 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CTRLStruct: Dialogue Structure Learning for Open-Domain Response Generation
Mar 02, 2023
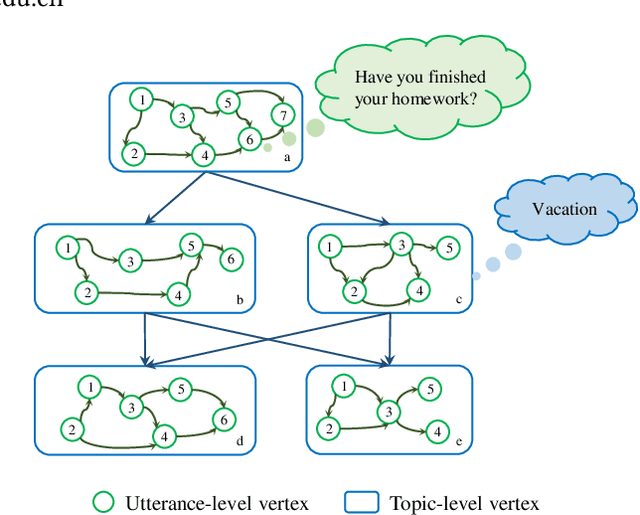
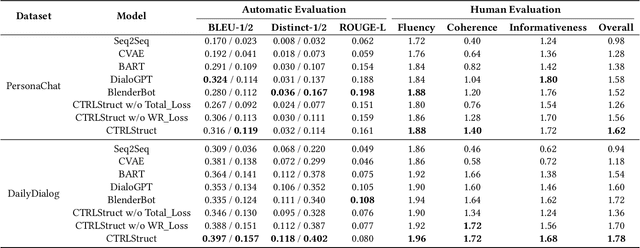
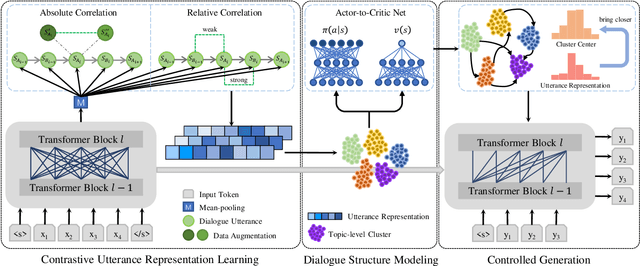
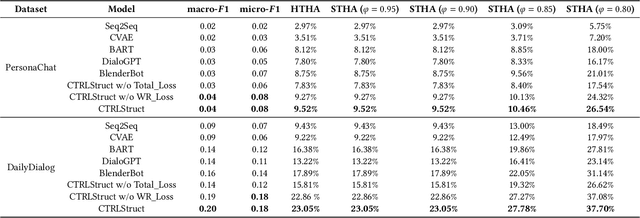
Dialogue structure discovery is essential in dialogue generation. Well-structured topic flow can leverage background information and predict future topics to help generate controllable and explainable responses. However, most previous work focused on dialogue structure learning in task-oriented dialogue other than open-domain dialogue which is more complicated and challenging. In this paper, we present a new framework CTRLStruct for dialogue structure learning to effectively explore topic-level dialogue clusters as well as their transitions with unlabelled information. Precisely, dialogue utterances encoded by bi-directional Transformer are further trained through a special designed contrastive learning task to improve representation. Then we perform clustering to utterance-level representations and form topic-level clusters that can be considered as vertices in dialogue structure graph. The edges in the graph indicating transition probability between vertices are calculated by mimicking expert behavior in datasets. Finally, dialogue structure graph is integrated into dialogue model to perform controlled response generation. Experiments on two popular open-domain dialogue datasets show our model can generate more coherent responses compared to some excellent dialogue models, as well as outperform some typical sentence embedding methods in dialogue utterance representation. Code is available in GitHub.
