 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Overlapping oriented imbalanced ensemble learning method based on projective clustering and stagewise hybrid sampling
Nov 30, 2022
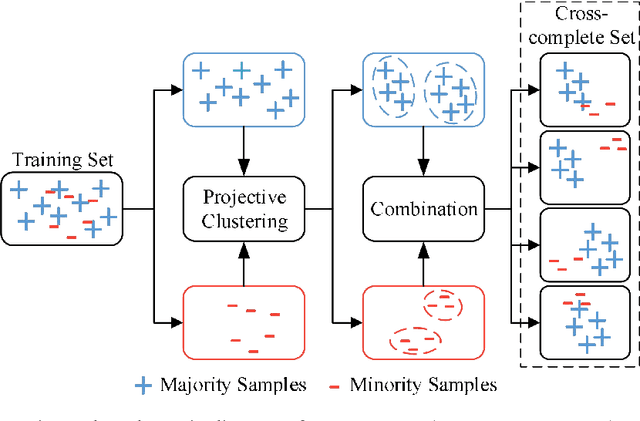
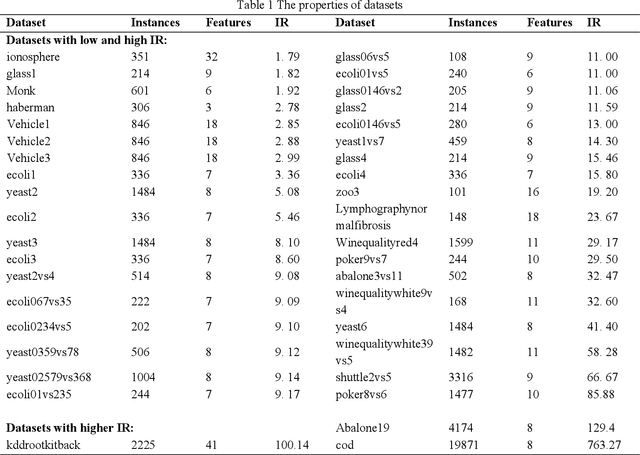
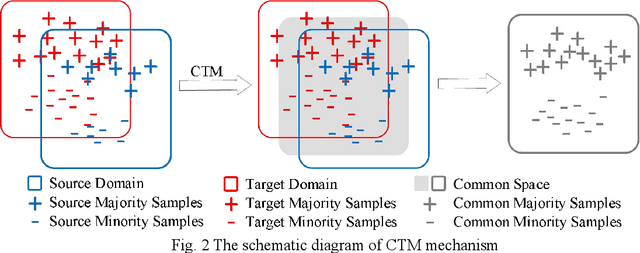
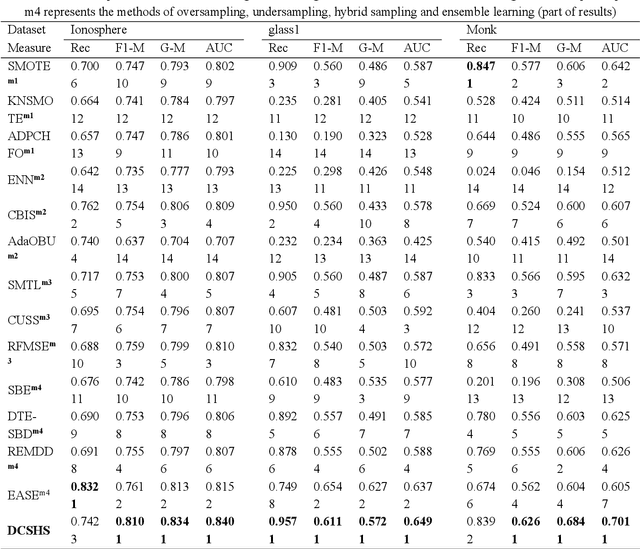
The challenge of imbalanced learning lies not only in class imbalance problem, but also in the class overlapping problem which is complex. However, most of the existing algorithms mainly focus on the former. The limitation prevents the existing methods from breaking through. To address this limitation, this paper proposes an ensemble learning algorithm based on dual clustering and stage-wise hybrid sampling (DCSHS). The DCSHS has three parts. Firstly, we design a projection clustering combination framework (PCC) guided by Davies-Bouldin clustering effectiveness index (DBI), which is used to obtain high-quality clusters and combine them to obtain a set of cross-complete subsets (CCS) with balanced class and low overlapping. Secondly, according to the characteristics of subset classes, a stage-wise hybrid sampling algorithm is designed to realize the de-overlapping and balancing of subsets. Finally, a projective clustering transfer mapping mechanism (CTM) is constructed for all processed subsets by means of transfer learning, thereby reducing class overlapping and explore structure information of samples. The major advantage of our algorithm is that it can exploit the intersectionality of the CCS to realize the soft elimination of overlapping majority samples, and learn as much information of overlapping samples as possible, thereby enhancing the class overlapping while class balancing. In the experimental section, more than 30 public datasets and over ten representative algorithms are chosen for verification. The experimental results show that the DCSHS is significantly best in terms of various evaluation criteria.
