 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Self-matching Training Method with Annotation Embedding Models for Ontology Subsumption Prediction
Mar 10, 2024
Recently, ontology embeddings representing entities in a low-dimensional space have been proposed for ontology completion. However, the ontology embeddings for concept subsumption prediction do not address the difficulties of similar and isolated entities and fail to extract the global information of annotation axioms from an ontology. In this paper, we propose a self-matching training method for the two ontology embedding models: Inverted-index Matrix Embedding (InME) and Co-occurrence Matrix Embedding (CoME). The two embeddings capture the global and local information in annotation axioms by means of the occurring locations of each word in a set of axioms and the co-occurrences of words in each axiom. The self-matching training method increases the robustness of the concept subsumption prediction when predicted superclasses are similar to subclasses and are isolated to other entities in an ontology. Our evaluation experiments show that the self-matching training method with InME outperforms the existing ontology embeddings for the GO and FoodOn ontologies and that the method with the concatenation of CoME and OWL2Vec* outperforms them for the HeLiS ontology.
Mitigating Reward Hacking via Information-Theoretic Reward Modeling
Feb 16, 2024Despite the success of reinforcement learning from human feedback (RLHF) in aligning language models with human values, reward hacking, also termed reward overoptimization, remains a critical challenge, which primarily stems from limitations in reward modeling, i.e., generalizability of the reward model and inconsistency in the preference dataset. In this work, we tackle this problem from an information theoretic-perspective, and propose a generalizable and robust framework for reward modeling, namely InfoRM, by introducing a variational information bottleneck objective to filter out irrelevant information and developing a mechanism for model complexity modulation. Notably, we further identify a correlation between overoptimization and outliers in the latent space, establishing InfoRM as a promising tool for detecting reward overoptimization. Inspired by this finding, we propose the Integrated Cluster Deviation Score (ICDS), which quantifies deviations in the latent space, as an indicator of reward overoptimization to facilitate the development of online mitigation strategies. Extensive experiments on a wide range of settings and model scales (70M, 440M, 1.4B, and 7B) support the effectiveness of InfoRM. Further analyses reveal that InfoRM's overoptimization detection mechanism is effective, potentially signifying a notable advancement in the field of RLHF. Code will be released upon acceptance.
Envision3D: One Image to 3D with Anchor Views Interpolation
Mar 13, 2024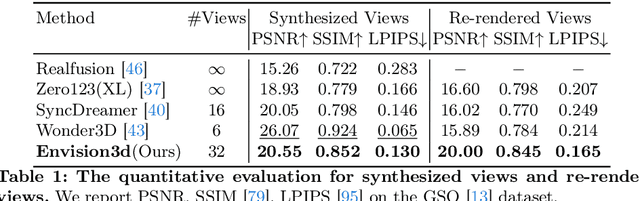
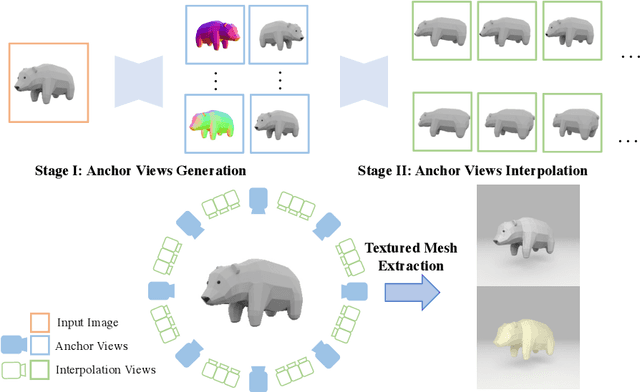

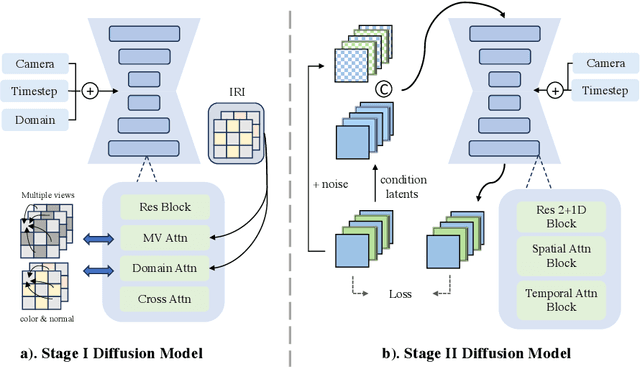
We present Envision3D, a novel method for efficiently generating high-quality 3D content from a single image. Recent methods that extract 3D content from multi-view images generated by diffusion models show great potential. However, it is still challenging for diffusion models to generate dense multi-view consistent images, which is crucial for the quality of 3D content extraction. To address this issue, we propose a novel cascade diffusion framework, which decomposes the challenging dense views generation task into two tractable stages, namely anchor views generation and anchor views interpolation. In the first stage, we train the image diffusion model to generate global consistent anchor views conditioning on image-normal pairs. Subsequently, leveraging our video diffusion model fine-tuned on consecutive multi-view images, we conduct interpolation on the previous anchor views to generate extra dense views. This framework yields dense, multi-view consistent images, providing comprehensive 3D information. To further enhance the overall generation quality, we introduce a coarse-to-fine sampling strategy for the reconstruction algorithm to robustly extract textured meshes from the generated dense images. Extensive experiments demonstrate that our method is capable of generating high-quality 3D content in terms of texture and geometry, surpassing previous image-to-3D baseline methods.
