 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Sequential Graph Attention Learning for Predicting Dynamic Stock Trends (Student Abstract)
Jan 15, 2023
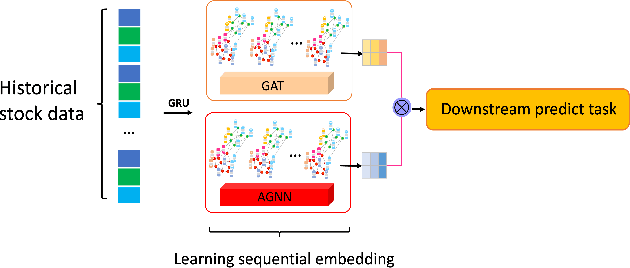
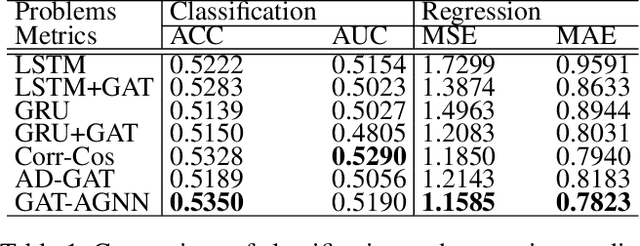

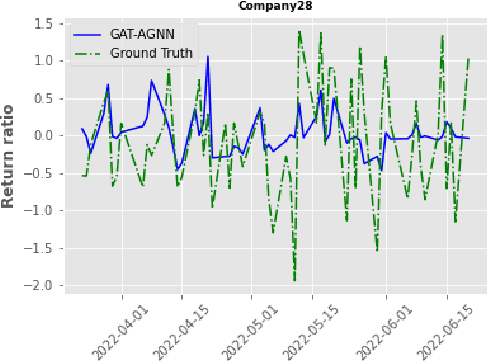
The stock market is characterized by a complex relationship between companies and the market. This study combines a sequential graph structure with attention mechanisms to learn global and local information within temporal time. Specifically, our proposed "GAT-AGNN" module compares model performance across multiple industries as well as within single industries. The results show that the proposed framework outperforms the state-of-the-art methods in predicting stock trends across multiple industries on Taiwan Stock datasets.
Look beyond labels: Incorporating functional summary information in Bayesian neural networks
Jul 04, 2022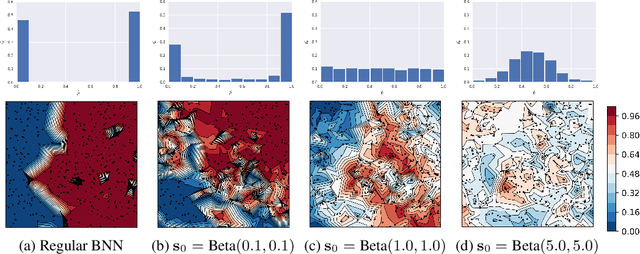
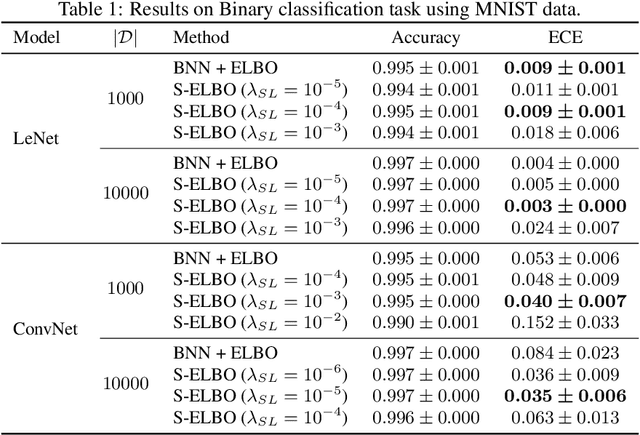
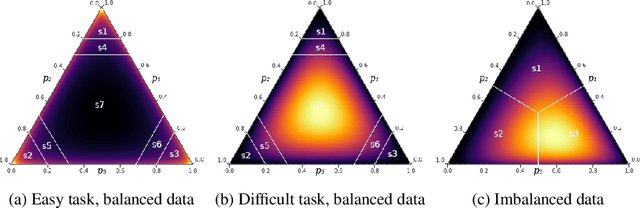
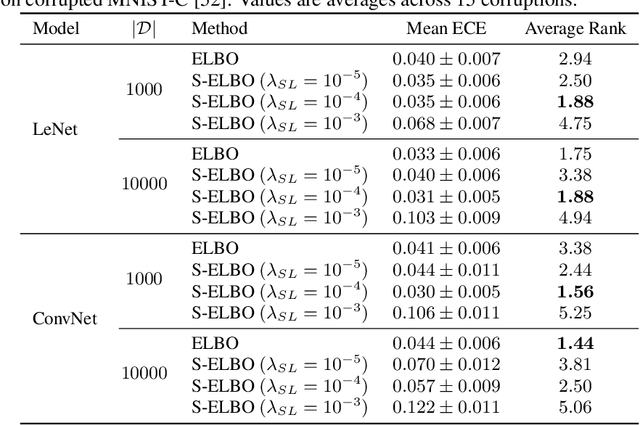
Bayesian deep learning offers a principled approach to train neural networks that accounts for both aleatoric and epistemic uncertainty. In variational inference, priors are often specified over the weight parameters, but they do not capture the true prior knowledge in large and complex neural network architectures. We present a simple approach to incorporate summary information about the predicted probability (such as sigmoid or softmax score) outputs in Bayesian neural networks (BNNs). The available summary information is