 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Gender Stereotyping Impact in Facial Expression Recognition
Oct 11, 2022
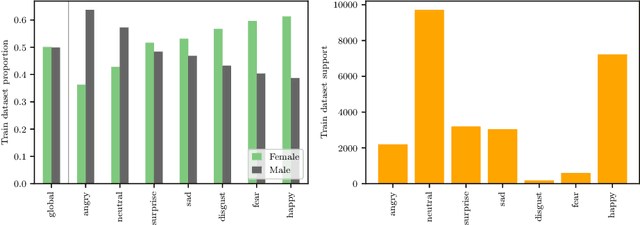
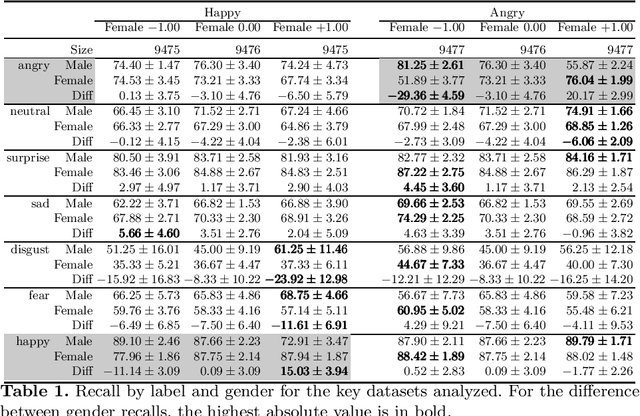
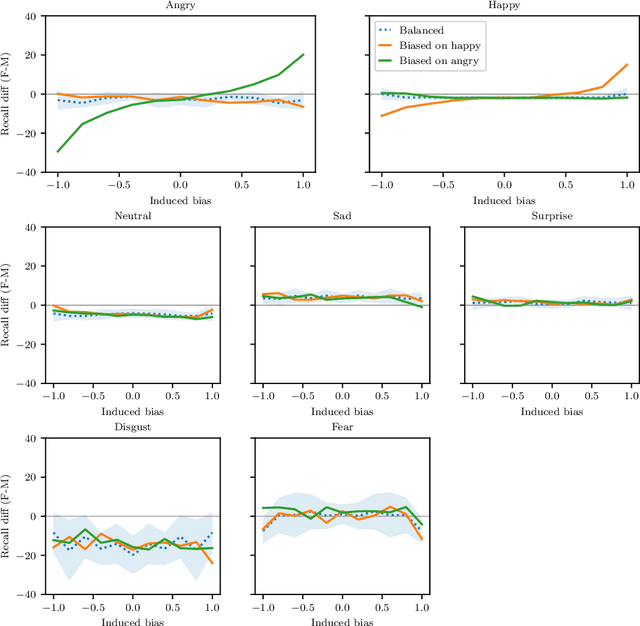
Facial Expression Recognition (FER) uses images of faces to identify the emotional state of users, allowing for a closer interaction between humans and autonomous systems. Unfortunately, as the images naturally integrate some demographic information, such as apparent age, gender, and race of the subject, these systems are prone to demographic bias issues. In recent years, machine learning-based models have become the most popular approach to FER. These models require training on large datasets of facial expression images, and their generalization capabilities are strongly related to the characteristics of the dataset. In publicly available FER datasets, apparent gender representation is usually mostly balanced, but their representation in the individual label is not, embedding social stereotypes into the datasets and generating a potential for harm. Although this type of bias has been overlooked so far, it is important to understand the impact it may have in the context of FER. To do so, we use a popular FER dataset, FER+, to generate derivative datasets with different amounts of stereotypical bias by altering the gender proportions of certain labels. We then proceed to measure the discrepancy between the performance of the models trained on these datasets for the apparent gender groups. We observe a discrepancy in the recognition of certain emotions between genders of up to $29 \%$ under the worst bias conditions. Our results also suggest a safety range for stereotypical bias in a dataset that does not appear to produce stereotypical bias in the resulting model. Our findings support the need for a thorough bias analysis of public datasets in problems like FER, where a global balance of demographic representation can still hide other types of bias that harm certain demographic groups.