TINA: Think, Interaction, and Action Framework for Zero-Shot Vision Language Navigation
Mar 13, 2024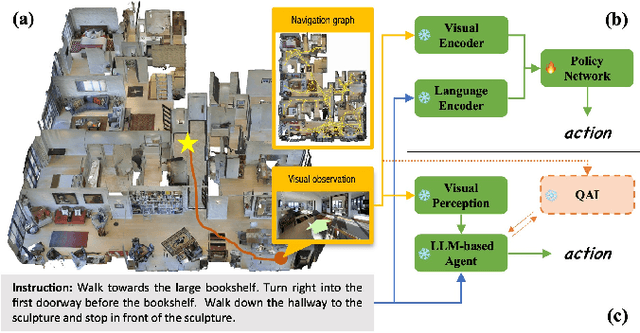
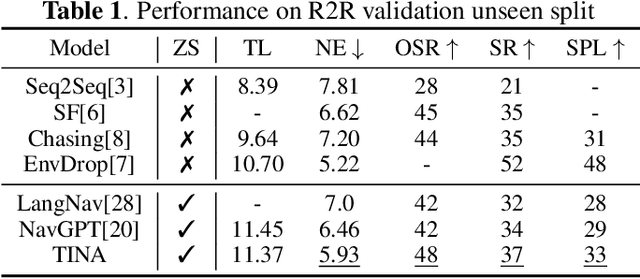
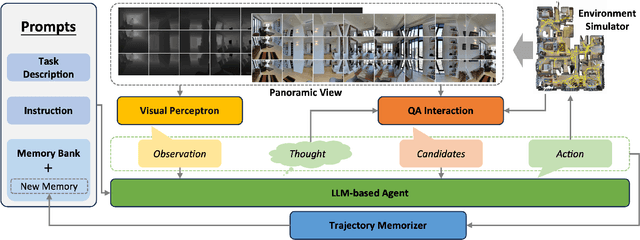
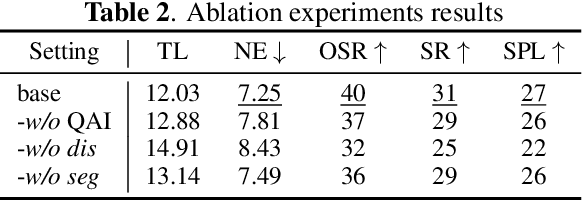
Zero-shot navigation is a critical challenge in Vision-Language Navigation (VLN) tasks, where the ability to adapt to unfamiliar instructions and to act in unknown environments is essential. Existing supervised learning-based models, trained using annotated data through reinforcement learning, exhibit limitations in generalization capabilities. Large Language Models (LLMs), with their extensive knowledge and emergent reasoning abilities, present a potential pathway for achieving zero-shot navigation. This paper presents a VLN agent based on LLMs, exploring approaches to the zero-shot navigation problem. To compensate for the shortcomings of LLMs in environmental perception, we propose the Thinking, Interacting, and Action (TINA) framework. TINA enables the agent to scrutinize perceptual information and autonomously query key clues within the environment through an introduced question-answering module, thereby aligning instructions with specific perceptual data. The navigation agent's perceptual abilities are enhanced through the TINA framework, while the explicit thought and query processes also improve the navigational procedure's explainability and transparency. We evaluate the performance of our method on the Room-to-Room dataset. The experiment results indicate that our approach improves the navigation performance of LLM-based agents. Our approach also outperformed some supervised learning-based methods, highlighting its efficacy in zero-shot navigation.
