 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Lower Bounds for Learning in Revealing POMDPs
Feb 02, 2023

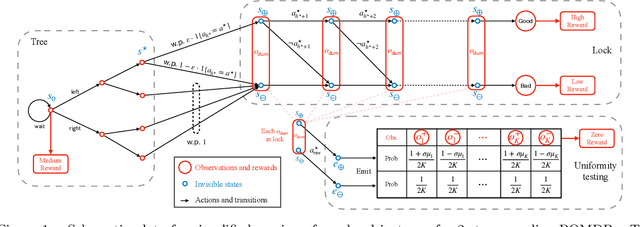
This paper studies the fundamental limits of reinforcement learning (RL) in the challenging \emph{partially observable} setting. While it is well-established that learning in Partially Observable Markov Decision Processes (POMDPs) requires exponentially many samples in the worst case, a surge of recent work shows that polynomial sample complexities are achievable under the \emph{revealing condition} -- A natural condition that requires the observables to reveal some information about the unobserved latent states. However, the fundamental limits for learning in revealing POMDPs are much less understood, with existing lower bounds being rather preliminary and having substantial gaps from the current best upper bounds. We establish strong PAC and regret lower bounds for learning in revealing POMDPs. Our lower bounds scale polynomially in all relevant problem parameters in a multiplicative fashion, and achieve significantly smaller gaps against the current best upper bounds, providing a solid starting point for future studies. In particular, for \emph{multi-step} revealing POMDPs, we show that (1) the latent state-space dependence is at least $\Omega(S^{1.5})$ in the PAC sample complexity, which is notably harder than the $\widetilde{\Theta}(S)$ scaling for fully-observable MDPs; (2) Any polynomial sublinear regret is at least $\Omega(T^{2/3})$, suggesting its fundamental difference from the \emph{single-step} case where $\widetilde{O}(\sqrt{T})$ regret is achievable. Technically, our hard instance construction adapts techniques in \emph{distribution testing}, which is new to the RL literature and may be of independent interest.
Timely Opportunistic Gossiping in Dense Networks
Jan 02, 2023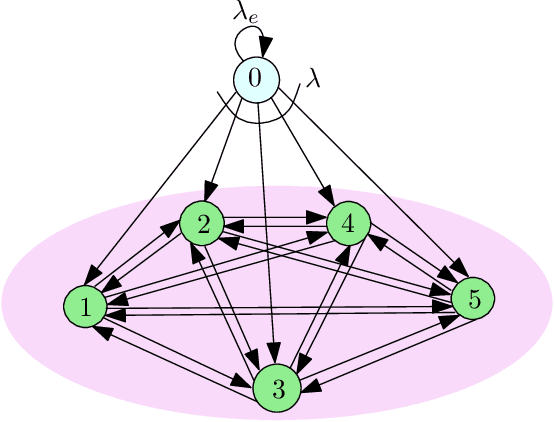
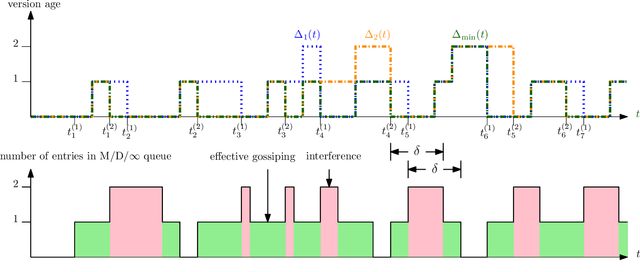

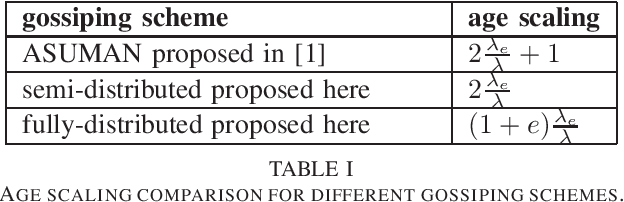
We consider gossiping in a fully-connected wireless network consisting of $n$ nodes. The network receives Poisson updates from a source, which generates new information. The nodes gossip their available information with the neighboring nodes to maintain network timeliness. In this work, we propose two gossiping schemes, one semi-distributed and the other one fully-distributed. In the semi-distributed scheme, the freshest nodes use pilot signals to interact with the network and gossip with the full available update rate $B$. In the fully-distributed scheme, each node gossips for a fixed amount of time duration with the full update rate $B$. Both schemes achieve $O(1)$ age scaling, and the semi-distributed scheme has the best age performance for any symmetric randomized gossiping policy. We compare the results with the recently proposed ASUMAN scheme, which also gives $O(1)$ age performance, but the nodes need to be age-aware.
