 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Invariant Representations of Graph Neural Networks via Cluster Generalization
Mar 06, 2024
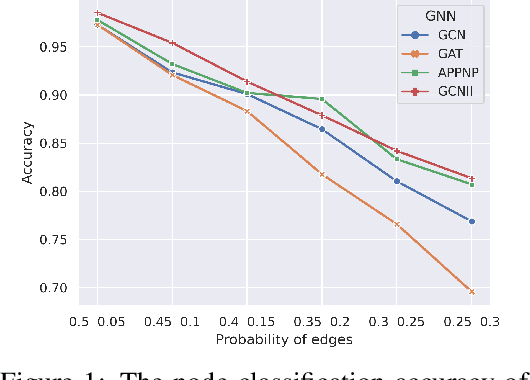
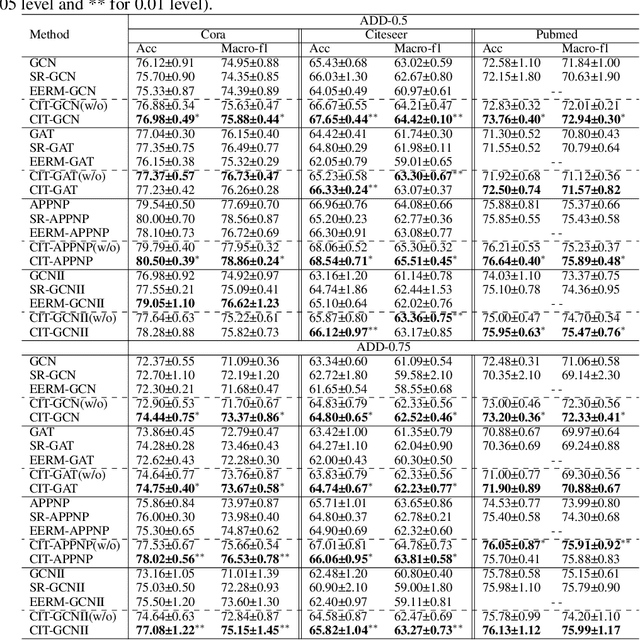
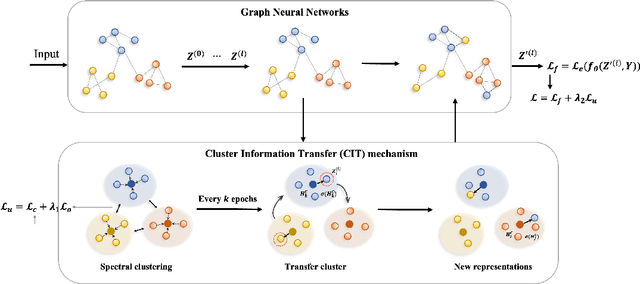
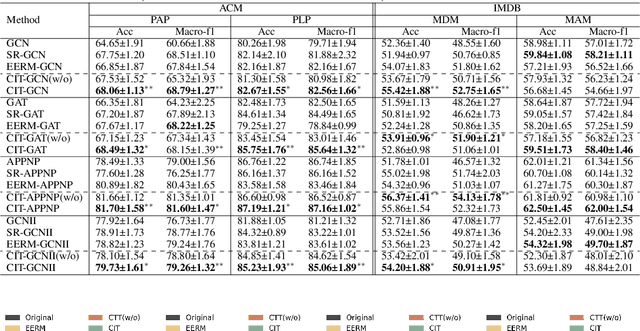
Graph neural networks (GNNs) have become increasingly popular in modeling graph-structured data due to their ability to learn node representations by aggregating local structure information. However, it is widely acknowledged that the test graph structure may differ from the training graph structure, resulting in a structure shift. In this paper, we experimentally find that the performance of GNNs drops significantly when the structure shift happens, suggesting that the learned models may be biased towards specific structure patterns. To address this challenge, we propose the Cluster Information Transfer (CIT) mechanism (Code available at https://github.com/BUPT-GAMMA/CITGNN), which can learn invariant representations for GNNs, thereby improving their generalization ability to various and unknown test graphs with structure shift. The CIT mechanism achieves this by combining different cluster information with the nodes while preserving their cluster-independent information. By generating nodes across different clusters, the mechanism significantly enhances the diversity of the nodes and helps GNNs learn the invariant representations. We provide a theoretical analysis of the CIT mechanism, showing that the impact of changing clusters during structure shift can be mitigated after transfer. Additionally, the proposed mechanism is a plug-in that can be easily used to improve existing GNNs. We comprehensively evaluate our proposed method on three typical structure shift scenarios, demonstrating its effectiveness in enhancing GNNs' performance.