Noisy Group Testing with Side Information
Feb 24, 2022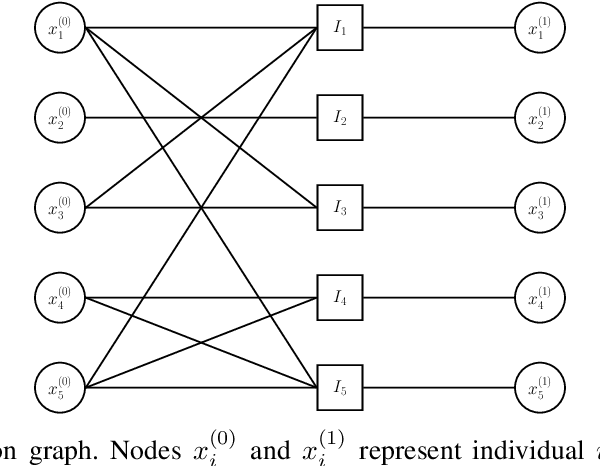
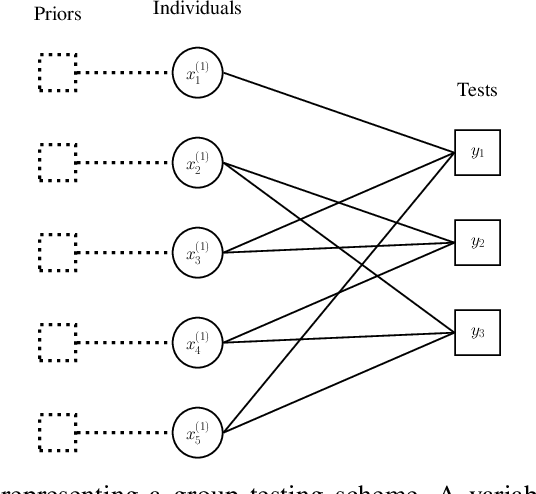
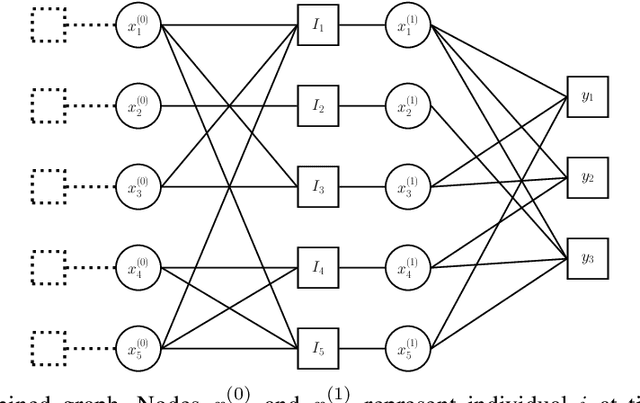
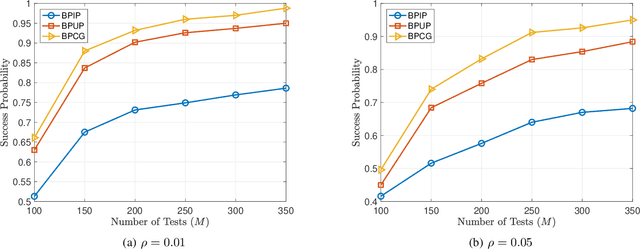
Group testing has recently attracted significant attention from the research community due to its applications in diagnostic virology. An instance of the group testing problem includes a ground set of individuals which includes a small subset of infected individuals. The group testing procedure consists of a number of tests, such that each test indicates whether or not a given subset of individuals includes one or more infected individuals. The goal of the group testing procedure is to identify the subset of infected individuals with the minimum number of tests. Motivated by practical scenarios, such as testing for viral diseases, this paper focuses on the following group testing settings: (i) the group testing procedure is noisy, i.e., the outcome of the group testing procedure can be flipped with a certain probability; (ii) there is a certain amount of side information on the distribution of the infected individuals available to the group testing algorithm. The paper makes the following contributions. First, we propose a probabilistic model, referred to as an interaction model, that captures the side information about the probability distribution of the infected individuals. Next, we present a decoding scheme, based on the belief propagation, that leverages the interaction model to improve the decoding accuracy. Our results indicate that the proposed algorithm achieves higher success probability and lower false-negative and false-positive rates when compared to the traditional belief propagation especially in the high noise regime.