PIER: Permutation-Level Interest-Based End-to-End Re-ranking Framework in E-commerce
Feb 06, 2023

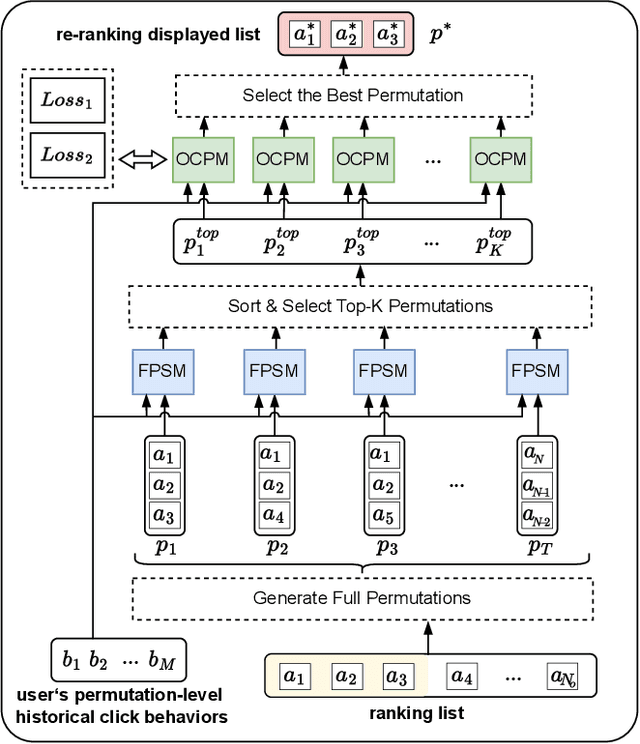
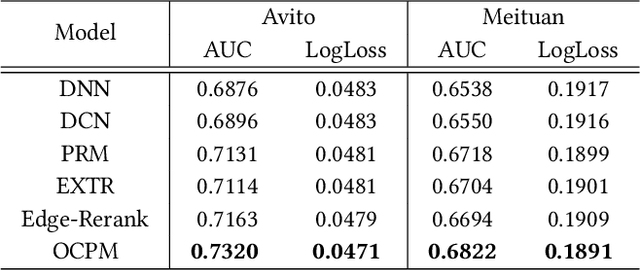
Re-ranking draws increased attention on both academics and industries, which rearranges the ranking list by modeling the mutual influence among items to better meet users' demands. Many existing re-ranking methods directly take the initial ranking list as input, and generate the optimal permutation through a well-designed context-wise model, which brings the evaluation-before-reranking problem. Meanwhile, evaluating all candidate permutations brings unacceptable computational costs in practice. Thus, to better balance efficiency and effectiveness, online systems usually use a two-stage architecture which uses some heuristic methods such as beam-search to generate a suitable amount of candidate permutations firstly, which are then fed into the evaluation model to get the optimal permutation. However, existing methods in both stages can be improved through the following aspects. As for generation stage, heuristic methods only use point-wise prediction scores and lack an effective judgment. As for evaluation stage, most existing context-wise evaluation models only consider the item context and lack more fine-grained feature context modeling. This paper presents a novel end-to-end re-ranking framework named PIER to tackle the above challenges which still follows the two-stage architecture and contains two mainly modules named FPSM and OCPM. We apply SimHash in FPSM to select top-K candidates from the full permutation based on user's permutation-level interest in an efficient way. Then we design a novel omnidirectional attention mechanism in OCPM to capture the context information in the permutation. Finally, we jointly train these two modules end-to-end by introducing a comparative learning loss. Offline experiment results demonstrate that PIER outperforms baseline models on both public and industrial datasets, and we have successfully deployed PIER on Meituan food delivery platform.