Ensemble Quadratic Assignment Network for Graph Matching
Mar 11, 2024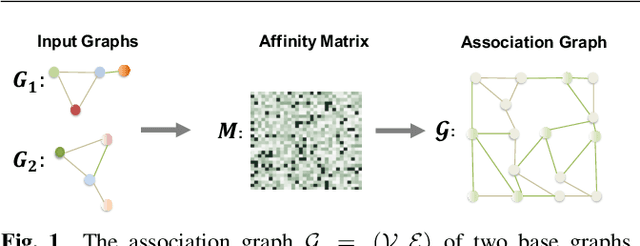

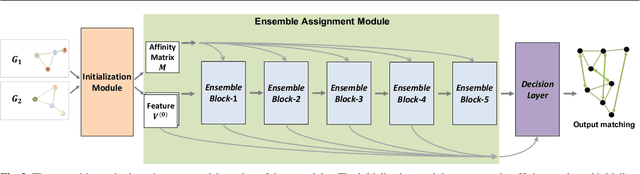
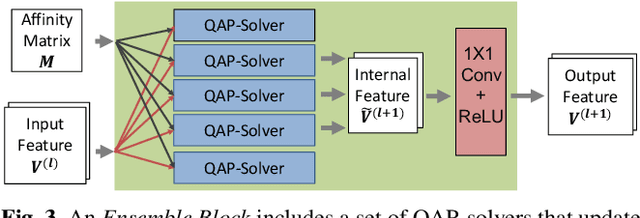
Graph matching is a commonly used technique in computer vision and pattern recognition. Recent data-driven approaches have improved the graph matching accuracy remarkably, whereas some traditional algorithm-based methods are more robust to feature noises, outlier nodes, and global transformation (e.g.~rotation). In this paper, we propose a graph neural network (GNN) based approach to combine the advantages of data-driven and traditional methods. In the GNN framework, we transform traditional graph-matching solvers as single-channel GNNs on the association graph and extend the single-channel architecture to the multi-channel network. The proposed model can be seen as an ensemble method that fuses multiple algorithms at every iteration. Instead of averaging the estimates at the end of the ensemble, in our approach, the independent iterations of the ensembled algorithms exchange their information after each iteration via a 1x1 channel-wise convolution layer. Experiments show that our model improves the performance of traditional algorithms significantly. In addition, we propose a random sampling strategy to reduce the computational complexity and GPU memory usage, so the model applies to matching graphs with thousands of nodes. We evaluate the performance of our method on three tasks: geometric graph matching, semantic feature matching, and few-shot 3D shape classification. The proposed model performs comparably or outperforms the best existing GNN-based methods.
Human-Exoskeleton Interaction Portrait
Mar 11, 2024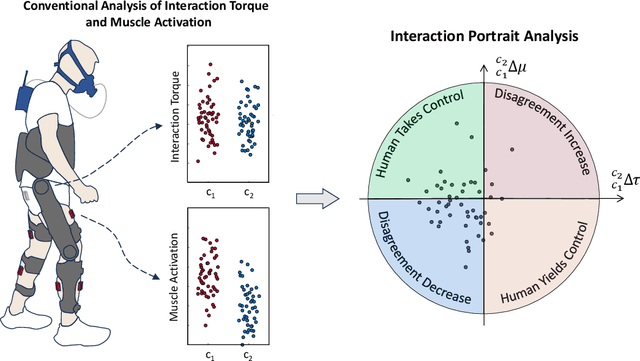
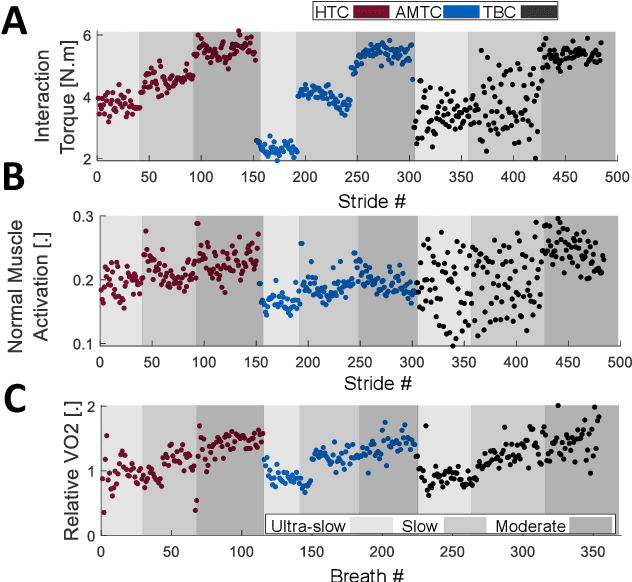
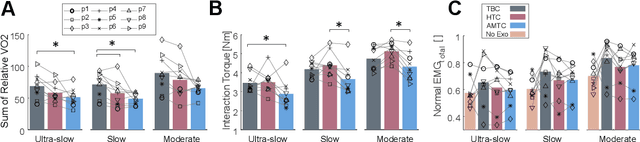
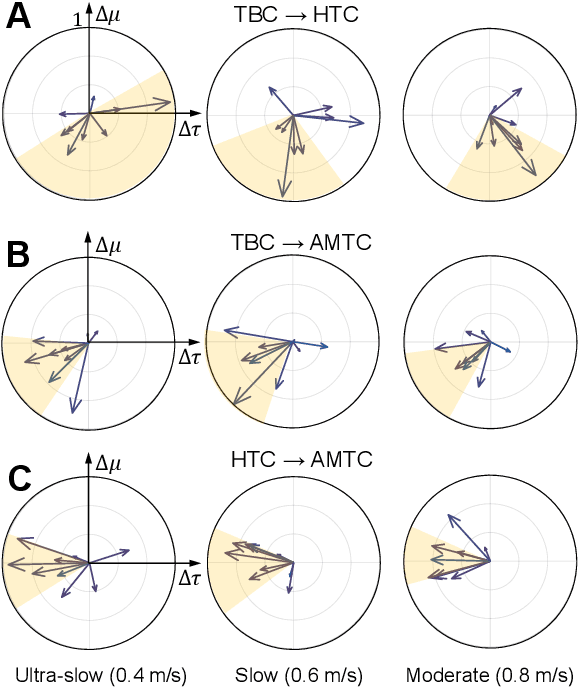
Human-robot physical interaction contains crucial information for optimizing user experience, enhancing robot performance, and objectively assessing user adaptation. This study introduces a new method to evaluate human-robot co-adaptation in lower limb exoskeletons by analyzing muscle activity and interaction torque as a two-dimensional random variable. We introduce the Interaction Portrait (IP), which visualizes this variable's distribution in polar coordinates. We applied this metric to