incorporated as augmented data and modeled with a Dirichlet process, and we derive the corresponding \emph{Summary Evidence Lower BOund}. We show how the method can inform the model about task difficulty or class imbalance. Extensive empirical experiments show that, with negligible computational overhead, the proposed method yields a BNN with a better calibration of uncertainty.
Hierarchical Dynamic Masks for Visual Explanation of Neural Networks
Jan 12, 2023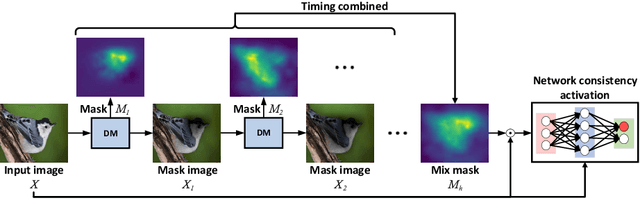
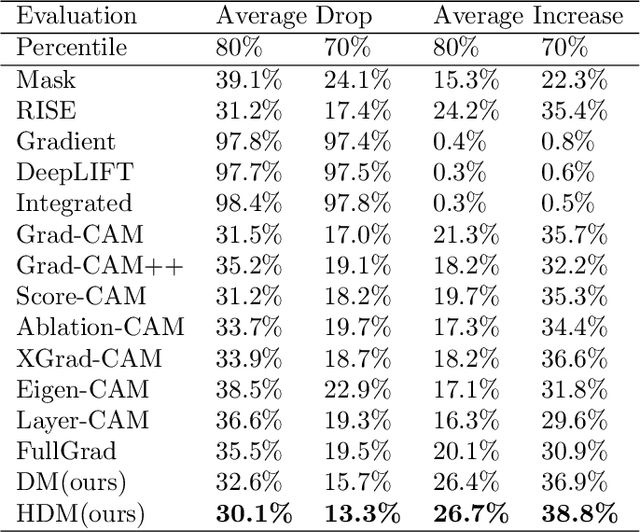

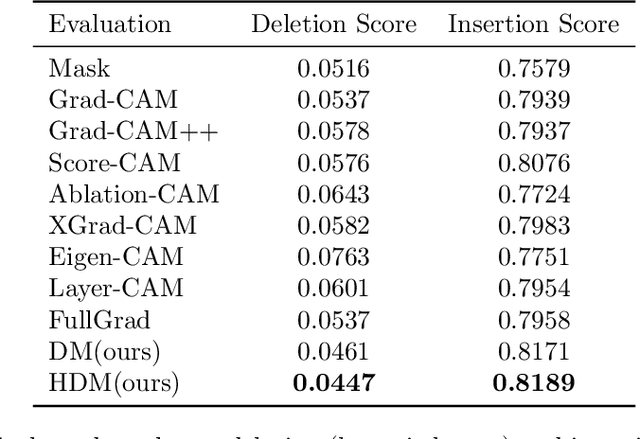
Saliency methods generating visual explanatory maps representing the importance of image pixels for model classification is a popular technique for explaining neural network decisions. Hierarchical dynamic masks (HDM), a novel explanatory maps generation method, is proposed in this paper to enhance the granularity and comprehensiveness of saliency maps. First, we suggest the dynamic masks (DM), which enables multiple small-sized benchmark mask vectors to roughly learn the critical information in the image through an optimization method. Then the benchmark mask vectors guide the learning of large-sized auxiliary mask vectors so that their superimposed mask can accurately learn fine-grained pixel importance information and reduce the sensitivity to adversarial perturbations. In addition, we construct the HDM by concatenating DM modules. These DM modules are used to find and fuse the regions of interest in the remaining neural network classification decisions in the mask image in a learning-based way. Since HDM forces