 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Nearly Optimal Latent State Decoding in Block MDPs
Aug 17, 2022
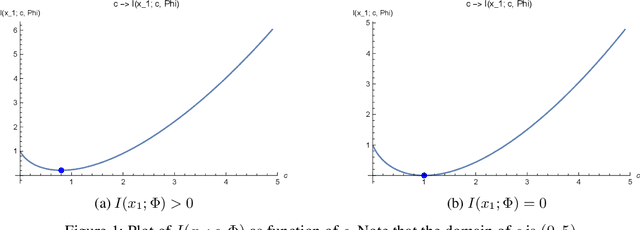
We investigate the problems of model estimation and reward-free learning in episodic Block MDPs. In these MDPs, the decision maker has access to rich observations or contexts generated from a small number of latent states. We are first interested in estimating the latent state decoding function (the mapping from the observations to latent states) based on data generated under a fixed behavior policy. We derive an information-theoretical lower bound on the error rate for estimating this function and present an algorithm approaching this fundamental limit. In turn, our algorithm also provides estimates of all the components of the MDP. We then study the problem of learning near-optimal policies in the reward-free framework. Based on our efficient model estimation algorithm, we show that we can infer a policy converging (as the number of collected samples grows large) to the optimal policy at the best possible rate. Interestingly, our analysis provides necessary and sufficient conditions under which exploiting the block structure yields improvements in the sample complexity for identifying near-optimal policies. When these conditions are met, the sample complexity in the minimax reward-free setting is improved by a multiplicative factor $n$, where $n$ is the number of possible contexts.
Adaptively-weighted Integral Space for Fast Multiview Clustering
Aug 25, 2022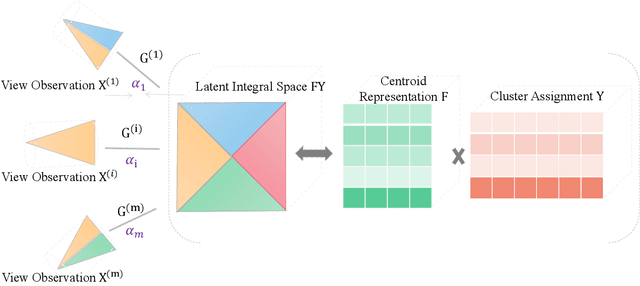
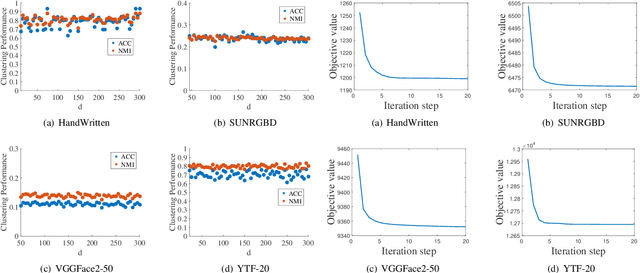
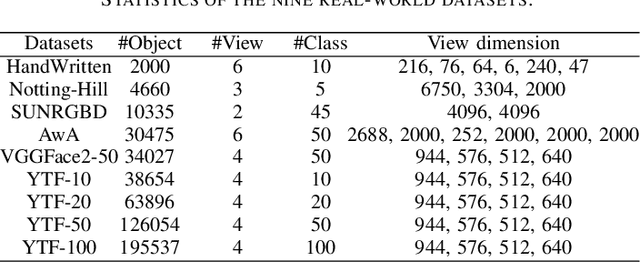
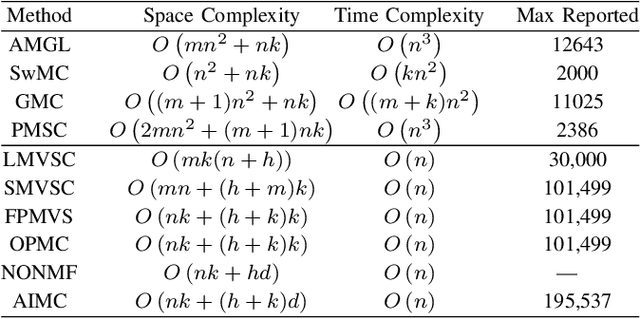
Multiview clustering has been extensively studied to take advantage of multi-source information to improve the clustering performance. In general, most of the existing works typically compute an n * n affinity graph by some similarity/distance metrics (e.g. the Euclidean distance) or learned representations, and explore the pairwise correlations across views. But unfortunately, a quadratic or even cubic complexity is often needed, bringing about difficulty in clustering largescale datasets. Some efforts have been made recently to capture data distribution in multiple views by selecting view-wise anchor representations with k-means, or by direct matrix factorization on the original observations. Despite the significant success, few of them have considered the view-insufficiency issue, implicitly holding the assumption