 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Spatially Adaptive Self-Supervised Learning for Real-World Image Denoising
Mar 27, 2023

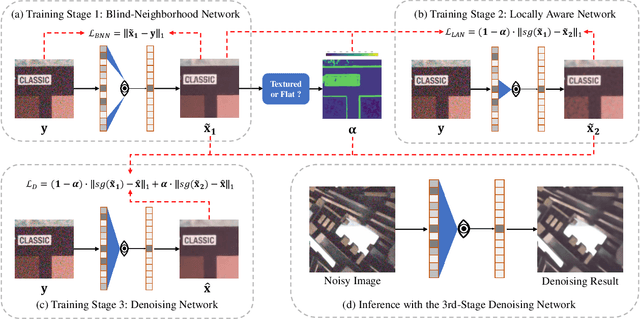
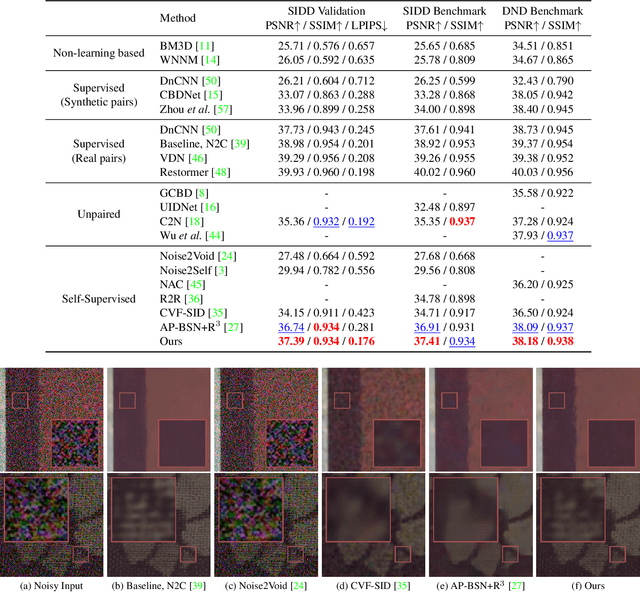
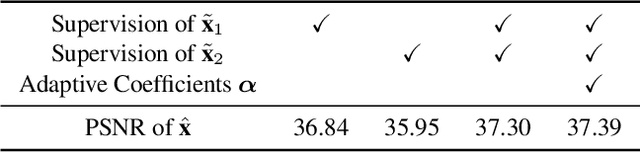
Significant progress has been made in self-supervised image denoising (SSID) in the recent few years. However, most methods focus on dealing with spatially independent noise, and they have little practicality on real-world sRGB images with spatially correlated noise. Although pixel-shuffle downsampling has been suggested for breaking the noise correlation, it breaks the original information of images, which limits the denoising performance. In this paper, we propose a novel perspective to solve this problem, i.e., seeking for spatially adaptive supervision for real-world sRGB image denoising. Specifically, we take into account the respective characteristics of flat and textured regions in noisy images, and construct supervisions for them separately. For flat areas, the supervision can be safely derived from non-adjacent pixels, which are much far from the current pixel for excluding the influence of the noise-correlated ones. And we extend the blind-spot network to a blind-neighborhood network (BNN) for providing supervision on flat areas. For textured regions, the supervision has to be closely related to the content of adjacent pixels. And we present a locally aware network (LAN) to meet the requirement, while LAN itself is selectively supervised with the output of BNN. Combining these two supervisions, a denoising network (e.g., U-Net) can be well-trained. Extensive experiments show that our method performs favorably against state-of-the-art SSID methods on real-world sRGB photographs. The code is available at https://github.com/nagejacob/SpatiallyAdaptiveSSID.
