 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Unleashing the Potential of Spiking Neural Networks by Dynamic Confidence
Mar 26, 2023
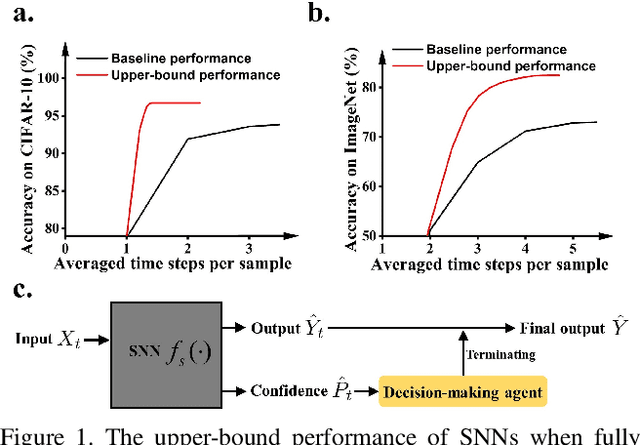
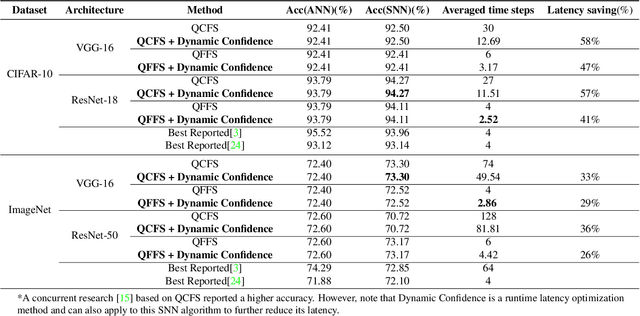
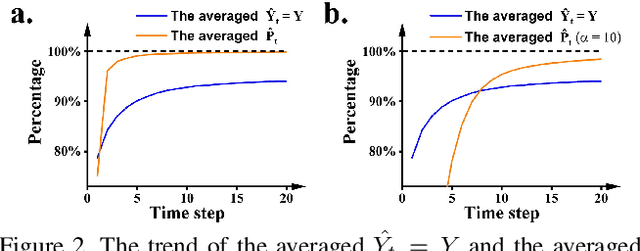
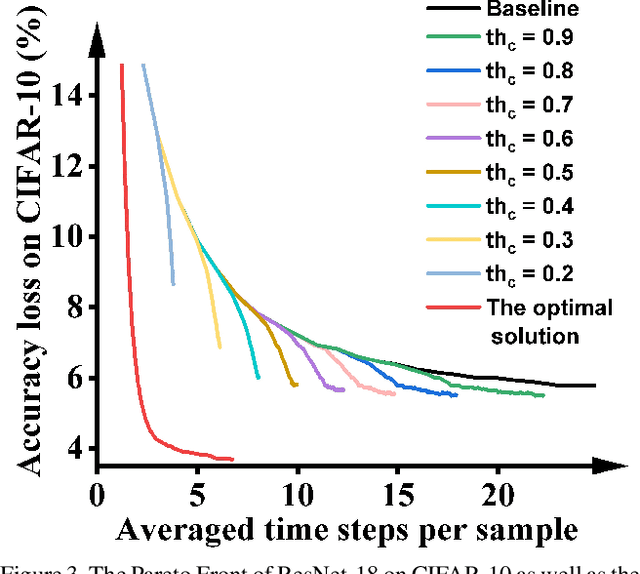
This paper presents a new methodology to alleviate the fundamental trade-off between accuracy and latency in spiking neural networks (SNNs). The approach involves decoding confidence information over time from the SNN outputs and using it to develop a decision-making agent that can dynamically determine when to terminate each inference. The proposed method, Dynamic Confidence, provides several significant benefits to SNNs. 1. It can effectively optimize latency dynamically at runtime, setting it apart from many existing low-latency SNN algorithms. Our experiments on CIFAR-10 and ImageNet datasets have demonstrated an average 40% speedup across eight different settings after applying Dynamic Confidence. 2. The decision-making agent in Dynamic Confidence is straightforward to construct and highly robust in parameter space, making it extremely easy to implement. 3. The proposed method enables visualizing the potential of any given SNN, which sets a target for current SNNs to approach. For instance, if an SNN can terminate at the most appropriate time point for each input sample, a ResNet-50 SNN can achieve an accuracy as high as 82.47% on ImageNet within just 4.71 time steps on average. Unlocking the potential of SNNs needs a highly-reliable decision-making agent to be constructed and fed with a high-quality estimation of ground truth. In this regard, Dynamic Confidence represents a meaningful step toward realizing the potential of SNNs.