that each individual view is sufficient to recover the cluster structure. Moreover, the latent integral space as well as the shared cluster structure from multiple insufficient views is not able to be simultaneously discovered. In view of this, we propose an Adaptively-weighted Integral Space for Fast Multiview Clustering (AIMC) with nearly linear complexity. Specifically, view generation models are designed to reconstruct the view observations from the latent integral space with diverse adaptive contributions. Meanwhile, a centroid representation with orthogonality constraint and cluster partition are seamlessly constructed to approximate the latent integral space. An alternate minimizing algorithm is developed to solve the optimization problem, which is proved to have linear time complexity w.r.t. the sample size. Extensive experiments conducted on several realworld datasets confirm the superiority of the proposed AIMC method compared with the state-of-the-art methods.
REZCR: A Zero-shot Character Recognition Method via Radical Extraction
Jul 12, 2022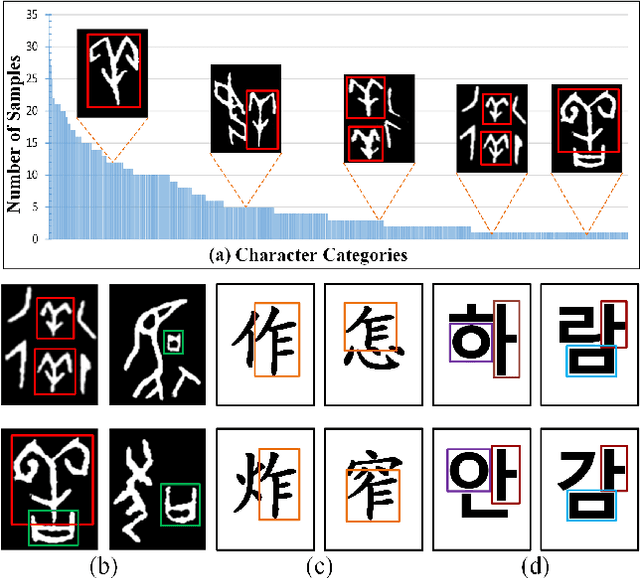
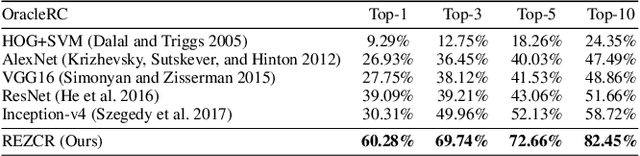
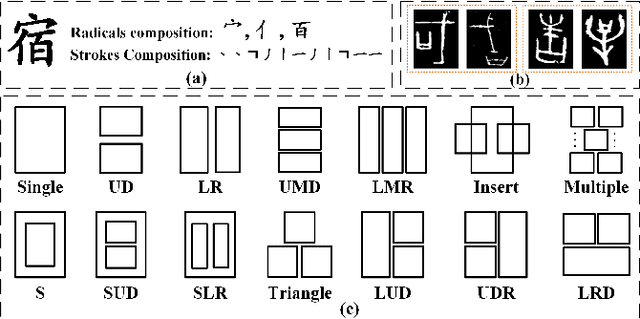

The long-tail effect is a common issue that limits the performance of deep learning models on real-world datasets. Character image dataset development is also affected by such unbalanced data distribution due to differences in character usage frequency. Thus, current character recognition methods are limited when applying to real-world datasets, in particular to the character categories in the tail which are lacking training samples, e.g., uncommon characters, or characters from historical documents. In this paper, we propose a zero-shot character recognition framework via radical extraction, i.e., REZCR, to improve the recognition performance of few-sample character categories, in which we exploit information on radicals, the graphical units of characters, by decomposing and reconstructing characters following orthography. REZCR consists of an attention-based radical information extractor (RIE) and a knowledge graph-based character reasoner (KGR). The RIE aims to recognize candidate radicals and their possible structural relations from character images. The results will be fed into KGR to recognize the target character by reasoning with a pre-designed character knowledge graph. We validate our method on multiple datasets, REZCR shows promising experimental results, especially for few-sample character datasets.
