 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self-matching Training Method with Annotation Embedding Models for Ontology Subsumption Prediction
Mar 10, 2024Recently, ontology embeddings representing entities in a low-dimensional space have been proposed for ontology completion. However, the ontology embeddings for concept subsumption prediction do not address the difficulties of similar and isolated entities and fail to extract the global information of annotation axioms from an ontology. In this paper, we propose a self-matching training method for the two ontology embedding models: Inverted-index Matrix Embedding (InME) and Co-occurrence Matrix Embedding (CoME). The two embeddings capture the global and local information in annotation axioms by means of the occurring locations of each word in a set of axioms and the co-occurrences of words in each axiom. The self-matching training method increases the robustness of the concept subsumption prediction when predicted superclasses are similar to subclasses and are isolated to other entities in an ontology. Our evaluation experiments show that the self-matching training method with InME outperforms the existing ontology embeddings for the GO and FoodOn ontologies and that the method with the concatenation of CoME and OWL2Vec* outperforms them for the HeLiS ontology.
Hierarchical Model Selection for Graph Neural Netoworks
Dec 01, 2022Node classification on graph data is a major problem, and various graph neural networks (GNNs) have been proposed. Variants of GNNs such as H2GCN and CPF outperform graph convolutional networks (GCNs) by improving on the weaknesses of the traditional GNN. However, there are some graph data which these GNN variants fail to perform well than other GNNs in the node classification task. This is because H2GCN has a feature thinning on graph data with high average degree, and CPF gives rise to a problem about label-propagation suitability. Accordingly, we propose a hierarchical model selection framework (HMSF) that selects an appropriate GNN model by analyzing the indicators of each graph data. In the experiment, we show that the model selected by our HMSF achieves high performance on node classification for various types of graph data.
Block-Segmentation Vectors for Arousal Prediction using Semi-supervised Learning
Apr 11, 2022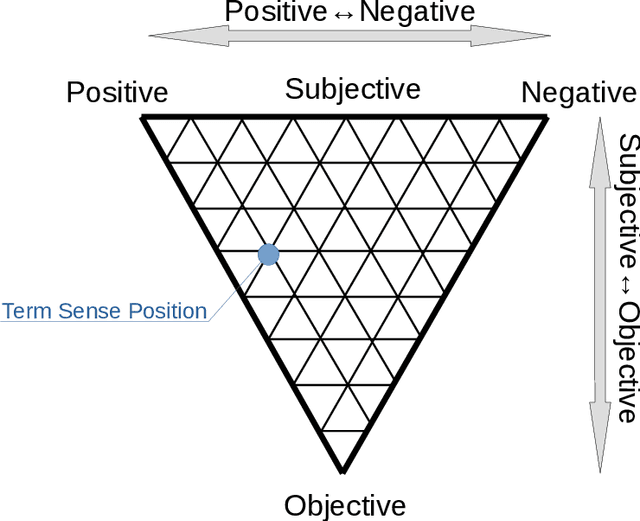
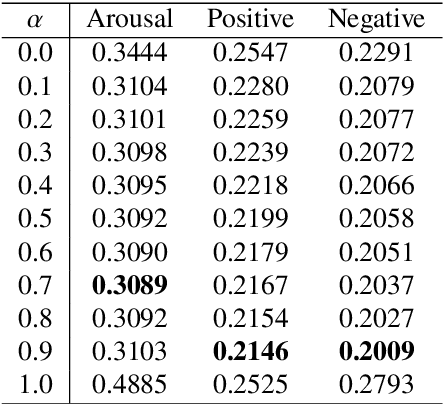
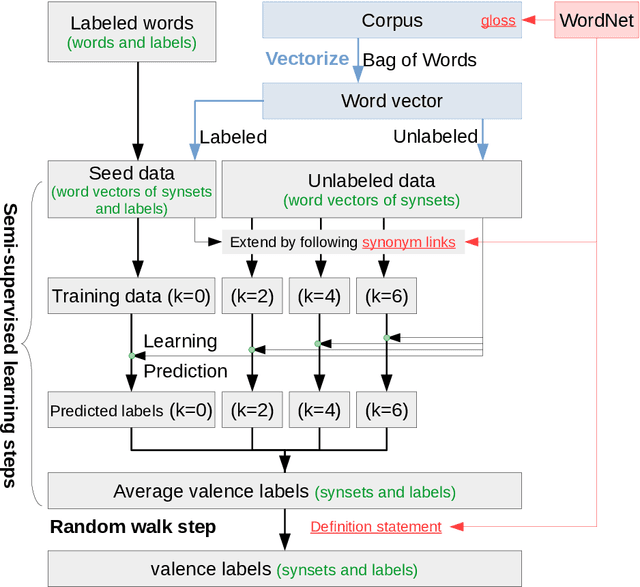
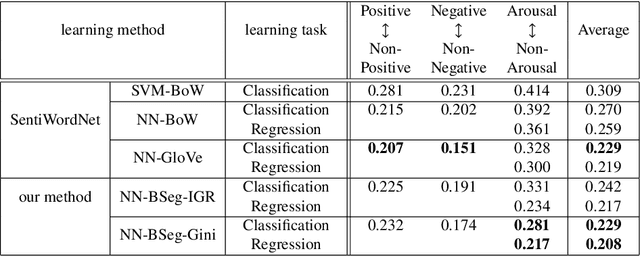
To handle emotional expressions in computer applications, Russell's circum- plex model has been useful for representing emotions according to valence and arousal. In SentiWordNet, the level of valence is automatically assigned to a large number of synsets (groups of synonyms in WordNet) using semi-supervised learning. However, when assigning the level of arousal, the existing method proposed for SentiWordNet reduces the accuracy of sentiment prediction. In this paper, we propose a block-segmentation vector for predicting the arousal levels of many synsets from a small number of labeled words using semi-supervised learning. We analyze the distribution of arousal and non-arousal words in a corpus of sentences by comparing it with the distribution of valence words. We address the problem that arousal level prediction fails when arousal and non-arousal words are mixed together in some sentences. To capture the features of such arousal and non-arousal words, we generate word vectors based on inverted indexes by block IDs, where the corpus is divided into blocks in the flow of sentences. In the evaluation experiment, we show that the results of arousal prediction with the block-segmentation vectors outperform the results of the previous method in SentiWordNet.