Heterogeneous Graph Contrastive Learning for Recommendation
Mar 02, 2023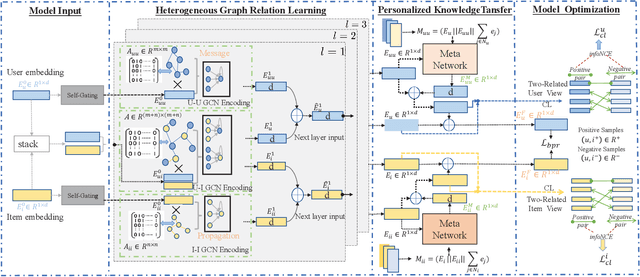

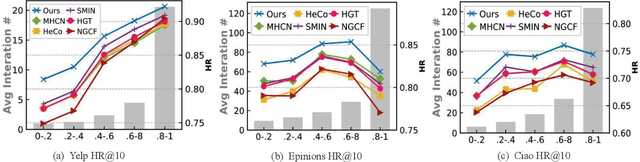
Graph Neural Networks (GNNs) have become powerful tools in modeling graph-structured data in recommender systems. However, real-life recommendation scenarios usually involve heterogeneous relationships (e.g., social-aware user influence, knowledge-aware item dependency) which contains fruitful information to enhance the user preference learning. In this paper, we study the problem of heterogeneous graph-enhanced relational learning for recommendation. Recently, contrastive self-supervised learning has become successful in recommendation. In light of this, we propose a Heterogeneous Graph Contrastive Learning (HGCL), which is able to incorporate heterogeneous relational semantics into the user-item interaction modeling with contrastive learning-enhanced knowledge transfer across different views. However, the influence of heterogeneous side information on interactions may vary by users and items. To move this idea forward, we enhance our heterogeneous graph contrastive learning with meta networks to allow the personalized knowledge transformer with adaptive contrastive augmentation. The experimental results on three real-world datasets demonstrate the superiority of HGCL over state-of-the-art recommendation methods. Through ablation study, key components in HGCL method are validated to benefit the recommendation performance improvement. The source code of the model implementation is available at the link https://github.com/HKUDS/HGCL.
FlowFormer++: Masked Cost Volume Autoencoding for Pretraining Optical Flow Estimation
Mar 02, 2023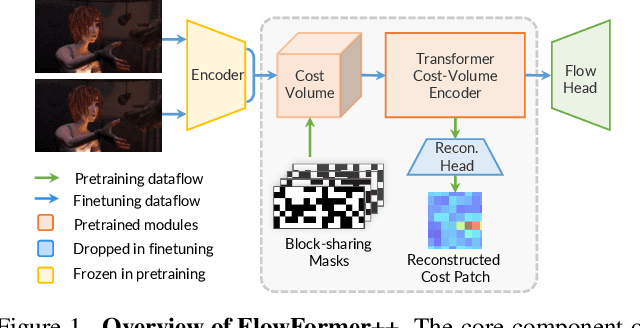
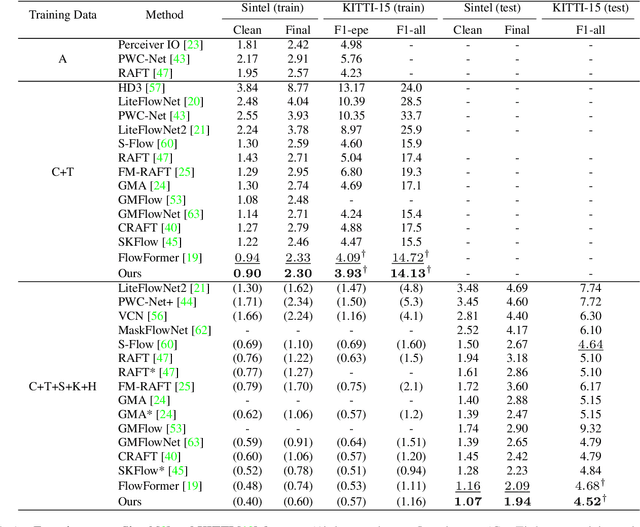
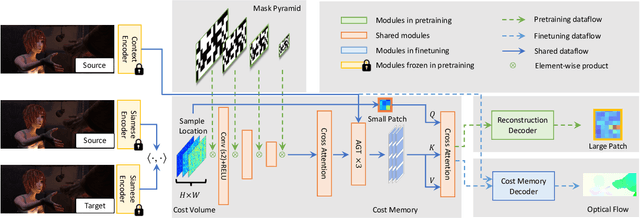
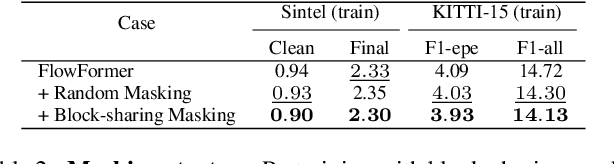