Mutually-paced Knowledge Distillation for Cross-lingual Temporal Knowledge Graph Reasoning
Mar 27, 2023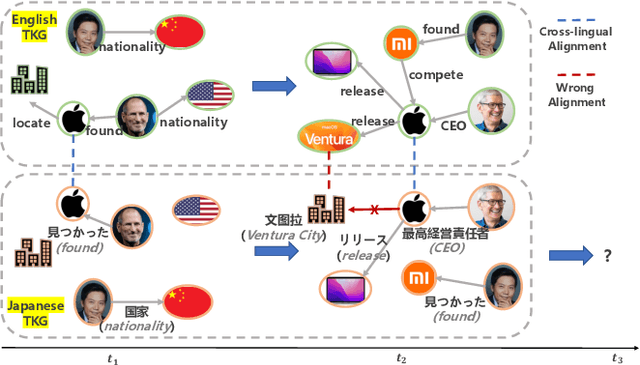

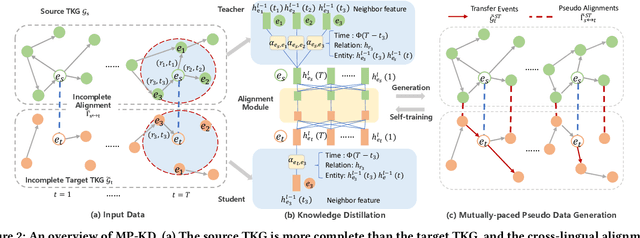
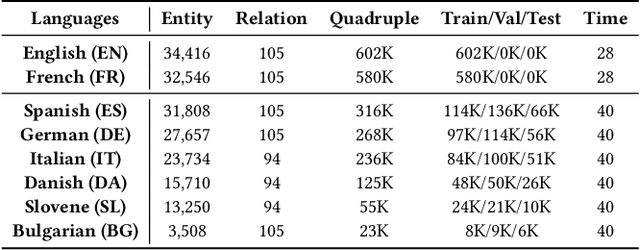
This paper investigates cross-lingual temporal knowledge graph reasoning problem, which aims to facilitate reasoning on Temporal Knowledge Graphs (TKGs) in low-resource languages by transfering knowledge from TKGs in high-resource ones. The cross-lingual distillation ability across TKGs becomes increasingly crucial, in light of the unsatisfying performance of existing reasoning methods on those severely incomplete TKGs, especially in low-resource languages. However, it poses tremendous challenges in two aspects. First, the cross-lingual alignments, which serve as bridges for knowledge transfer, are usually too scarce to transfer sufficient knowledge between two TKGs. Second, temporal knowledge discrepancy of the aligned entities, especially when alignments are unreliable, can mislead the knowledge distillation process. We correspondingly propose a mutually-paced knowledge distillation model MP-KD, where a teacher network trained on a source TKG can guide the training of a student network on target TKGs with an alignment module. Concretely, to deal with the scarcity issue, MP-KD generates pseudo alignments between TKGs based on the temporal information extracted by our representation module. To maximize the efficacy of knowledge transfer and control the noise caused by the temporal knowledge discrepancy, we enhance MP-KD with a temporal cross-lingual attention mechanism to dynamically estimate the alignment strength. The two procedures are mutually paced along with model training. Extensive experiments on twelve cross-lingual TKG transfer tasks in the EventKG benchmark demonstrate the effectiveness of the proposed MP-KD method.
Target-to-User Association in ISAC Systems With Vehicle-Lodged RIS