CLIP$^2$: Contrastive Language-Image-Point Pretraining from Real-World Point Cloud Data
Mar 26, 2023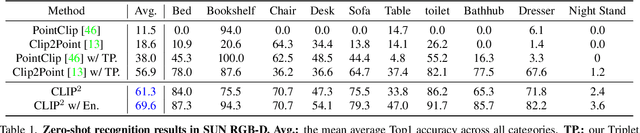
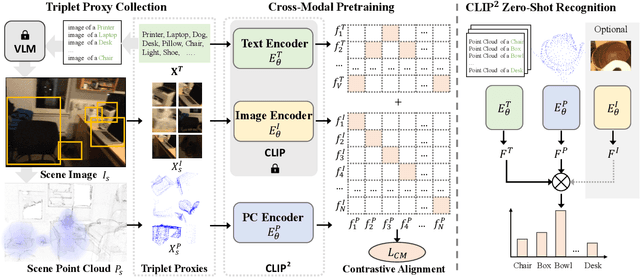

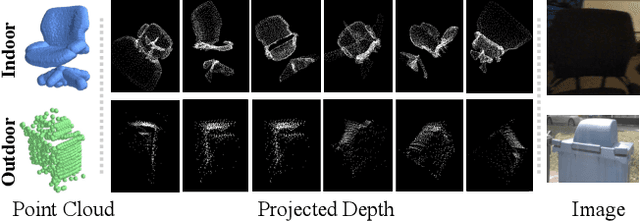
Contrastive Language-Image Pre-training, benefiting from large-scale unlabeled text-image pairs, has demonstrated great performance in open-world vision understanding tasks. However, due to the limited Text-3D data pairs, adapting the success of 2D Vision-Language Models (VLM) to the 3D space remains an open problem. Existing works that leverage VLM for 3D understanding generally resort to constructing intermediate 2D representations for the 3D data, but at the cost of losing 3D geometry information. To take a step toward open-world 3D vision understanding, we propose Contrastive Language-Image-Point Cloud Pretraining (CLIP$^2$) to directly learn the transferable 3D point cloud representation in realistic scenarios with a novel proxy alignment mechanism. Specifically, we exploit naturally-existed correspondences in 2D and 3D scenarios, and build well-aligned and instance-based text-image-point proxies from those complex scenarios. On top of that, we propose a cross-modal contrastive objective to learn semantic and instance-level aligned point cloud representation. Experimental results on both indoor and outdoor scenarios show that our learned 3D representation has great transfer ability in downstream tasks, including zero-shot and few-shot 3D recognition, which boosts the state-of-the-art methods by large margins. Furthermore, we provide analyses of the capability of different representations in real scenarios and present the optional ensemble scheme.