Explainable Machine Learning for Hydrocarbon Prospect Risking
Dec 15, 2022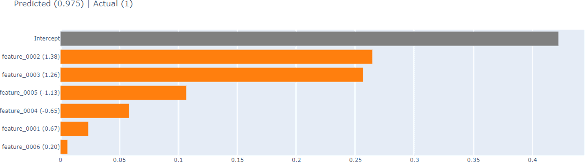
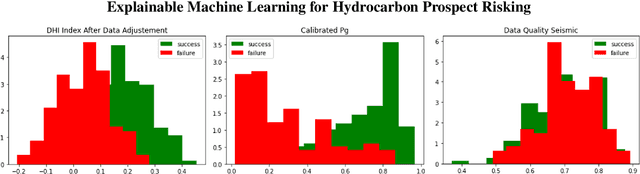
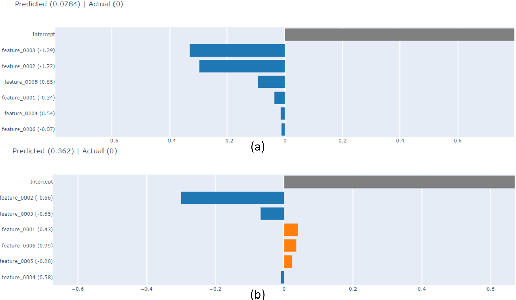
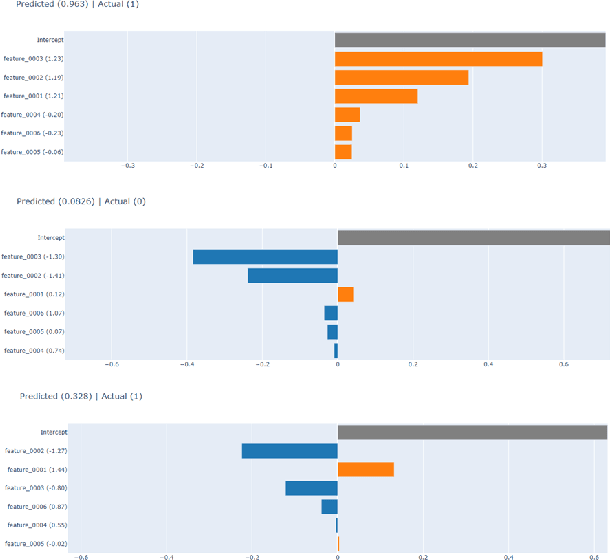
Hydrocarbon prospect risking is a critical application in geophysics predicting well outcomes from a variety of data including geological, geophysical, and other information modalities. Traditional routines require interpreters to go through a long process to arrive at the probability of success of specific outcomes. AI has the capability to automate the process but its adoption has been limited thus far owing to a lack of transparency in the way complicated, black box models generate decisions. We demonstrate how LIME -- a model-agnostic explanation technique -- can be used to inject trust in model decisions by uncovering the model's reasoning process for individual predictions. It generates these explanations by fitting interpretable models in the local neighborhood of specific datapoints being queried. On a dataset of well outcomes and corresponding geophysical attribute data, we show how LIME can induce trust in model's decisions by revealing the decision-making process to be aligned to domain knowledge. Further, it has the potential to debug mispredictions made due to anomalous patterns in the data or faulty training datasets.
Gaussian Process Mapping of Uncertain Building Models with GMM as Prior
Dec 15, 2022
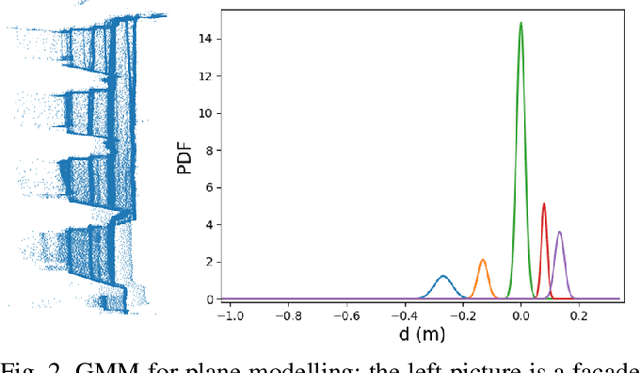
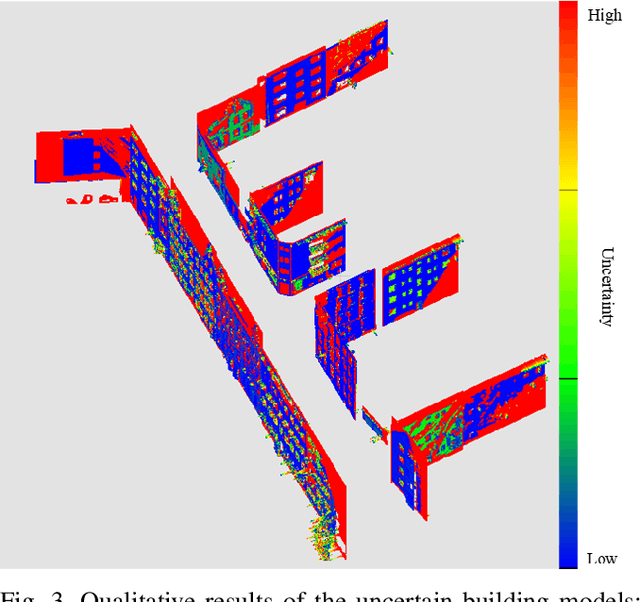
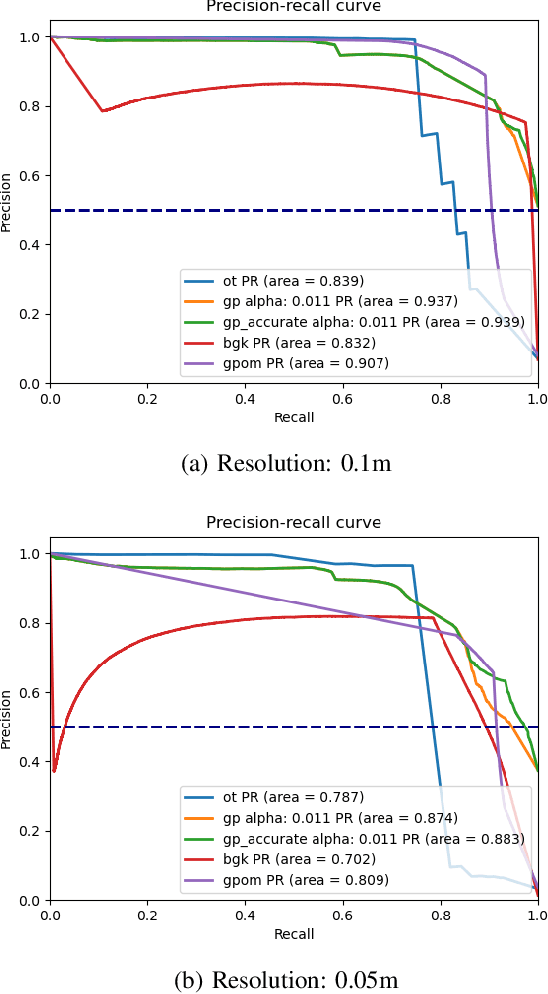