Skip Vectors for RDF Data: Extraction Based on the Complexity of Feature Patterns
Jan 07, 2022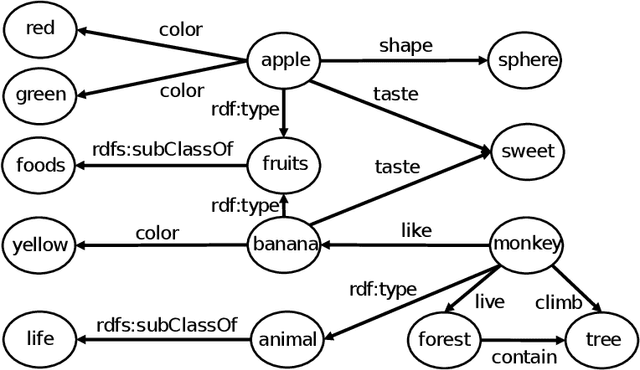
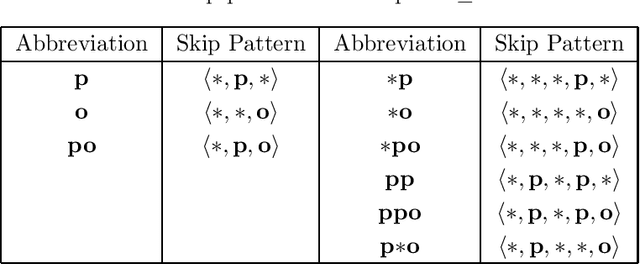
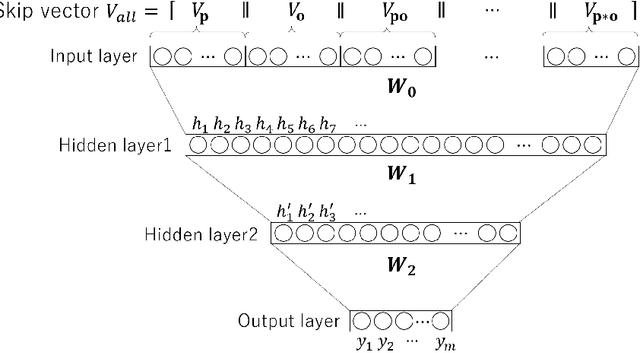
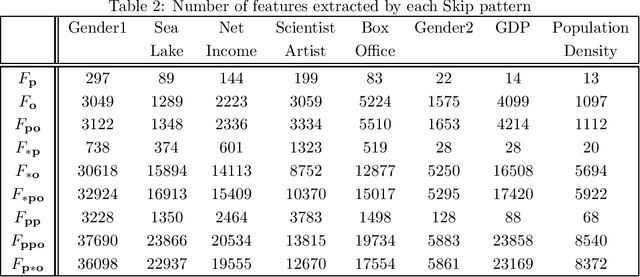
The Resource Description Framework (RDF) is a framework for describing metadata, such as attributes and relationships of resources on the Web. Machine learning tasks for RDF graphs adopt three methods: (i) support vector machines (SVMs) with RDF graph kernels, (ii) RDF graph embeddings, and (iii) relational graph convolutional networks. In this paper, we propose a novel feature vector (called a Skip vector) that represents some features of each resource in an RDF graph by extracting various combinations of neighboring edges and nodes. In order to make the Skip vector low-dimensional, we select important features for classification tasks based on the information gain ratio of each feature. The classification tasks can be performed by applying the low-dimensional Skip vector of each resource to conventional machine learning algorithms, such as SVMs, the k-nearest neighbors method, neural networks, random forests, and AdaBoost. In our evaluation experiments with RDF data, such as Wikidata, DBpedia, and YAGO, we compare our method with RDF graph kernels in an SVM. We also compare our method with the two approaches: RDF graph embeddings such as RDF2vec and relational graph convolutional networks on the AIFB, MUTAG, BGS, and AM benchmarks.