 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphTok: Morphologically Grounded Tokenization for Indian Languages
Apr 14, 2025



Tokenization is a crucial step in NLP, especially with the rise of large language models (LLMs), impacting downstream performance, computational cost, and efficiency. Existing LLMs rely on the classical Byte-pair Encoding (BPE) algorithm for subword tokenization that greedily merges frequent character bigrams. This often leads to segmentation that does not align with linguistically meaningful units. To address this, we propose morphology-aware segmentation as a pre-tokenization step prior to applying BPE. To facilitate morphology-aware segmentation, we create a novel dataset for Hindi and Marathi, incorporating sandhi splitting to enhance the subword tokenization. Experiments on downstream tasks show that morphologically grounded tokenization improves performance for machine translation and language modeling. Additionally, to handle the ambiguity in the Unicode characters for diacritics, particularly dependent vowels in syllable-based writing systems, we introduce Constrained BPE (CBPE), an extension to the traditional BPE algorithm that incorporates script-specific constraints. Specifically, CBPE handles dependent vowels. Our results show that CBPE achieves a 1.68\% reduction in fertility scores while maintaining comparable or improved downstream performance in machine translation, offering a computationally efficient alternative to standard BPE. Moreover, to evaluate segmentation across different tokenization algorithms, we introduce a new human evaluation metric, \textit{EvalTok}, enabling more human-grounded assessment.
BoK: Introducing Bag-of-Keywords Loss for Interpretable Dialogue Response Generation
Jan 17, 2025The standard language modeling (LM) loss by itself has been shown to be inadequate for effective dialogue modeling. As a result, various training approaches, such as auxiliary loss functions and leveraging human feedback, are being adopted to enrich open-domain dialogue systems. One such auxiliary loss function is Bag-of-Words (BoW) loss, defined as the cross-entropy loss for predicting all the words/tokens of the next utterance. In this work, we propose a novel auxiliary loss named Bag-of-Keywords (BoK) loss to capture the central thought of the response through keyword prediction and leverage it to enhance the generation of meaningful and interpretable responses in open-domain dialogue systems. BoK loss upgrades the BoW loss by predicting only the keywords or critical words/tokens of the next utterance, intending to estimate the core idea rather than the entire response. We incorporate BoK loss in both encoder-decoder (T5) and decoder-only (DialoGPT) architecture and train the models to minimize the weighted sum of BoK and LM (BoK-LM) loss. We perform our experiments on two popular open-domain dialogue datasets, DailyDialog and Persona-Chat. We show that the inclusion of BoK loss improves the dialogue generation of backbone models while also enabling post-hoc interpretability. We also study the effectiveness of BoK-LM loss as a reference-free metric and observe comparable performance to the state-of-the-art metrics on various dialogue evaluation datasets.
NLIP_Lab-IITH Multilingual MT System for WAT24 MT Shared Task
Oct 17, 2024



This paper describes NLIP Lab's multilingual machine translation system for the WAT24 shared task on multilingual Indic MT task for 22 scheduled languages belonging to 4 language families. We explore pre-training for Indic languages using alignment agreement objectives. We utilize bi-lingual dictionaries to substitute words from source sentences. Furthermore, we fine-tuned language direction-specific multilingual translation models using small and high-quality seed data. Our primary submission is a 243M parameters multilingual translation model covering 22 Indic languages. In the IN22-Gen benchmark, we achieved an average chrF++ score of 46.80 and 18.19 BLEU score for the En-Indic direction. In the Indic-En direction, we achieved an average chrF++ score of 56.34 and 30.82 BLEU score. In the In22-Conv benchmark, we achieved an average chrF++ score of 43.43 and BLEU score of 16.58 in the En-Indic direction, and in the Indic-En direction, we achieved an average of 52.44 and 29.77 for chrF++ and BLEU respectively. Our model\footnote{Our code and models are available at \url{https://github.com/maharajbrahma/WAT2024-MultiIndicMT}} is competitive with IndicTransv1 (474M parameter model).