DM to perform importance analysis in different areas, it makes the fused saliency map more comprehensive. The proposed method outperformed previous approaches significantly in terms of recognition and localization capabilities when tested on natural and medical datasets.
Cost Inference for Feedback Dynamic Games from Noisy Partial State Observations and Incomplete Trajectories
Jan 04, 2023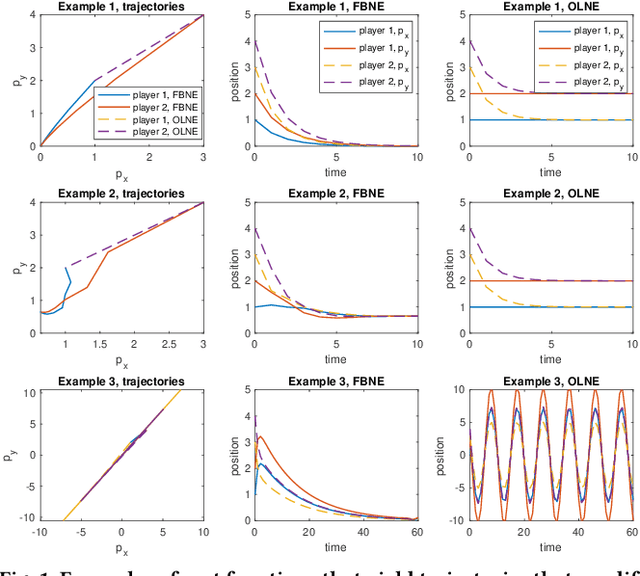
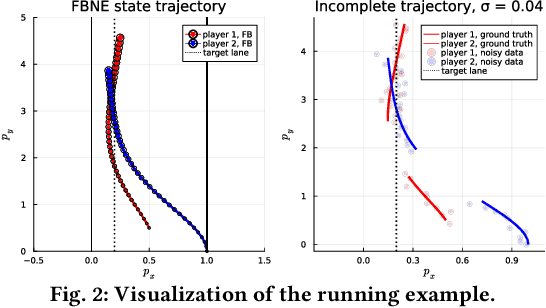
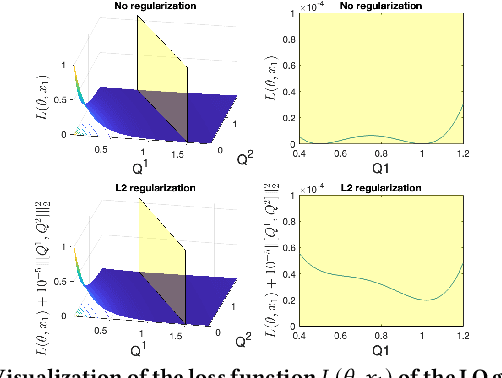
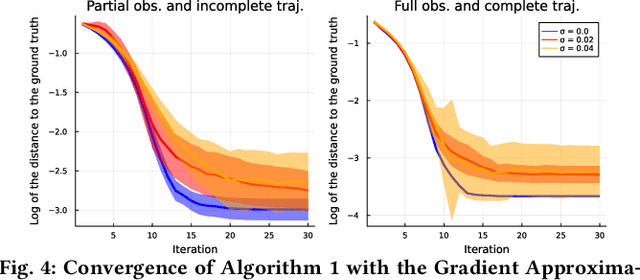
In multi-agent dynamic games, the Nash equilibrium state trajectory of each agent is determined by its cost function and the information pattern of the game. However, the cost and trajectory of each agent may be unavailable to the other agents. Prior work on using partial observations to infer the costs in dynamic games assumes an open-loop information pattern. In this work, we demonstrate that the feedback Nash equilibrium concept is more expressive and encodes more complex behavior. It is desirable to develop specific tools for inferring players' objectives in feedback games. Therefore, we consider the dynamic game cost inference problem under the feedback information pattern, using only partial state observations and incomplete trajectory data. To this end, we first propose an inverse feedback game loss function, whose minimizer yields a feedback Nash equilibrium state trajectory closest to the observation data. We characterize the landscape and differentiability of the loss function. Given the difficulty of obtaining the exact gradient, our