FlowFormer introduces a transformer architecture into optical flow estimation and achieves state-of-the-art performance. The core component of FlowFormer is the transformer-based cost-volume encoder. Inspired by the recent success of masked autoencoding (MAE) pretraining in unleashing transformers' capacity of encoding visual representation, we propose Masked Cost Volume Autoencoding (MCVA) to enhance FlowFormer by pretraining the cost-volume encoder with a novel MAE scheme. Firstly, we introduce a block-sharing masking strategy to prevent masked information leakage, as the cost maps of neighboring source pixels are highly correlated. Secondly, we propose a novel pre-text reconstruction task, which encourages the cost-volume encoder to aggregate long-range information and ensures pretraining-finetuning consistency. We also show how to modify the FlowFormer architecture to accommodate masks during pretraining. Pretrained with MCVA, FlowFormer++ ranks 1st among published methods on both Sintel and KITTI-2015 benchmarks. Specifically, FlowFormer++ achieves 1.07 and 1.94 average end-point error (AEPE) on the clean and final pass of Sintel benchmark, leading to 7.76\% and 7.18\% error reductions from FlowFormer. FlowFormer++ obtains 4.52 F1-all on the KITTI-2015 test set, improving FlowFormer by 0.16.
Anchor Free remote sensing detector based on solving discrete polar coordinate equation
Mar 25, 2023
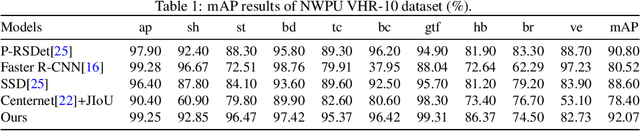
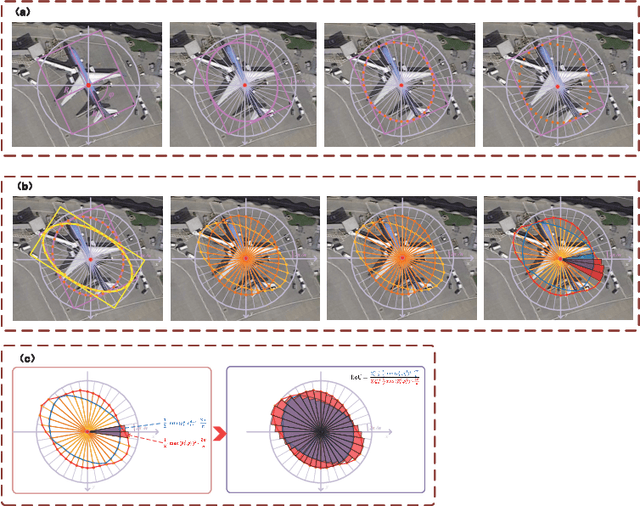
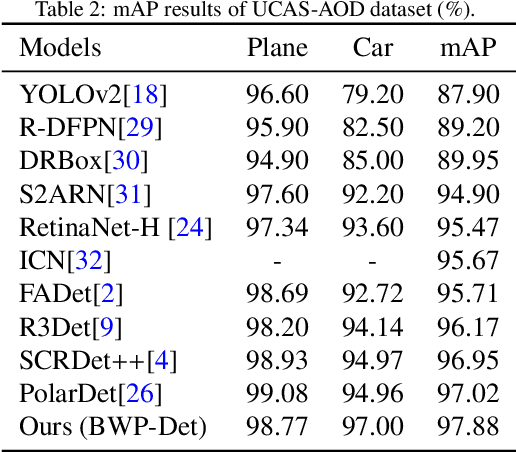
As the rapid development of depth learning, object detection in aviatic remote sensing images has become increasingly popular in recent years. Most of the current Anchor Free detectors based on key point detection sampling directly regression and classification features, with the design of object loss function based on the horizontal bounding box. It is more challenging for complex and diverse aviatic remote sensing object. In this paper, we propose an Anchor Free aviatic remote sensing object detector (BWP-Det) to detect rotating and multi-scale object. Specifically, we