NLIP_Lab-IITH Low-Resource MT System for WMT24 Indic MT Shared Task
Oct 04, 2024



In this paper, we describe our system for the WMT 24 shared task of Low-Resource Indic Language Translation. We consider eng $\leftrightarrow$ {as, kha, lus, mni} as participating language pairs. In this shared task, we explore the finetuning of a pre-trained model motivated by the pre-trained objective of aligning embeddings closer by alignment augmentation \cite{lin-etal-2020-pre} for 22 scheduled Indian languages. Our primary system is based on language-specific finetuning on a pre-trained model. We achieve chrF2 scores of 50.6, 42.3, 54.9, and 66.3 on the official public test set for eng$\rightarrow$as, eng$\rightarrow$kha, eng$\rightarrow$lus, eng$\rightarrow$mni respectively. We also explore multilingual training with/without language grouping and layer-freezing. Our code, models, and generated translations are available here: https://github.com/pramitsahoo/WMT2024-LRILT.
Transformer based Multitask Learning for Image Captioning and Object Detection
Mar 10, 2024In several real-world scenarios like autonomous navigation and mobility, to obtain a better visual understanding of the surroundings, image captioning and object detection play a crucial role. This work introduces a novel multitask learning framework that combines image captioning and object detection into a joint model. We propose TICOD, Transformer-based Image Captioning and Object detection model for jointly training both tasks by combining the losses obtained from image captioning and object detection networks. By leveraging joint training, the model benefits from the complementary information shared between the two tasks, leading to improved performance for image captioning. Our approach utilizes a transformer-based architecture that enables end-to-end network integration for image captioning and object detection and performs both tasks jointly. We evaluate the effectiveness of our approach through comprehensive experiments on the MS-COCO dataset. Our model outperforms the baselines from image captioning literature by achieving a 3.65% improvement in BERTScore.
Trie-NLG: Trie Context Augmentation to Improve Personalized Query Auto-Completion for Short and Unseen Prefixes
Jul 28, 2023Query auto-completion (QAC) aims at suggesting plausible completions for a given query prefix. Traditionally, QAC systems have leveraged tries curated from historical query logs to suggest most popular completions. In this context, there are two specific scenarios that are difficult to handle for any QAC system: short prefixes (which are inherently ambiguous) and unseen prefixes. Recently, personalized Natural Language Generation (NLG) models have been proposed to leverage previous session queries as context for addressing these two challenges. However, such NLG models suffer from two drawbacks: (1) some of the previous session queries could be noisy and irrelevant to the user intent for the current prefix, and (2) NLG models cannot directly incorporate historical query popularity. This motivates us to propose a novel NLG model for QAC, Trie-NLG, which jointly leverages popularity signals from trie and personalization signals from previous session queries. We train the Trie-NLG model by augmenting the prefix with rich context comprising of recent session queries and top trie completions. This simple modeling approach overcomes the limitations of trie-based and NLG-based approaches and leads to state-of-the-art performance. We evaluate the Trie-NLG model using two large QAC datasets. On average, our model achieves huge ~57% and ~14% boost in MRR over the popular trie-based lookup and the strong BART-based baseline methods, respectively. We make our code publicly available.
* Accepted at Journal Track of ECML-PKDD 2023
Utilizing Lexical Similarity to Enable Zero-Shot Machine Translation for Extremely Low-resource Languages
May 09, 2023



We address the task of machine translation from an extremely low-resource language (LRL) to English using cross-lingual transfer from a closely related high-resource language (HRL). For many of these languages, no parallel corpora are available, even monolingual corpora are limited and representations in pre-trained sequence-to-sequence models are absent. These factors limit the benefits of cross-lingual transfer from shared embedding spaces in multilingual models. However, many extremely LRLs have a high level of lexical similarity with related HRLs. We utilize this property by injecting character and character-span noise into the training data of the HRL prior to learning the vocabulary. This serves as a regularizer which makes the model more robust to lexical divergences between the HRL and LRL and better facilitates cross-lingual transfer. On closely related HRL and LRL pairs from multiple language families, we observe that our method significantly outperforms the baseline MT as well as approaches proposed previously to address cross-lingual transfer between closely related languages. We also show that the proposed character-span noise injection performs better than the unigram-character noise injection.
