 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Lock-in: Diversifying Text-to-Image Generation via Representation Modulation
Jun 05, 2026Recent text-to-image models built on large-scale Transformer backbones and flow-based objectives deliver strong text-image alignment and high visual quality, yet often produce overly similar samples under a fixed prompt. Existing diversity-enhancement methods alleviate this issue, but typically require expensive sampling or auxiliary optimization, incurring non-trivial overhead. To investigate the root cause of this homogeneity, we examine intermediate Transformer features and observe that the zero-frequency spatial average (DC) component rapidly converges across seeds early in generation, causing early trajectory lock-in that limits downstream variation. Building on this observation, we propose DC Attenuation for diVersity Enhancement (DAVE), a training-free representation-level intervention that selectively attenuates this component in the early regime. DAVE preserves the sampling pipeline with negligible overhead, improving prompt-consistent diversity while maintaining competitive image quality.
Enhancing Creative Generation on Stable Diffusion-based Models
Mar 30, 2025Recent text-to-image generative models, particularly Stable Diffusion and its distilled variants, have achieved impressive fidelity and strong text-image alignment. However, their creative capability remains constrained, as including `creative' in prompts seldom yields the desired results. This paper introduces C3 (Creative Concept Catalyst), a training-free approach designed to enhance creativity in Stable Diffusion-based models. C3 selectively amplifies features during the denoising process to foster more creative outputs. We offer practical guidelines for choosing amplification factors based on two main aspects of creativity. C3 is the first study to enhance creativity in diffusion models without extensive computational costs. We demonstrate its effectiveness across various Stable Diffusion-based models.
Understanding Distributed Representations of Concepts in Deep Neural Networks without Supervision
Dec 28, 2023



Understanding intermediate representations of the concepts learned by deep learning classifiers is indispensable for interpreting general model behaviors. Existing approaches to reveal learned concepts often rely on human supervision, such as pre-defined concept sets or segmentation processes. In this paper, we propose a novel unsupervised method for discovering distributed representations of concepts by selecting a principal subset of neurons. Our empirical findings demonstrate that instances with similar neuron activation states tend to share coherent concepts. Based on the observations, the proposed method selects principal neurons that construct an interpretable region, namely a Relaxed Decision Region (RDR), encompassing instances with coherent concepts in the feature space. It can be utilized to identify unlabeled subclasses within data and to detect the causes of misclassifications. Furthermore, the applicability of our method across various layers discloses distinct distributed representations over the layers, which provides deeper insights into the internal mechanisms of the deep learning model.
Edge-oriented Implicit Neural Representation with Channel Tuning
Sep 22, 2022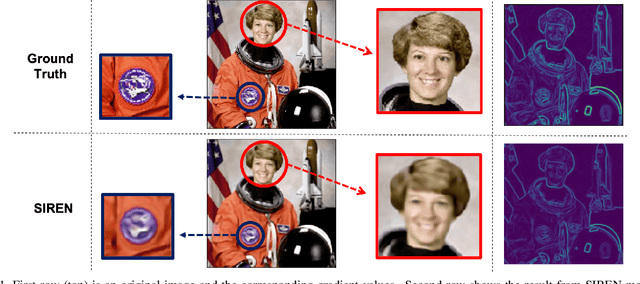

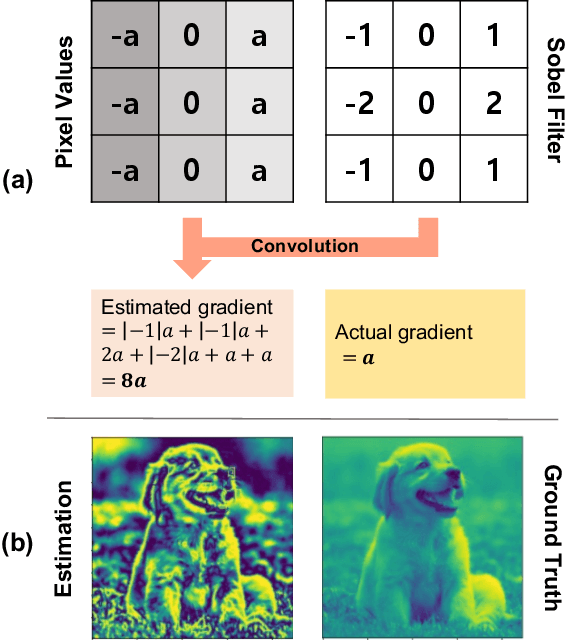
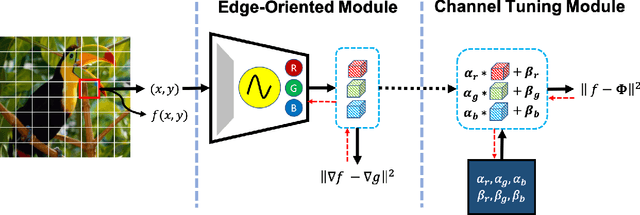
Implicit neural representation, which expresses an image as a continuous function rather than a discrete grid form, is widely used for image processing. Despite its outperforming results, there are still remaining limitations on restoring clear shapes of a given signal such as the edges of an image. In this paper, we propose Gradient Magnitude Adjustment algorithm which calculates the gradient of an image for training the implicit representation. In addition, we propose Edge-oriented Representation Network (EoREN) that can reconstruct the image with clear edges by fitting gradient information (Edge-oriented module). Furthermore, we add Channel-tuning module to adjust the distribution of given signals so that it solves a chronic problem of fitting gradients. By separating backpropagation paths of the two modules, EoREN can learn true color of the image without hindering the role for gradients. We qualitatively show that our model can reconstruct complex signals and demonstrate general reconstruction ability of our model with quantitative results.