design a interactive double-branch(IDB) up-sampling network, in which one branch gradually up-sampling is used for the prediction of Heatmap, and the other branch is used for the regression of boundary box parameters. We improve a weighted multi-scale convolution (WmConv) in order to highlight the difference between foreground and background. We extracted Pixel level attention features from the middle layer to guide the two branches to pay attention to effective object information in the sampling process. Finally, referring to the calculation idea of horizontal IoU, we design a rotating IoU based on the split polar coordinate plane, namely JIoU, which is expressed as the intersection ratio following discretization of the inner ellipse of the rotating bounding box, to solve the correlation between angle and side length in the regression process of the rotating bounding box. Ultimately, BWP-Det, our experiments on DOTA, UCAS-AOD and NWPU VHR-10 datasets show, achieves advanced performance with simpler models and fewer regression parameters.
Adaptive Bi-Recommendation and Self-Improving Network for Heterogeneous Domain Adaptation-Assisted IoT Intrusion Detection
Mar 25, 2023
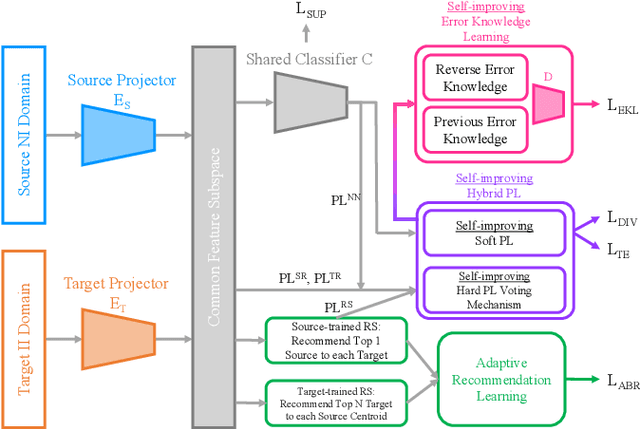
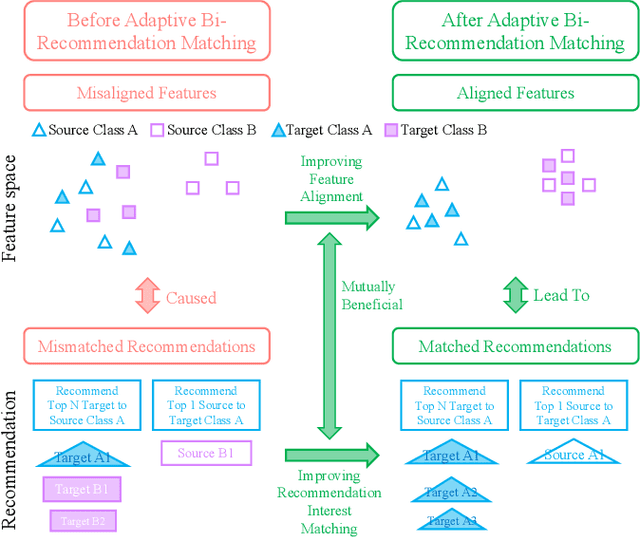
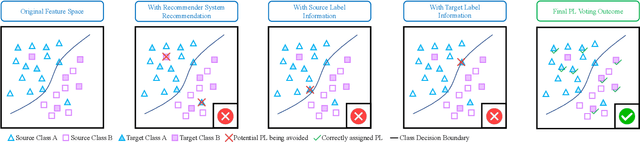
As Internet of Things devices become prevalent, using intrusion detection to protect IoT from malicious intrusions is of vital importance. However, the data scarcity of IoT hinders the effectiveness of traditional intrusion detection methods. To tackle this issue, in this paper, we propose the Adaptive Bi-Recommendation and Self-Improving Network (ABRSI) based on unsupervised heterogeneous domain adaptation (HDA). The ABRSI transfers enrich intrusion knowledge from a data-rich network intrusion source domain to facilitate effective intrusion detection for data-scarce IoT target domains. The ABRSI achieves fine-grained intrusion knowledge transfer via adaptive bi-recommendation