Edge-oriented Implicit Neural Representation with Channel Tuning
Sep 22, 2022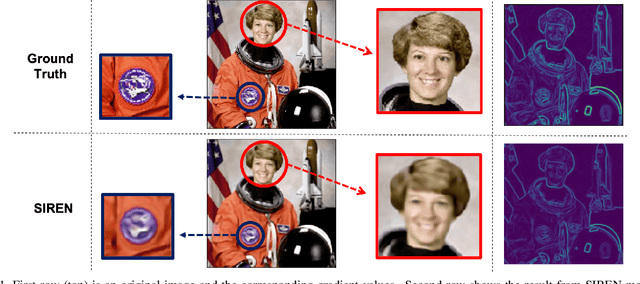

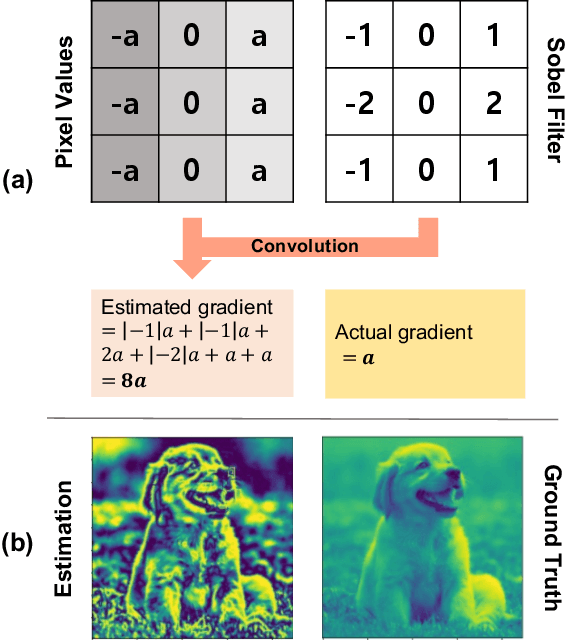
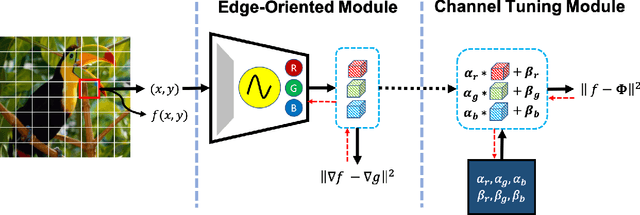
Implicit neural representation, which expresses an image as a continuous function rather than a discrete grid form, is widely used for image processing. Despite its outperforming results, there are still remaining limitations on restoring clear shapes of a given signal such as the edges of an image. In this paper, we propose Gradient Magnitude Adjustment algorithm which calculates the gradient of an image for training the implicit representation. In addition, we propose Edge-oriented Representation Network (EoREN) that can reconstruct the image with clear edges by fitting gradient information (Edge-oriented module). Furthermore, we add Channel-tuning module to adjust the distribution of given signals so that it solves a chronic problem of fitting gradients. By separating backpropagation paths of the two modules, EoREN can learn true color of the image without hindering the role for gradients. We qualitatively show that our model can reconstruct complex signals and demonstrate general reconstruction ability of our model with quantitative results.