Mar 14, 2023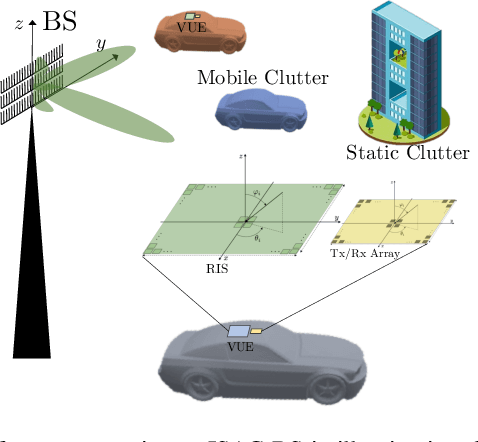
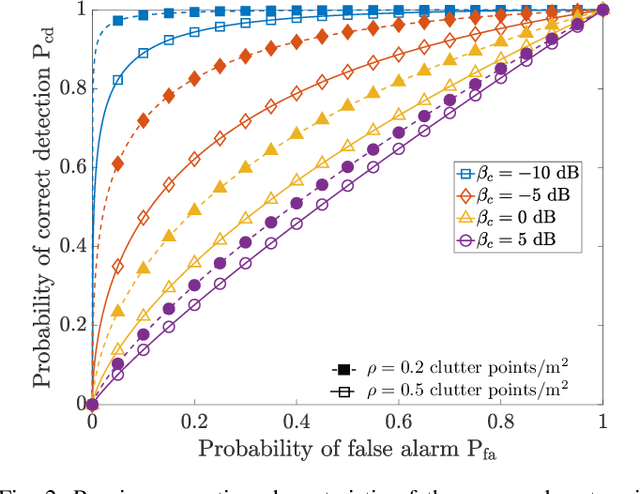
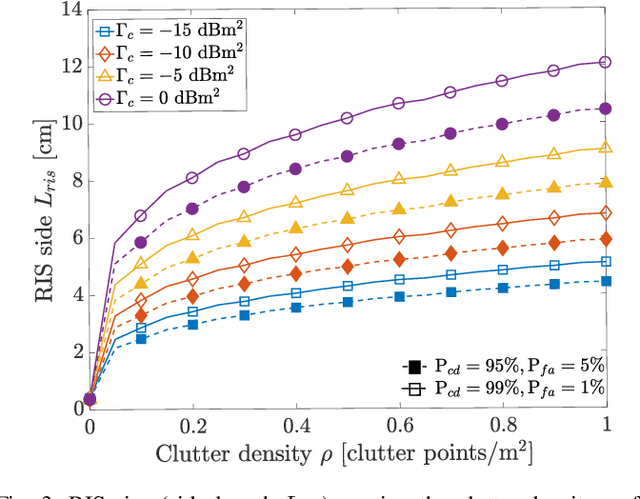
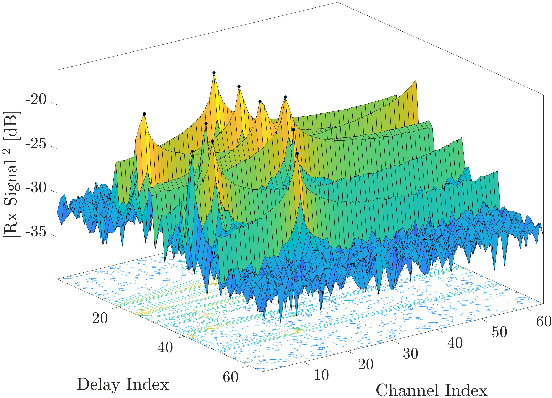
Target-to-user (T2U) association is a prerequisite to fully exploit the potential of the sensing function in communication-centric integrated sensing and communication (ISAC) systems, e.g., for beam and blockage management. This letter proposes to purposely mount a RIS on the roof of the vehicular user equipment (VUE), which can serve as an intentional back-reflector towards the base station. By controlling the reflection pattern over time, it is possible to transmit information to the sensing system, i.e., back-reflection as bit 1, no back-reflection as bit 0. The VUEs are configured to back-reflect a Hadamard code sequence, which enables T2U association. The numerical results confirm the validity of our proposal.
ForDigitStress: A multi-modal stress dataset employing a digital job interview scenario
Mar 14, 2023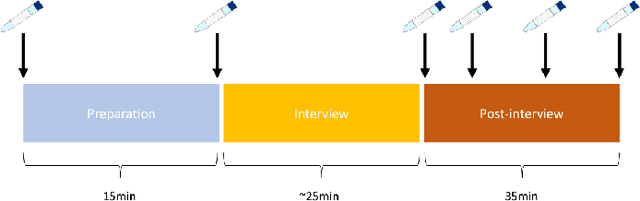
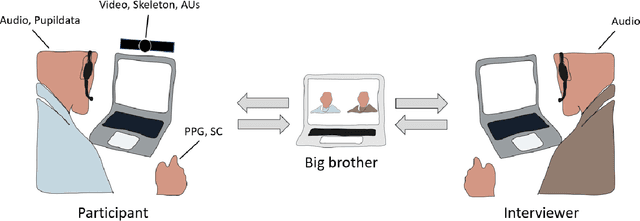
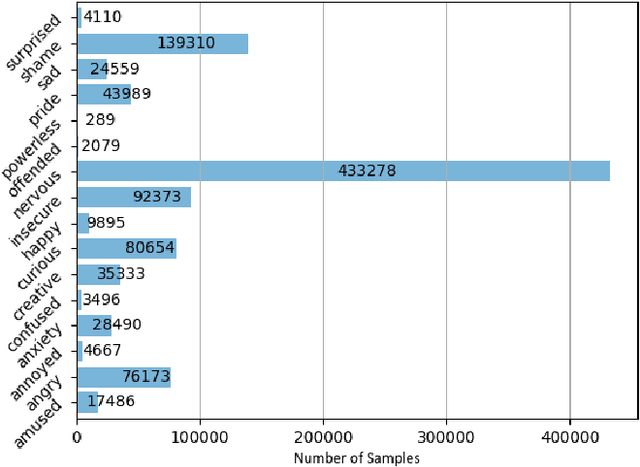
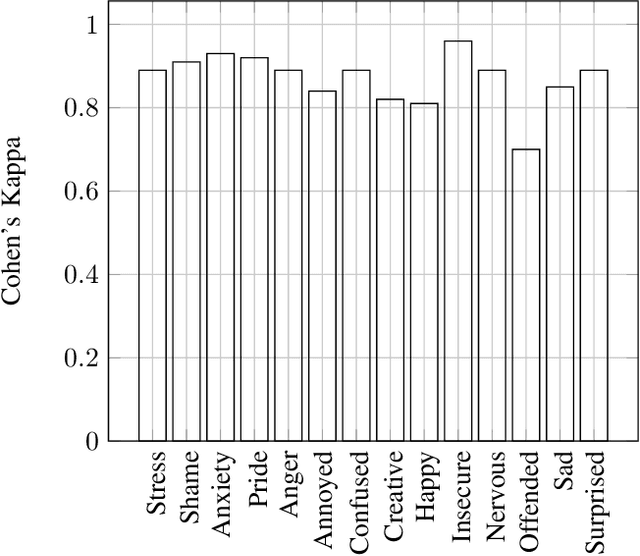
We present a multi-modal stress dataset that uses digital job interviews to induce stress. The dataset provides multi-modal data of 40 participants including audio, video (motion capturing, facial recognition, eye tracking) as well as physiological information (photoplethysmography, electrodermal activity). In addition to that, the dataset contains time-continuous annotations for stress and occurred emotions (e.g. shame, anger, anxiety, surprise). In order to establish a baseline, five different machine learning classifiers (Support Vector Machine, K-Nearest Neighbors, Random Forest, Long-Short-Term Memory Network) have been trained and evaluated on the proposed dataset for a binary stress classification task. The best-performing classifier achieved an accuracy of 88.3% and an F1-score of 87.5%.