compare a recent torque controller (HTC) based on kinematic state feedback and a novel feedforward controller (AMTC) with online learning, proposed herein, against a time-based controller (TBC) during treadmill walking at varying speeds. Compared to TBC, both HTC and AMTC significantly lower users' normalized oxygen uptake, suggesting enhanced user-exoskeleton coordination. IP analysis reveals this improvement stems from two distinct co-adaptation strategies, unidentifiable by traditional muscle activity or interaction torque analyses alone. HTC encourages users to yield control to the exoskeleton, decreasing muscular effort but increasing interaction torque, as the exoskeleton compensates for user dynamics. Conversely, AMTC promotes user engagement through increased muscular effort and reduced interaction torques, aligning it more closely with rehabilitation and gait training applications. IP phase evolution provides insight into each user's interaction strategy development, showcasing IP analysis's potential in comparing and designing novel controllers to optimize human-robot interaction in wearable robots.
FocusCLIP: Multimodal Subject-Level Guidance for Zero-Shot Transfer in Human-Centric Tasks
Mar 11, 2024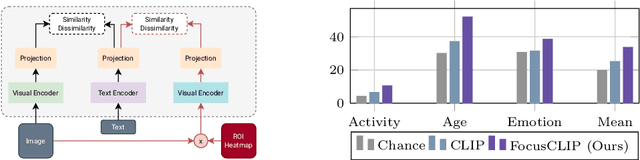
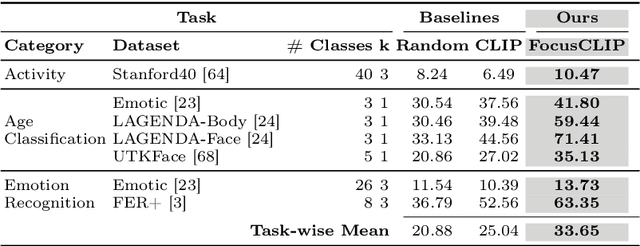
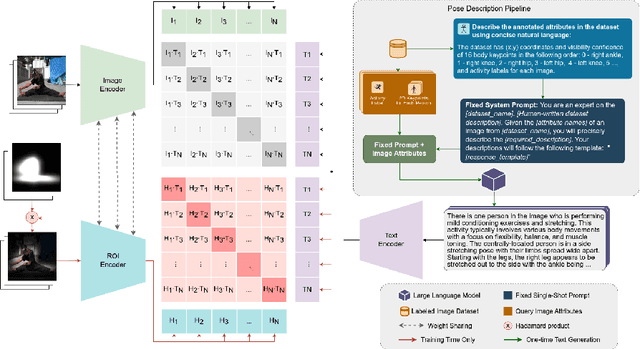
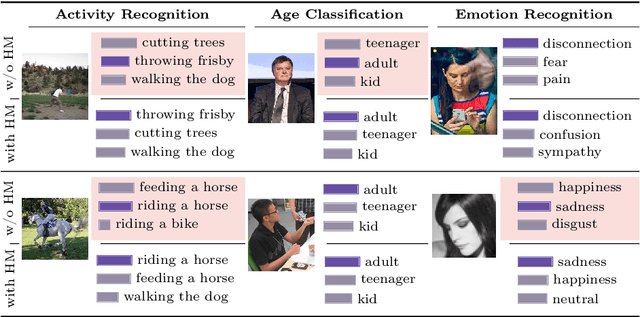
We propose FocusCLIP, integrating subject-level guidance--a specialized mechanism for target-specific supervision--into the CLIP framework for improved zero-shot transfer on human-centric tasks. Our novel contributions enhance CLIP on both the vision and text sides. On the vision side, we incorporate ROI heatmaps emulating human visual attention mechanisms to emphasize subject-relevant image regions. On the text side, we introduce human pose descriptions to provide rich contextual information. For human-centric tasks, FocusCLIP is trained with images from the MPII Human Pose dataset. The proposed approach surpassed CLIP by an average of 8.61% across five previously unseen datasets covering three human-centric tasks. FocusCLIP achieved an average accuracy of 33.65% compared to 25.04% by CLIP. We observed a 3.98% improvement in activity recognition, a 14.78% improvement in age classification, and a 7.06% improvement in emotion recognition. Moreover, using our proposed single-shot LLM