Realistic PointGoal Navigation via Auxiliary Losses and Information Bottleneck
Sep 17, 2021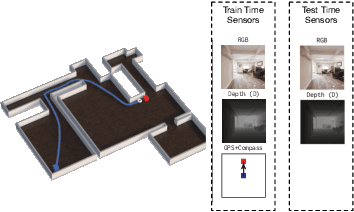
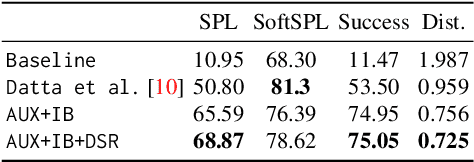
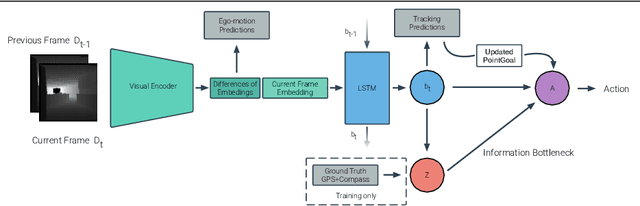
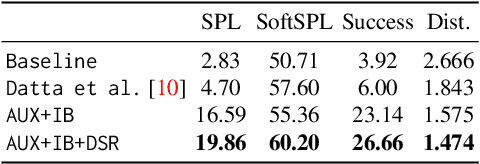
We propose a novel architecture and training paradigm for training realistic PointGoal Navigation -- navigating to a target coordinate in an unseen environment under actuation and sensor noise without access to ground-truth localization. Specifically, we find that the primary challenge under this setting is learning localization -- when stripped of idealized localization, agents fail to stop precisely at the goal despite reliably making progress towards it. To address this we introduce a set of auxiliary losses to help the agent learn localization. Further, we explore the idea of treating the precise location of the agent as privileged information -- it is unavailable during test time, however, it is available during training time in simulation. We grant the agent restricted access to ground-truth localization readings during training via an information bottleneck. Under this setting, the agent incurs a penalty for using this privileged information, encouraging the agent to only leverage this information when it is crucial to learning. This enables the agent to first learn navigation and then learn localization instead of conflating these two objectives in training. We evaluate our proposed method both in a semi-idealized (noiseless simulation without Compass+GPS) and realistic (addition of noisy simulation) settings. Specifically, our method outperforms existing baselines on the semi-idealized setting by 18\%/21\% SPL/Success and by 15\%/20\% SPL in the realistic setting. Our improved Success and SPL metrics indicate our agent's improved ability to accurately self-localize while maintaining a strong navigation policy. Our implementation can be found at https://github.com/NicoGrande/habitat-pointnav-via-ib.
Enhancing Data-Driven Reachability Analysis using Temporal Logic Side Information
Sep 15, 2021
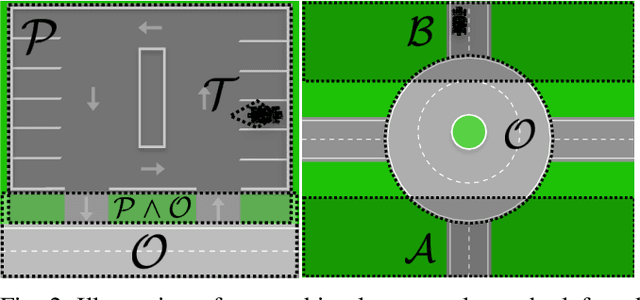
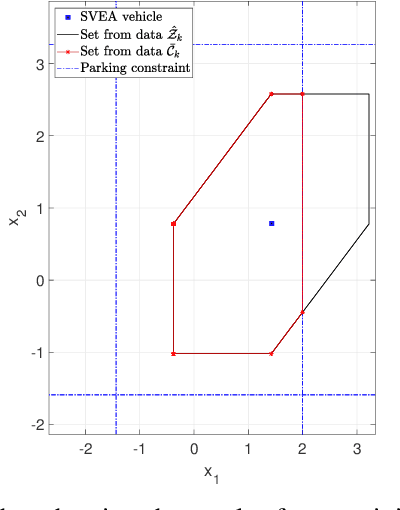
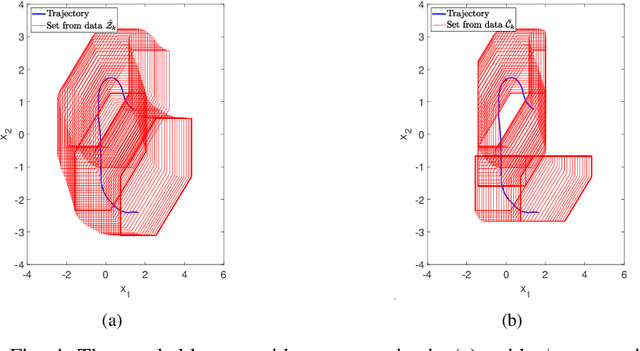
This paper presents algorithms for performing data-driven reachability analysis under temporal logic side information. In certain scenarios, the data-driven reachable sets of a robot can be prohibitively conservative due to the inherent noise in the robot's historical measurement data. In the same scenarios, we often have side information about the robot's expected motion (e.g., limits on how much a robot can move in a one-time step) that could be useful for further specifying the reachability analysis. In this work, we show that if we can model this side information using a signal temporal logic (STL) fragment, we can constrain the data-driven reachability analysis and safely limit the conservatism of the computed reachable sets. Moreover, we provide formal guarantees that, even after incorporating side information, the computed reachable sets still properly over-approximate the robot's future states. Lastly, we empirically validate the practicality of the over-approximation by computing constrained, data-driven reachable sets for the Small-Vehicles-for-Autonomy (SVEA) hardware platform in two driving scenarios.