Multi-Module G2P Converter for Persian Focusing on Relations between Words
Aug 02, 2022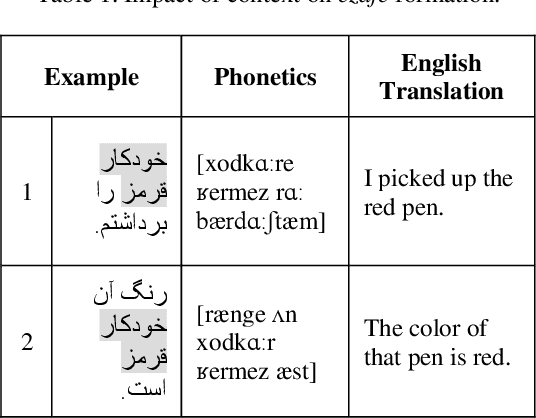
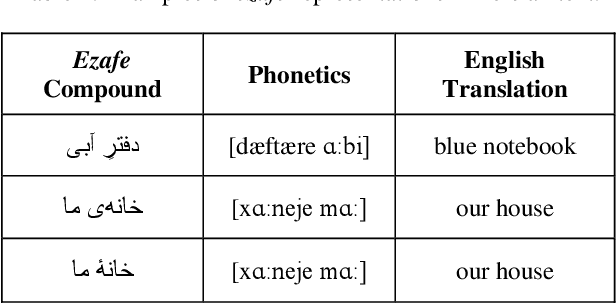
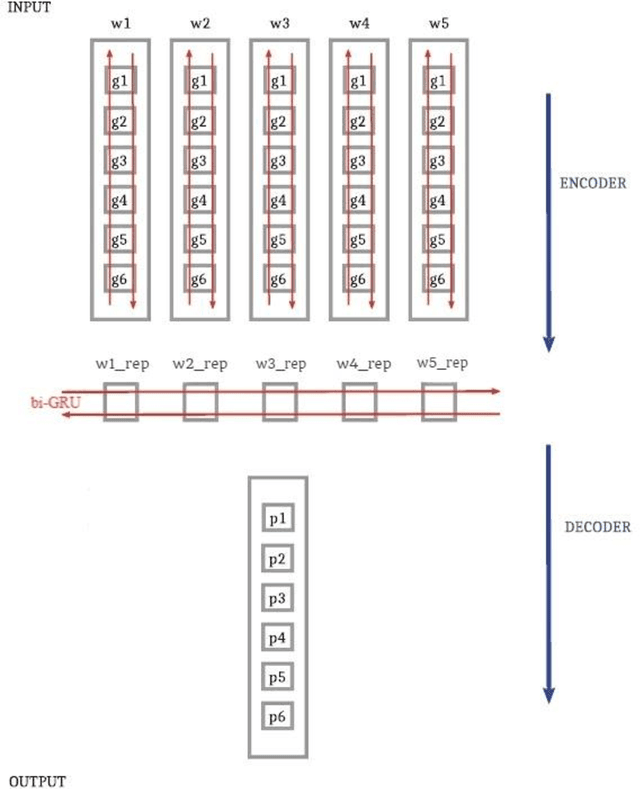
In this paper, we investigate the application of end-to-end and multi-module frameworks for G2P conversion for the Persian language. The results demonstrate that our proposed multi-module G2P system outperforms our end-to-end systems in terms of accuracy and speed. The system consists of a pronunciation dictionary as our look-up table, along with separate models to handle homographs, OOVs and ezafe in Persian created using GRU and Transformer architectures. The system is sequence-level rather than word-level, which allows it to effectively capture the unwritten relations between words (cross-word information) necessary for homograph disambiguation and ezafe recognition without the need for any pre-processing. After evaluation, our system achieved a 94.48% word-level accuracy, outperforming the previous G2P systems for Persian.