prompting strategy, we release a high-quality MPII Pose Descriptions dataset to encourage further research in multimodal learning for human-centric tasks. Furthermore, we also demonstrate the effectiveness of our subject-level supervision on non-human-centric tasks. FocusCLIP shows a 2.47% improvement over CLIP in zero-shot bird classification using the CUB dataset. Our findings emphasize the potential of integrating subject-level guidance with general pretraining methods for enhanced downstream performance.
See Through Their Minds: Learning Transferable Neural Representation from Cross-Subject fMRI
Mar 11, 2024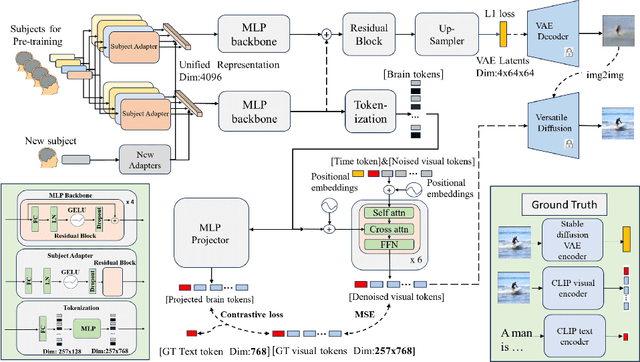
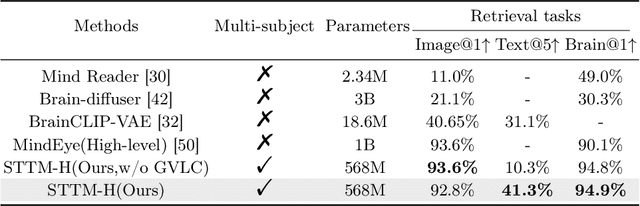

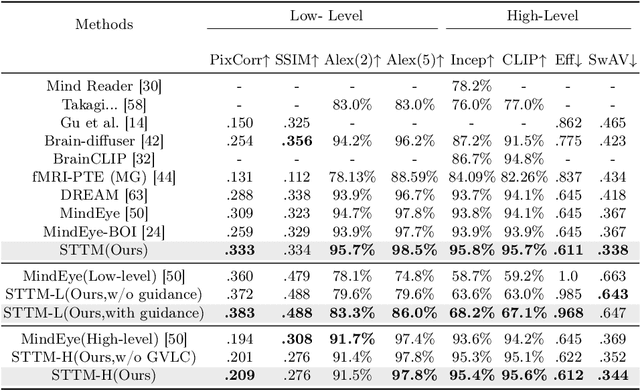
Deciphering visual content from functional Magnetic Resonance Imaging (fMRI) helps illuminate the human vision system. However, the scarcity of fMRI data and noise hamper brain decoding model performance. Previous approaches primarily employ subject-specific models, sensitive to training sample size. In this paper, we explore a straightforward but overlooked solution to address data scarcity. We propose shallow subject-specific adapters to map cross-subject fMRI data into unified representations. Subsequently, a shared deeper decoding model decodes cross-subject features into the target feature space. During training, we leverage both visual and textual supervision for multi-modal brain decoding. Our model integrates a high-level perception decoding pipeline and a pixel-wise reconstruction pipeline guided by high-level perceptions, simulating bottom-up and top-down processes in neuroscience. Empirical experiments demonstrate robust neural representation learning across subjects for both pipelines. Moreover, merging high-level and low-level information improves both low-level and high-level reconstruction metrics. Additionally, we successfully transfer learned general knowledge to new subjects by training new adapters with limited training data. Compared to previous state-of-the-art methods, notably pre-training-based methods (Mind-Vis and fMRI-PTE), our approach achieves comparable or superior results across diverse tasks, showing promise as an alternative method for cross-subject fMRI data pre-training. Our code and pre-trained weights will be publicly released at https://github.com/YulongBonjour/See_Through_Their_Minds.