CroSel: Cross Selection of Confident Pseudo Labels for Partial-Label Learning
Mar 23, 2023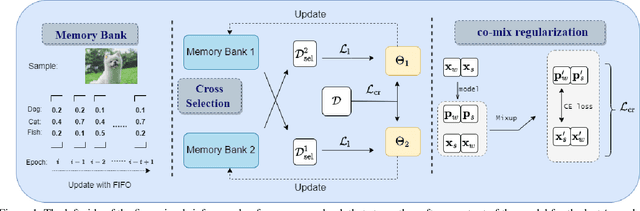
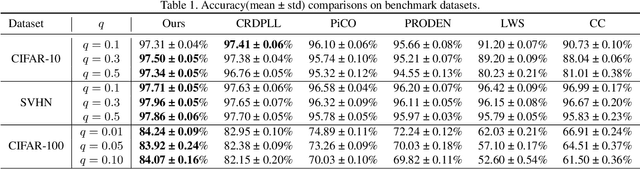
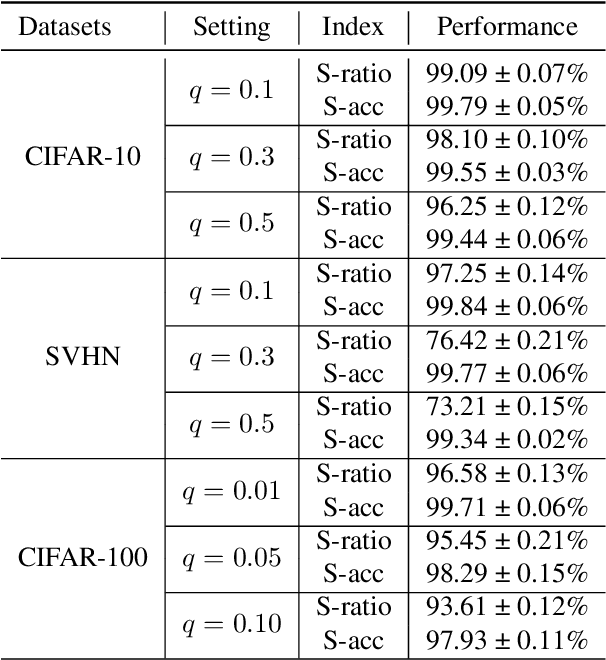
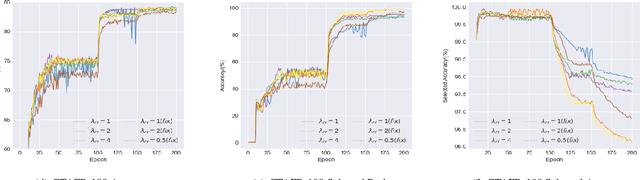
Partial-label learning (PLL) is an important weakly supervised learning problem, which allows each training example to have a candidate label set instead of a single ground-truth label. Identification-based methods have been widely explored to tackle label ambiguity issues in PLL, which regard the true label as a latent variable to be identified. However, identifying the true labels accurately and completely remains challenging, causing noise in pseudo labels during model training. In this paper, we propose a new method called CroSel, which leverages historical prediction information from models to identify true labels for most training examples. First, we introduce a cross selection strategy, which enables two deep models to select true labels of partially labeled data for each other. Besides, we propose a novel consistent regularization term called co-mix to avoid sample waste and tiny noise caused by false selection. In this way, CroSel can pick out the true labels of most examples with high precision. Extensive experiments demonstrate the superiority of CroSel, which consistently outperforms previous state-of-the-art methods on benchmark datasets. Additionally, our method achieves over 90\% accuracy and quantity for selecting true labels on CIFAR-type datasets under various settings.