Explainable Multilayer Graph Neural Network for Cancer Gene Prediction
Jan 20, 2023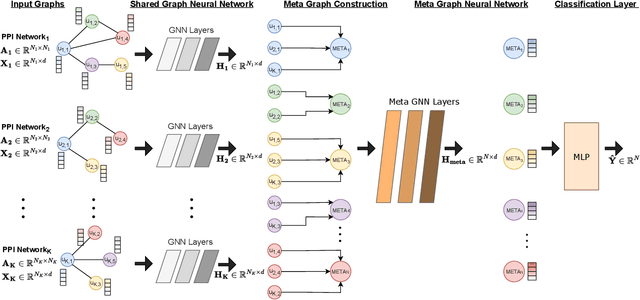
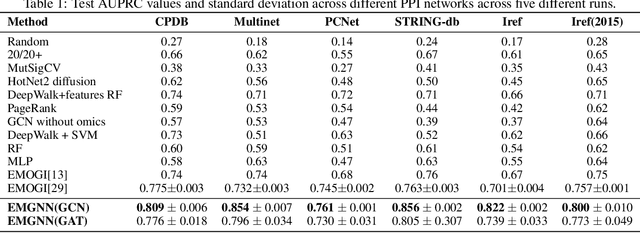
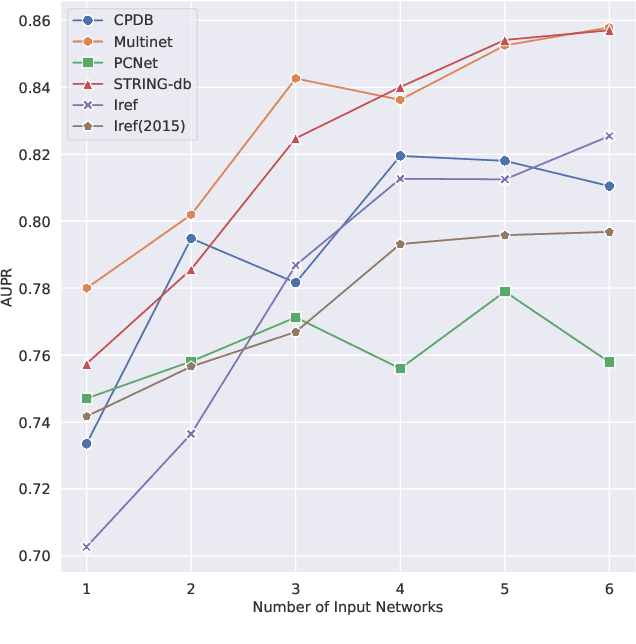

The identification of cancer genes is a critical, yet challenging problem in cancer genomics research. Recently, several computational methods have been developed to address this issue, including deep neural networks. However, these methods fail to exploit the multilayered gene-gene interactions and provide little to no explanation for their predictions. Results: In this study, we propose an Explainable Multilayer Graph Neural Network (EMGNN) approach to identify cancer genes, by leveraging multiple gene-gene interaction networks and multi-omics data. Compared to conventional graph learning methods, EMGNN learned complementary information in multiple graphs to accurately predict cancer genes. Our method consistently outperforms existing approaches while providing valuable biological insights into its predictions. We further release our novel cancer gene predictions and connect them with known cancer patterns, aiming to accelerate the progress of cancer research
Universal Multimodal Representation for Language Understanding
Jan 09, 2023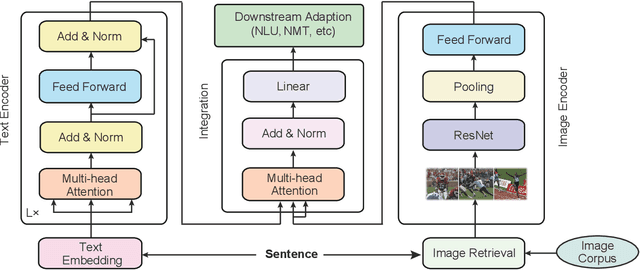
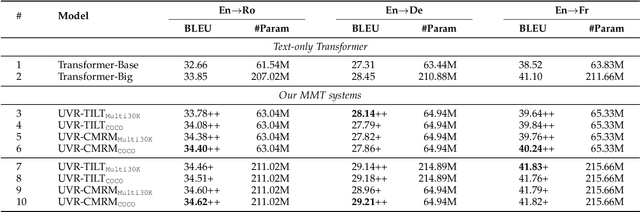
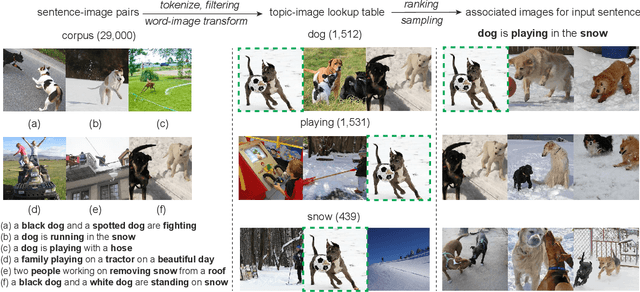

Representation learning is the foundation of natural language processing (NLP). This work presents new methods to employ visual information as assistant signals to general NLP tasks. For each sentence, we first retrieve a flexible number of images either from a light topic-image lookup table extracted over the existing sentence-image pairs or a shared cross-modal embedding space that is pre-trained on out-of-shelf text-image pairs. Then, the text and images are encoded by a Transformer encoder and convolutional neural network, respectively. The two sequences of representations are further fused by an attention layer for the interaction of the two modalities. In this study, the retrieval process is controllable and flexible. The universal visual representation overcomes the