AI in Telemedicine: An Appraisal on Deep Learning-Based Approaches to Virtual Diagnostic Solutions (VDS)
Jul 31, 2022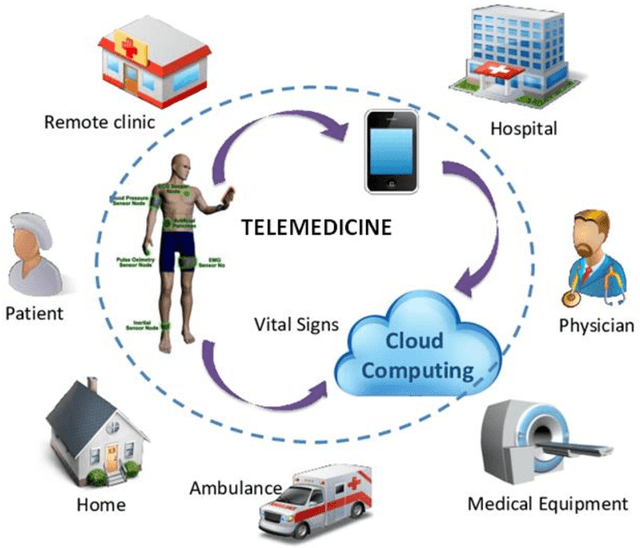


Advancements in Telemedicine as an approach to healthcare delivery have heralded a new dawn in modern Medicine. Its fast-paced development in our contemporary society is credence to the advances in Artificial Intelligence and Information Technology. This paper carries out a descriptive study to broadly explore AI's implementations in healthcare delivery with a more holistic view of the usability of various Telemedical Innovations in enhancing Virtual Diagnostic Solutions (VDS). This research further explores notable developments in Deep Learning model optimizations for Virtual Diagnostic Solutions. A further research review on the prospects of Virtual Diagnostic Solutions (VDS) and foreseeable challenges was also highlighted. Conclusively, this research gives a general overview of Artificial Intelligence in Telemedicine with a central focus on Deep Learning-based approaches to Virtual Diagnostic Solutions.
Text Enriched Sparse Hyperbolic Graph Convolutional Networks
Jul 07, 2022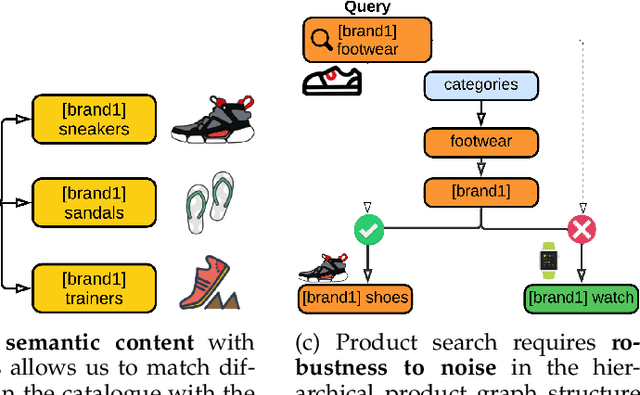

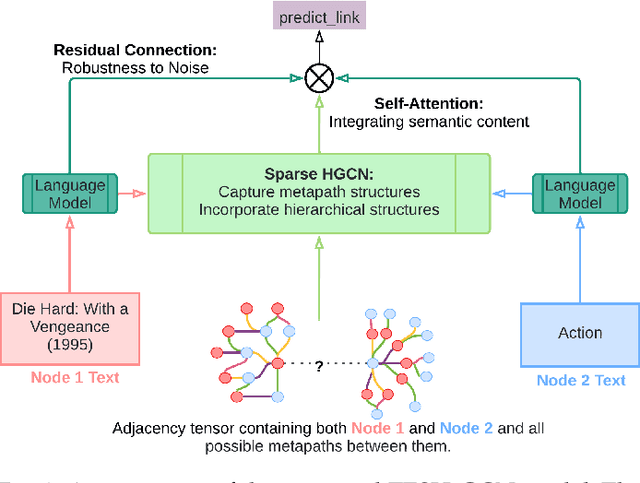
Heterogeneous networks, which connect informative nodes containing text with different edge types, are routinely used to store and process information in various real-world applications. Graph Neural Networks (GNNs) and their hyperbolic variants provide a promising approach to encode such networks in a low-dimensional latent space through neighborhood aggregation and hierarchical feature extraction, respectively. However, these approaches typically ignore metapath structures and the available semantic information. Furthermore, these approaches are sensitive to the noise present in the training data. To tackle these limitations, in this paper, we propose Text Enriched Sparse Hyperbolic Graph Convolution Network (TESH-GCN) to capture the graph's metapath structures using semantic signals and further improve prediction in large heterogeneous graphs. In TESH-GCN, we extract semantic node information, which successively acts as a connection signal to extract relevant nodes' local neighborhood and graph-level metapath features from the sparse adjacency tensor in a reformulated hyperbolic graph convolution layer. These extracted features in conjunction with semantic features from the language model (for robustness) are used for the final downstream task. Experiments on various heterogeneous graph datasets show that our model outperforms the current state-of-the-art approaches by a large margin on the task of link prediction. We also report a reduction in both the training time and model parameters compared to the existing hyperbolic approaches through a reformulated hyperbolic graph convolution. Furthermore, we illustrate the robustness of our model by experimenting with different levels of simulated noise in both the graph structure and text, and also, present a mechanism to explain TESH-GCN's prediction by analyzing the extracted metapaths.
