 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrinity: Unifying Class-Agnostic Terrain and Semantic Segmentation for Unstructured Outdoor Environments by Leveraging Synthetic Data
May 26, 2026Terrain understanding is fundamental for mobile robots operating in unstructured outdoor environments. Existing vision-based traversability estimation methods rely on robot-specific annotations or semantic class mappings, limiting transferability across platforms and requiring costly re-annotation when robot capabilities change, while standard semantic segmentation methods only focus on specific predefined classes, which do not capture the variety of terrains. In this work, we propose a transformer-based architecture that jointly performs class-specific semantic segmentation and class-agnostic terrain segmentation within a unified network, called Trinity. Terrain regions are segmented based solely on visual appearance, without predefined semantic labels or robot-dependent traversability scores. This formulation enables the learning of robot-agnostic visual terrain priors that can be combined with robot-specific experience for downstream tasks such as traversability estimation, visual odometry, and mission planning. To enable large-scale training with diverse terrain appearances, we extend the OAISYS simulator and introduce RUGDSynth, a synthetic dataset inspired by RUGD with class-agnostic terrain samples. Furthermore, we present the EXTerra Dataset, providing real-world images annotated with both class-specific and class-agnostic terrain labels. Experiments demonstrate the feasibility of the proposed task and the effectiveness of our joint segmentation approach in complex outdoor environments. Code and datasets will be released with this publication (after review).
Markerless Robot Detection and 6D Pose Estimation for Multi-Agent SLAM
Feb 18, 2026The capability of multi-robot SLAM approaches to merge localization history and maps from different observers is often challenged by the difficulty in establishing data association. Loop closure detection between perceptual inputs of different robotic agents is easily compromised in the context of perceptual aliasing, or when perspectives differ significantly. For this reason, direct mutual observation among robots is a powerful way to connect partial SLAM graphs, but often relies on the presence of calibrated arrays of fiducial markers (e.g., AprilTag arrays), which severely limits the range of observations and frequently fails under sharp lighting conditions, e.g., reflections or overexposure. In this work, we propose a novel solution to this problem leveraging recent advances in Deep-Learning-based 6D pose estimation. We feature markerless pose estimation as part of a decentralized multi-robot SLAM system and demonstrate the benefit to the relative localization accuracy among the robotic team. The solution is validated experimentally on data recorded in a test field campaign on a planetary analogous environment.
Finding NeMO: A Geometry-Aware Representation of Template Views for Few-Shot Perception
Feb 04, 2026We present Neural Memory Object (NeMO), a novel object-centric representation that can be used to detect, segment and estimate the 6DoF pose of objects unseen during training using RGB images. Our method consists of an encoder that requires only a few RGB template views depicting an object to generate a sparse object-like point cloud using a learned UDF containing semantic and geometric information. Next, a decoder takes the object encoding together with a query image to generate a variety of dense predictions. Through extensive experiments, we show that our method can be used for few-shot object perception without requiring any camera-specific parameters or retraining on target data. Our proposed concept of outsourcing object information in a NeMO and using a single network for multiple perception tasks enhances interaction with novel objects, improving scalability and efficiency by enabling quick object onboarding without retraining or extensive pre-processing. We report competitive and state-of-the-art results on various datasets and perception tasks of the BOP benchmark, demonstrating the versatility of our approach. https://github.com/DLR-RM/nemo
Conditional Latent Diffusion Models for Zero-Shot Instance Segmentation
Aug 06, 2025This paper presents OC-DiT, a novel class of diffusion models designed for object-centric prediction, and applies it to zero-shot instance segmentation. We propose a conditional latent diffusion framework that generates instance masks by conditioning the generative process on object templates and image features within the diffusion model's latent space. This allows our model to effectively disentangle object instances through the diffusion process, which is guided by visual object descriptors and localized image cues. Specifically, we introduce two model variants: a coarse model for generating initial object instance proposals, and a refinement model that refines all proposals in parallel. We train these models on a newly created, large-scale synthetic dataset comprising thousands of high-quality object meshes. Remarkably, our model achieves state-of-the-art performance on multiple challenging real-world benchmarks, without requiring any retraining on target data. Through comprehensive ablation studies, we demonstrate the potential of diffusion models for instance segmentation tasks.
How Important are Data Augmentations to Close the Domain Gap for Object Detection in Orbit?
Oct 21, 2024