Leveraging Non-Decimated Wavelet Packet Features and Transformer Models for Time Series Forecasting
Mar 13, 2024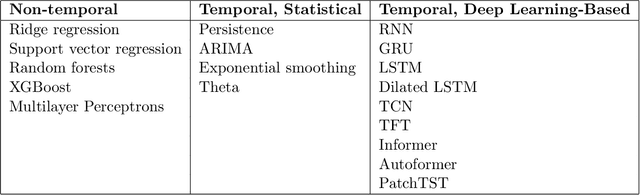
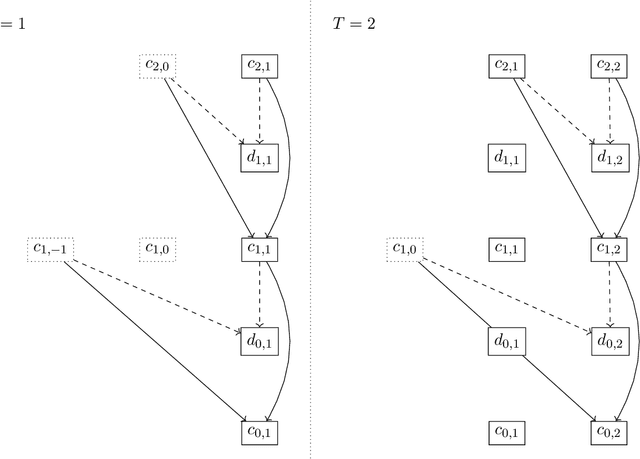
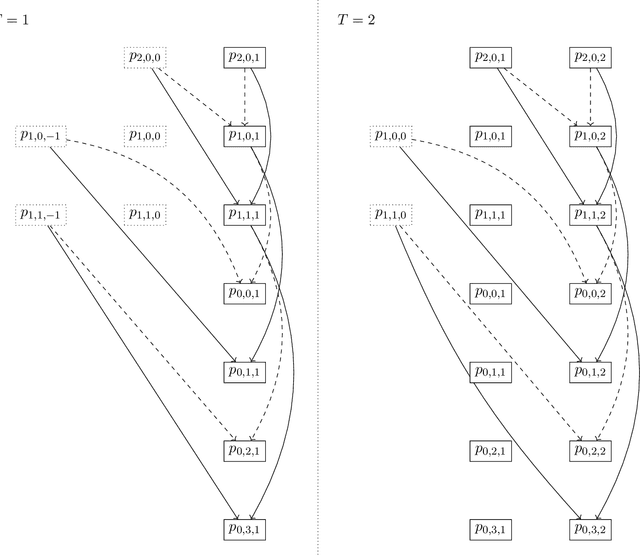
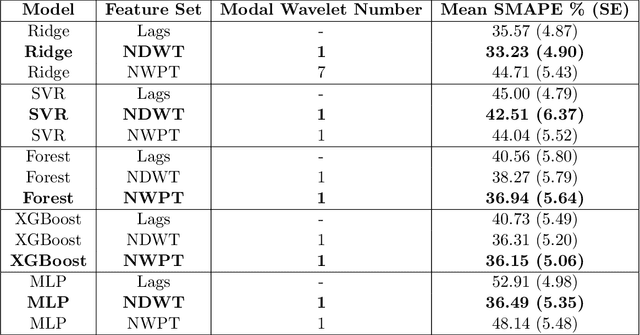
This article combines wavelet analysis techniques with machine learning methods for univariate time series forecasting, focusing on three main contributions. Firstly, we consider the use of Daubechies wavelets with different numbers of vanishing moments as input features to both non-temporal and temporal forecasting methods, by selecting these numbers during the cross-validation phase. Secondly, we compare the use of both the non-decimated wavelet transform and the non-decimated wavelet packet transform for computing these features, the latter providing a much larger set of potentially useful coefficient vectors. The wavelet coefficients are computed using a shifted version of the typical pyramidal algorithm to ensure no leakage of future information into these inputs. Thirdly, we evaluate the use of these wavelet features on a significantly wider set of forecasting methods than previous studies, including both temporal and non-temporal models, and both statistical and deep learning-based methods. The latter include state-of-the-art transformer-based neural network architectures. Our experiments suggest significant benefit in replacing higher-order lagged features with wavelet features across all examined non-temporal methods for one-step-forward forecasting, and modest benefit when used as inputs for temporal deep learning-based models for long-horizon forecasting.