Medical Image Synthesis via Fine-Grained Image-Text Alignment and Anatomy-Pathology Prompting
Mar 11, 2024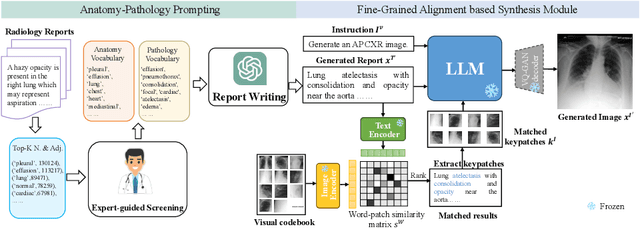
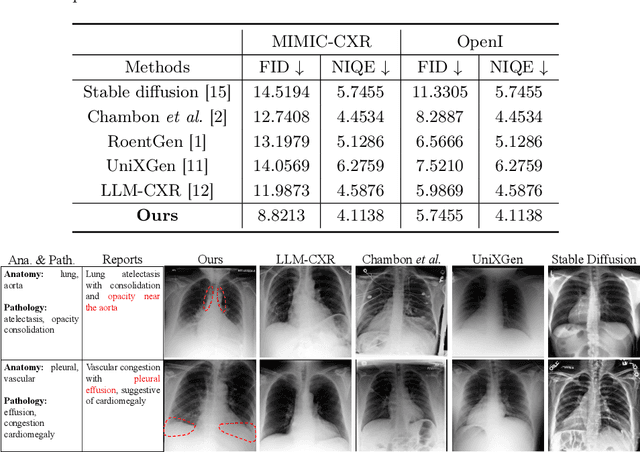
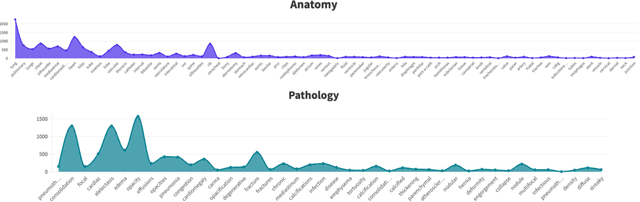

Data scarcity and privacy concerns limit the availability of high-quality medical images for public use, which can be mitigated through medical image synthesis. However, current medical image synthesis methods often struggle to accurately capture the complexity of detailed anatomical structures and pathological conditions. To address these challenges, we propose a novel medical image synthesis model that leverages fine-grained image-text alignment and anatomy-pathology prompts to generate highly detailed and accurate synthetic medical images. Our method integrates advanced natural language processing techniques with image generative modeling, enabling precise alignment between descriptive text prompts and the synthesized images' anatomical and pathological details. The proposed approach consists of two key components: an anatomy-pathology prompting module and a fine-grained alignment-based synthesis module. The anatomy-pathology prompting module automatically generates descriptive prompts for high-quality medical images. To further synthesize high-quality medical images from the generated prompts, the fine-grained alignment-based synthesis module pre-defines a visual codebook for the radiology dataset and performs fine-grained alignment between the codebook and generated prompts to obtain key patches as visual clues, facilitating accurate image synthesis. We validate the superiority of our method through experiments on public chest X-ray datasets and demonstrate that our synthetic images preserve accurate semantic information, making them valuable for various medical applications.