TEA-PSE 3.0: Tencent-Ethereal-Audio-Lab Personalized Speech Enhancement System For ICASSP 2023 DNS Challenge
Mar 14, 2023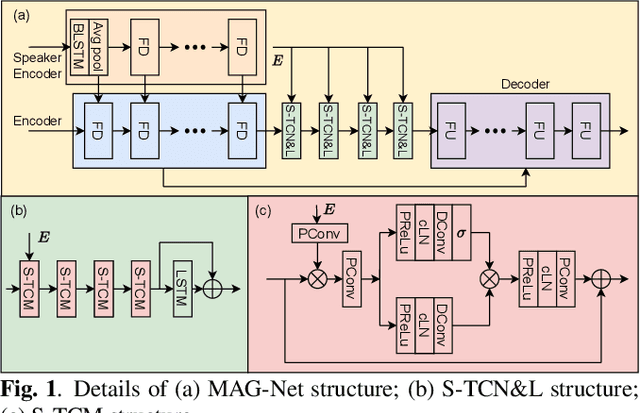
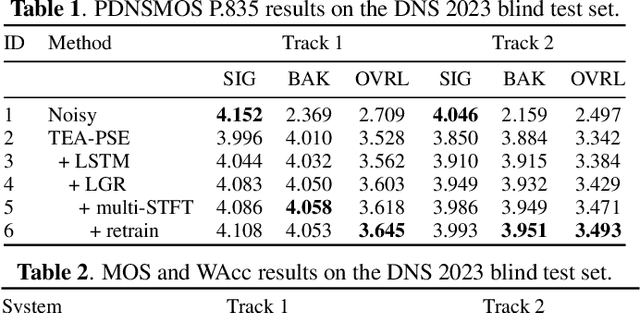
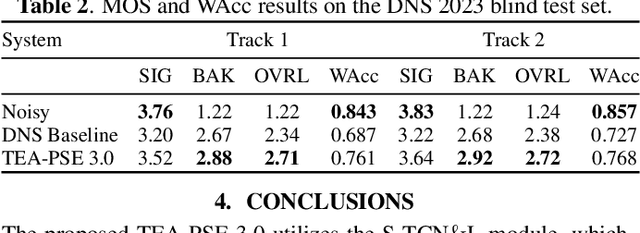
This paper introduces the Unbeatable Team's submission to the ICASSP 2023 Deep Noise Suppression (DNS) Challenge. We expand our previous work, TEA-PSE, to its upgraded version -- TEA-PSE 3.0. Specifically, TEA-PSE 3.0 incorporates a residual LSTM after squeezed temporal convolution network (S-TCN) to enhance sequence modeling capabilities. Additionally, the local-global representation (LGR) structure is introduced to boost speaker information extraction, and multi-STFT resolution loss is used to effectively capture the time-frequency characteristics of the speech signals. Moreover, retraining methods are employed based on the freeze training strategy to fine-tune the system. According to the official results, TEA-PSE 3.0 ranks 1st in both ICASSP 2023 DNS-Challenge track 1 and track 2.
Reliable Beamforming at Terahertz Bands: Are Causal Representations the Way Forward?