Resource Allocation for Simultaneous Wireless Information and Power Transfer Systems: A Tutorial Overview
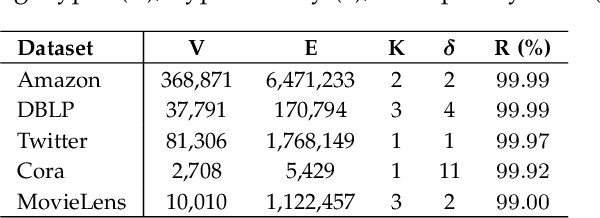
Oct 14, 2021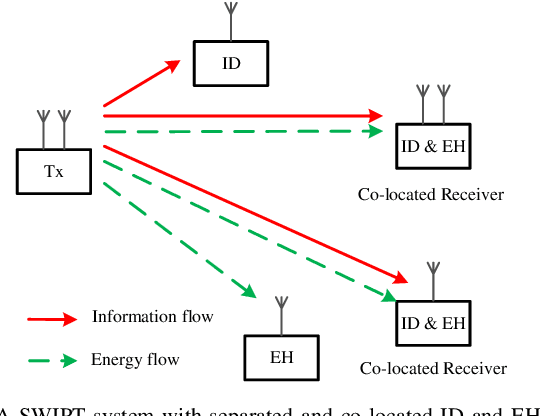
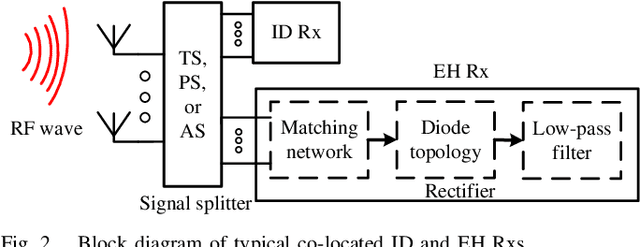
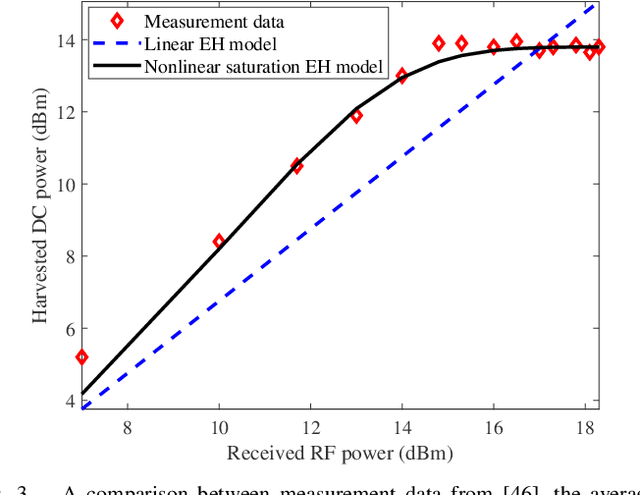
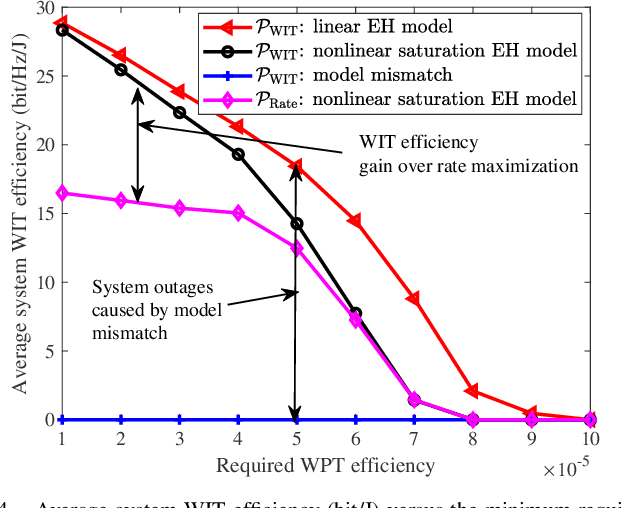
Over the last decade, simultaneous wireless information and power transfer (SWIPT) has become a practical and promising solution for connecting and recharging battery-limited devices, thanks to significant advances in low-power electronics technology and wireless communications techniques. To realize the promised potentials, advanced resource allocation design plays a decisive role in revealing, understanding, and exploiting the intrinsic rate-energy tradeoff capitalizing on the dual use of radio frequency (RF) signals for wireless charging and communication. In this paper, we provide a comprehensive tutorial overview of SWIPT from the perspective of resource allocation design. The fundamental concepts, system architectures, and RF energy harvesting (EH) models are introduced. In particular, three commonly adopted EH models, namely the linear EH model, the nonlinear saturation EH model, and the nonlinear circuit-based EH model are characterized and discussed. Then, for a typical wireless system setup, we establish a generalized resource allocation design framework which subsumes conventional resource allocation design problems as special cases. Subsequently, we elaborate on relevant tools from optimization theory and exploit them for solving representative resource allocation design problems for SWIPT systems with and without perfect channel state information (CSI) available at the