main contribution is an efficient gradient approximator, which enables a novel inverse feedback game solver that minimizes the loss using first-order optimization. In thorough empirical evaluations, we demonstrate that our algorithm converges reliably and has better robustness and generalization performance than the open-loop baseline method when the observation data reflects a group of players acting in a feedback Nash game.
Neural Episodic Control with State Abstraction
Jan 27, 2023
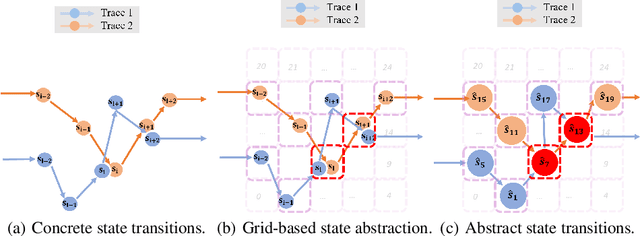
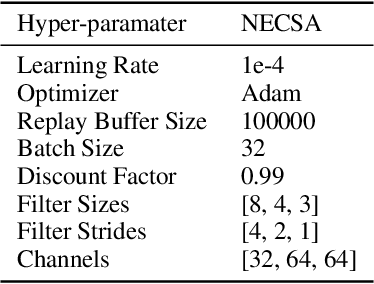
Existing Deep Reinforcement Learning (DRL) algorithms suffer from sample inefficiency. Generally, episodic control-based approaches are solutions that leverage highly-rewarded past experiences to improve sample efficiency of DRL algorithms. However, previous episodic control-based approaches fail to utilize the latent information from the historical behaviors (e.g., state transitions, topological similarities, etc.) and lack scalability during DRL training. This work introduces Neural Episodic Control with State Abstraction (NECSA), a simple but effective state abstraction-based episodic control containing a more comprehensive episodic memory, a novel state evaluation, and a multi-step state analysis. We evaluate our approach to the MuJoCo and Atari tasks in OpenAI gym domains. The experimental results indicate that NECSA achieves higher sample efficiency than the state-of-the-art episodic control-based approaches. Our data and code are available at the project website\footnote{\url{https://sites.google.com/view/drl-necsa}}.