Mapping with uncertainty representation is required in many research domains, such as localization and sensor fusion. Although there are many uncertainty explorations in pose estimation of an ego-robot with map information, the quality of the reference maps is often neglected. To avoid the potential problems caused by the errors of maps and a lack of the uncertainty quantification, an adequate uncertainty measure for the maps is required. In this paper, uncertain building models with abstract map surface using Gaussian Process (GP) is proposed to measure the map uncertainty in a probabilistic way. To reduce the redundant computation for simple planar objects, extracted facets from a Gaussian Mixture Model (GMM) are combined with the implicit GP map while local GP-block techniques are used as well. The proposed method is evaluated on LiDAR point clouds of city buildings collected by a mobile mapping system. Compared to the performances of other methods such like Octomap, Gaussian Process Occupancy Map (GPOM) and Bayersian Generalized Kernel Inference (BGKOctomap), our method has achieved higher Precision-Recall AUC for evaluated buildings.
Joint Spatio-Temporal Modeling for the Semantic Change Detection in Remote Sensing Images
Dec 15, 2022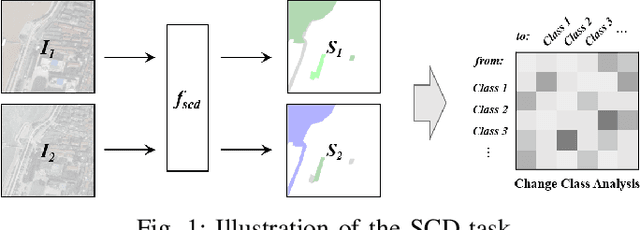
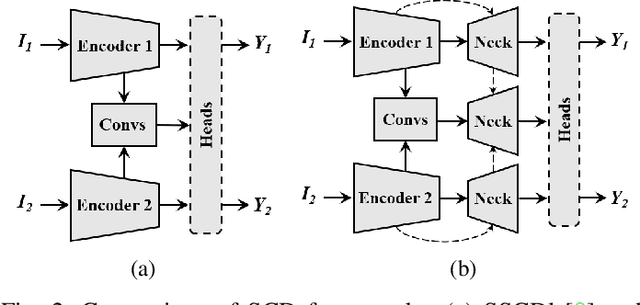
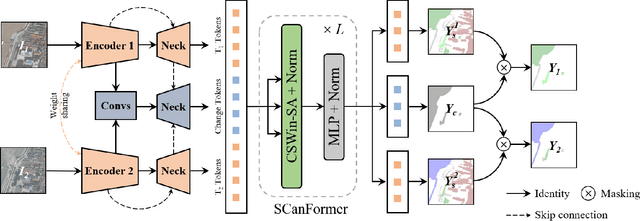
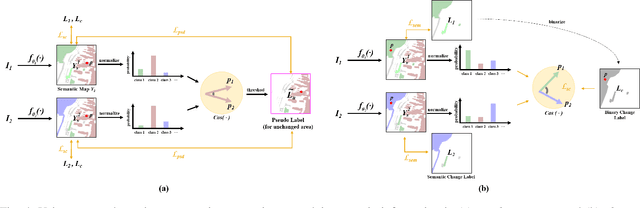
Semantic Change Detection (SCD) refers to the task of simultaneously extracting the changed areas and the semantic categories (before and after the changes) in Remote Sensing Images (RSIs). This is more meaningful than Binary Change Detection (BCD) since it enables detailed change analysis in the observed areas. Previous works established triple-branch Convolutional Neural Network (CNN) architectures as the paradigm for SCD. However, it remains challenging to exploit semantic information with a limited amount of change samples. In this work, we investigate to jointly consider the spatio-temporal dependencies to improve the accuracy of SCD. First, we propose a Semantic Change Transformer (SCanFormer) to explicitly model the 'from-to' semantic transitions between the bi-temporal RSIs. Then, we introduce a semantic learning scheme to leverage the spatio-temporal constraints, which are coherent to the SCD task, to guide the learning of semantic changes. The resulting network (SCanNet) significantly outperforms the baseline method in terms of both detection of critical semantic changes and semantic consistency in the obtained bi-temporal results. It achieves the SOTA accuracy on two benchmark datasets for the SCD.
SteerNeRF: Accelerating NeRF Rendering via Smooth Viewpoint Trajectory
Dec 15, 2022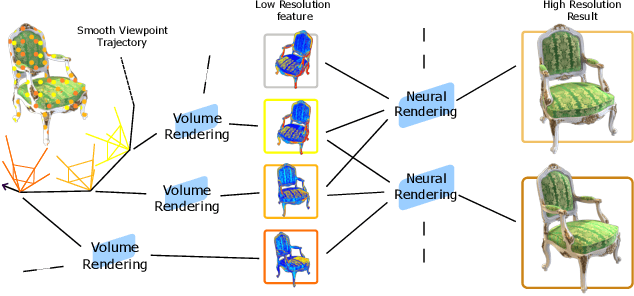
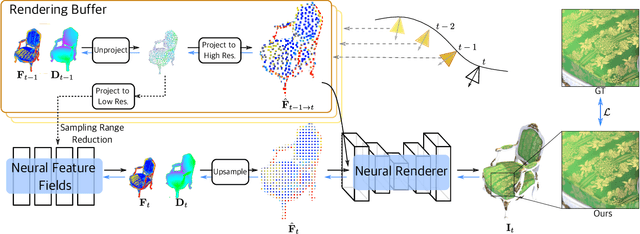

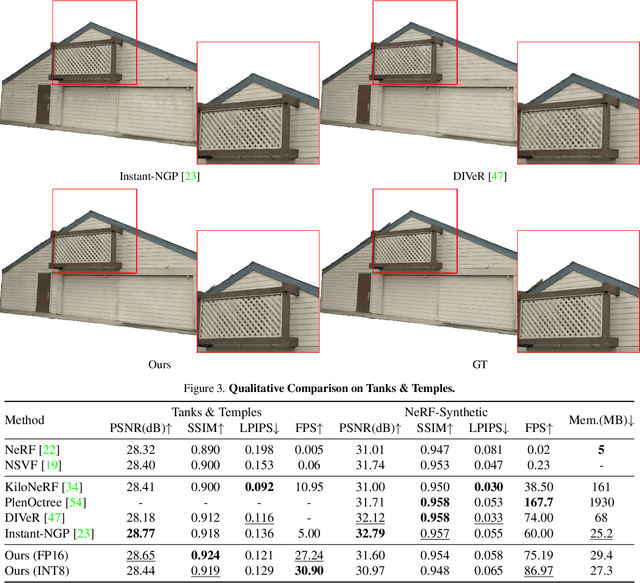
Neural Radiance Fields (NeRF) have demonstrated superior novel view synthesis performance but are slow at rendering. To speed up the volume rendering process, many acceleration methods have been proposed at the cost of large memory consumption. To push the frontier of the efficiency-memory trade-off, we explore a new perspective to accelerate NeRF rendering, leveraging a key fact that the viewpoint change is usually smooth and continuous in interactive viewpoint control. This allows us to leverage the information of preceding viewpoints to reduce the number of rendered pixels as well as the number of sampled points along the ray of the remaining pixels. In our pipeline, a low-resolution feature map is rendered first by volume rendering, then a lightweight 2D neural renderer is applied to generate the output image at target resolution leveraging the features of preceding and current frames. We show that the proposed method can achieve competitive rendering quality while reducing the rendering time with little memory overhead, enabling 30FPS at 1080P image resolution with a low memory footprint.
CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion
Nov 26, 2022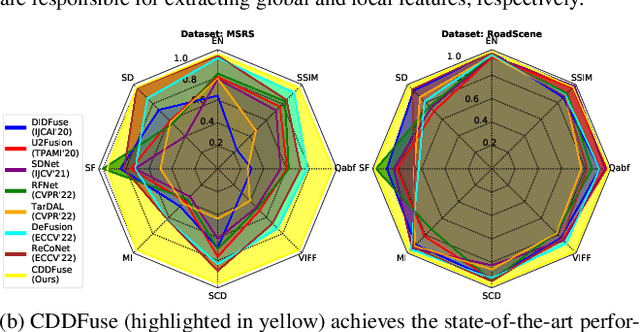
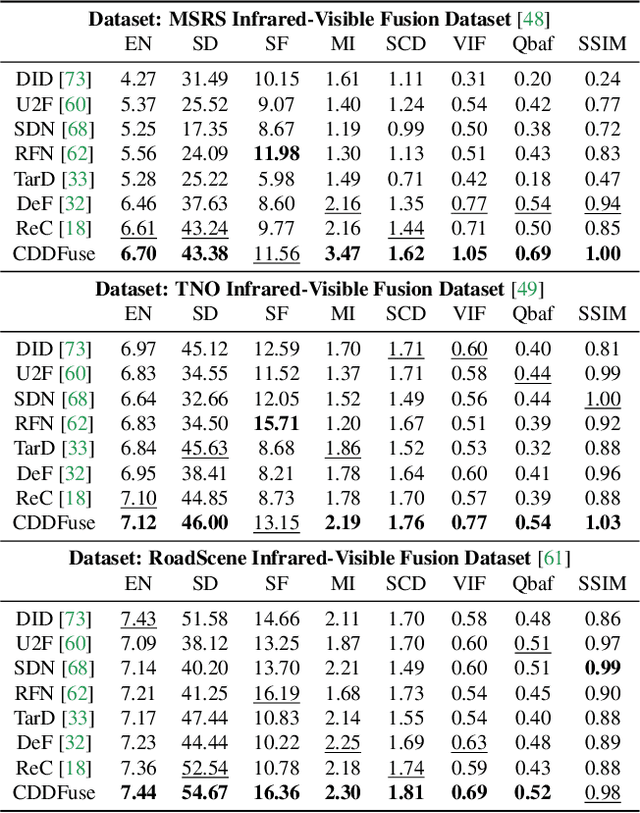
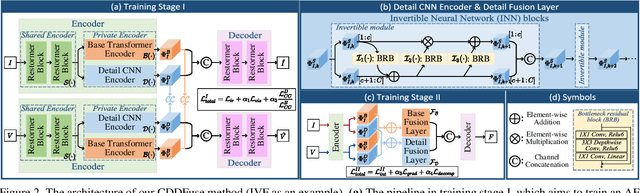
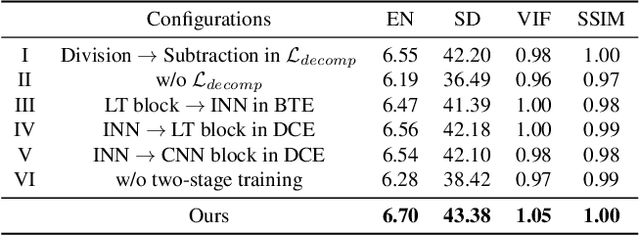
Multi-modality (MM) image fusion aims to render fused images that maintain the merits of different modalities, e.g., functional highlight and detailed textures. To tackle the challenge in modeling cross-modality features and decomposing desirable modality-specific and modality-shared features, we propose a novel Correlation-Driven feature Decomposition Fusion (CDDFuse) network for end-to-end MM feature decomposition and image fusion. In the first stage of the two-stage architectures, CDDFuse uses Restormer blocks to extract cross-modality shallow features. We then introduce a dual-branch Transformer-CNN feature extractor with Lite Transformer (LT) blocks leveraging long-range attention to handle low-frequency global features and Invertible Neural Networks (INN) blocks focusing on extracting high-frequency local information. Upon the embedded semantic information, the low-frequency features should be correlated while the high-frequency features should be uncorrelated. Thus, we propose a correlation-driven loss for better feature decomposition. In the second stage, the LT-based global fusion and INN-based local fusion layers output the fused image. Extensive experiments demonstrate that our CDDFuse achieves promising results in multiple fusion tasks, including infrared-visible image fusion and medical image fusion. We also show that CDDFuse can boost the performance in downstream infrared-visible semantic segmentation and object detection in a unified benchmark.