transmitter, respectively. The associated technical challenges and insights are also highlighted. Furthermore, we discuss several promising and exciting future research directions for resource allocation design for SWIPT systems intertwined with cutting-edge communication technologies, such as intelligent reflecting surfaces, unmanned aerial vehicles, mobile edge computing, federated learning, and machine learning.
Generalizable Medical Image Segmentation via Random Amplitude Mixup and Domain-Specific Image Restoration
Aug 08, 2022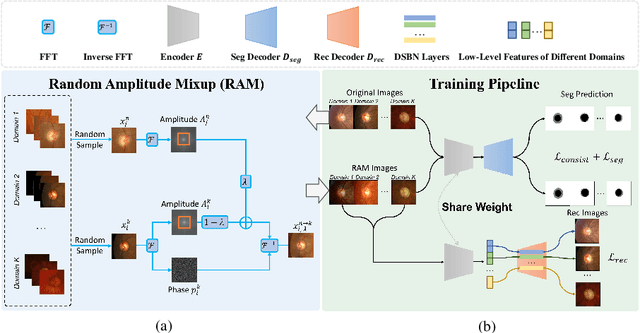
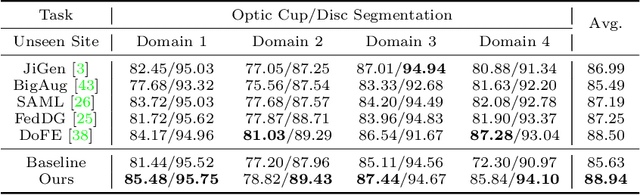
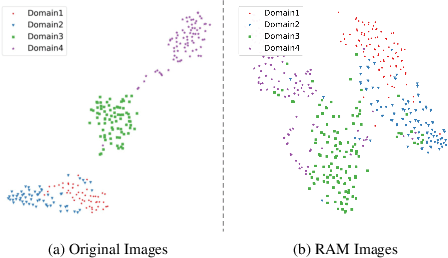
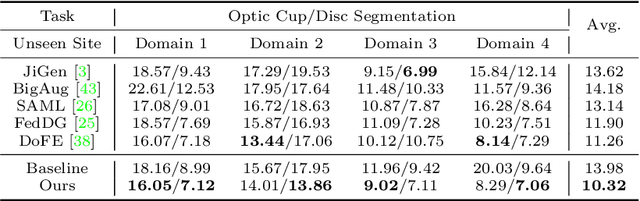
For medical image analysis, segmentation models trained on one or several domains lack generalization ability to unseen domains due to discrepancies between different data acquisition policies. We argue that the degeneration in segmentation performance is mainly attributed to overfitting to source domains and domain shift. To this end, we present a novel generalizable medical image segmentation method. To be specific, we design our approach as a multi-task paradigm by combining the segmentation model with a self-supervision domain-specific image restoration (DSIR) module for model regularization. We also design a random amplitude mixup (RAM) module, which incorporates low-level frequency information of different domain images to synthesize new images. To guide our model be resistant to domain shift, we introduce a semantic consistency loss. We demonstrate the performance of our method on two public generalizable segmentation benchmarks in medical images, which validates our method could achieve the state-of-the-art performance.