Large Language Models Are Implicitly Topic Models: Explaining and Finding Good Demonstrations for In-Context Learning
Jan 27, 2023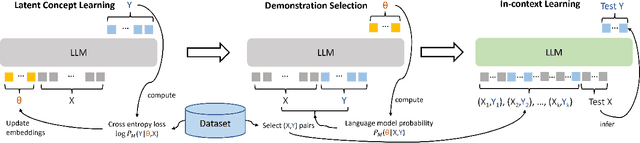
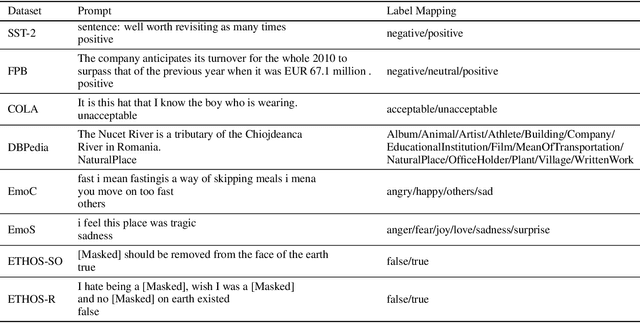
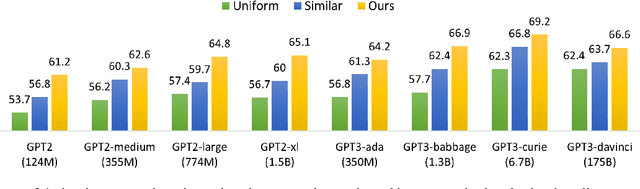
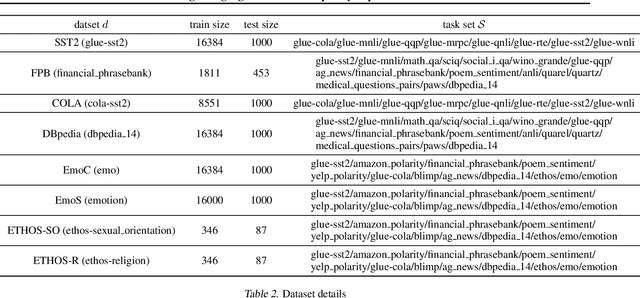
In recent years, pre-trained large language models have demonstrated remarkable efficiency in achieving an inference-time few-shot learning capability known as in-context learning. However, existing literature has highlighted the sensitivity of this capability to the selection of few-shot demonstrations. The underlying mechanisms by which this capability arises from regular language model pretraining objectives remain poorly understood. In this study, we aim to examine the in-context learning phenomenon through a Bayesian lens, viewing large language models as topic models that implicitly infer task-related information from demonstrations. On this premise, we propose an algorithm for selecting optimal demonstrations from a set of annotated data and demonstrate a significant 12.5% improvement relative to the random selection baseline, averaged over eight GPT2 and GPT3 models on eight different real-world text classification datasets. Our empirical findings support our hypothesis that large language models implicitly infer a latent concept variable.