matching. Matching the bi-recommendation interests of two recommender systems and the alignment of intrusion categories in the shared feature space form a mutual-benefit loop. Besides, the ABRSI uses a self-improving mechanism, autonomously improving the intrusion knowledge transfer from four ways. A hard pseudo label voting mechanism jointly considers recommender system decision and label relationship information to promote more accurate hard pseudo label assignment. To promote diversity and target data participation during intrusion knowledge transfer, target instances failing to be assigned with a hard pseudo label will be assigned with a probabilistic soft pseudo label, forming a hybrid pseudo-labelling strategy. Meanwhile, the ABRSI also makes soft pseudo-labels globally diverse and individually certain. Finally, an error knowledge learning mechanism is utilised to adversarially exploit factors that causes detection ambiguity and learns through both current and previous error knowledge, preventing error knowledge forgetfulness. Holistically, these mechanisms form the ABRSI model that boosts IoT intrusion detection accuracy via HDA-assisted intrusion knowledge transfer.
Class Cardinality Comparison as a Fermi Problem
Mar 08, 2023
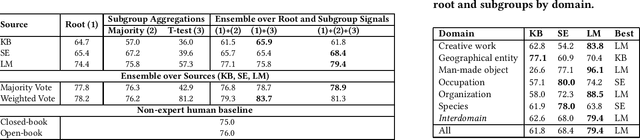

Questions on class cardinality comparisons are quite tricky to answer and come with its own challenges. They require some kind of reasoning since web documents and knowledge bases, indispensable sources of information, rarely store direct answers to questions, such as, ``Are there more astronauts or Physics Nobel Laureates?'' We tackle questions on class cardinality comparison by tapping into three sources for absolute cardinalities as well as the cardinalities of orthogonal subgroups of the classes. We propose novel techniques for aggregating signals with partial coverage for more reliable estimates and evaluate them on a dataset of 4005 class pairs, achieving an accuracy of 83.7%.