lack of large-scale bilingual sentence-image pairs. Our method can be easily applied to text-only tasks without manually annotated multimodal parallel corpora. We apply the proposed method to a wide range of natural language generation and understanding tasks, including neural machine translation, natural language inference, and semantic similarity. Experimental results show that our method is generally effective for different tasks and languages. Analysis indicates that the visual signals enrich textual representations of content words, provide fine-grained grounding information about the relationship between concepts and events, and potentially conduce to disambiguation.
Active Learning for Abstractive Text Summarization
Jan 09, 2023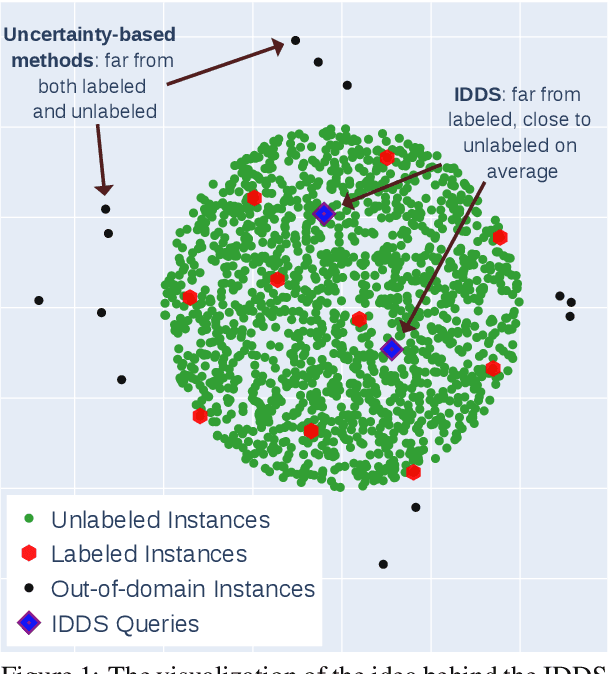

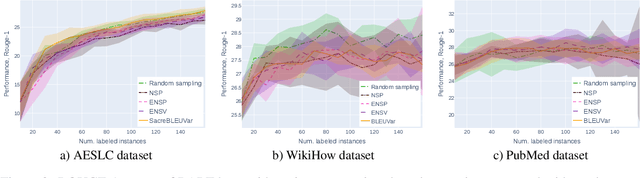
Construction of human-curated annotated datasets for abstractive text summarization (ATS) is very time-consuming and expensive because creating each instance requires a human annotator to read a long document and compose a shorter summary that would preserve the key information relayed by the original document. Active Learning (AL) is a technique developed to reduce the amount of annotation required to achieve a certain level of machine learning model performance. In information extraction and text classification, AL can reduce the amount of labor up to multiple times. Despite its potential for aiding expensive annotation, as far as we know, there were no effective AL query strategies for ATS. This stems from the fact that many AL strategies rely on uncertainty estimation, while as we show in our work, uncertain instances are usually noisy, and selecting them can degrade the model performance compared to passive annotation. We address this problem by proposing the first effective query strategy for AL in ATS based on diversity principles. We show that given a certain annotation budget, using our strategy in AL annotation helps to improve the model performance in terms of ROUGE and consistency scores. Additionally, we analyze the effect of self-learning and show that it can further increase the performance of the model.