A Novel Feature Learning-based Bio-inspired Neural Network for Real-time Collision-free Rescue of Multi-Robot Systems
Mar 13, 2024
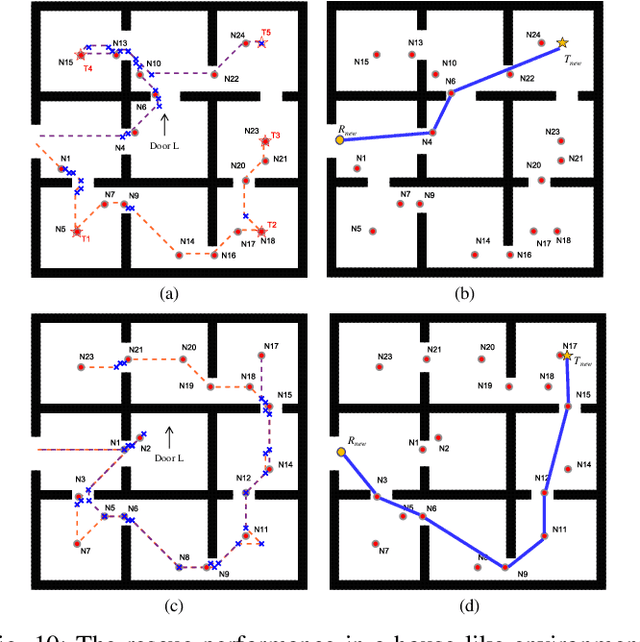

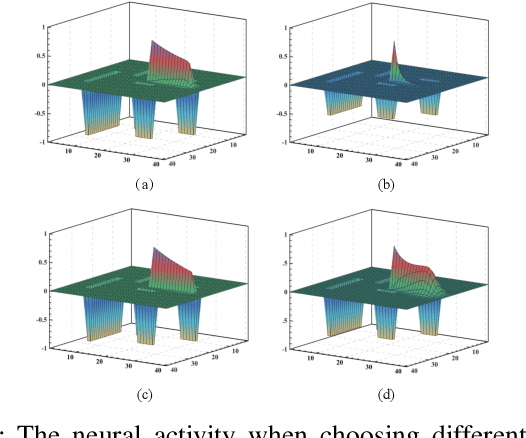
Natural disasters and urban accidents drive the demand for rescue robots to provide safer, faster, and more efficient rescue trajectories. In this paper, a feature learning-based bio-inspired neural network (FLBBINN) is proposed to quickly generate a heuristic rescue path in complex and dynamic environments, as traditional approaches usually cannot provide a satisfactory solution to real-time responses to sudden environmental changes. The neurodynamic model is incorporated into the feature learning method that can use environmental information to improve path planning strategies. Task assignment and collision-free rescue trajectory are generated through robot poses and the dynamic landscape of neural activity. A dual-channel scale filter, a neural activity channel, and a secondary distance fusion are employed to extract and filter feature neurons. After completion of the feature learning process, a neurodynamics-based feature matrix is established to quickly generate the new heuristic rescue paths with parameter-driven topological adaptability. The proposed FLBBINN aims to reduce the computational complexity of the neural network-based approach and enable the feature learning method to achieve real-time responses to environmental changes. Several simulations and experiments have been conducted to evaluate the performance of the proposed FLBBINN. The results show that the proposed FLBBINN would significantly improve the speed, efficiency, and optimality for rescue operations.
HIP Network: Historical Information Passing Network for Extrapolation Reasoning on Temporal Knowledge Graph
Feb 19, 2024In recent years, temporal knowledge graph (TKG) reasoning has received significant attention. Most existing methods assume that all timestamps and corresponding graphs are available during training, which makes it difficult to predict future events. To address this issue, recent works learn to infer future events based on historical information. However, these methods do not comprehensively consider the latent patterns behind temporal changes, to pass historical information selectively, update representations appropriately and predict events accurately. In this paper, we propose the Historical Information Passing (HIP) network to predict future events. HIP network passes information from temporal, structural and repetitive perspectives, which are used to model the temporal evolution of events, the interactions of events at the same time step, and the known events respectively. In particular, our method considers the updating of relation representations and adopts three scoring functions corresponding to the above dimensions. Experimental results on five benchmark datasets show the superiority of HIP network, and the significant improvements on Hits@1 prove that our method can more accurately predict what is going to happen.