GPTSee: Enhancing Moment Retrieval and Highlight Detection via Description-Based Similarity Features
Mar 10, 2024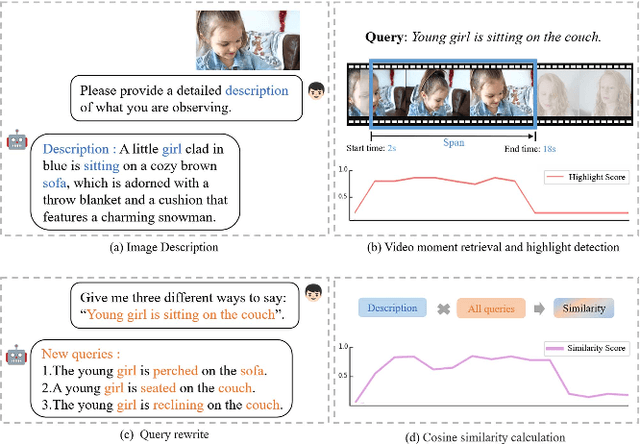
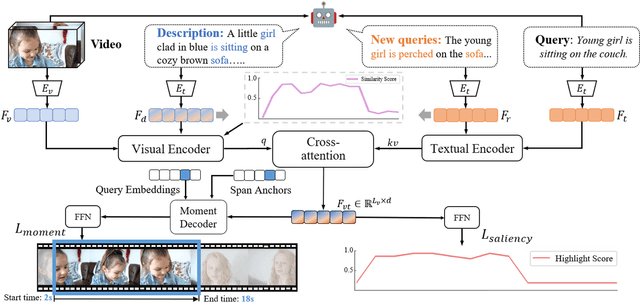
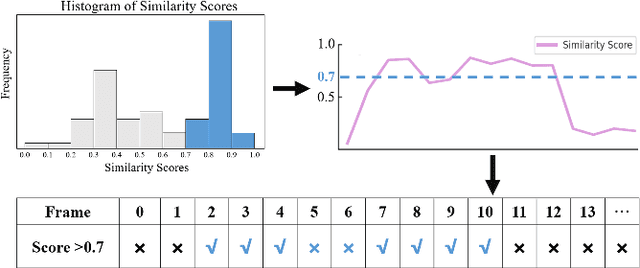
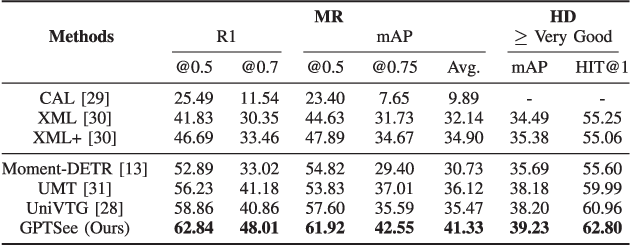
Moment retrieval (MR) and highlight detection (HD) aim to identify relevant moments and highlights in video from corresponding natural language query. Large language models (LLMs) have demonstrated proficiency in various computer vision tasks. However, existing methods for MR\&HD have not yet been integrated with LLMs. In this letter, we propose a novel two-stage model that takes the output of LLMs as the input to the second-stage transformer encoder-decoder. First, MiniGPT-4 is employed to generate the detailed description of the video frame and rewrite the query statement, fed into the encoder as new features. Then, semantic similarity is computed between the generated description and the rewritten queries. Finally, continuous high-similarity video frames are converted into span anchors, serving as prior position information for the decoder. Experiments demonstrate that our approach achieves a state-of-the-art result, and by using only span anchors and similarity scores as outputs, positioning accuracy outperforms traditional methods, like Moment-DETR.
Generalization of Graph Neural Networks through the Lens of Homomorphism
Mar 10, 2024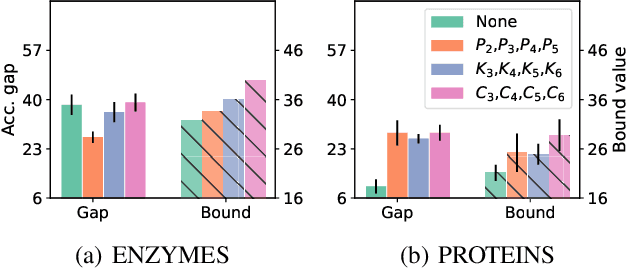
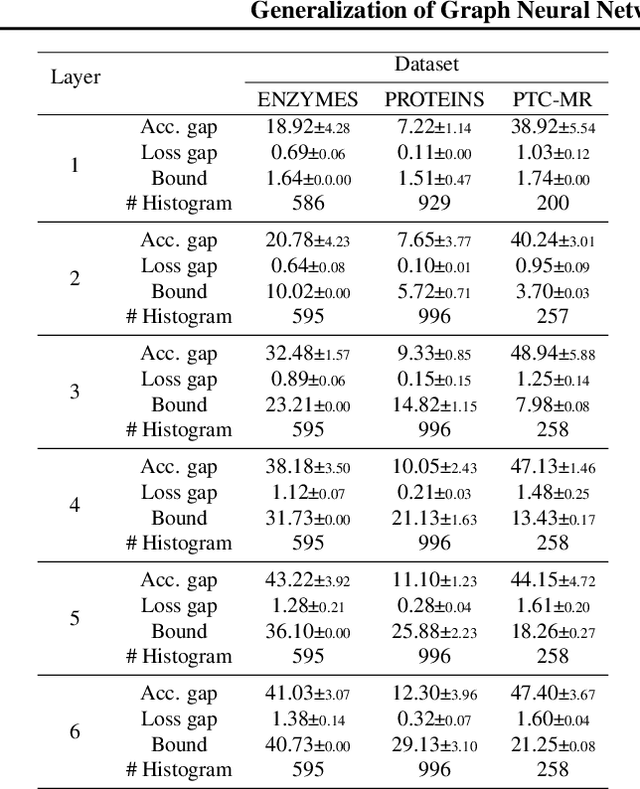
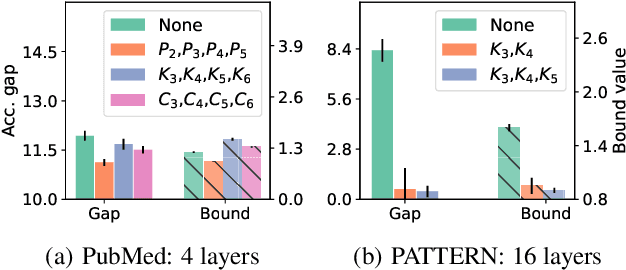
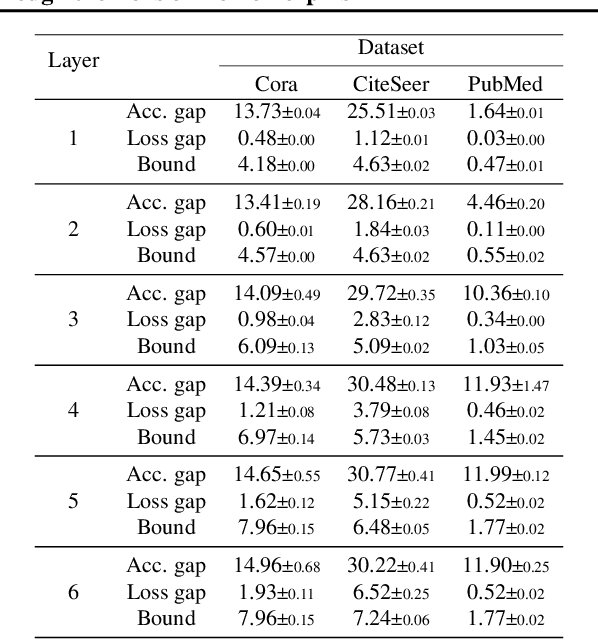