Musical Information Extraction from the Singing Voice
Apr 07, 2022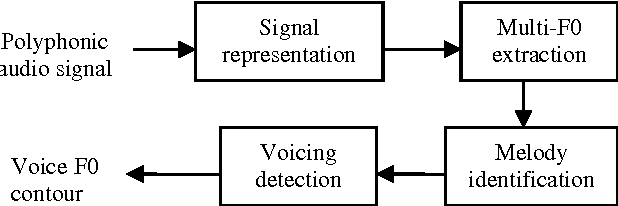

Music information retrieval is currently an active research area that addresses the extraction of musically important information from audio signals, and the applications of such information. The extracted information can be used for search and retrieval of music in recommendation systems, or to aid musicological studies or even in music learning. Sophisticated signal processing techniques are applied to convert low-level acoustic signal properties to musical attributes which are further embedded in a rule-based or statistical classification framework to link with high-level descriptions such as melody, genre, mood and artist type. Vocal music comprises a large and interesting category of music where the lead instrument is the singing voice. The singing voice is more versatile than many musical instruments and therefore poses interesting challenges to information retrieval systems. In this paper, we provide a brief overview of research in vocal music processing followed by a description of related work at IIT Bombay leading to the development of an interface for melody detection of singing voice in polyphony.
Multi-Stage Spatio-Temporal Aggregation Transformer for Video Person Re-identification
Jan 02, 2023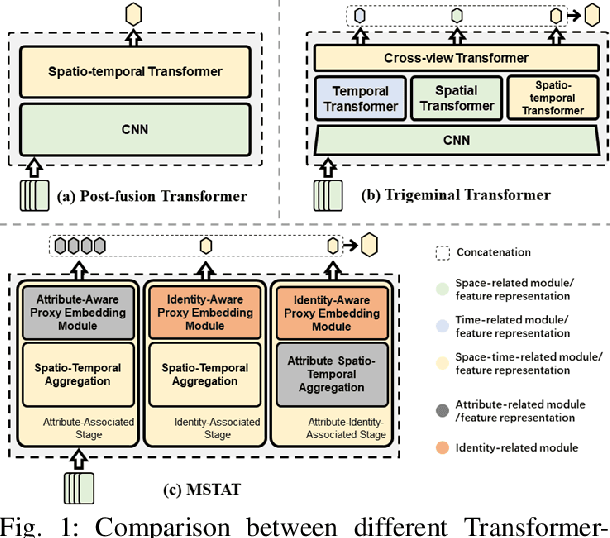
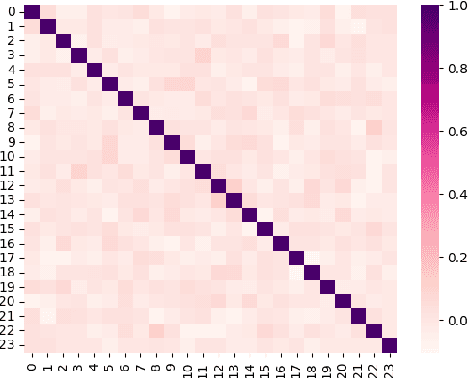

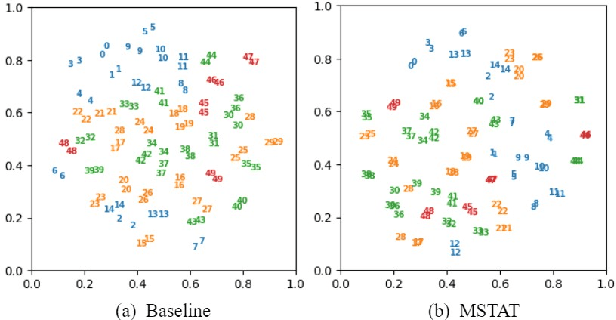
In recent years, the Transformer architecture has shown its superiority in the video-based person re-identification task. Inspired by video representation learning, these methods mainly focus on designing modules to extract informative spatial and temporal features. However, they are still limited in extracting local attributes and global identity information, which are critical for the person re-identification task. In this paper, we propose a novel Multi-Stage Spatial-Temporal Aggregation Transformer (MSTAT) with two novel designed proxy embedding modules to address the above issue. Specifically, MSTAT consists of three stages to encode the attribute-associated, the identity-associated, and the attribute-identity-associated information from the video clips, respectively, achieving the holistic perception of the