* 7 pages, 3 figures
DAMSDet: Dynamic Adaptive Multispectral Detection Transformer with Competitive Query Selection and Adaptive Feature Fusion
Mar 07, 2024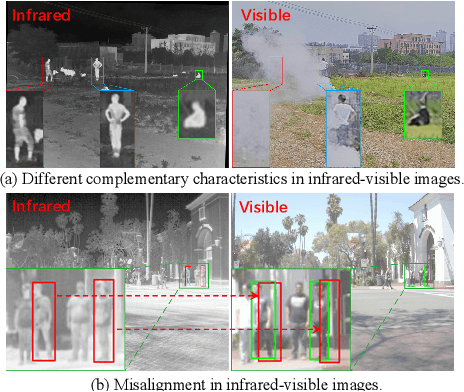
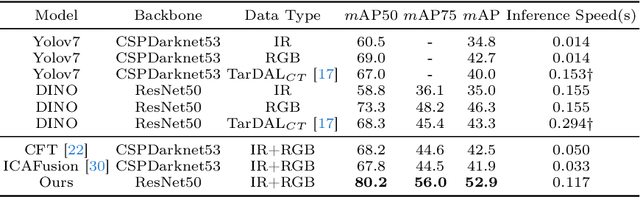
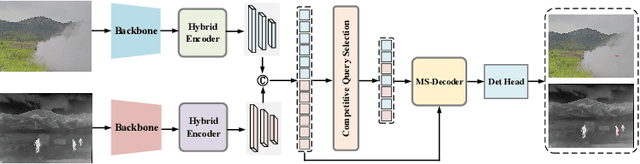
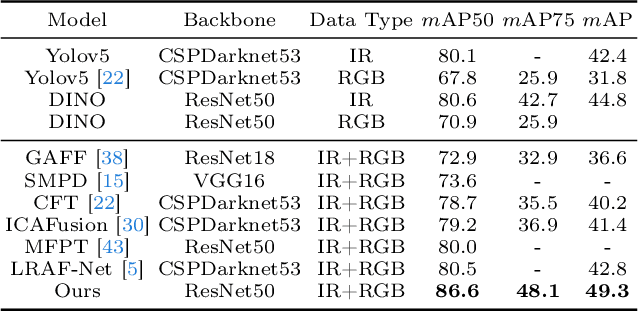
Infrared-visible object detection aims to achieve robust even full-day object detection by fusing the complementary information of infrared and visible images. However, highly dynamically variable complementary characteristics and commonly existing modality misalignment make the fusion of complementary information difficult. In this paper, we propose a Dynamic Adaptive Multispectral Detection Transformer (DAMSDet) to simultaneously address these two challenges. Specifically, we propose a Modality Competitive Query Selection strategy to provide useful prior information. This strategy can dynamically select basic salient modality feature representation for each object. To effectively mine the complementary information and adapt to misalignment situations, we propose a Multispectral Deformable Cross-attention module to adaptively sample and aggregate multi-semantic level features of infrared and visible images for each object. In addition, we further adopt the cascade structure of DETR to better mine complementary information. Experiments on four public datasets of different scenes demonstrate significant improvements compared to other state-of-the-art methods. The code will be released at https://github.com/gjj45/DAMSDet.