A Watermark for Large Language Models
Jan 27, 2023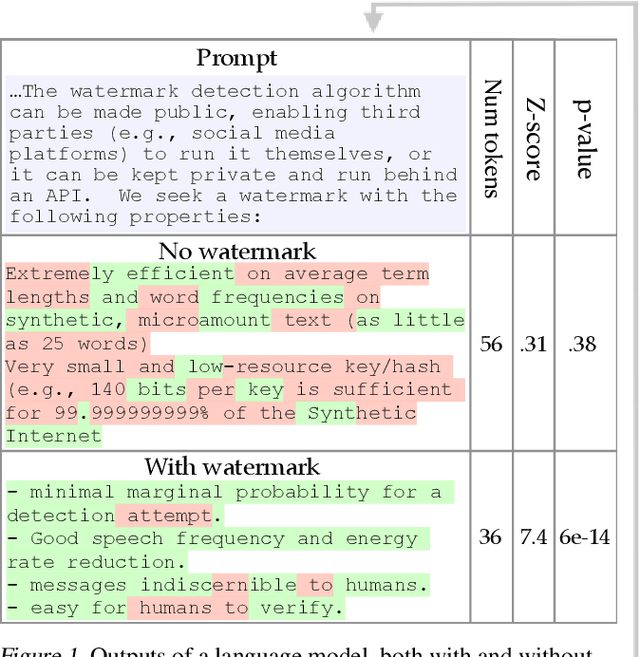
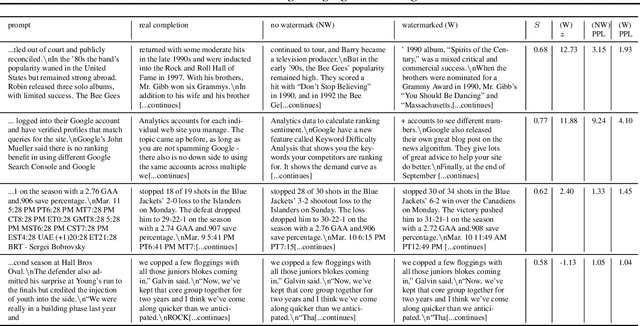
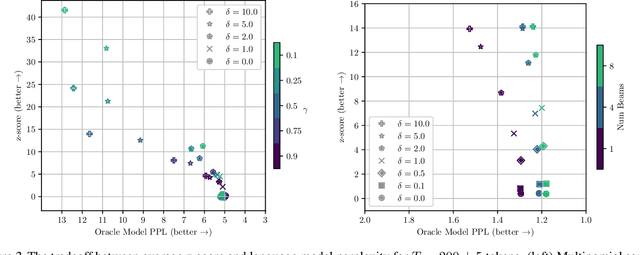
Potential harms of large language models can be mitigated by watermarking model output, i.e., embedding signals into generated text that are invisible to humans but algorithmically detectable from a short span of tokens. We propose a watermarking framework for proprietary language models. The watermark can be embedded with negligible impact on text quality, and can be detected using an efficient open-source algorithm without access to the language model API or parameters. The watermark works by selecting a randomized set of "green" tokens before a word is generated, and then softly promoting use of green tokens during sampling. We propose a statistical test for detecting the watermark with interpretable p-values, and derive an information-theoretic framework for analyzing the sensitivity of the watermark. We test the watermark using a multi-billion parameter model from the Open Pretrained Transformer (OPT) family, and discuss robustness and security.
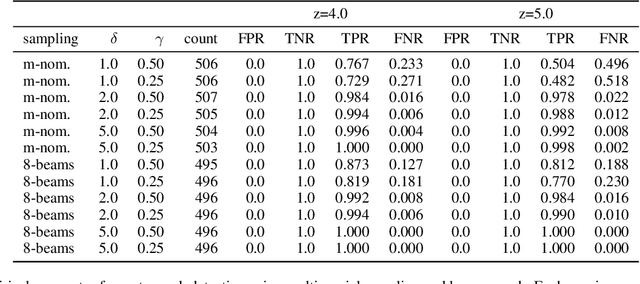
Open-Set Multi-Source Multi-Target Domain Adaptation
Feb 03, 2023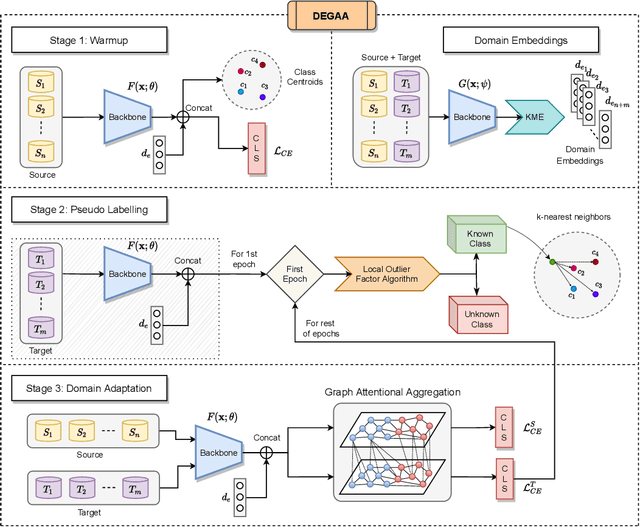
Single-Source Single-Target Domain Adaptation (1S1T) aims to bridge the gap between a labelled source domain and an unlabelled target domain. Despite 1S1T being a well-researched topic, they are typically not deployed to the real world. Methods like Multi-Source Domain Adaptation and Multi-Target Domain Adaptation have evolved to model real-world problems but still do not generalise well. The fact that most of these methods assume a common label-set between source and target is very restrictive. Recent Open-Set Domain Adaptation methods handle unknown target labels but fail to generalise in multiple domains. To overcome these difficulties, first, we propose a novel generic domain adaptation (DA) setting named Open-Set Multi-Source Multi-Target Domain Adaptation (OS-nSmT), with n and m being number of source and target domains respectively. Next, we propose a graph attention based framework named DEGAA which can capture information from multiple source and target domains without knowing the exact label-set of the target. We argue that our method, though offered for multiple sources and multiple targets, can also be agnostic to various other DA settings. To check the robustness and versatility of DEGAA, we put forward ample experiments and ablation studies.
CVTNet: A Cross-View Transformer Network for Place Recognition Using LiDAR Data
Feb 03, 2023
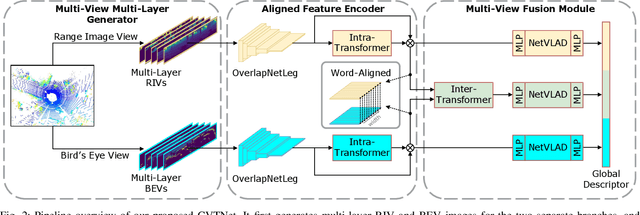
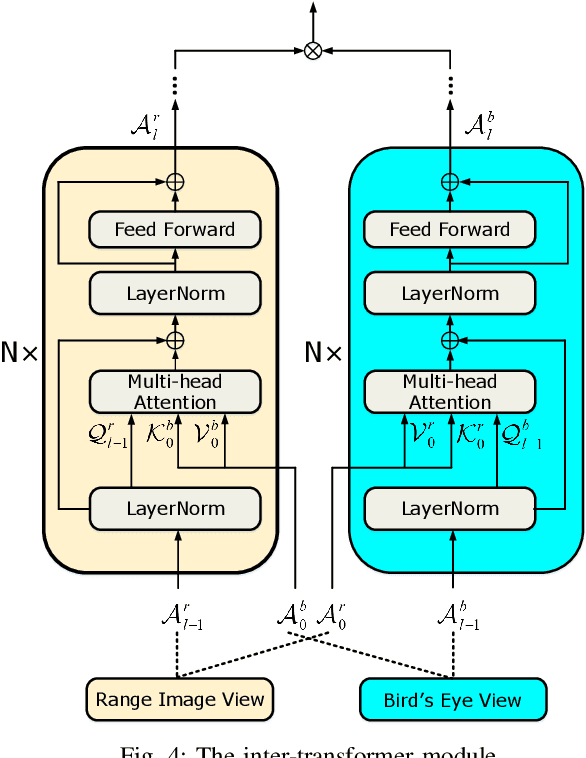
LiDAR-based place recognition (LPR) is one of the most crucial components of autonomous vehicles to identify previously visited places in GPS-denied environments. Most existing LPR methods use mundane representations of the input point cloud without considering different views, which may not fully exploit the information from LiDAR sensors. In this paper, we propose a cross-view transformer-based network, dubbed CVTNet, to fuse the range image views (RIVs) and bird's eye views (BEVs) generated from the LiDAR data. It extracts correlations within the views themselves using intra-transformers and between the two different views using inter-transformers. Based on that, our proposed CVTNet generates a yaw-angle-invariant global descriptor for each laser scan end-to-end online and retrieves previously seen places by descriptor matching between the current query scan and the pre-built database. We evaluate our approach on three datasets collected with different sensor setups and environmental conditions. The experimental results show that our method outperforms the state-of-the-art LPR methods with strong robustness to viewpoint changes and long-time spans. Furthermore, our approach has a good real-time performance that can run faster than the typical LiDAR frame rate. The implementation of our method is released as open source at: https://github.com/BIT-MJY/CVTNet.
