 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Linear MIMO Precoders Design for Finite Alphabet Inputs via Model-Free Training
Aug 04, 2022
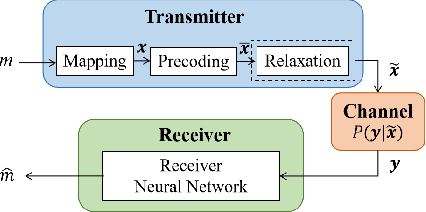
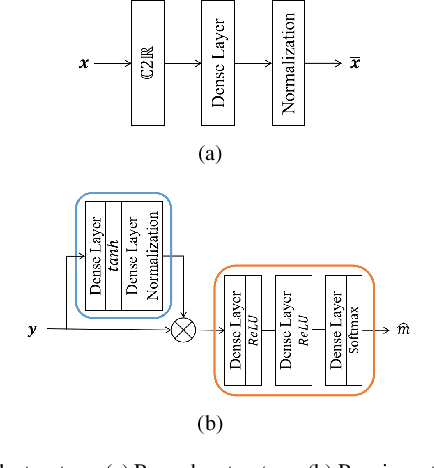
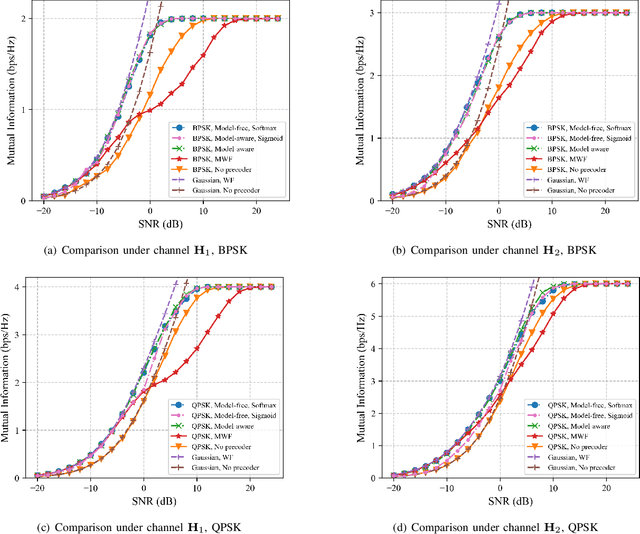
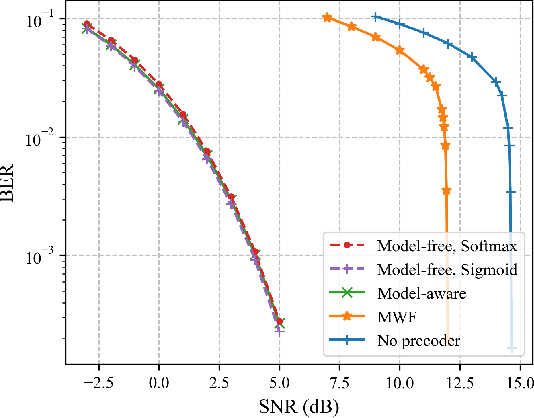
This paper investigates a novel method for designing linear precoders with finite alphabet inputs based on autoencoders (AE) without the knowledge of the channel model. By model-free training of the autoencoder in a multiple-input multiple-output (MIMO) system, the proposed method can effectively solve the optimization problem to design the precoders that maximize the mutual information between the channel inputs and outputs, when only the input-output information of the channel can be observed. Specifically, the proposed method regards the receiver and the precoder as two independent parameterized functions in the AE and alternately trains them using the exact and approximated gradient, respectively. Compared with previous precoders design methods, it alleviates the limitation of requiring the explicit channel model to be known. Simulation results show that the proposed method works as well as those methods under known channel models in terms of maximizing the mutual information and reducing the bit error rate.