DiffMIC: Dual-Guidance Diffusion Network for Medical Image Classification
Mar 23, 2023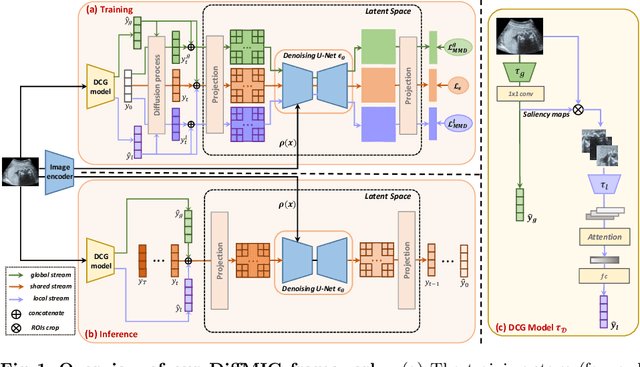
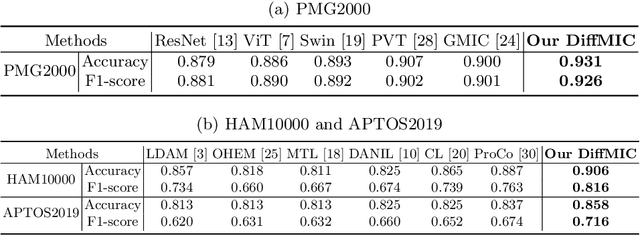
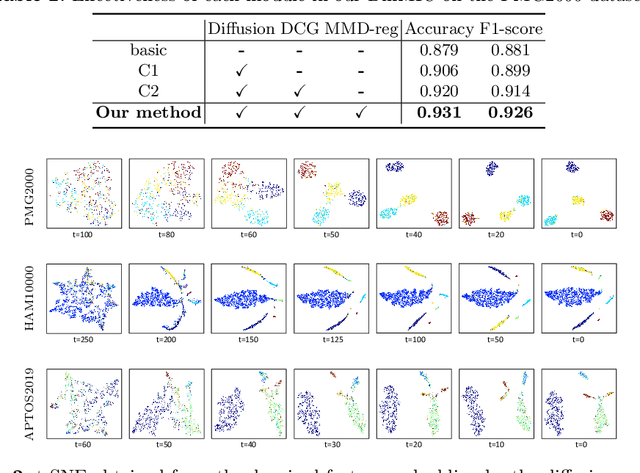
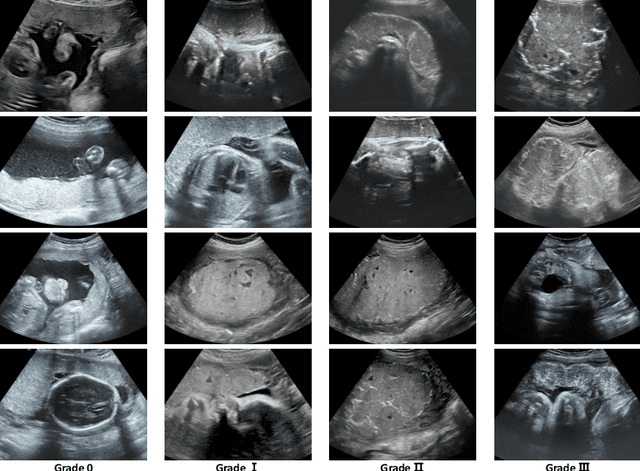
Diffusion Probabilistic Models have recently shown remarkable performance in generative image modeling, attracting significant attention in the computer vision community. However, while a substantial amount of diffusion-based research has focused on generative tasks, few studies have applied diffusion models to general medical image classification. In this paper, we propose the first diffusion-based model (named DiffMIC) to address general medical image classification by eliminating unexpected noise and perturbations in medical images and robustly capturing semantic representation. To achieve this goal, we devise a dual conditional guidance strategy that conditions each diffusion step with multiple granularities to improve step-wise regional attention. Furthermore, we propose learning the mutual information in each granularity by enforcing Maximum-Mean Discrepancy regularization during the diffusion forward process. We evaluate the effectiveness of our DiffMIC on three medical classification tasks with different image modalities, including placental maturity grading on ultrasound images, skin lesion classification using dermatoscopic images, and diabetic retinopathy grading using fundus images. Our experimental results demonstrate that DiffMIC outperforms state-of-the-art methods by a significant margin, indicating the universality and effectiveness of the proposed model. Our code will be publicly available at https://github.com/scott-yjyang/DiffMIC.