Predicting Eye Gaze Location on Websites
Nov 26, 2022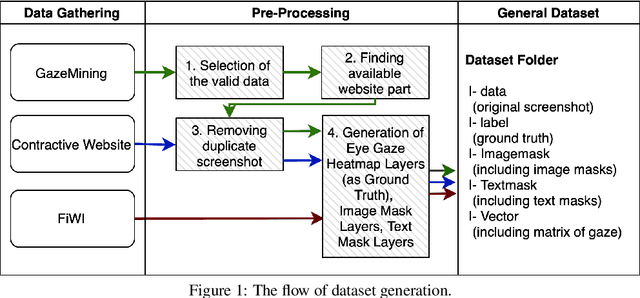
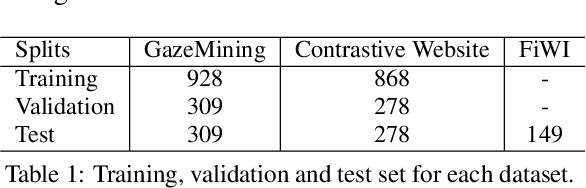
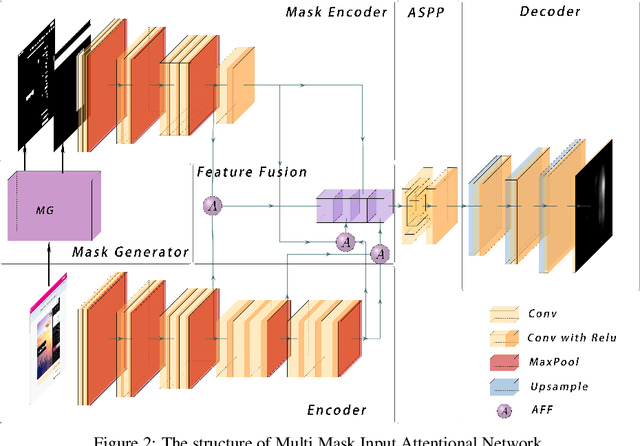
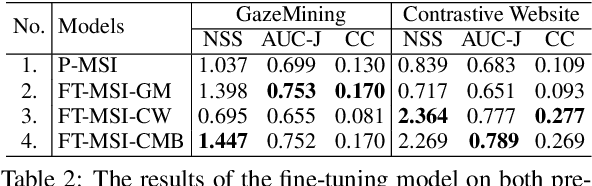
World-wide-web, with the website and webpage as the main interface, facilitates the dissemination of important information. Hence it is crucial to optimize them for better user interaction, which is primarily done by analyzing users' behavior, especially users' eye-gaze locations. However, gathering these data is still considered to be labor and time intensive. In this work, we enable the development of automatic eye-gaze estimations given a website screenshots as the input. This is done by the curation of a unified dataset that consists of website screenshots, eye-gaze heatmap and website's layout information in the form of image and text masks. Our pre-processed dataset allows us to propose an effective deep learning-based model that leverages both image and text spatial location, which is combined through attention mechanism for effective eye-gaze prediction. In our experiment, we show the benefit of careful fine-tuning using our unified dataset to improve the accuracy of eye-gaze predictions. We further observe the capability of our model to focus on the targeted areas (images and text) to achieve high accuracy. Finally, the comparison with other alternatives shows the state-of-the-art result of our model establishing the benchmark for the eye-gaze prediction task.
Mitigating Relational Bias on Knowledge Graphs
Nov 26, 2022
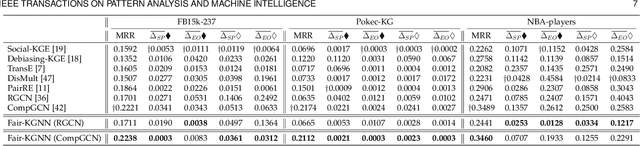
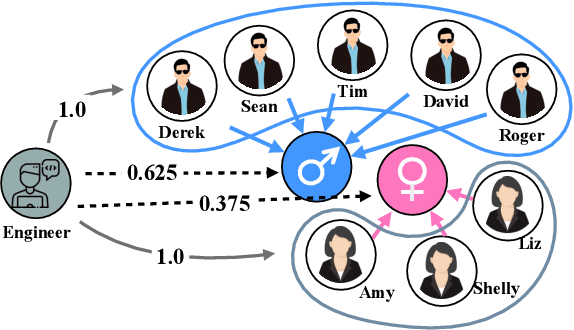
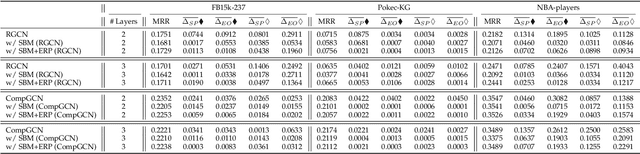
Knowledge graph data are prevalent in real-world applications, and knowledge graph neural networks (KGNNs) are essential techniques for knowledge graph representation learning. Although KGNN effectively models the structural information from knowledge graphs, these frameworks amplify the underlying data bias that leads to discrimination towards certain groups or individuals in resulting applications. Additionally, as existing debiasing approaches mainly focus on the entity-wise bias, eliminating the multi-hop relational bias that pervasively exists in knowledge graphs remains an open question. However, it is very challenging to eliminate relational bias due to the sparsity of the paths that generate the bias and the non-linear proximity structure of knowledge graphs. To tackle the challenges, we propose Fair-KGNN, a KGNN framework that simultaneously alleviates multi-hop bias and preserves the proximity information of entity-to-relation in knowledge graphs. The proposed framework is generalizable to mitigate the relational bias for all types of KGNN. We develop two instances of Fair-KGNN incorporating with two state-of-the-art KGNN models, RGCN and CompGCN, to mitigate gender-occupation and nationality-salary bias. The experiments carried out on three benchmark knowledge graph datasets demonstrate that the Fair-KGNN can effectively mitigate unfair situations during representation learning while preserving the predictive performance of KGNN models.