Secrecy Rate of the Cooperative RSMA-Aided UAV Downlink Relying on Optimal Relay Selection
Oct 08, 2022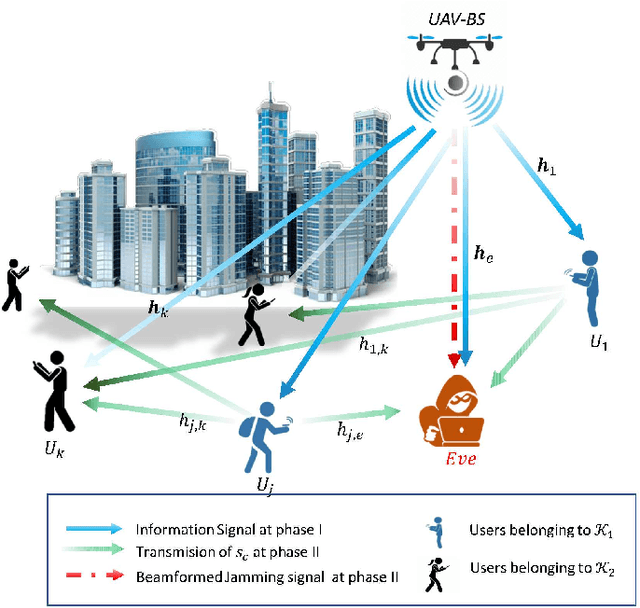

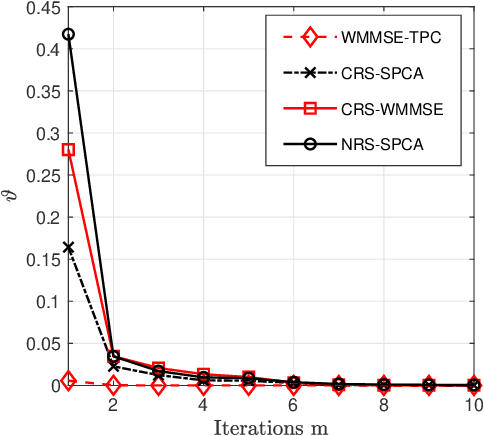
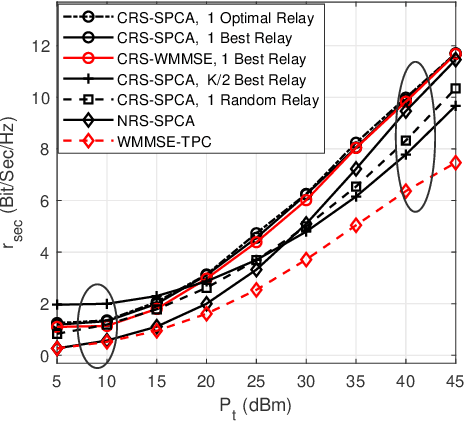
The Cooperative Rate-Splitting (CRS) scheme, proposed evolves from conventional Rate Splitting (RS) and relies on forwarding a portion of the RS message by the relaying users. In terms of secrecy enhancement, it has been shown that CRS outperforms its non-cooperative counterpart for a two-user Multiple Input Single Output (MISO) Broadcast Channel (BC). Given the massive connectivity requirement of 6G, we have generalized the existing secure two-user CRS framework to the multi-user framework, where the highest-security users must be selected as the relay nodes. This paper addresses the problem of maximizing the Worst-Case Secrecy Rate (WCSR) in a UAV-aided downlink network where a multi-antenna UAV Base-Station (UAV-BS) serves a group of users in the presence of an external eavesdropper (Eve). We consider a practical scenario in which only imperfect channel state information of Eve is available at the UAV-BS. Accordingly, we conceive a robust and secure resource allocation algorithm, which maximizes the WCSR by jointly optimizing both the Secure Relaying User Selection (SRUS) and the network parameter allocation problem, including the RS transmit precoders, message splitting variables, time slot sharing and power allocation. To circumvent the resultant non-convexity owing to the discrete variables imposed by SRUS, we propose a two-stage algorithm where the SRUS and network parameter allocation are accomplished in two consecutive stages. With regard to the SRUS, we study both centralized and distributed protocols. On the other hand, for jointly optimizing the network parameter allocation we resort to the Sequential Parametric Convex Approximation (SPCA) algorithm. Our numerical results show that the proposed solution significantly outperforms the existing benchmarks for a wide range of network loads in terms of the WCSR.