Scenario-Adaptive and Self-Supervised Model for Multi-Scenario Personalized Recommendation
Aug 24, 2022
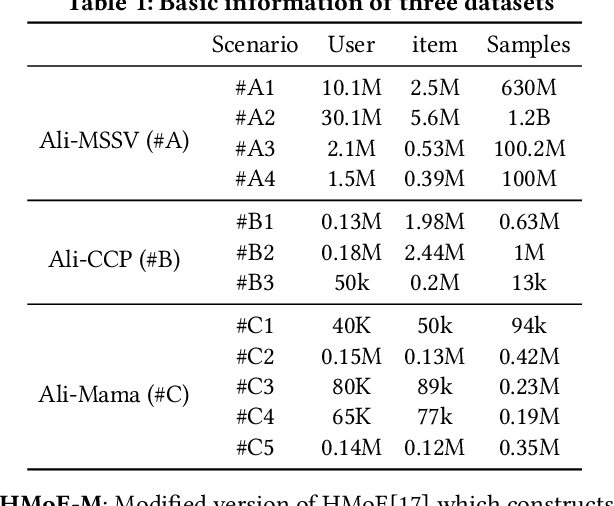

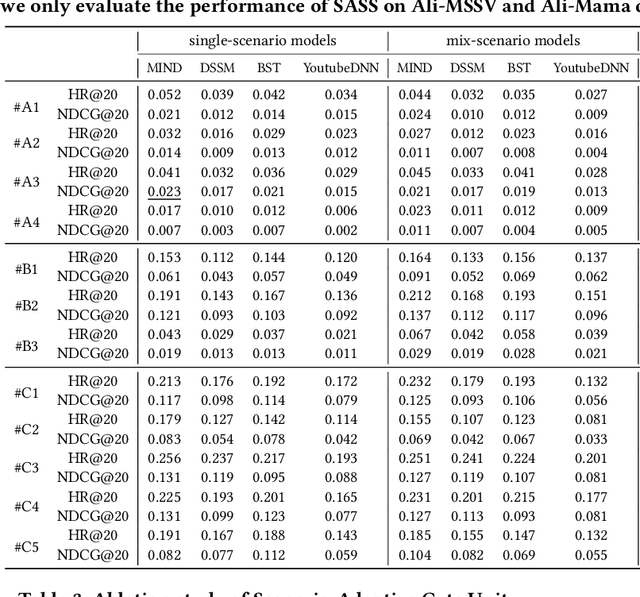
Multi-scenario recommendation is dedicated to retrieve relevant items for users in multiple scenarios, which is ubiquitous in industrial recommendation systems. These scenarios enjoy portions of overlaps in users and items, while the distribution of different scenarios is different. The key point of multi-scenario modeling is to efficiently maximize the use of whole-scenario information and granularly generate adaptive representations both for users and items among multiple scenarios. we summarize three practical challenges which are not well solved for multi-scenario modeling: (1) Lacking of fine-grained and decoupled information transfer controls among multiple scenarios. (2) Insufficient exploitation of entire space samples. (3) Item's multi-scenario representation disentanglement problem. In this paper, we propose a Scenario-Adaptive and Self-Supervised (SASS) model to solve the three challenges mentioned above. Specifically, we design a Multi-Layer Scenario Adaptive Transfer (ML-SAT) module with scenario-adaptive gate units to select and fuse effective transfer information from whole scenario to individual scenario in a quite fine-grained and decoupled way. To sufficiently exploit the power of entire space samples, a two-stage training process including pre-training and fine-tune is introduced. The pre-training stage is based on a scenario-supervised contrastive learning task with the training samples drawn from labeled and unlabeled data spaces. The model is created symmetrically both in user side and item side, so that we can get distinguishing representations of items in different scenarios. Extensive experimental results on public and industrial datasets demonstrate the superiority of the SASS model over state-of-the-art methods. This model also achieves more than 8.0% improvement on Average Watching Time Per User in online A/B tests.