Graph Augmentation Clustering Network
Nov 19, 2022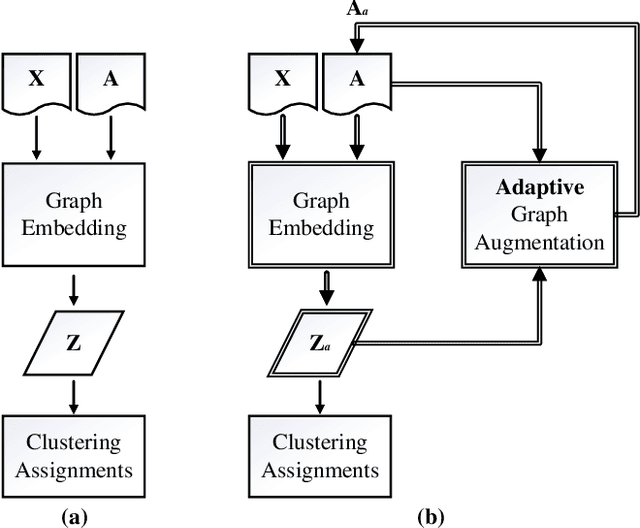
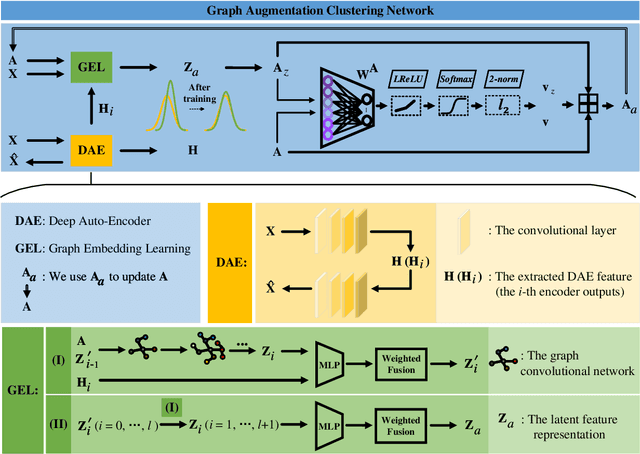

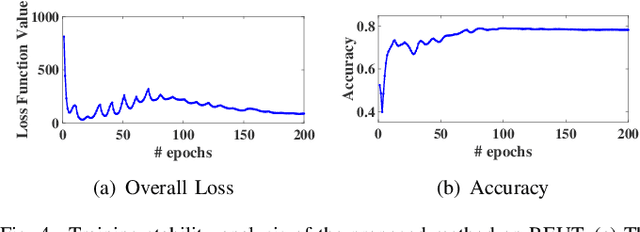
Existing graph clustering networks heavily rely on a predefined graph and may fail if the initial graph is of low quality. To tackle this issue, we propose a novel graph augmentation clustering network capable of adaptively enhancing the initial graph to achieve better clustering performance. Specifically, we first integrate the node attribute and topology structure information to learn the latent feature representation. Then, we explore the local geometric structure information on the embedding space to construct an adjacency graph and subsequently develop an adaptive graph augmentation architecture to fuse that graph with the initial one dynamically. Finally, we minimize the Jeffreys divergence between multiple derived distributions to conduct network training in an unsupervised fashion. Extensive experiments on six commonly used benchmark datasets demonstrate that the proposed method consistently outperforms several state-of-the-art approaches. In particular, our method improves the ARI by more than 9.39\% over the best baseline on DBLP. The source codes and data have been submitted to the appendix.