Pretrained Domain-Specific Language Model for General Information Retrieval Tasks in the AEC Domain
Mar 09, 2022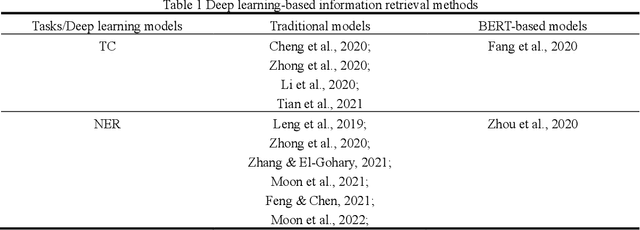
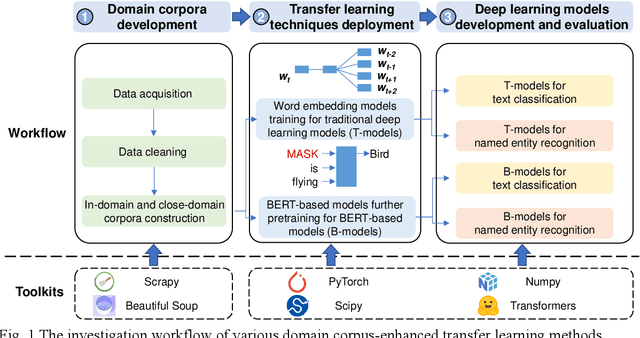
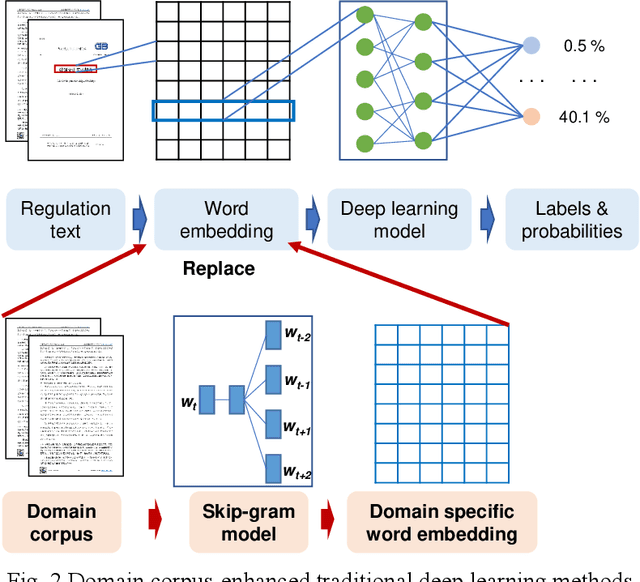

As an essential task for the architecture, engineering, and construction (AEC) industry, information retrieval (IR) from unstructured textual data based on natural language processing (NLP) is gaining increasing attention. Although various deep learning (DL) models for IR tasks have been investigated in the AEC domain, it is still unclear how domain corpora and domain-specific pretrained DL models can improve performance in various IR tasks. To this end, this work systematically explores the impacts of domain corpora and various transfer learning techniques on the performance of DL models for IR tasks and proposes a pretrained domain-specific language model for the AEC domain. First, both in-domain and close-domain corpora are developed. Then, two types of pretrained models, including traditional wording embedding models and BERT-based models, are pretrained based on various domain corpora and transfer learning strategies. Finally, several widely used DL models for IR tasks are further trained and tested based on various configurations and pretrained models. The result shows that domain corpora have opposite effects on traditional word embedding models for text classification and named entity recognition tasks but can further improve the performance of BERT-based models in all tasks. Meanwhile, BERT-based models dramatically outperform traditional methods in all IR tasks, with maximum improvements of 5.4% and 10.1% in the F1 score, respectively. This research contributes to the body of knowledge in two ways: 1) demonstrating the advantages of domain corpora and pretrained DL models and 2) opening the first domain-specific dataset and pretrained language model for the AEC domain, to the best of our knowledge. Thus, this work sheds light on the adoption and application of pretrained models in the AEC domain.
How to Define the Propagation Environment Semantics and Its Application in Scatterer-Based Beam Prediction
Sep 17, 2022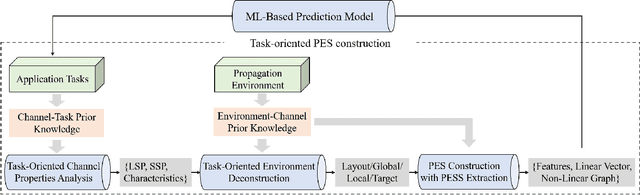
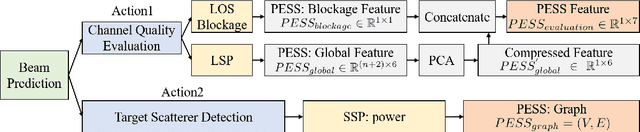
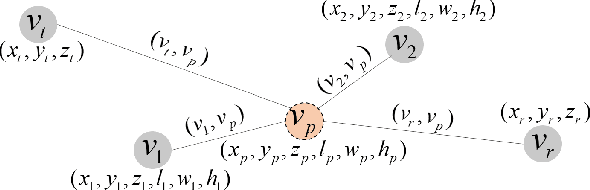
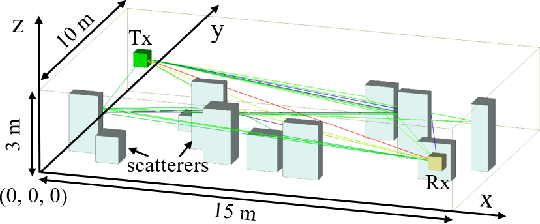
In view of the propagation environment directly determining the channel fading, the application tasks can also be solved with the aid of the environment information. Inspired by task-oriented semantic communication and machine learning (ML) powered environment-channel mapping methods, this work aims to provide a new view of the environment from the semantic level, which defines the propagation environment semantics (PES) as a limited set of propagation environment semantic symbols (PESS) for diverse application tasks. The PESS is extracted oriented to the tasks with channel properties as a foundation. For method validation, the PES-aided beam prediction (PESaBP) is presented in non-line-of-sight (NLOS). The PESS of environment features and graphs are given for the semantic actions of channel quality evaluation and target scatterer detection of maximum power, which can obtain 0.92 and 0.9 precision, respectively, and save over 87% of time cost.