V2XP-ASG: Generating Adversarial Scenes for Vehicle-to-Everything Perception
Sep 27, 2022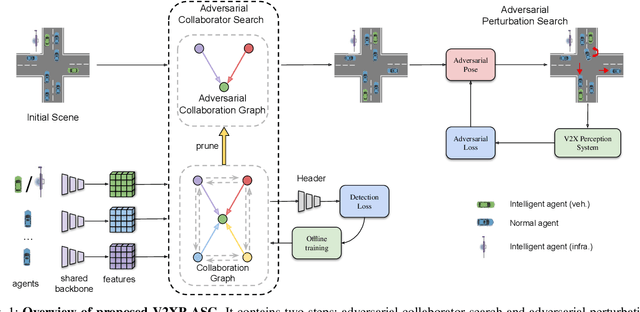
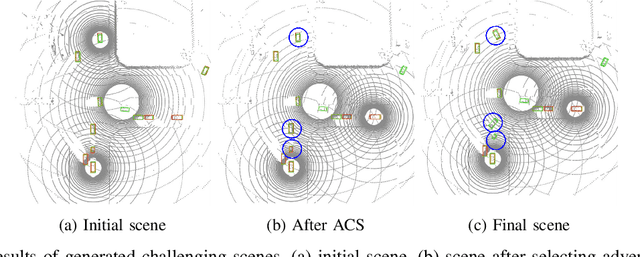
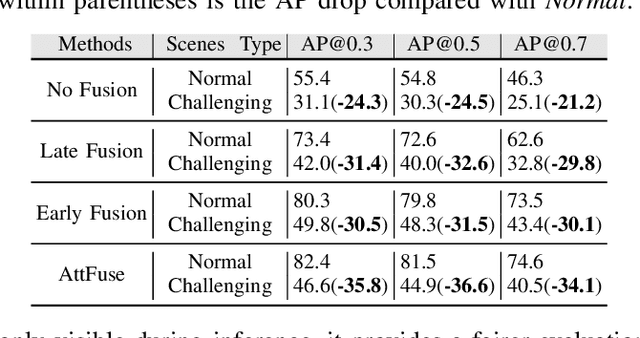

Recent advancements in Vehicle-to-Everything communication technology have enabled autonomous vehicles to share sensory information to obtain better perception performance. With the rapid growth of autonomous vehicles and intelligent infrastructure, the V2X perception systems will soon be deployed at scale, which raises a safety-critical question: how can we evaluate and improve its performance under challenging traffic scenarios before the real-world deployment? Collecting diverse large-scale real-world test scenes seems to be the most straightforward solution, but it is expensive and time-consuming, and the collections can only cover limited scenarios. To this end, we propose the first open adversarial scene generator V2XP-ASG that can produce realistic, challenging scenes for modern LiDAR-based multi-agent perception system. V2XP-ASG learns to construct an adversarial collaboration graph and simultaneously perturb multiple agents' poses in an adversarial and plausible manner. The experiments demonstrate that V2XP-ASG can effectively identify challenging scenes for a large range of V2X perception systems. Meanwhile, by training on the limited number of generated challenging scenes, the accuracy of V2X perception systems can be further improved by 12.3% on challenging and 4% on normal scenes.