input person. We combine the outputs of all the stages for the final identification. In practice, to save the computational cost, the Spatial-Temporal Aggregation (STA) modules are first adopted in each stage to conduct the self-attention operations along the spatial and temporal dimensions separately. We further introduce the Attribute-Aware and Identity-Aware Proxy embedding modules (AAP and IAP) to extract the informative and discriminative feature representations at different stages. All of them are realized by employing newly designed self-attention operations with specific meanings. Moreover, temporal patch shuffling is also introduced to further improve the robustness of the model. Extensive experimental results demonstrate the effectiveness of the proposed modules in extracting the informative and discriminative information from the videos, and illustrate the MSTAT can achieve state-of-the-art accuracies on various standard benchmarks.
Bayesian Hierarchical Models for Counterfactual Estimation
Jan 21, 2023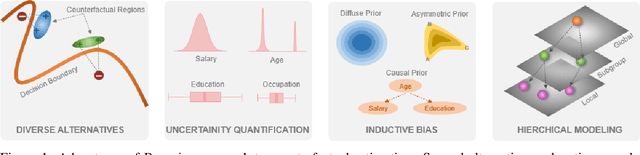
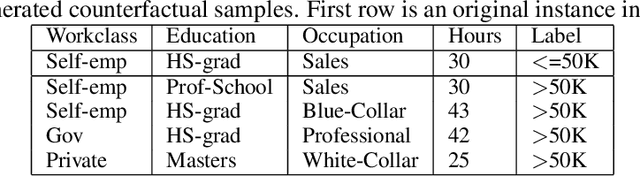
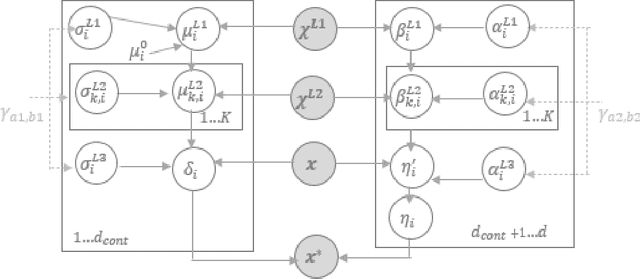
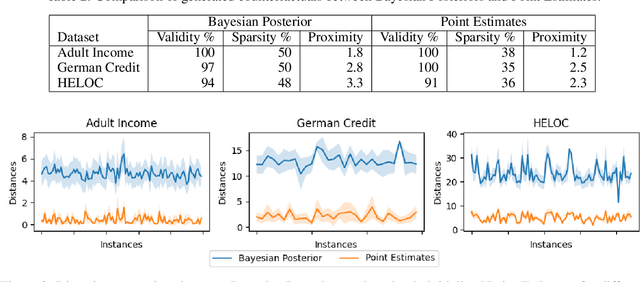
Counterfactual explanations utilize feature perturbations to analyze the outcome of an original decision and recommend an actionable recourse. We argue that it is beneficial to provide several alternative explanations rather than a single point solution and propose a probabilistic paradigm to estimate a diverse set of counterfactuals. Specifically, we treat the perturbations as random variables endowed with prior distribution functions. This allows sampling multiple counterfactuals from the posterior density, with the added benefit of incorporating inductive biases, preserving domain specific constraints and quantifying uncertainty in estimates. More importantly, we leverage Bayesian hierarchical modeling to share information across different subgroups of a population, which can both improve robustness and measure fairness. A gradient based sampler with superior convergence characteristics efficiently computes the posterior samples. Experiments across several datasets demonstrate that the counterfactuals estimated using our approach are valid, sparse, diverse and feasible.