Deep Spiking Neural Networks with High Representation Similarity Model Visual Pathways of Macaque and Mouse
Mar 09, 2023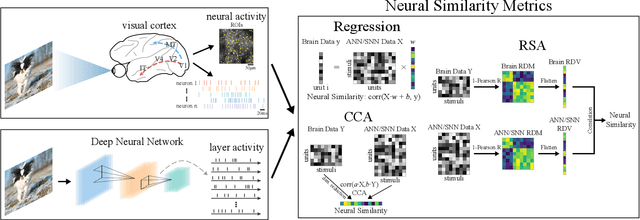

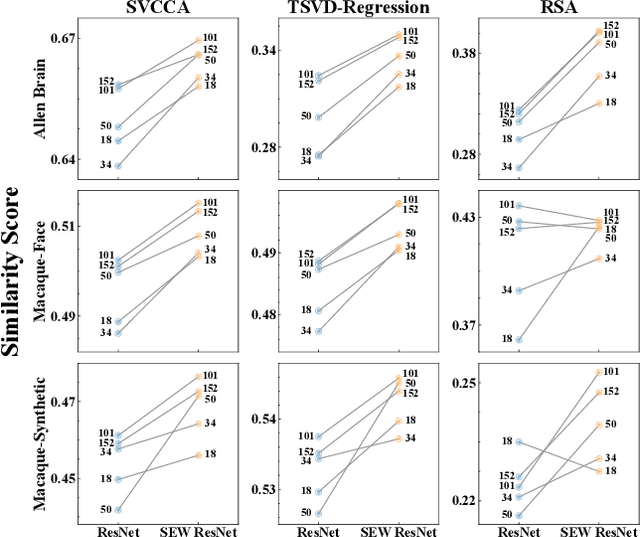

Deep artificial neural networks (ANNs) play a major role in modeling the visual pathways of primate and rodent. However, they highly simplify the computational properties of neurons compared to their biological counterparts. Instead, Spiking Neural Networks (SNNs) are more biologically plausible models since spiking neurons encode information with time sequences of spikes, just like biological neurons do. However, there is a lack of studies on visual pathways with deep SNNs models. In this study, we model the visual cortex with deep SNNs for the first time, and also with a wide range of state-of-the-art deep CNNs and ViTs for comparison. Using three similarity metrics, we conduct neural representation similarity experiments on three neural datasets collected from two species under three types of stimuli. Based on extensive similarity analyses, we further investigate the functional hierarchy and mechanisms across species. Almost all similarity scores of SNNs are higher than their counterparts of CNNs with an average of 6.6%. Depths of the layers with the highest similarity scores exhibit little differences across mouse cortical regions, but vary significantly across macaque regions, suggesting that the visual processing structure of mice is more regionally homogeneous than that of macaques. Besides, the multi-branch structures observed in some top mouse brain-like neural networks provide computational evidence of parallel processing streams in mice, and the different performance in fitting macaque neural representations under different stimuli exhibits the functional specialization of information processing in macaques. Taken together, our study demonstrates that SNNs could serve as promising candidates to better model and explain the functional hierarchy and mechanisms of the visual system.