Joint Network Topology Inference via a Shared Graphon Model
Sep 17, 2022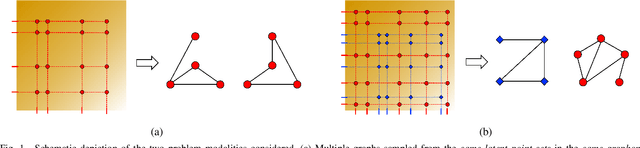
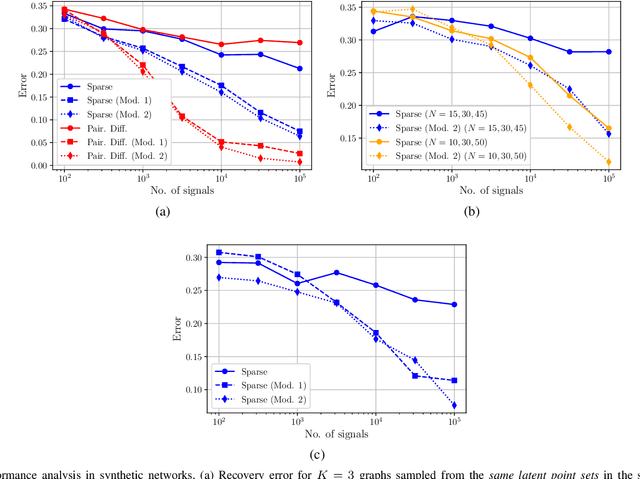
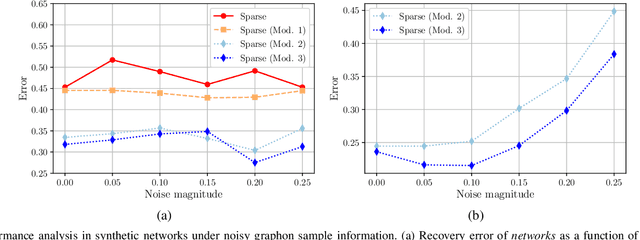
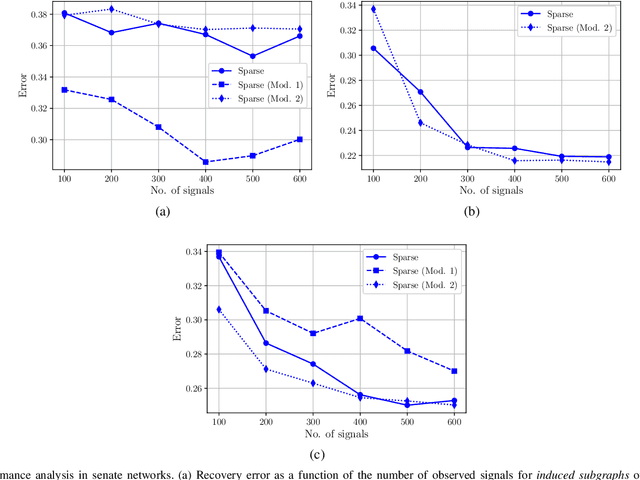
We consider the problem of estimating the topology of multiple networks from nodal observations, where these networks are assumed to be drawn from the same (unknown) random graph model. We adopt a graphon as our random graph model, which is a nonparametric model from which graphs of potentially different sizes can be drawn. The versatility of graphons allows us to tackle the joint inference problem even for the cases where the graphs to be recovered contain different number of nodes and lack precise alignment across the graphs. Our solution is based on combining a maximum likelihood penalty with graphon estimation schemes and can be used to augment existing network inference methods. The proposed joint network and graphon estimation is further enhanced with the introduction of a robust method for noisy graph sampling information. We validate our proposed approach by comparing its performance against competing methods in synthetic and real-world datasets.