ComplAI: Theory of A Unified Framework for Multi-factor Assessment of Black-Box Supervised Machine Learning Models
Dec 30, 2022



The advances in Artificial Intelligence are creating new opportunities to improve lives of people around the world, from business to healthcare, from lifestyle to education. For example, some systems profile the users using their demographic and behavioral characteristics to make certain domain-specific predictions. Often, such predictions impact the life of the user directly or indirectly (e.g., loan disbursement, determining insurance coverage, shortlisting applications, etc.). As a result, the concerns over such AI-enabled systems are also increasing. To address these concerns, such systems are mandated to be responsible i.e., transparent, fair, and explainable to developers and end-users. In this paper, we present ComplAI, a unique framework to enable, observe, analyze and quantify explainability, robustness, performance, fairness, and model behavior in drift scenarios, and to provide a single Trust Factor that evaluates different supervised Machine Learning models not just from their ability to make correct predictions but from overall responsibility perspective. The framework helps users to (a) connect their models and enable explanations, (b) assess and visualize different aspects of the model, such as robustness, drift susceptibility, and fairness, and (c) compare different models (from different model families or obtained through different hyperparameter settings) from an overall perspective thereby facilitating actionable recourse for improvement of the models. It is model agnostic and works with different supervised machine learning scenarios (i.e., Binary Classification, Multi-class Classification, and Regression) and frameworks. It can be seamlessly integrated with any ML life-cycle framework. Thus, this already deployed framework aims to unify critical aspects of Responsible AI systems for regulating the development process of such real systems.
Towards Generalized and Explainable Long-Range Context Representation for Dialogue Systems
Oct 12, 2022
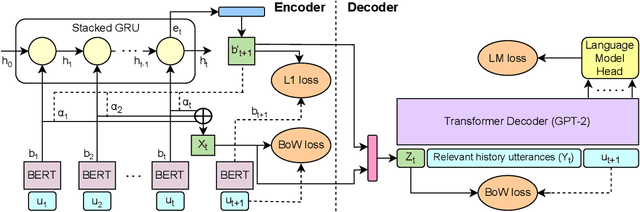
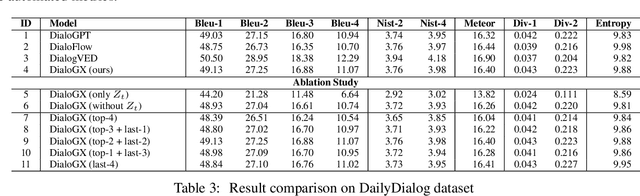
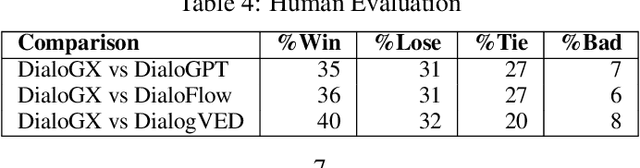
Context representation is crucial to both dialogue understanding and generation. Recently, the most popular method for dialog context representation is to concatenate the last-$k$ previous utterances as context and use a large transformer-based model to generate the next response. However, this method may not be ideal for conversations containing long-range dependencies. In this work, we propose DialoGX, a novel encoder-decoder based framework for conversational response generation with a generalized and explainable context representation that can look beyond the last-$k$ utterances. Hence the method is adaptive to conversations with long-range dependencies. Our proposed solution is based on two key ideas: a) computing a dynamic representation of the entire context, and b) finding the previous utterances that are relevant for generating the next response. Instead of last-$k$ utterances, DialoGX uses the concatenation of the dynamic context vector and encoding of the most relevant utterances as input which enables it to represent conversations of any length in a compact and generalized fashion. We conduct our experiments on DailyDialog, a popular open-domain chit-chat dataset. DialoGX achieves comparable performance with the state-of-the-art models on the automated metrics. We also justify our context representation through the lens of psycholinguistics and show that the relevance score of previous utterances agrees well with human cognition which makes DialoGX explainable as well.