Intent-based Deep Reinforcement Learning for Multi-agent Informative Path Planning
Mar 09, 2023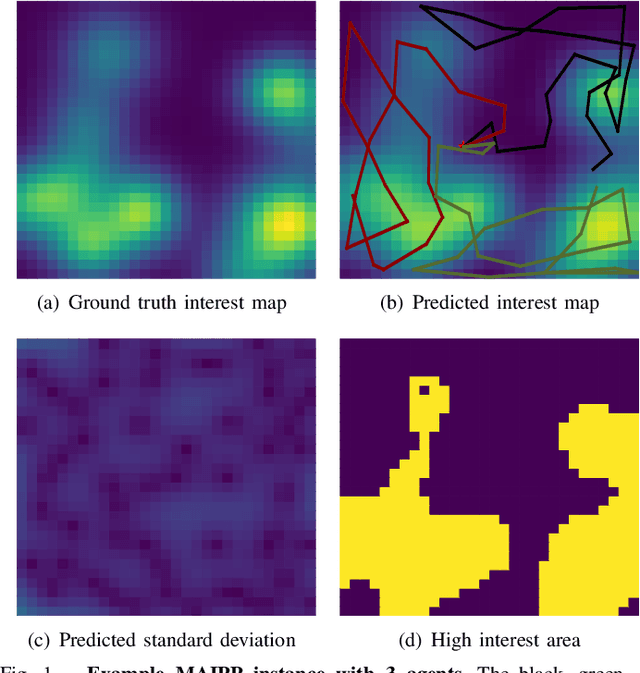
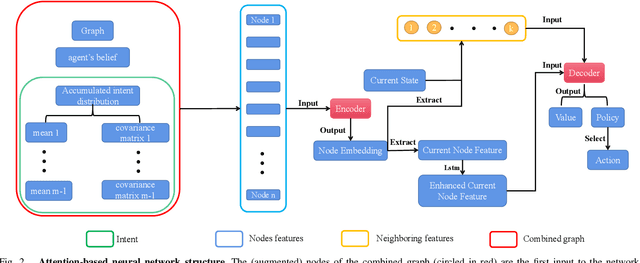
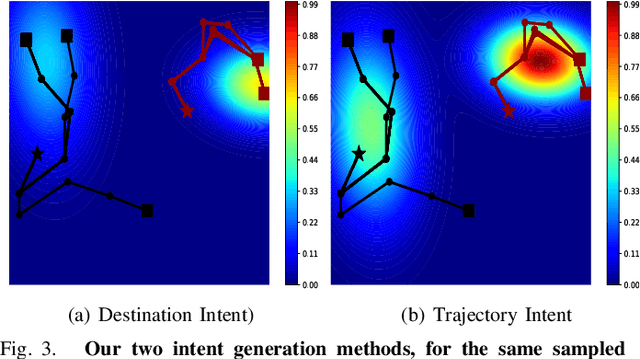
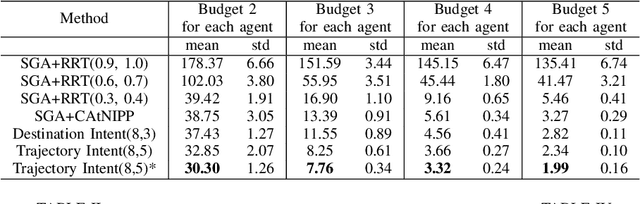
In multi-agent informative path planning (MAIPP), agents must collectively construct a global belief map of an underlying distribution of interest (e.g., gas concentration, light intensity, or pollution levels) over a given domain, based on measurements taken along their trajectory. They must frequently replan their path to balance the distributed exploration of new areas and the collective, meticulous exploitation of known high-interest areas, to maximize the information gained within a predefined budget (e.g., path length or working time). A common approach to achieving such cooperation relies on planning the agents' paths reactively, conditioned on other agents' future actions. However, as the agent's belief is updated continuously, these predicted future actions may not end up being the ones executed by agents, introducing a form of noise/inaccuracy in the system and often decreasing performance. In this work, we propose a decentralized deep reinforcement learning (DRL) approach to MAIPP, which relies on an attention-based neural network, where agents optimize long-term individual and cooperative objectives by explicitly sharing their intent (i.e., medium-/long-term future positions distribution, obtained from their individual policy) in a reactive, asynchronous manner. That is, in our work, intent sharing allows agents to learn to claim/avoid broader areas of the world. Moreover, since our approach relies on learned attention over these shared intents, agents are able to learn to recognize the useful portion(s) of these (imperfect) predictions to maximize cooperation even in the presence of imperfect information. Our comparison experiments demonstrate the performance of our approach compared to its variants and high-quality baselines over a large set of MAIPP simulations.