Motion and Appearance Adaptation for Cross-Domain Motion Transfer
Oct 06, 2022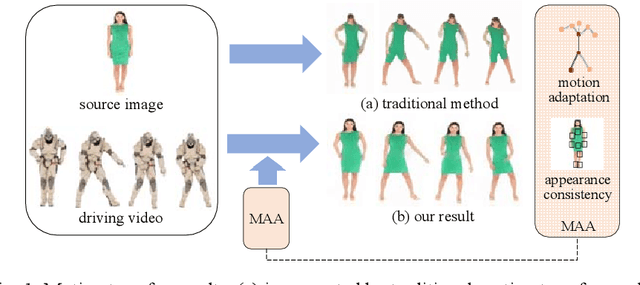
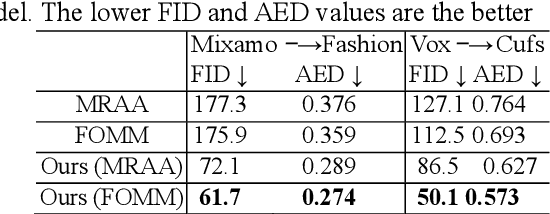
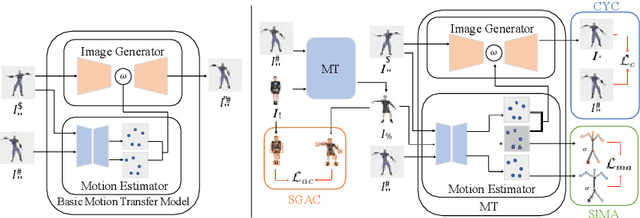
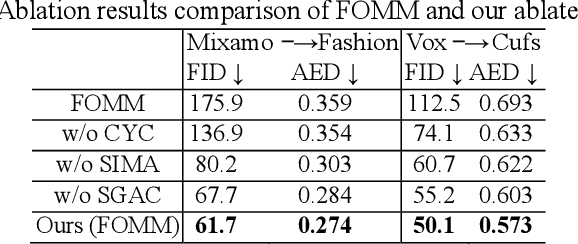
Motion transfer aims to transfer the motion of a driving video to a source image. When there are considerable differences between object in the driving video and that in the source image, traditional single domain motion transfer approaches often produce notable artifacts; for example, the synthesized image may fail to preserve the human shape of the source image (cf . Fig. 1 (a)). To address this issue, in this work, we propose a Motion and Appearance Adaptation (MAA) approach for cross-domain motion transfer, in which we regularize the object in the synthesized image to capture the motion of the object in the driving frame, while still preserving the shape and appearance of the object in the source image. On one hand, considering the object shapes of the synthesized image and the driving frame might be different, we design a shape-invariant motion adaptation module that enforces the consistency of the angles of object parts in two images to capture the motion information. On the other hand, we introduce a structure-guided appearance consistency module designed to regularize the similarity between the corresponding patches of the synthesized image and the source image without affecting the learned motion in the synthesized image. Our proposed MAA model can be trained in an end-to-end manner with a cyclic reconstruction loss, and ultimately produces a satisfactory motion transfer result (cf . Fig. 1 (b)). We conduct extensive experiments on human dancing dataset Mixamo-Video to Fashion-Video and human face dataset Vox-Celeb to Cufs; on both of these, our MAA model outperforms existing methods both quantitatively and qualitatively.
A Review of Multilingualism in and for Ontologies
Oct 06, 2022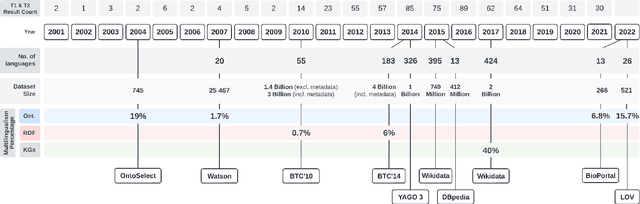
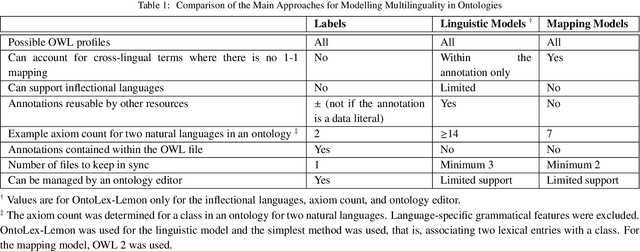
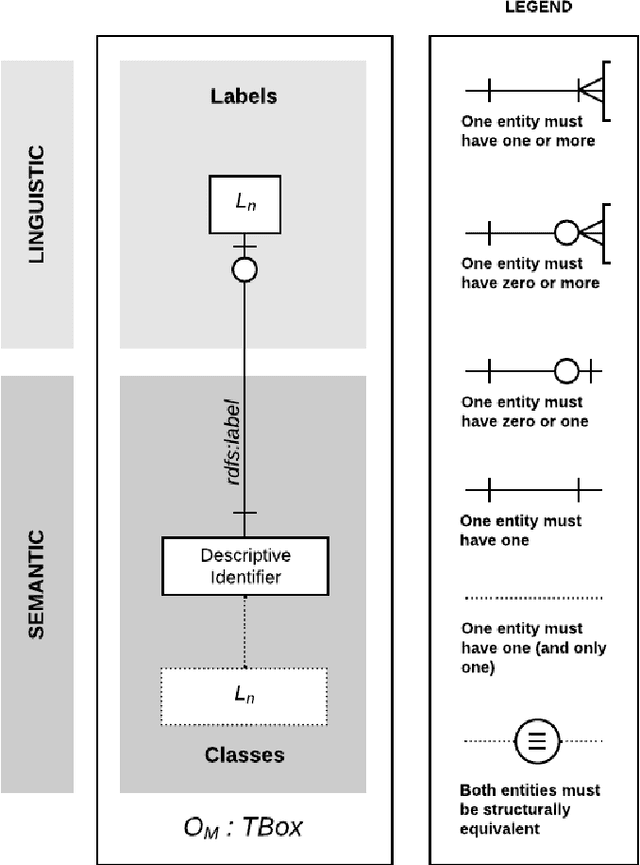