Disentangled Unsupervised Image Translation via Restricted Information Flow
Nov 26, 2021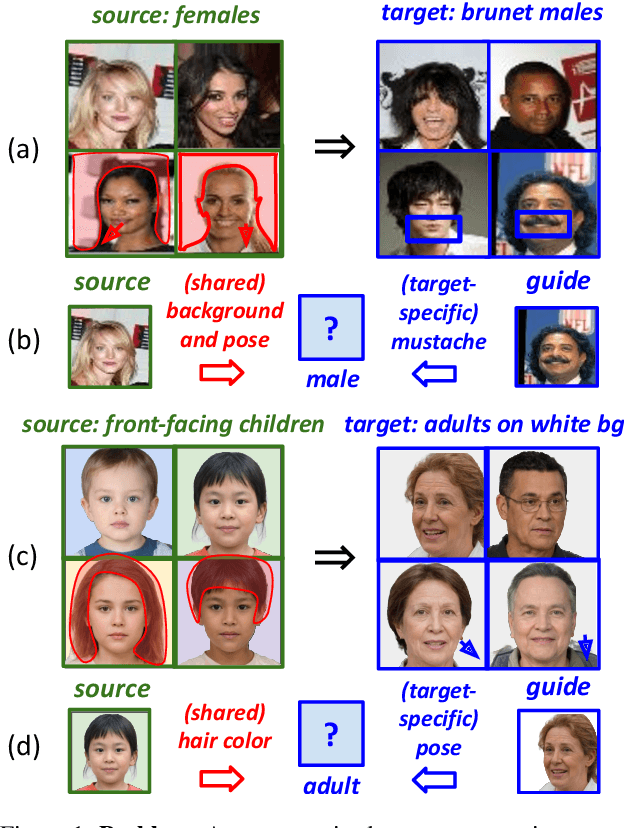
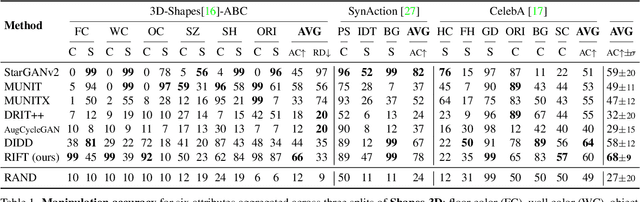
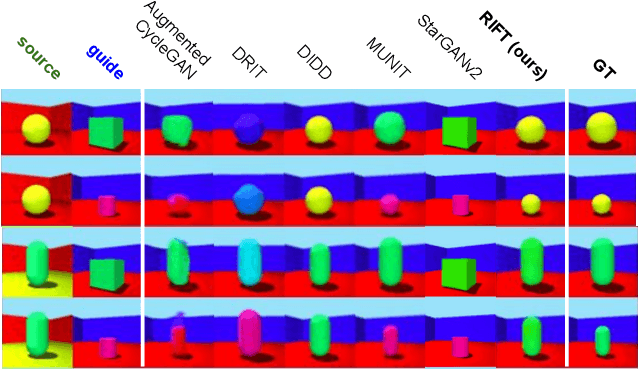
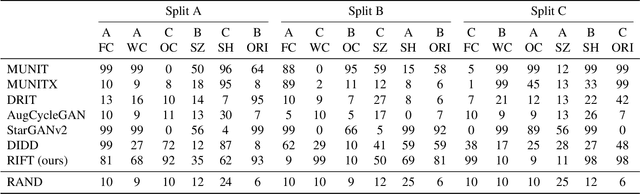
Unsupervised image-to-image translation methods aim to map images from one domain into plausible examples from another domain while preserving structures shared across two domains. In the many-to-many setting, an additional guidance example from the target domain is used to determine domain-specific attributes of the generated image. In the absence of attribute annotations, methods have to infer which factors are specific to each domain from data during training. Many state-of-art methods hard-code the desired shared-vs-specific split into their architecture, severely restricting the scope of the problem. In this paper, we propose a new method that does not rely on such inductive architectural biases, and infers which attributes are domain-specific from data by constraining information flow through the network using translation honesty losses and a penalty on the capacity of domain-specific embedding. We show that the proposed method achieves consistently high manipulation accuracy across two synthetic and one natural dataset spanning a wide variety of domain-specific and shared attributes.