ScanERU: Interactive 3D Visual Grounding based on Embodied Reference Understanding
Mar 23, 2023
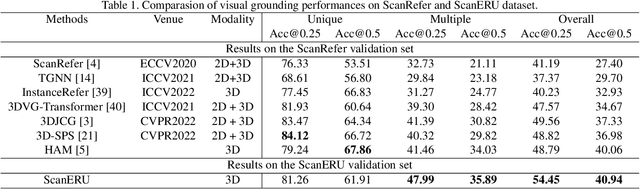
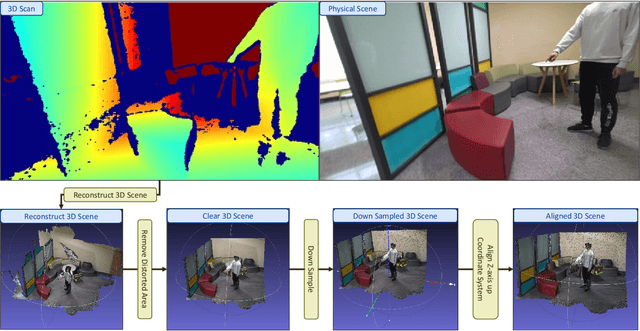

Aiming to link natural language descriptions to specific regions in a 3D scene represented as 3D point clouds, 3D visual grounding is a very fundamental task for human-robot interaction. The recognition errors can significantly impact the overall accuracy and then degrade the operation of AI systems. Despite their effectiveness, existing methods suffer from the difficulty of low recognition accuracy in cases of multiple adjacent objects with similar appearances.To address this issue, this work intuitively introduces the human-robot interaction as a cue to facilitate the development of 3D visual grounding. Specifically, a new task termed Embodied Reference Understanding (ERU) is first designed for this concern. Then a new dataset called ScanERU is constructed to evaluate the effectiveness of this idea. Different from existing datasets, our ScanERU is the first to cover semi-synthetic scene integration with textual, real-world visual, and synthetic gestural information. Additionally, this paper formulates a heuristic framework based on attention mechanisms and human body movements to enlighten the research of ERU. Experimental results demonstrate the superiority of the proposed method, especially in the recognition of multiple identical objects. Our codes and dataset are ready to be available publicly.
Decision-aid or Controller? Steering Human Decision Makers with Algorithms
Mar 23, 2023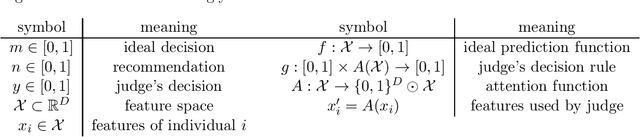
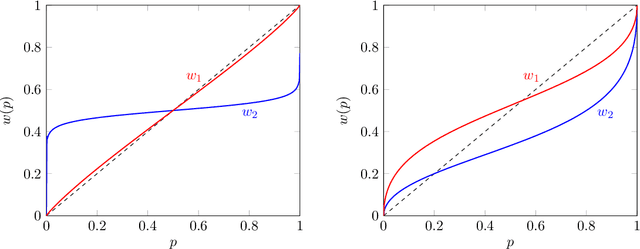
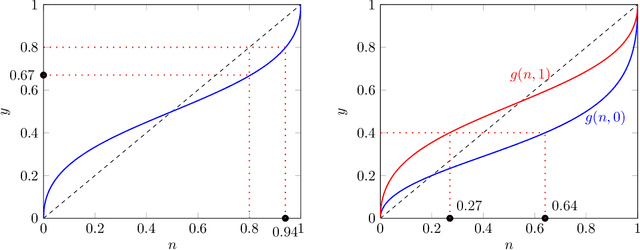
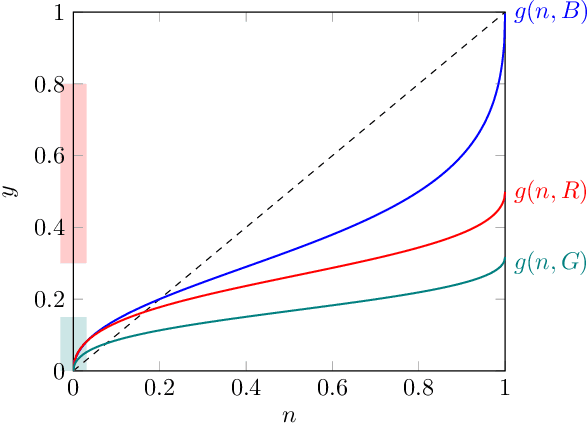
Algorithms are used to aid human decision makers by making predictions and recommending decisions. Currently, these algorithms are trained to optimize prediction accuracy. What if they were optimized to control final decisions? In this paper, we study a decision-aid algorithm that learns about the human decision maker and provides ''personalized recommendations'' to influence final decisions. We first consider fixed human decision functions which map observable features and the algorithm's recommendations to final decisions. We characterize the conditions under which perfect control over final decisions is attainable. Under fairly general assumptions, the parameters of the human decision function can be identified from past interactions between the algorithm and the human decision maker, even when the algorithm was constrained to make truthful recommendations. We then consider a decision maker who is aware of the algorithm's manipulation and responds strategically. By posing the setting as a variation of the cheap talk game [Crawford and Sobel, 1982], we show that all equilibria are partition equilibria where only coarse information is shared: the algorithm recommends an interval containing the ideal decision. We discuss the potential applications of such algorithms and their social implications.