Semantic Communications with Variable-Length Coding for Extended Reality
Feb 17, 2023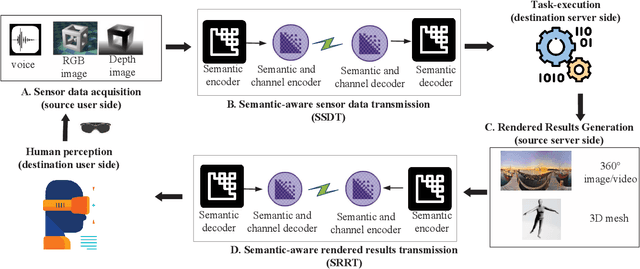
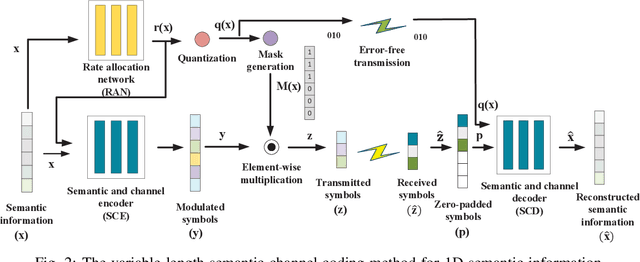
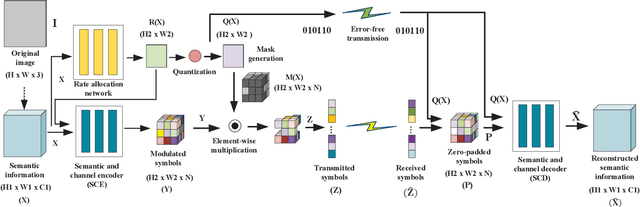
Wireless extended reality (XR) has attracted wide attentions as a promising technology to improve users' mobility and quality of experience. However, the ultra-high data rate requirement of wireless XR has hindered its development for many years. To overcome this challenge, we develop a semantic communication framework, where semantically-unimportant information is highly-compressed or discarded in semantic coders, significantly improving the transmission efficiency. Besides, considering the fact that some source content may have less amount of semantic information or have higher tolerance to channel noise, we propose a universal variable-length semantic-channel coding method. In particular, we first use a rate allocation network to estimate the best code length for semantic information and then adjust the coding process accordingly. By adopting some proxy functions, the whole framework is trained in an end-to-end manner. Numerical results show that our semantic system significantly outperforms traditional transmission methods and the proposed variable-length coding scheme is superior to the fixed-length coding methods.
Temporal Coherent Test-Time Optimization for Robust Video Classification
Feb 28, 2023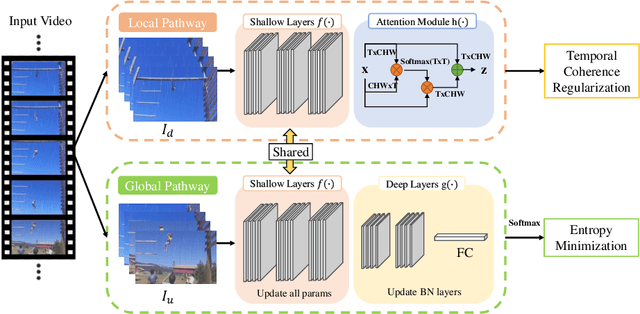
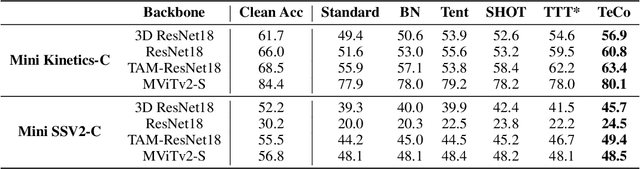
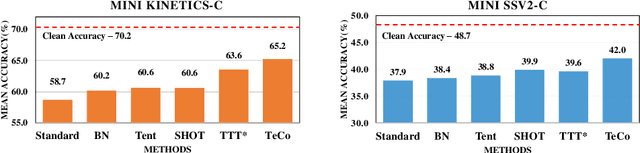

Deep neural networks are likely to fail when the test data is corrupted in real-world deployment (e.g., blur, weather, etc.). Test-time optimization is an effective way that adapts models to generalize to corrupted data during testing, which has been shown in the image domain. However, the techniques for improving video classification corruption robustness remain few. In this work, we propose a Temporal Coherent Test-time Optimization framework (TeCo) to utilize spatio-temporal information in test-time optimization for robust video classification. To exploit information in video with self-supervised learning, TeCo uses global content from video clips and optimizes models for entropy minimization. TeCo minimizes the entropy of the prediction based on the global content from video clips. Meanwhile, it also feeds local content to regularize the temporal coherence at the feature level. TeCo retains the generalization ability of various video classification models and achieves significant improvements in corruption robustness across Mini Kinetics-C and Mini SSV2-C. Furthermore, TeCo sets a new baseline in video classification corruption robustness via test-time optimization.