The Multilingual Semantic Web has been in focus for over a decade. Multilingualism in Linked Data and RDF has shown substantial adoption, but this is unclear for ontologies since the last review 15 years ago. One of the design goals for OWL was internationalisation, with the aim that an ontology is usable across languages and cultures. Much research to improve on multilingual ontologies has taken place in the meantime, and presumably multilingual linked data could use multilingual ontologies. Therefore, this review seeks to (i) elucidate and compare the modelling options for multilingual ontologies, (ii) examine extant ontologies for their multilingualism, and (iii) evaluate ontology editors for their ability to manage a multilingual ontology. Nine different principal approaches for modelling multilinguality in ontologies were identified, which fall into either of the following approaches: using multilingual labels, linguistic models, or a mapping-based approach. They are compared on design by means of an ad hoc visualisation mode of modelling multilingual information for ontologies, shortcomings, and what issues they aim to solve. For the ontologies, we extracted production-level and accessible ontologies from BioPortal and the LOV repositories, which had, at best, 6.77% and 15.74% multilingual ontologies, respectively, where most of them have only partial translations and they all use a labels-based approach only. Based on a set of nine tool requirements for managing multilingual ontologies, the assessment of seven relevant ontology editors showed that there are significant gaps in tooling support, with VocBench 3 nearest of meeting them all. This stock-taking may function as a new baseline and motivate new research directions for multilingual ontologies.
Learned Image Compression with Generalized Octave Convolution and Cross-Resolution Parameter Estimation
Sep 07, 2022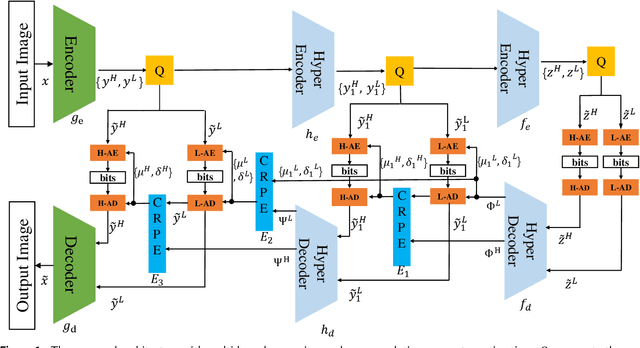

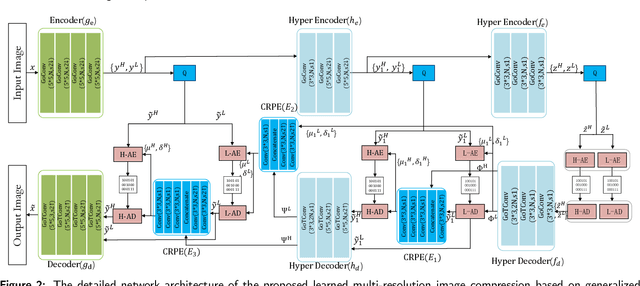
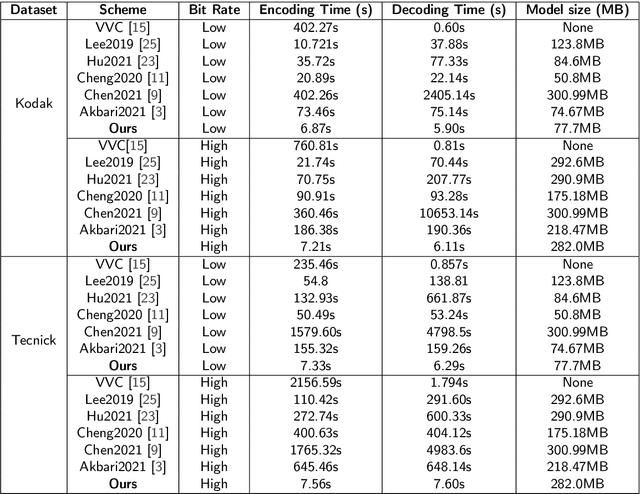
The application of the context-adaptive entropy model significantly improves the rate-distortion (R-D) performance, in which hyperpriors and autoregressive models are jointly utilized to effectively capture the spatial redundancy of the latent representations. However, the latent representations still contain some spatial correlations. In addition, these methods based on the context-adaptive entropy model cannot be accelerated in the decoding process by parallel computing devices, e.g. FPGA or GPU. To alleviate these limitations, we