Preference-Aware Constrained Multi-Objective Bayesian Optimization
Mar 23, 2023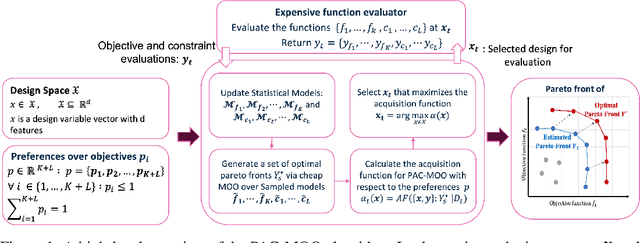
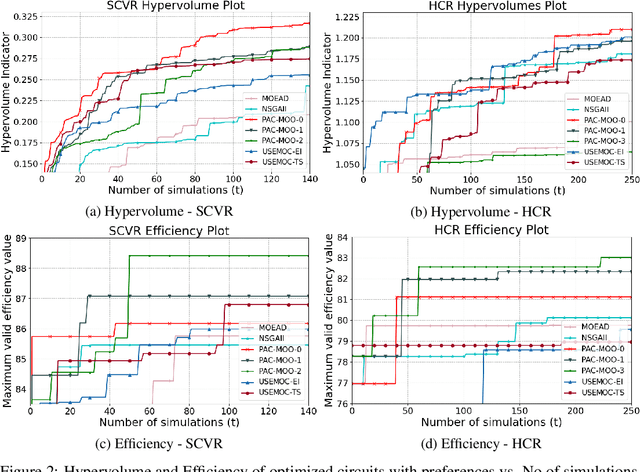
This paper addresses the problem of constrained multi-objective optimization over black-box objective functions with practitioner-specified preferences over the objectives when a large fraction of the input space is infeasible (i.e., violates constraints). This problem arises in many engineering design problems including analog circuits and electric power system design. Our overall goal is to approximate the optimal Pareto set over the small fraction of feasible input designs. The key challenges include the huge size of the design space, multiple objectives and large number of constraints, and the small fraction of feasible input designs which can be identified only after performing expensive simulations. We propose a novel and efficient preference-aware constrained multi-objective Bayesian optimization approach referred to as PAC-MOO to address these challenges. The key idea is to learn surrogate models for both output objectives and constraints, and select the candidate input for evaluation in each iteration that maximizes the information gained about the optimal constrained Pareto front while factoring in the preferences over objectives. Our experiments on two real-world analog circuit design optimization problems demonstrate the efficacy of PAC-MOO over prior methods.