Memory-based Adapters for Online 3D Scene Perception
Mar 11, 2024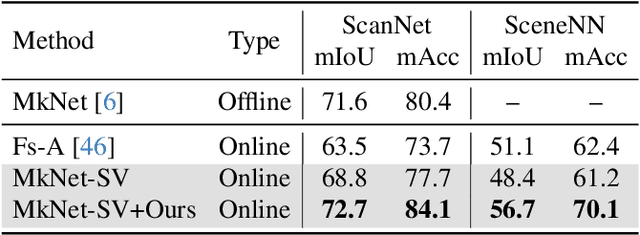
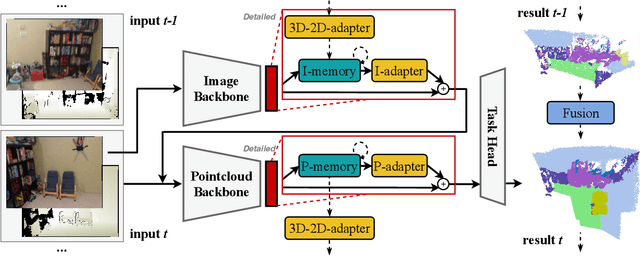
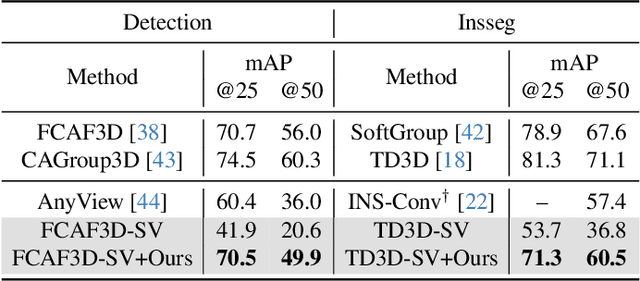
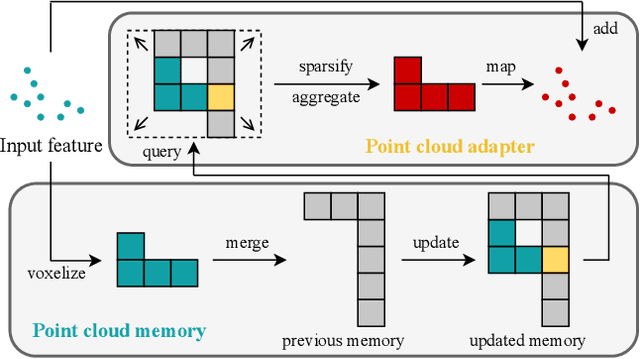
In this paper, we propose a new framework for online 3D scene perception. Conventional 3D scene perception methods are offline, i.e., take an already reconstructed 3D scene geometry as input, which is not applicable in robotic applications where the input data is streaming RGB-D videos rather than a complete 3D scene reconstructed from pre-collected RGB-D videos. To deal with online 3D scene perception tasks where data collection and perception should be performed simultaneously, the model should be able to process 3D scenes frame by frame and make use of the temporal information. To this end, we propose an adapter-based plug-and-play module for the backbone of 3D scene perception model, which constructs memory to cache and aggregate the extracted RGB-D features to empower offline models with temporal learning ability. Specifically, we propose a queued memory mechanism to cache the supporting point cloud and image features. Then we devise aggregation modules which directly perform on the memory and pass temporal information to current frame. We further propose 3D-to-2D adapter to enhance image features with strong global context. Our adapters can be easily inserted into mainstream offline architectures of different tasks and significantly boost their performance on online tasks. Extensive experiments on ScanNet and SceneNN datasets demonstrate our approach achieves leading performance on three 3D scene perception tasks compared with state-of-the-art online methods by simply finetuning existing offline models, without any model and task-specific designs. \href{https://xuxw98.github.io/Online3D/}{Project page}.