Multi-Depth Boundary-Aware Left Atrial Scar Segmentation Network
Aug 08, 2022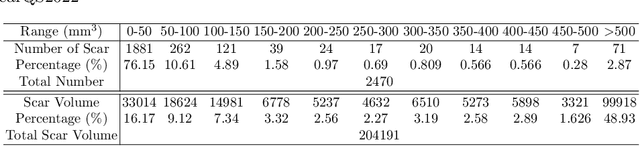
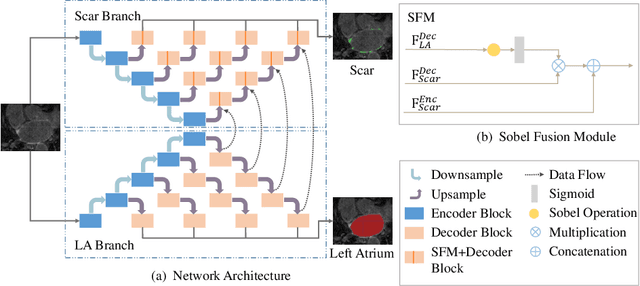
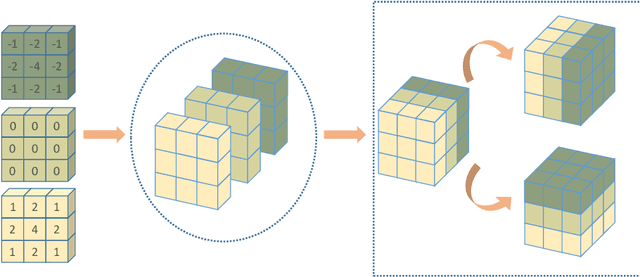

Automatic segmentation of left atrial (LA) scars from late gadolinium enhanced CMR images is a crucial step for atrial fibrillation (AF) recurrence analysis. However, delineating LA scars is tedious and error-prone due to the variation of scar shapes. In this work, we propose a boundary-aware LA scar segmentation network, which is composed of two branches to segment LA and LA scars, respectively. We explore the inherent spatial relationship between LA and LA scars. By introducing a Sobel fusion module between the two segmentation branches, the spatial information of LA boundaries can be propagated from the LA branch to the scar branch. Thus, LA scar segmentation can be performed condition on the LA boundaries regions. In our experiments, 40 labeled images were used to train the proposed network, and the remaining 20 labeled images were used for evaluation. The network achieved an average Dice score of 0.608 for LA scar segmentation.