Despite the celebrated popularity of Graph Neural Networks (GNNs) across numerous applications, the ability of GNNs to generalize remains less explored. In this work, we propose to study the generalization of GNNs through a novel perspective - analyzing the entropy of graph homomorphism. By linking graph homomorphism with information-theoretic measures, we derive generalization bounds for both graph and node classifications. These bounds are capable of capturing subtleties inherent in various graph structures, including but not limited to paths, cycles and cliques. This enables a data-dependent generalization analysis with robust theoretical guarantees. To shed light on the generality of of our proposed bounds, we present a unifying framework that can characterize a broad spectrum of GNN models through the lens of graph homomorphism. We validate the practical applicability of our theoretical findings by showing the alignment between the proposed bounds and the empirically observed generalization gaps over both real-world and synthetic datasets.
Personalized LoRA for Human-Centered Text Understanding
Mar 10, 2024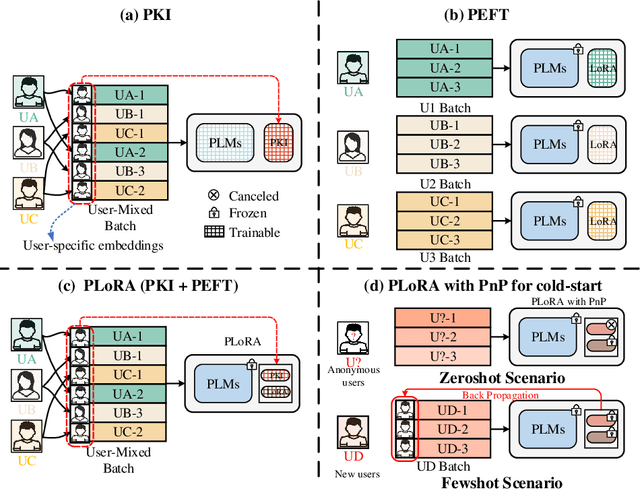
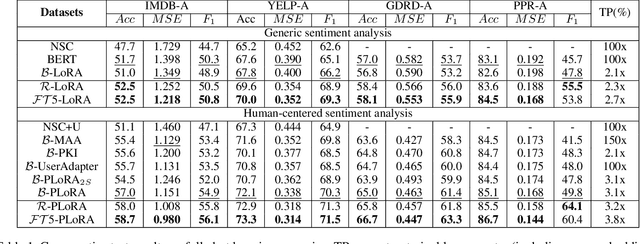
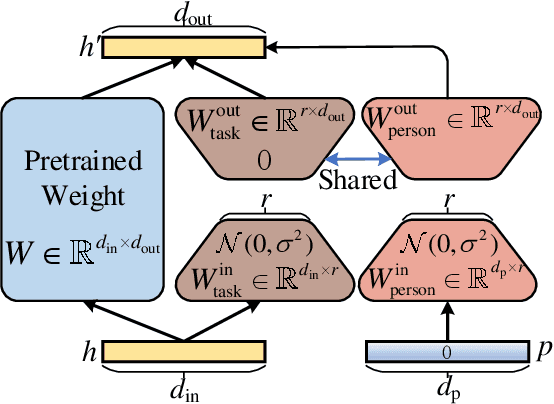
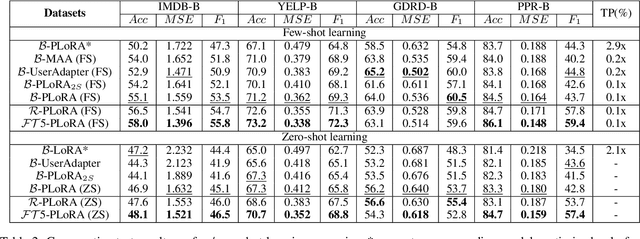
Effectively and efficiently adapting a pre-trained language model (PLM) for human-centered text understanding (HCTU) is challenging since user tokens are million-level in most personalized applications and do not have concrete explicit semantics. A standard and parameter-efficient approach (e.g., LoRA) necessitates memorizing numerous suits of adapters for each user. In this work, we introduce a personalized LoRA (PLoRA) with a plug-and-play (PnP) framework for the HCTU task. PLoRA is effective, parameter-efficient, and dynamically deploying in PLMs. Moreover, a personalized dropout and a mutual information maximizing strategies are