We investigate the efficacy of data augmentations to close the domain gap in spaceborne computer vision, crucial for autonomous operations like on-orbit servicing. As the use of computer vision in space increases, challenges such as hostile illumination and low signal-to-noise ratios significantly hinder performance. While learning-based algorithms show promising results, their adoption is limited by the need for extensive annotated training data and the domain gap that arises from differences between synthesized and real-world imagery. This study explores domain generalization in terms of data augmentations -- classical color and geometric transformations, corruptions, and noise -- to enhance model performance across the domain gap. To this end, we conduct an large scale experiment using a hyperparameter optimization pipeline that samples hundreds of different configurations and searches for the best set to bridge the domain gap. As a reference task, we use 2D object detection and evaluate on the SPEED+ dataset that contains real hardware-in-the-loop satellite images in its test set. Moreover, we evaluate four popular object detectors, including Mask R-CNN, Faster R-CNN, YOLO-v7, and the open set detector GroundingDINO, and highlight their trade-offs between performance, inference speed, and training time. Our results underscore the vital role of data augmentations in bridging the domain gap, improving model performance, robustness, and reliability for critical space applications. As a result, we propose two novel data augmentations specifically developed to emulate the visual effects observed in orbital imagery. We conclude by recommending the most effective augmentations for advancing computer vision in challenging orbital environments. Code for training detectors and hyperparameter search will be made publicly available.
Unknown Object Grasping for Assistive Robotics
Apr 23, 2024



We propose a novel pipeline for unknown object grasping in shared robotic autonomy scenarios. State-of-the-art methods for fully autonomous scenarios are typically learning-based approaches optimised for a specific end-effector, that generate grasp poses directly from sensor input. In the domain of assistive robotics, we seek instead to utilise the user's cognitive abilities for enhanced satisfaction, grasping performance, and alignment with their high level task-specific goals. Given a pair of stereo images, we perform unknown object instance segmentation and generate a 3D reconstruction of the object of interest. In shared control, the user then guides the robot end-effector across a virtual hemisphere centered around the object to their desired approach direction. A physics-based grasp planner finds the most stable local grasp on the reconstruction, and finally the user is guided by shared control to this grasp. In experiments on the DLR EDAN platform, we report a grasp success rate of 87% for 10 unknown objects, and demonstrate the method's capability to grasp objects in structured clutter and from shelves.
Density-based Feasibility Learning with Normalizing Flows for Introspective Robotic Assembly
Jul 06, 2023Machine Learning (ML) models in Robotic Assembly Sequence Planning (RASP) need to be introspective on the predicted solutions, i.e. whether they are feasible or not, to circumvent potential efficiency degradation. Previous works need both feasible and infeasible examples during training. However, the infeasible ones are hard to collect sufficiently when re-training is required for swift adaptation to new product variants. In this work, we propose a density-based feasibility learning method that requires only feasible examples. Concretely, we formulate the feasibility learning problem as Out-of-Distribution (OOD) detection with Normalizing Flows (NF), which are powerful generative models for estimating complex probability distributions. Empirically, the proposed method is demonstrated on robotic assembly use cases and outperforms other single-class baselines in detecting infeasible assemblies. We further investigate the internal working mechanism of our method and show that a large memory saving can be obtained based on an advanced variant of NF.
6D Object Pose Estimation from Approximate 3D Models for Orbital Robotics
Mar 31, 2023



We present a novel technique to estimate the 6D pose of objects from single images where the 3D geometry of the object is only given approximately and not as a precise 3D model. To achieve this, we employ a dense 2D-to-3D correspondence predictor that regresses 3D model coordinates for every pixel. In addition to the 3D coordinates, our model also estimates the pixel-wise coordinate error to discard correspondences that are likely wrong. This allows us to generate multiple 6D pose hypotheses of the object, which we then refine iteratively using a highly efficient region-based approach. We also introduce a novel pixel-wise posterior formulation by which we can estimate the probability for each hypothesis and select the most likely one. As we show in experiments, our approach is capable of dealing with extreme visual conditions including overexposure, high contrast, or low signal-to-noise ratio. This makes it a powerful technique for the particularly challenging task of estimating the pose of tumbling satellites for in-orbit robotic applications. Our method achieves state-of-the-art performance on the SPEED+ dataset and has won the SPEC2021 post-mortem competition.
Efficient and Feasible Robotic Assembly Sequence Planning via Graph Representation Learning
Mar 21, 2023



