customize the network architecture according to task requirements, thereby enabling task-specific semantic compensation and allowing the fusion network to actively adapt to diverse tasks without retraining. To promote semantic compensation, a reward-penalty strategy is introduced to reward or penalize the RSC module based on task performance variations. Experiments on the M3FD, FMB, and VT5000 datasets demonstrate that CLDyN not only maintains high fusion quality but also exhibits strong multi-task adaptability. The code is available at https://github.com/YR0211/CLDyN.
Associative Learning Mechanism for Drug-Target Interaction Prediction
Jun 01, 2022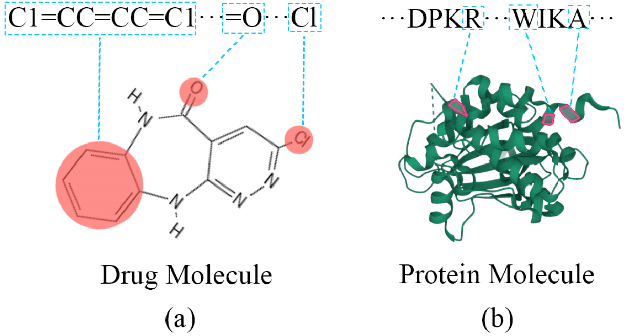

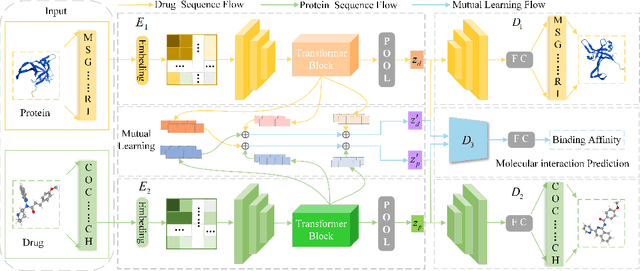
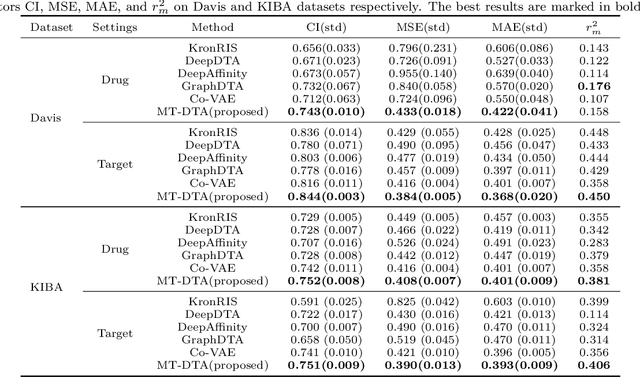
As a necessary process in drug development, finding a drug compound that can selectively bind to a specific protein is highly challenging and costly. Drug-target affinity (DTA), which represents the strength of drug-target interaction (DTI), has played an important role in the DTI prediction task over the past decade. Although deep learning has been applied to DTA-related research, existing solutions ignore fundamental correlations between molecular substructures in molecular representation learning of drug compound molecules/protein targets. Moreover, traditional methods lack the interpretability of the DTA prediction process. This results in missing feature information of intermolecular interactions, thereby affecting prediction performance. Therefore, this paper proposes a DTA prediction method with interactive learning and an autoencoder mechanism. The proposed model enhances the corresponding ability to capture the feature information of a single molecular sequence by the drug/protein molecular representation learning module and supplements the information interaction between molecular sequence pairs by the interactive information learning module. The DTA value prediction module fuses the drug-target pair interaction information to output the predicted value of DTA. Additionally, this paper theoretically proves that the proposed method maximizes evidence lower bound (ELBO) for the joint distribution of the DTA prediction model, which enhances the consistency of the probability distribution between the actual value and the predicted value. The experimental results confirm mutual transformer-drug target affinity (MT-DTA) achieves better performance than other comparative methods.