Optimal Measurement of Drone Swarm in RSS-based Passive Localization with Region Constraints
Aug 08, 2022
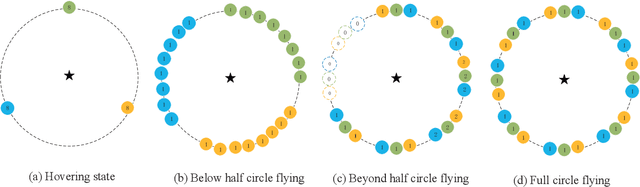
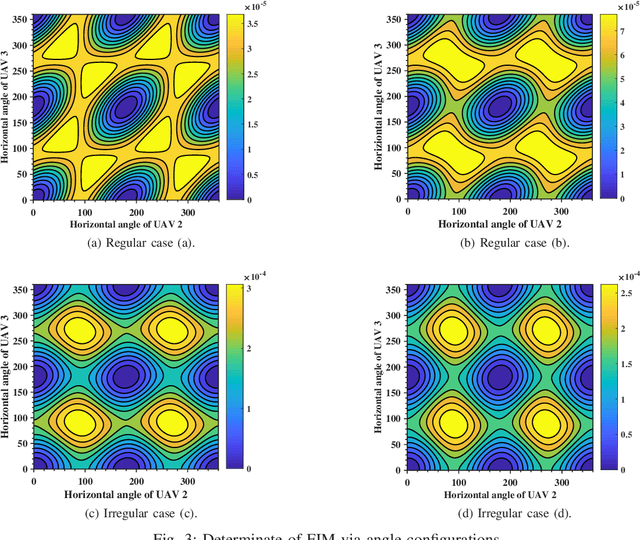
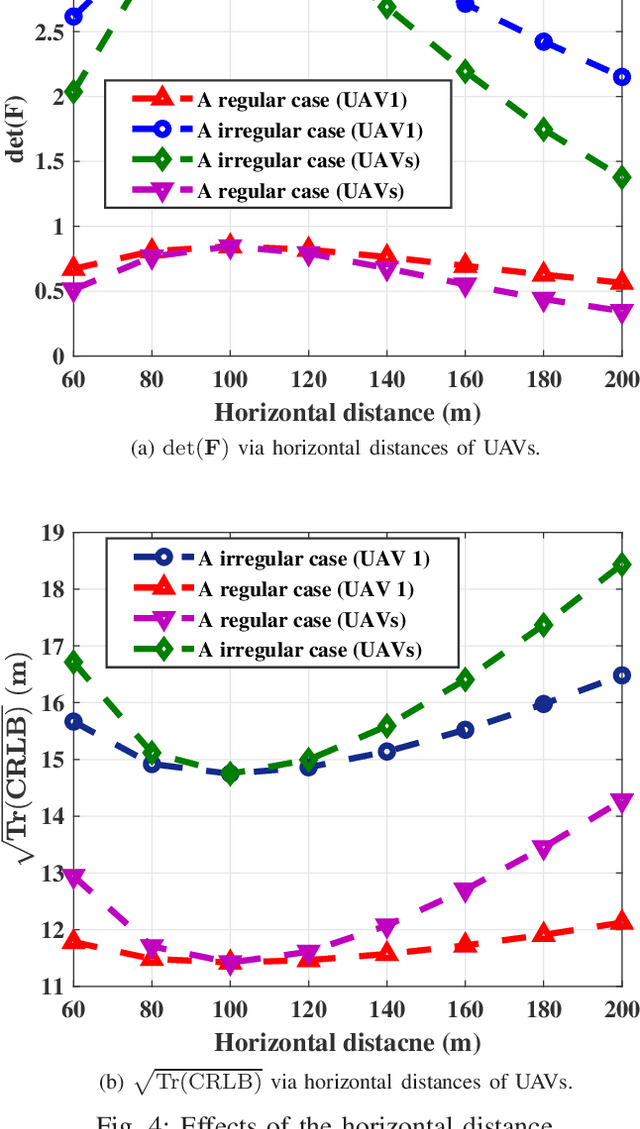
Passive geolocation by multiple unmanned aerial vehicles (UAVs) covers a wide range of military and civilian applications including rescue, wild life tracking and electronic warfare. The sensor-target geometry is known to significantly affect the localization precision. The existing sensor placement strategies mainly work on the cases without any constraints on the sensors locations. However, UAVs cannot fly/hover simply in arbitrary region due to realistic constraints, such as the geographical limitations, the security issues, and the max flying speed. In this paper, optimal geometrical configurations of UAVs in received signal strength (RSS)-based localization under region constraints are investigated. Employing the D-optimal criteria, i.e., minimizing the determinate of Fisher information matrix (FIM), such optimal problem is formulated. Based on the rigorous algebra and geometrical derivations, optimal and also closed form configurations of UAVs under different flying states are proposed. Finally, the effectiveness and practicality of the proposed configurations are demonstrated by simulation examples.