It is all Connected: A New Graph Formulation for Spatio-Temporal Forecasting
Mar 23, 2023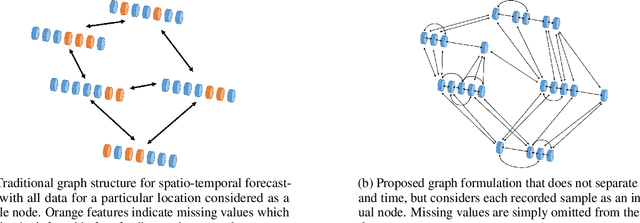

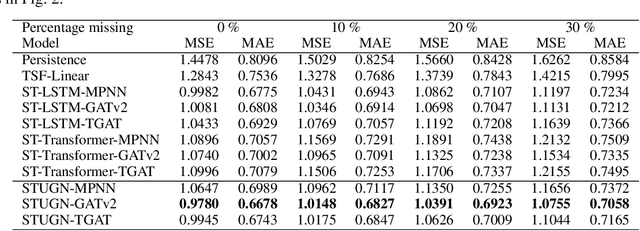
With an ever-increasing number of sensors in modern society, spatio-temporal time series forecasting has become a de facto tool to make informed decisions about the future. Most spatio-temporal forecasting models typically comprise distinct components that learn spatial and temporal dependencies. A common methodology employs some Graph Neural Network (GNN) to capture relations between spatial locations, while another network, such as a recurrent neural network (RNN), learns temporal correlations. By representing every recorded sample as its own node in a graph, rather than all measurements for a particular location as a single node, temporal and spatial information is encoded in a similar manner. In this setting, GNNs can now directly learn both temporal and spatial dependencies, jointly, while also alleviating the need for additional temporal networks. Furthermore, the framework does not require aligned measurements along the temporal dimension, meaning that it also naturally facilitates irregular time series, different sampling frequencies or missing data, without the need for data imputation. To evaluate the proposed methodology, we consider wind speed forecasting as a case study, where our proposed framework outperformed other spatio-temporal models using GNNs with either Transformer or LSTM networks as temporal update functions.
Damage detection of high-speed railway box girder using train-induced dynamic responses
Mar 23, 2023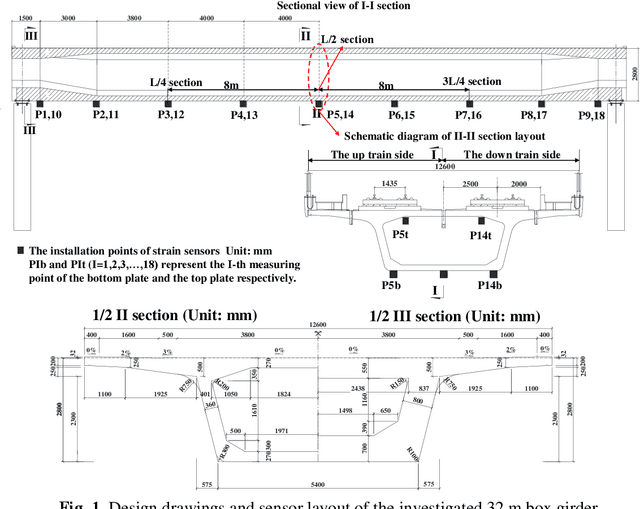
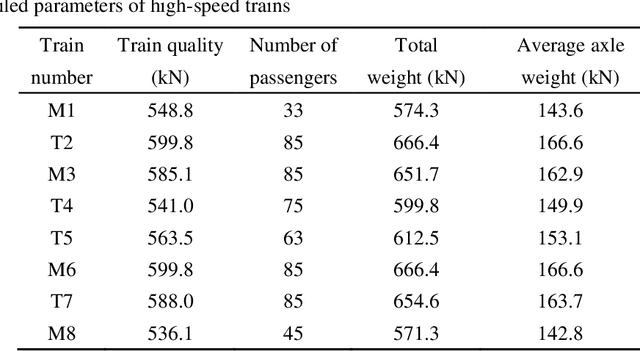
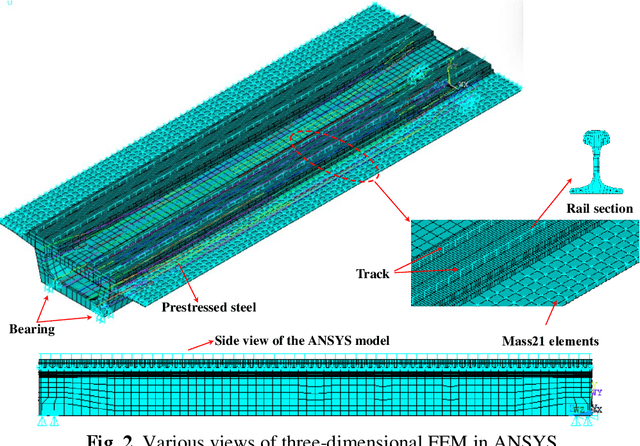

This paper proposes a damage detection method based on the train-induced responses of high-speed railway box girder. Under the coupling effects of bending and torsion, the traditional damage detection method based on the Euler beam theory cannot be applied. In this research, the box girder section is divided into different components based on the plate element analysis method. The strain responses were preprocessed based on Principal Component Analysis (PCA) method to remove the influence of train operation variation. The residual error of autoregressive (AR) model was used as a potential index of