propose a learned multi-resolution image compression framework, which exploits the recently developed octave convolutions to factorize the latent representations into the high-resolution (HR) and low-resolution (LR) parts, similar to wavelet transform, which further improves the R-D performance. To speed up the decoding, our scheme does not use context-adaptive entropy model. Instead, we exploit an additional hyper layer including hyper encoder and hyper decoder to further remove the spatial redundancy of the latent representation. Moreover, the cross-resolution parameter estimation (CRPE) is introduced into the proposed framework to enhance the flow of information and further improve the rate-distortion performance. An additional information-fidelity loss is proposed to the total loss function to adjust the contribution of the LR part to the final bit stream. Experimental results show that our method separately reduces the decoding time by approximately 73.35 % and 93.44 % compared with that of state-of-the-art learned image compression methods, and the R-D performance is still better than H.266/VVC(4:2:0) and some learning-based methods on both PSNR and MS-SSIM metrics across a wide bit rates.
TRUST: An Accurate and End-to-End Table structure Recognizer Using Splitting-based Transformers
Aug 31, 2022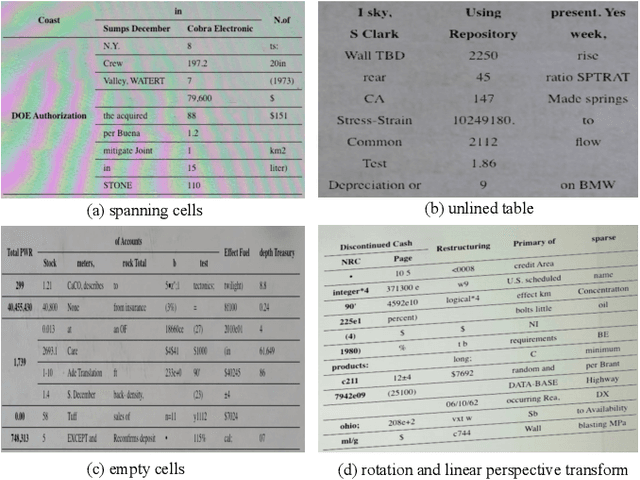
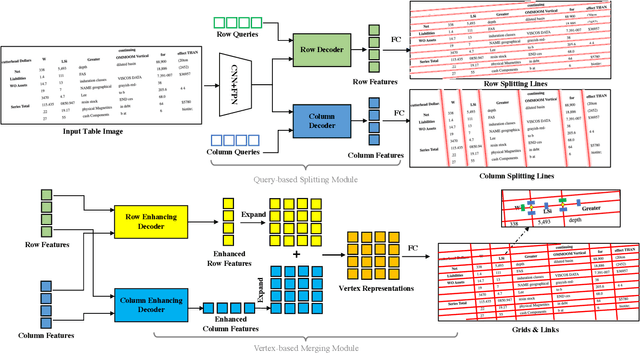
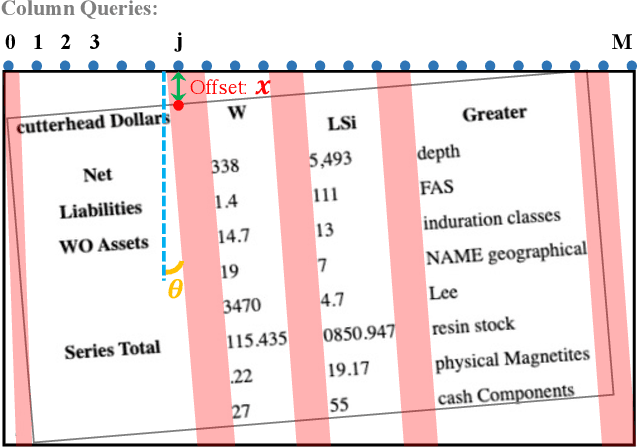
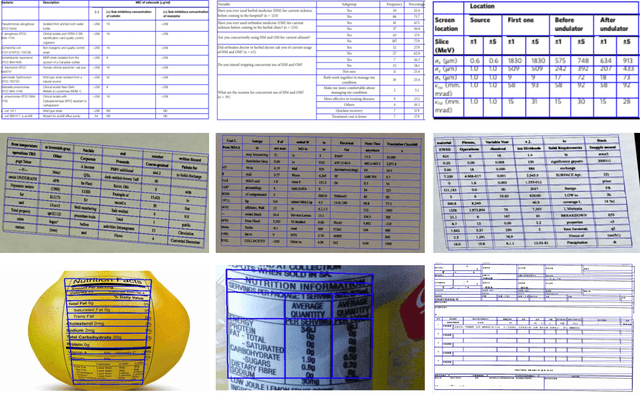
Table structure recognition is a crucial part of document image analysis domain. Its difficulty lies in the need to parse the physical coordinates and logical indices of each cell at the same time. However, the existing methods are difficult to achieve both these goals, especially when the table splitting lines are blurred or tilted. In this paper, we propose an accurate and end-to-end transformer-based table structure recognition method, referred to as TRUST. Transformers are suitable for table structure recognition because of their global computations, perfect memory, and parallel computation. By introducing novel Transformer-based Query-based Splitting Module and Vertex-based Merging Module, the table structure recognition problem is decoupled into two joint optimization sub-tasks: multi-oriented table row/column splitting and