NashAE: Disentangling Representations through Adversarial Covariance Minimization
Sep 21, 2022We present a self-supervised method to disentangle factors of variation in high-dimensional data that does not rely on prior knowledge of the underlying variation profile (e.g., no assumptions on the number or distribution of the individual latent variables to be extracted). In this method which we call NashAE, high-dimensional feature disentanglement is accomplished in the low-dimensional latent space of a standard autoencoder (AE) by promoting the discrepancy between each encoding element and information of the element recovered from all other encoding elements. Disentanglement is promoted efficiently by framing this as a minmax game between the AE and an ensemble of regression networks which each provide an estimate of an element conditioned on an observation of all other elements. We quantitatively compare our approach with leading disentanglement methods using existing disentanglement metrics. Furthermore, we show that NashAE has increased reliability and increased capacity to capture salient data characteristics in the learned latent representation.
Improved Abdominal Multi-Organ Segmentation via 3D Boundary-Constrained Deep Neural Networks
Oct 09, 2022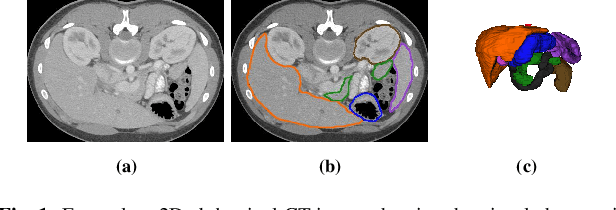
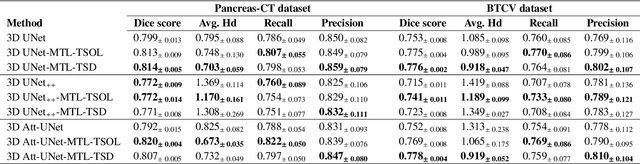
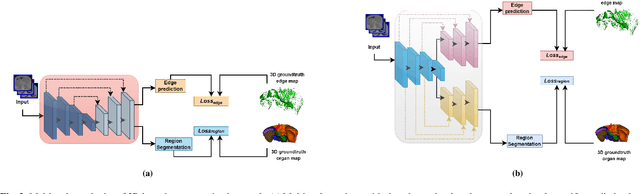
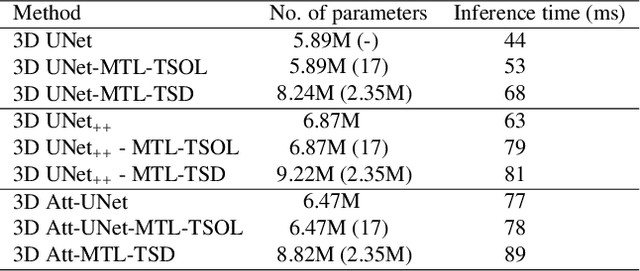
Quantitative assessment of the abdominal region from clinically acquired CT scans requires the simultaneous segmentation of abdominal organs. Thanks to the availability of high-performance computational resources, deep learning-based methods have resulted in state-of-the-art performance for the segmentation of 3D abdominal CT scans. However, the complex characterization of organs with fuzzy boundaries prevents the deep learning methods from accurately segmenting these anatomical organs. Specifically, the voxels on the boundary of organs are more vulnerable to misprediction due to the highly-varying intensity of inter-organ boundaries. This paper investigates the possibility of improving the abdominal image segmentation performance of the existing 3D encoder-decoder networks by leveraging organ-boundary prediction as a complementary task. To address the problem of abdominal multi-organ segmentation, we train the 3D encoder-decoder network to simultaneously segment the abdominal organs and their corresponding boundaries in CT scans via multi-task learning. The network is trained end-to-end using a loss function that combines two task-specific losses, i.e., complete organ segmentation loss and boundary prediction loss. We explore two different network topologies based on the extent of weights shared between the two tasks within a unified multi-task framework. To evaluate the utilization of complementary boundary prediction task in improving the abdominal multi-organ segmentation, we use three state-of-the-art encoder-decoder networks: 3D UNet, 3D UNet++, and 3D Attention-UNet. The effectiveness of utilizing the organs' boundary information for abdominal multi-organ segmentation is evaluated on two publically available abdominal CT datasets. A maximum relative improvement of 3.5% and 3.6% is observed in Mean Dice Score for Pancreas-CT and BTCV datasets, respectively.