adopted and hence the proposed PLoRA can be well adapted to few/zero-shot learning scenarios for the cold-start issue. Experiments conducted on four benchmark datasets show that the proposed method outperforms existing methods in full/few/zero-shot learning scenarios for the HCTU task, even though it has fewer trainable parameters. For reproducibility, the code for this paper is available at: https://github.com/yoyo-yun/PLoRA.
Transformer based Multitask Learning for Image Captioning and Object Detection
Mar 10, 2024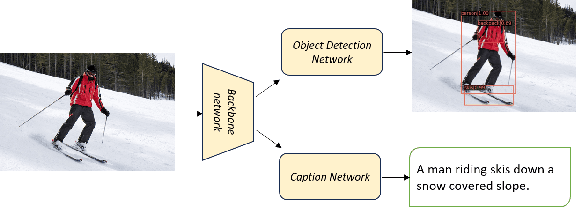
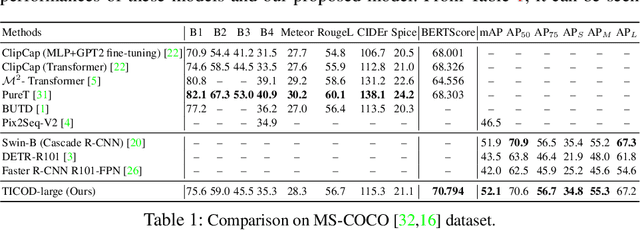
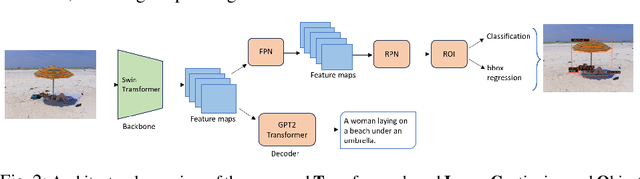
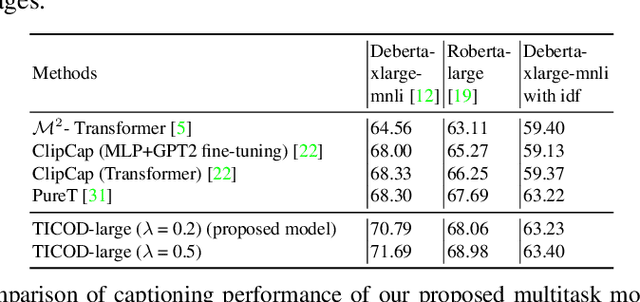
In several real-world scenarios like autonomous navigation and mobility, to obtain a better visual understanding of the surroundings, image captioning and object detection play a crucial role. This work introduces a novel multitask learning framework that combines image captioning and object detection into a joint model. We propose TICOD, Transformer-based Image Captioning and Object detection model for jointly training both tasks by combining the losses obtained from image captioning and object detection networks. By leveraging joint training, the model benefits from the complementary information shared between the two tasks, leading to improved performance for image captioning. Our approach utilizes a transformer-based architecture that enables end-to-end network integration for image captioning and object detection and performs both tasks jointly. We evaluate the effectiveness of our approach through comprehensive experiments on the MS-COCO dataset. Our model outperforms the baselines from image captioning literature by achieving a 3.65% improvement in BERTScore.