Mar 14, 2023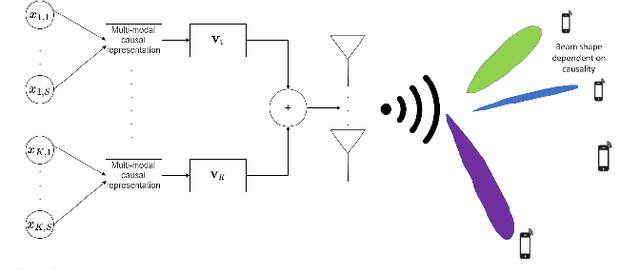
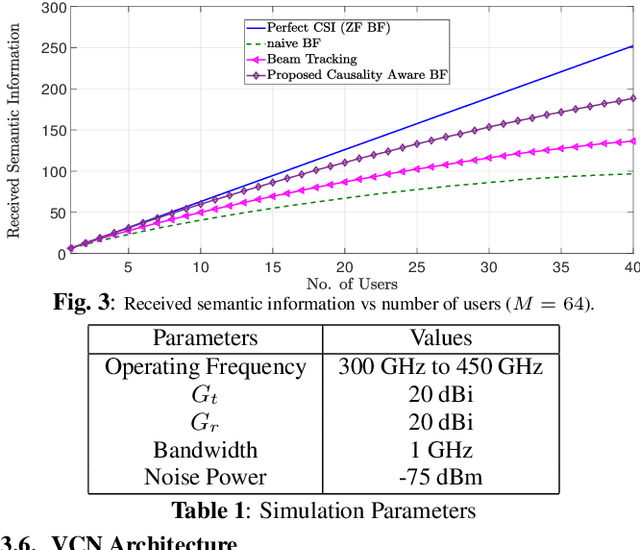
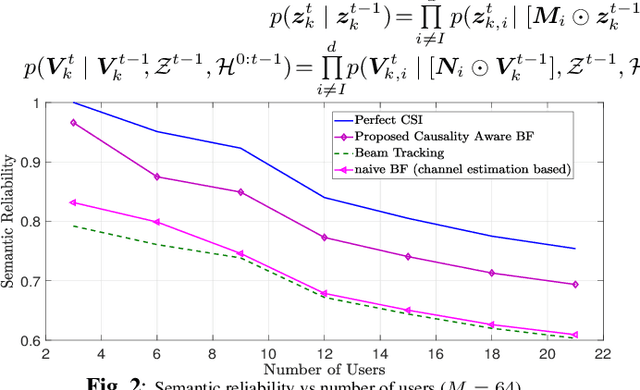
Future wireless services, such as the metaverse require high information rate, reliability, and low latency. Multi-user wireless systems can meet such requirements by utilizing the abundant terahertz bandwidth with a massive number of antennas, creating narrow beamforming solutions. However, existing solutions lack proper modeling of channel dynamics, resulting in inaccurate beamforming solutions in high-mobility scenarios. Herein, a dynamic, semantically aware beamforming solution is proposed for the first time, utilizing novel artificial intelligence algorithms in variational causal inference to compute the time-varying dynamics of the causal representation of multi-modal data and the beamforming. Simulations show that the proposed causality-guided approach for Terahertz (THz) beamforming outperforms classical MIMO beamforming techniques.
Low-complexity Deep Video Compression with A Distributed Coding Architecture
Mar 21, 2023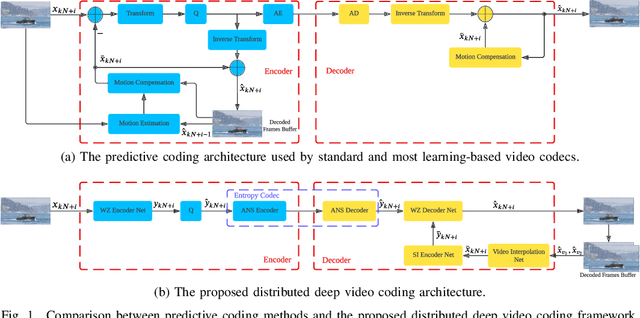
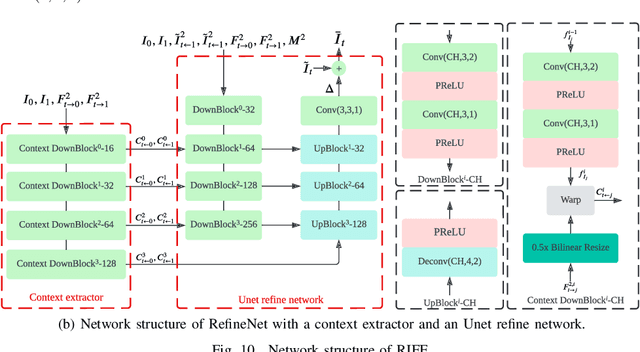
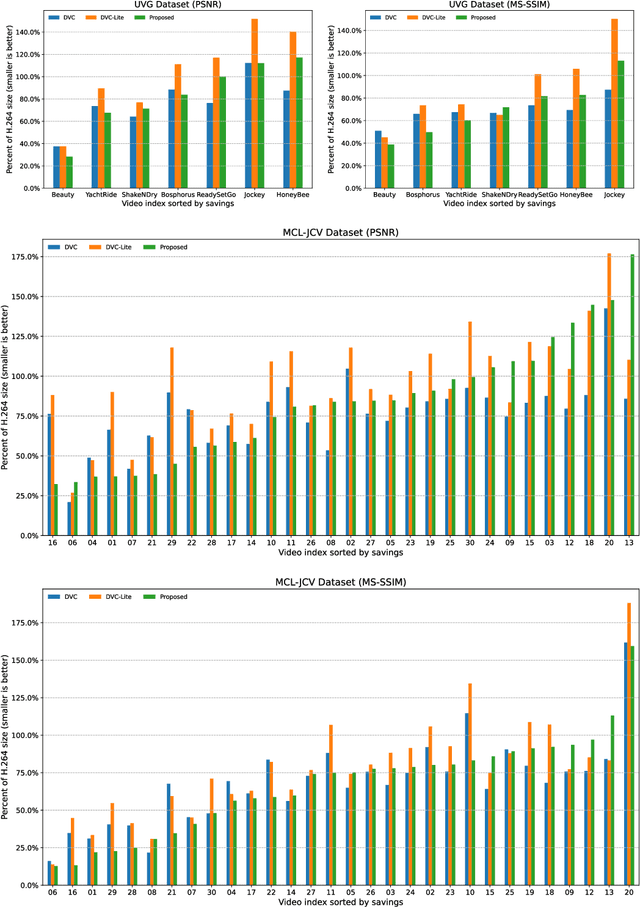

Prevalent predictive coding-based video compression methods rely on a heavy encoder to reduce the temporal redundancy, which makes it challenging to deploy them on resource-constrained devices. Meanwhile, as early as the 1970s, distributed source coding theory has indicated that independent encoding and joint decoding with side information (SI) can achieve high-efficient compression of correlated sources. This has inspired a distributed coding architecture aiming at reducing the encoding complexity. However, traditional distributed coding methods suffer from a substantial performance gap to predictive coding ones. Inspired by the great success of learning-based compression, we propose the first end-to-end distributed deep video compression framework