Answering Diverse Questions via Text Attached with Key Audio-Visual Clues
Mar 11, 2024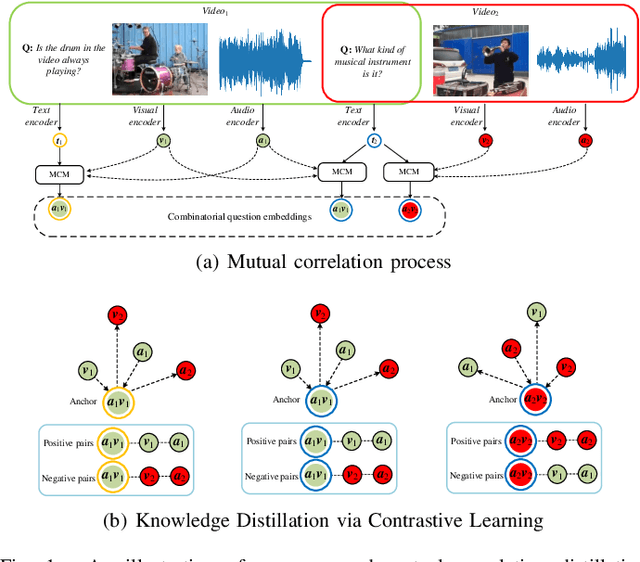
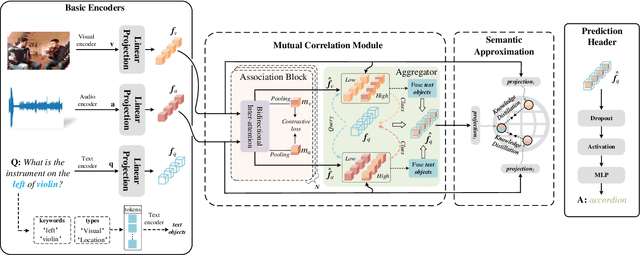
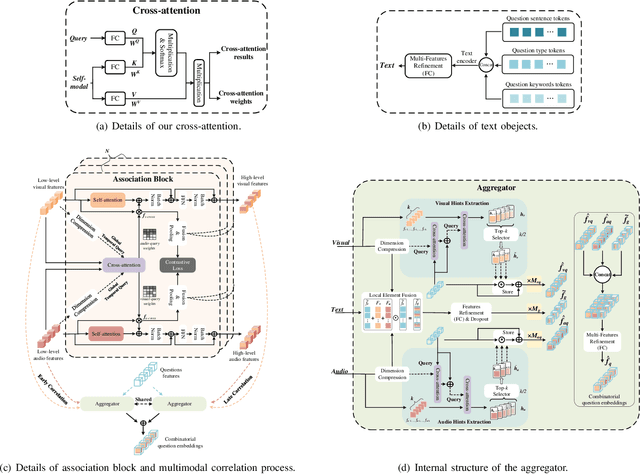
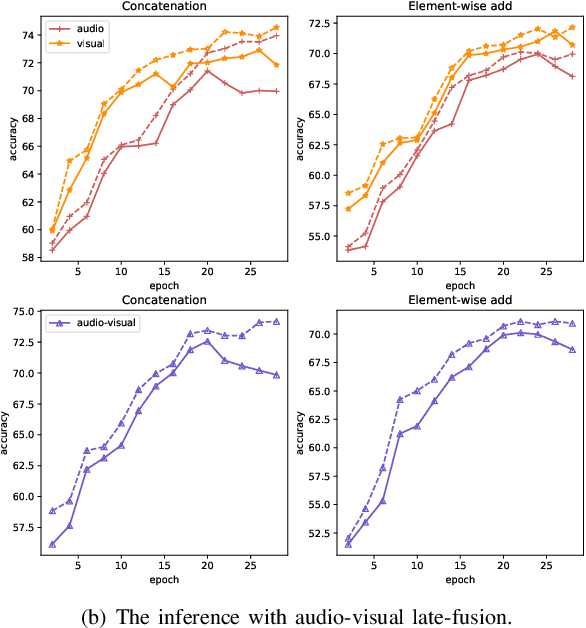
Audio-visual question answering (AVQA) requires reference to video content and auditory information, followed by correlating the question to predict the most precise answer. Although mining deeper layers of audio-visual information to interact with questions facilitates the multimodal fusion process, the redundancy of audio-visual parameters tends to reduce the generalization of the inference engine to multiple question-answer pairs in a single video. Indeed, the natural heterogeneous relationship between audiovisuals and text makes the perfect fusion challenging, to prevent high-level audio-visual semantics from weakening the network's adaptability to diverse question types, we propose a framework for performing mutual correlation distillation (MCD) to aid question inference. MCD is divided into three main steps: 1) firstly, the residual structure is utilized to enhance the audio-visual soft associations based on self-attention, then key local audio-visual features relevant to the question context are captured hierarchically by shared aggregators and coupled in the form of clues with specific question vectors. 2) Secondly, knowledge distillation is enforced to align audio-visual-text pairs in a shared latent space to narrow the cross-modal semantic gap. 3) And finally, the audio-visual dependencies are decoupled by discarding the decision-level integrations. We evaluate the proposed method on two publicly available datasets containing multiple question-and-answer pairs, i.e., Music-AVQA and AVQA. Experiments show that our method outperforms other state-of-the-art methods, and one interesting finding behind is that removing deep audio-visual features during inference can effectively mitigate overfitting. The source code is released at http://github.com/rikeilong/MCD-forAVQA.