Automatic Robotic Assembly Sequence Planning (RASP) can significantly improve productivity and resilience in modern manufacturing along with the growing need for greater product customization. One of the main challenges in realizing such automation resides in efficiently finding solutions from a growing number of potential sequences for increasingly complex assemblies. Besides, costly feasibility checks are always required for the robotic system. To address this, we propose a holistic graphical approach including a graph representation called Assembly Graph for product assemblies and a policy architecture, Graph Assembly Processing Network, dubbed GRACE for assembly sequence generation. Secondly, we use GRACE to extract meaningful information from the graph input and predict assembly sequences in a step-by-step manner. In experiments, we show that our approach can predict feasible assembly sequences across product variants of aluminum profiles based on data collected in simulation of a dual-armed robotic system. We further demonstrate that our method is capable of detecting infeasible assemblies, substantially alleviating the undesirable impacts from false predictions, and hence facilitating real-world deployment soon. Code and training data will be open-sourced.
Bridging the Last Mile in Sim-to-Real Robot Perception via Bayesian Active Learning
Sep 29, 2021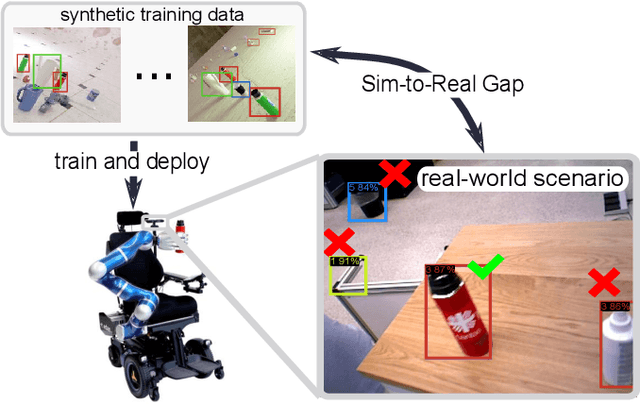

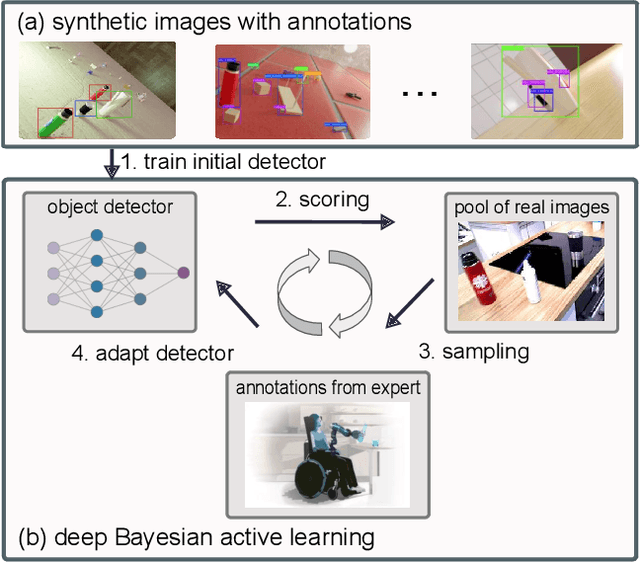
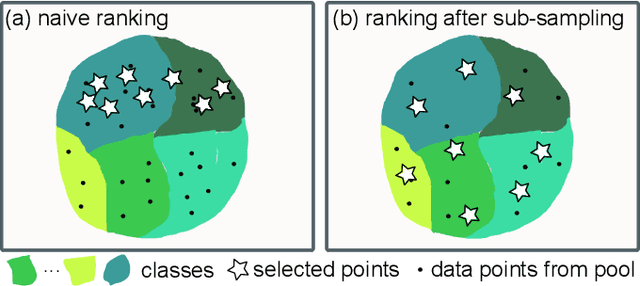
Learning from synthetic data is popular in a variety of robotic vision tasks such as object detection, because a large amount of data can be generated without annotations by humans. However, when relying only on synthetic data,we encounter the well-known problem of the simulation-to-reality (Sim-to-Real) gap, which is hard to resolve completely in practice. For such cases, real human-annotated data is necessary to bridge this gap, and in our work we focus on howto acquire this data efficiently. Therefore, we propose a Sim-to-Real pipeline that relies on deep Bayesian active learning and aims to minimize the manual annotation efforts. We devise a learning paradigm that autonomously selects the data that is considered useful for the human expert to annotate. To achieve this, a Bayesian Neural Network (BNN) object detector providing reliable uncertain estimates is adapted to infer the informativeness of the unlabeled data, in order to perform active learning. In our experiments on two object detection data sets, we show that the labeling effort required to bridge the reality gap can be reduced to a small amount. Furthermore, we demonstrate the practical effectiveness of this idea in a grasping task on an assistive robot.