to improve the rate-distortion performance. A key ingredient is an effective SI generation module at the decoder, which helps to effectively exploit inter-frame correlations without computation-intensive encoder-side motion estimation and compensation. Experiments show that our method significantly outperforms conventional distributed video coding and H.264. Meanwhile, it enjoys 6-7x encoding speedup against DVC [1] with comparable compression performance. Code is released at https://github.com/Xinjie-Q/Distributed-DVC.
Graph-less Collaborative Filtering
Mar 21, 2023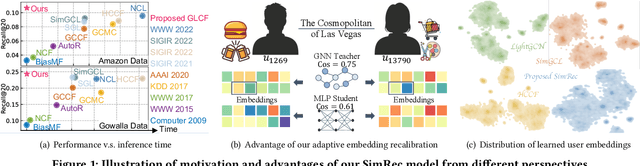

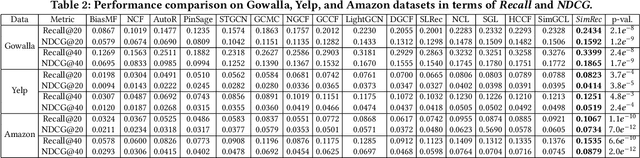
Graph neural networks (GNNs) have shown the power in representation learning over graph-structured user-item interaction data for collaborative filtering (CF) task. However, with their inherently recursive message propagation among neighboring nodes, existing GNN-based CF models may generate indistinguishable and inaccurate user (item) representations due to the over-smoothing and noise effect with low-pass Laplacian smoothing operators. In addition, the recursive information propagation with the stacked aggregators in the entire graph structures may result in poor scalability in practical applications. Motivated by these limitations, we propose a simple and effective collaborative filtering model (SimRec) that marries the power of knowledge distillation and contrastive learning. In SimRec, adaptive transferring knowledge is enabled between the teacher GNN model and a lightweight student network, to not only preserve the global collaborative signals, but also address the over-smoothing issue with representation recalibration. Empirical results on public datasets show that SimRec archives better efficiency while maintaining superior recommendation performance compared with various strong baselines. Our implementations are publicly available at: https://github.com/HKUDS/SimRec.