On Text Style Transfer via Style Masked Language Models
Oct 12, 2022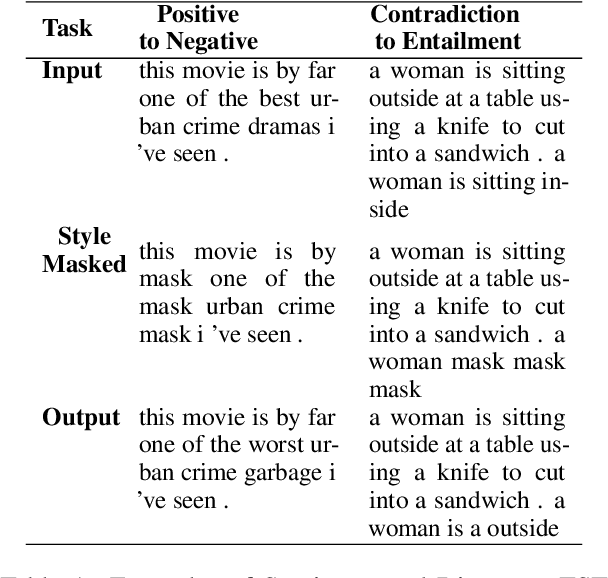
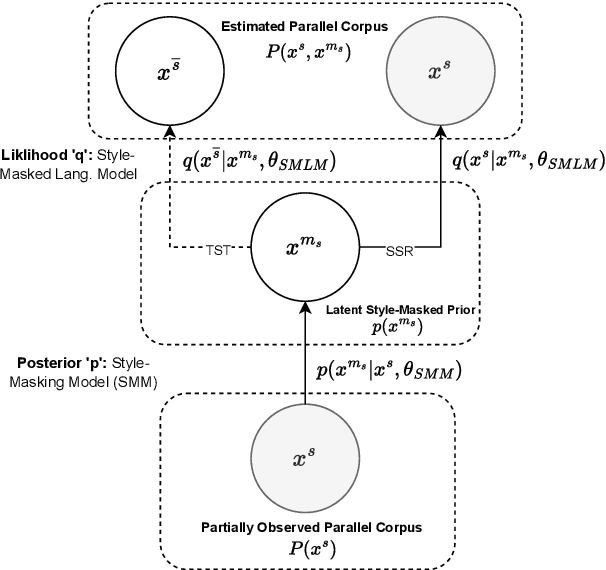
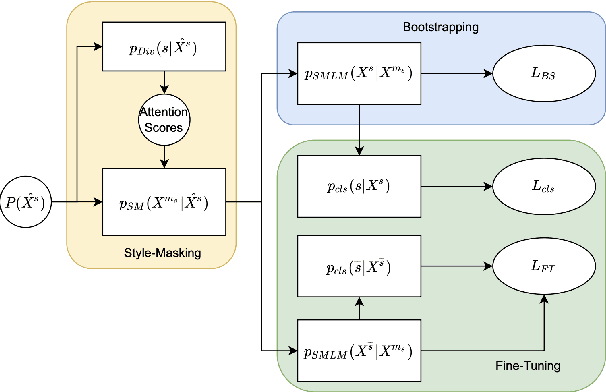
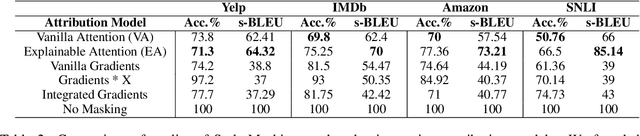
Text Style Transfer (TST) is performable through approaches such as latent space disentanglement, cycle-consistency losses, prototype editing etc. The prototype editing approach, which is known to be quite successful in TST, involves two key phases a) Masking of source style-associated tokens and b) Reconstruction of this source-style masked sentence conditioned with the target style. We follow a similar transduction method, in which we transpose the more difficult direct source to target TST task to a simpler Style-Masked Language Model (SMLM) Task, wherein, similar to BERT \cite{bert}, the goal of our model is now to reconstruct the source sentence from its style-masked version. We arrive at the SMLM mechanism naturally by formulating prototype editing/ transduction methods in a probabilistic framework, where TST resolves into estimating a hypothetical parallel dataset from a partially observed parallel dataset, wherein each domain is assumed to have a common latent style-masked prior. To generate this style-masked prior, we use "Explainable Attention" as our choice of attribution for a more precise style-masking step and also introduce a cost-effective and accurate "Attribution-Surplus" method of determining the position of masks from any arbitrary attribution model in O(1) time. We empirically show that this non-generational approach well suites the "content preserving" criteria for a task like TST, even for a complex style like Discourse Manipulation. Our model, the Style MLM, outperforms strong TST baselines and is on par with state-of-the-art TST models, which use complex architectures and orders of more parameters.