table grid merging. The Query-based Splitting Module learns strong context information from long dependencies via Transformer networks, accurately predicts the multi-oriented table row/column separators, and obtains the basic grids of the table accordingly. The Vertex-based Merging Module is capable of aggregating local contextual information between adjacent basic grids, providing the ability to merge basic girds that belong to the same spanning cell accurately. We conduct experiments on several popular benchmarks including PubTabNet and SynthTable, our method achieves new state-of-the-art results. In particular, TRUST runs at 10 FPS on PubTabNet, surpassing the previous methods by a large margin.
M2IOSR: Maximal Mutual Information Open Set Recognition
Aug 06, 2021
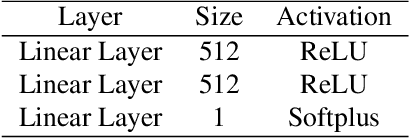
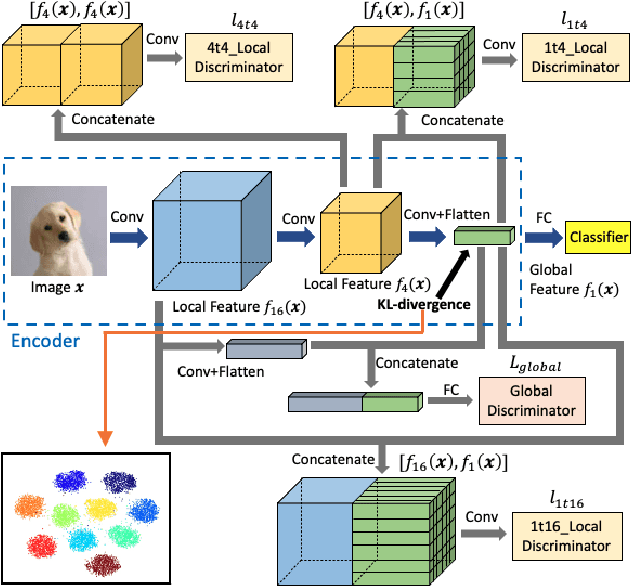
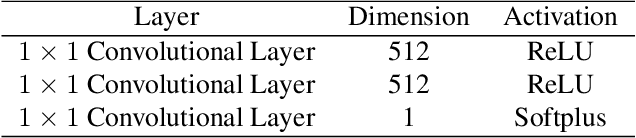
In this work, we aim to address the challenging task of open set recognition (OSR). Many recent OSR methods rely on auto-encoders to extract class-specific features by a reconstruction strategy, requiring the network to restore the input image on pixel-level. This strategy is commonly over-demanding for OSR since class-specific features are generally contained in target objects, not in all pixels. To address this shortcoming, here we discard the pixel-level reconstruction strategy and pay more attention to improving the effectiveness of class-specific feature extraction. We propose a mutual information-based method with a streamlined architecture, Maximal Mutual Information Open Set Recognition (M2IOSR). The proposed M2IOSR only uses an encoder to extract class-specific features by maximizing the mutual information between the given input and its latent features across multiple scales. Meanwhile, to further reduce the open space risk, latent features are constrained to class conditional Gaussian distributions by a KL-divergence loss function. In this way, a strong function is learned to prevent the network from mapping different observations to similar latent features and help the network extract class-specific features with desired statistical characteristics. The proposed method significantly improves the performance of baselines and achieves new state-of-the-art results on several benchmarks consistently.