Efficient and Feasible Robotic Assembly Sequence Planning via Graph Representation Learning
Mar 21, 2023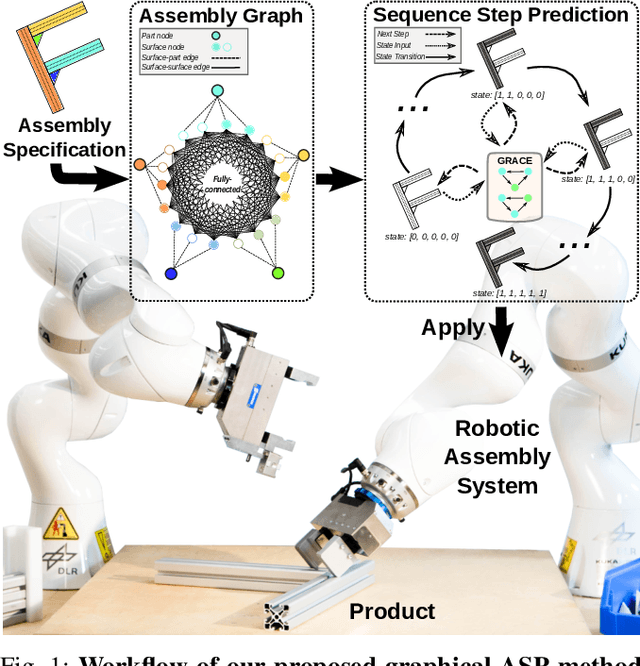
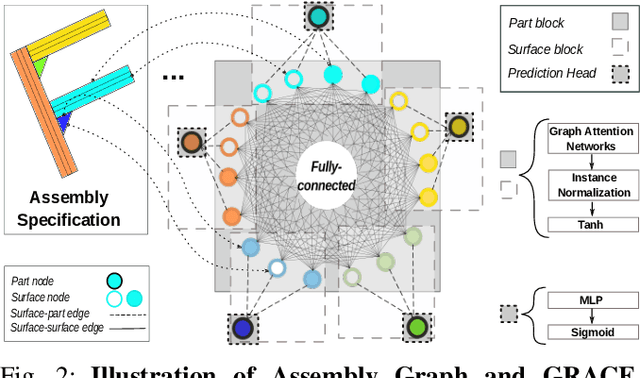
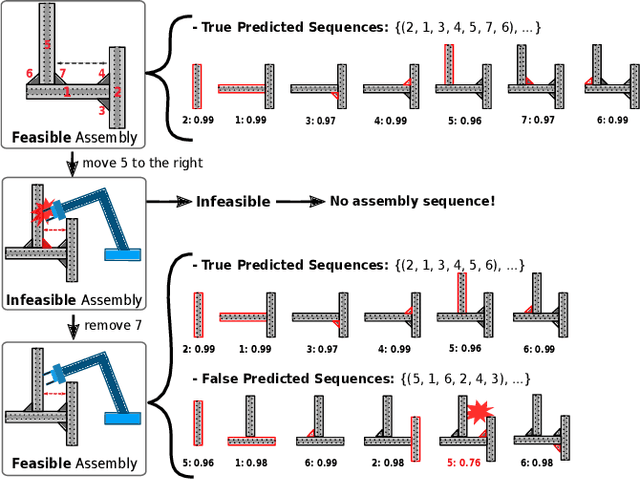
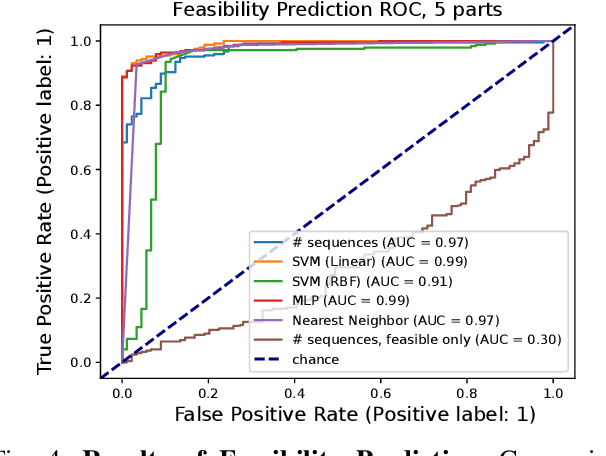
Automatic Robotic Assembly Sequence Planning (RASP) can significantly improve productivity and resilience in modern manufacturing along with the growing need for greater product customization. One of the main challenges in realizing such automation resides in efficiently finding solutions from a growing number of potential sequences for increasingly complex assemblies. Besides, costly feasibility checks are always required for the robotic system. To address this, we propose a holistic graphical approach including a graph representation called Assembly Graph for product assemblies and a policy architecture, Graph Assembly Processing Network, dubbed GRACE for assembly sequence generation. Secondly, we use GRACE to extract meaningful information from the graph input and predict assembly sequences in a step-by-step manner. In experiments, we show that our approach can predict feasible assembly sequences across product variants of aluminum profiles based on data collected in simulation of a dual-armed robotic system. We further demonstrate that our method is capable of detecting infeasible assemblies, substantially alleviating the undesirable impacts from false predictions, and hence facilitating real-world deployment soon. Code and training data will be open-sourced.