damage features. The optimal order of the model was determined based on Bayesian information criterion (BIC) criterion. Finally, the confidence boundary (CB) of damage features (DF) constituting outliers can be estimated by Gaussian inverse cumulative distribution function (ICDF). The numerical simulation results show that the proposed method in this paper can effectively identify, locate and quantify the damage, which verifies the accuracy of the proposed method. The proposed method effectively identifies the early damage of all components on the key section by using four strain sensors, and it is helpful for developing effective maintenance strategies for high-speed railway box girder.
Graph Construction using Principal Axis Trees for Simple Graph Convolution
Feb 22, 2023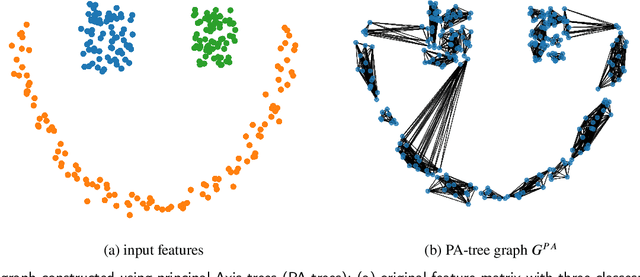


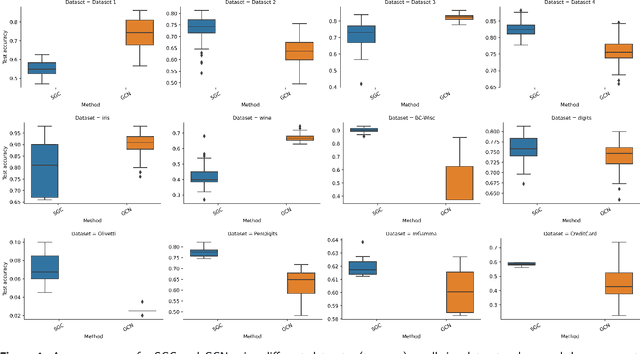
Graph Neural Networks (GNNs) are increasingly becoming the favorite method for graph learning. They exploit the semi-supervised nature of deep learning, and they bypass computational bottlenecks associated with traditional graph learning methods. In addition to the feature matrix $X$, GNNs need an adjacency matrix $A$ to perform feature propagation. In many cases the adjacency matrix $A$ is missing. We introduce a graph construction scheme that construct the adjacency matrix $A$ using unsupervised and supervised information. Unsupervised information characterize the neighborhood around points. We used Principal Axis trees (PA-trees) as a source of unsupervised information, where we create edges between points falling onto the same leaf node. For supervised information, we used the concept of penalty and intrinsic graphs. A penalty graph connects points with different class labels, whereas intrinsic graph connects points with the same class label. We used the penalty and intrinsic graphs to remove or add edges to the graph constructed via PA-tree. This graph construction scheme was tested on two well-known GNNs: 1) Graph Convolutional Network (GCN) and 2) Simple Graph Convolution (SGC). The experiments show that it is better to use SGC because it is faster and delivers better or the same results as GCN. We also test the effect of oversmoothing on both GCN and SGC. We found out that the level of smoothing has to be selected carefully for SGC to avoid oversmoothing.