Private and Efficient Meta-Learning with Low Rank and Sparse Decomposition
Oct 07, 2022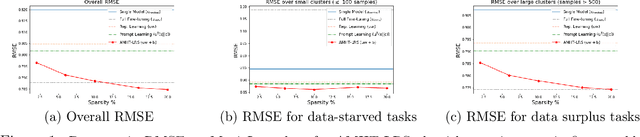
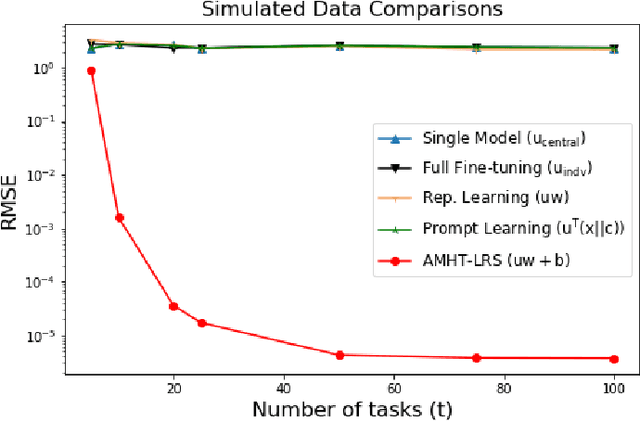
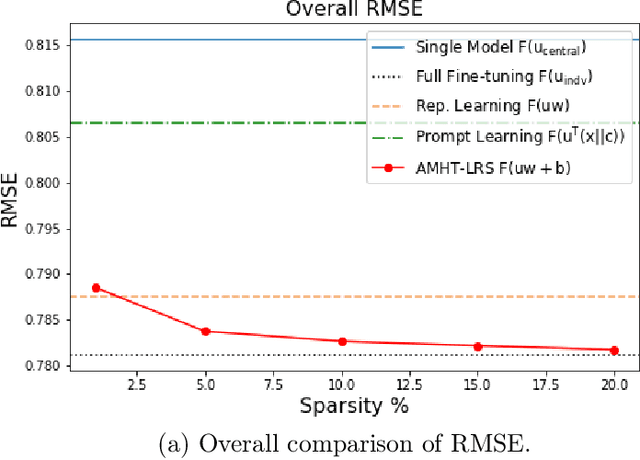
Meta-learning is critical for a variety of practical ML systems -- like personalized recommendations systems -- that are required to generalize to new tasks despite a small number of task-specific training points. Existing meta-learning techniques use two complementary approaches of either learning a low-dimensional representation of points for all tasks, or task-specific fine-tuning of a global model trained using all the tasks. In this work, we propose a novel meta-learning framework that combines both the techniques to enable handling of a large number of data-starved tasks. Our framework models network weights as a sum of low-rank and sparse matrices. This allows us to capture information from multiple domains together in the low-rank part while still allowing task specific personalization using the sparse part. We instantiate and study the framework in the linear setting, where the problem reduces to that of estimating the sum of a rank-$r$ and a $k$-column sparse matrix using a small number of linear measurements. We propose an alternating minimization method with hard thresholding -- AMHT-LRS -- to learn the low-rank and sparse part effectively and efficiently. For the realizable, Gaussian data setting, we show that AMHT-LRS indeed solves the problem efficiently with nearly optimal samples. We extend AMHT-LRS to ensure that it preserves privacy of each individual user in the dataset, while still ensuring strong generalization with nearly optimal number of samples. Finally, on multiple datasets, we demonstrate that the framework allows personalized models to obtain superior performance in the data-scarce regime.