In-depth analysis of music structure as a self-organized network
Mar 21, 2023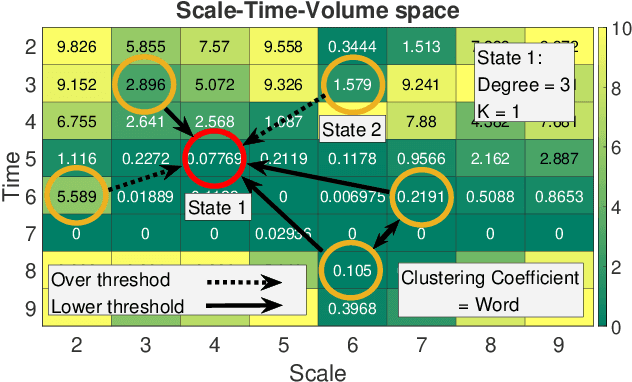
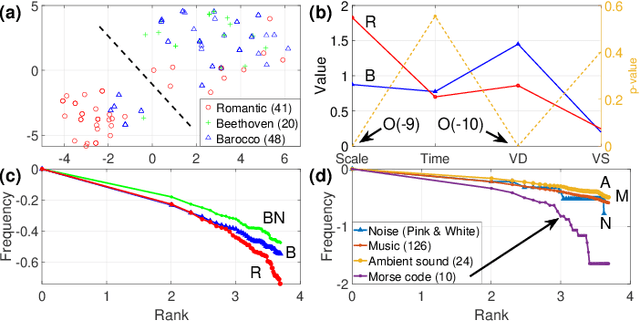
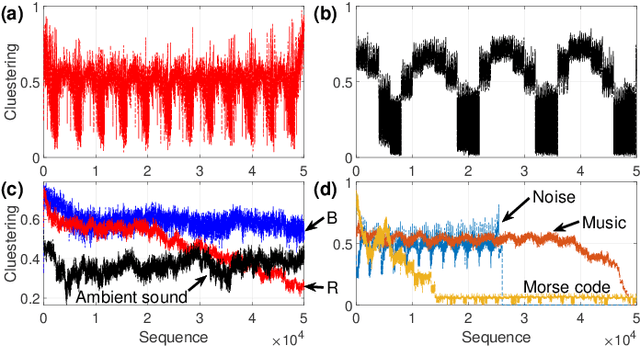
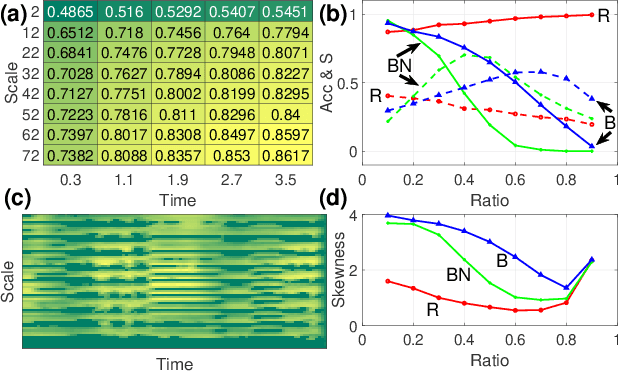
Words in a natural language not only transmit information but also evolve with the development of civilization and human migration. The same is true for music. To understand the complex structure behind the music, we introduced an algorithm called the Essential Element Network (EEN) to encode the audio into text. The network is obtained by calculating the correlations between scales, time, and volume. Optimizing EEN to generate Zipfs law for the frequency and rank of the clustering coefficient enables us to generate and regard the semantic relationships as words. We map these encoded words into the scale-temporal space, which helps us organize systematically the syntax in the deep structure of music. Our algorithm provides precise descriptions of the complex network behind the music, as opposed to the black-box nature of other deep learning approaches. As a result, the experience and properties accumulated through these processes can offer not only a new approach to the applications of Natural Language Processing (NLP) but also an easier and more objective way to analyze the evolution and development of music.