Probably Anytime-Safe Stochastic Combinatorial Semi-Bandits
Jan 31, 2023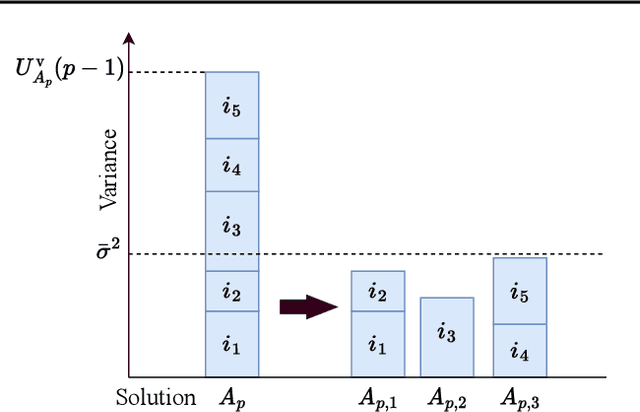
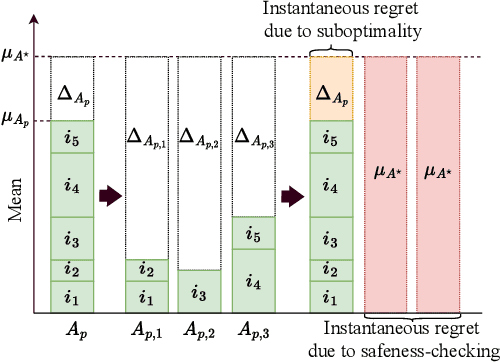
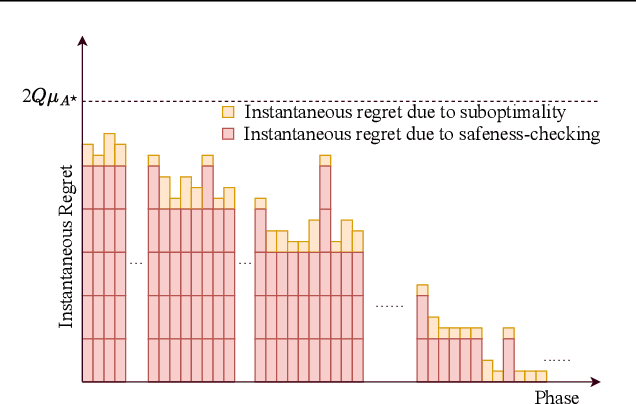

Motivated by concerns about making online decisions that incur undue amount of risk at each time step, in this paper, we formulate the probably anytime-safe stochastic combinatorial semi-bandits problem. In this problem, the agent is given the option to select a subset of size at most $K$ from a set of $L$ ground items. Each item is associated to a certain mean reward as well as a variance that represents its risk. To mitigate the risk that the agent incurs, we require that with probability at least $1-\delta$, over the entire horizon of time $T$, each of the choices that the agent makes should contain items whose sum of variances does not exceed a certain variance budget. We call this probably anytime-safe constraint. Under this constraint, we design and analyze an algorithm {\sc PASCombUCB} that minimizes the regret over the horizon of time $T$. By developing accompanying information-theoretic lower bounds, we show under both the problem-dependent and problem-independent paradigms, {\sc PASCombUCB} is almost asymptotically optimal. Our problem setup, the proposed {\sc PASCombUCB} algorithm, and novel analyses are applicable to domains such as recommendation systems and transportation in which an agent is allowed to choose multiple items at a single time step and wishes to control the risk over the whole time horizon.