Bridging the Emotional Semantic Gap via Multimodal Relevance Estimation
Feb 03, 2023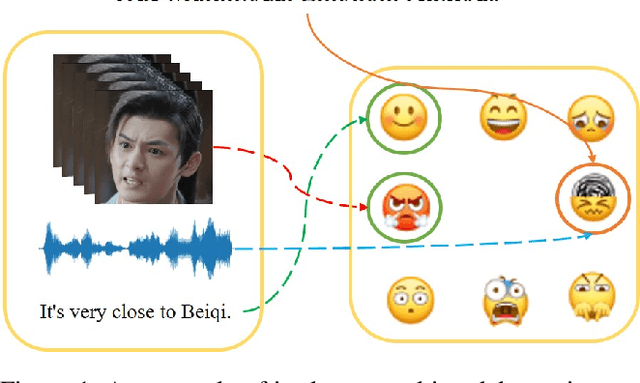

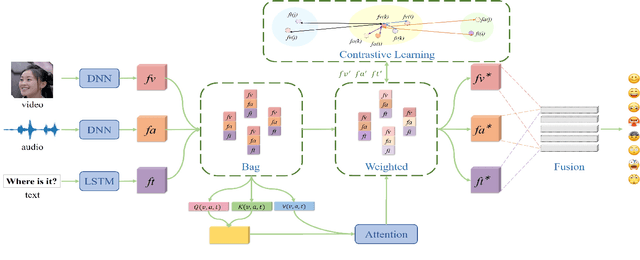
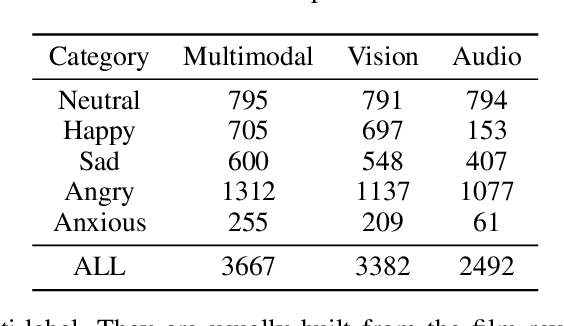
Human beings have rich ways of emotional expressions, including facial action, voice, and natural languages. Due to the diversity and complexity of different individuals, the emotions expressed by various modalities may be semantically irrelevant. Directly fusing information from different modalities may inevitably make the model subject to the noise from semantically irrelevant modalities. To tackle this problem, we propose a multimodal relevance estimation network to capture the relevant semantics among modalities in multimodal emotions. Specifically, we take advantage of an attention mechanism to reflect the semantic relevance weights of each modality. Moreover, we propose a relevant semantic estimation loss to weakly supervise the semantics of each modality. Furthermore, we make use of contrastive learning to optimize the similarity of category-level modality-relevant semantics across different modalities in feature space, thereby bridging the semantic gap between heterogeneous modalities. In order to better reflect the emotional state in the real interactive scenarios and perform the semantic relevance analysis, we collect a single-label discrete multimodal emotion dataset named SDME, which enables researchers to conduct multimodal semantic relevance research with large category bias. Experiments on continuous and discrete emotion datasets show that our model can effectively capture the relevant semantics, especially for the large deviations in modal semantics. The code and SDME dataset will be publicly available.