 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Enhanced Controllability of Diffusion Models
Mar 15, 2023

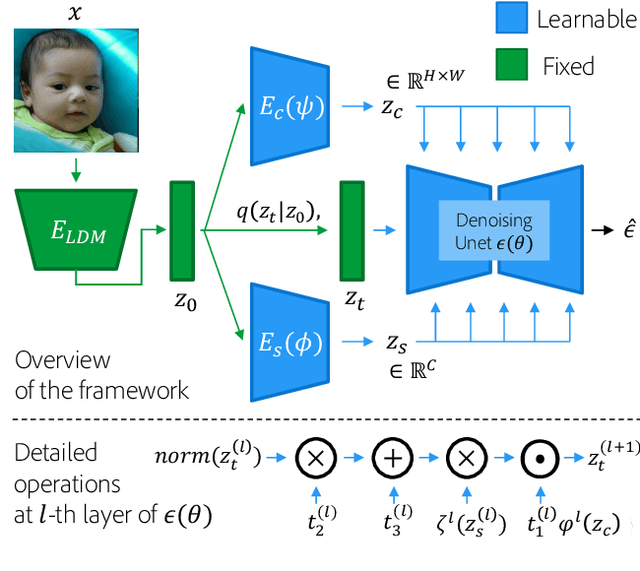
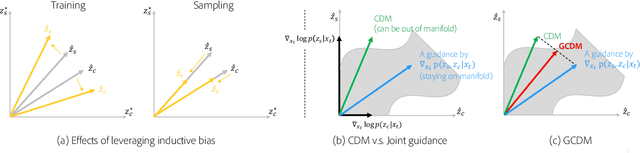

Denoising Diffusion models have shown remarkable capabilities in generating realistic, high-quality and diverse images. However, the extent of controllability during generation is underexplored. Inspired by techniques based on GAN latent space for image manipulation, we train a diffusion model conditioned on two latent codes, a spatial content mask and a flattened style embedding. We rely on the inductive bias of the progressive denoising process of diffusion models to encode pose/layout information in the spatial structure mask and semantic/style information in the style code. We propose two generic sampling techniques for improving controllability. We extend composable diffusion models to allow for some dependence between conditional inputs, to improve the quality of generations while also providing control over the amount of guidance from each latent code and their joint distribution. We also propose timestep dependent weight scheduling for content and style latents to further improve the translations. We observe better controllability compared to existing methods and show that without explicit training objectives, diffusion models can be used for effective image manipulation and image translation.
Information Maximization for Extreme Pose Face Recognition
Sep 07, 2022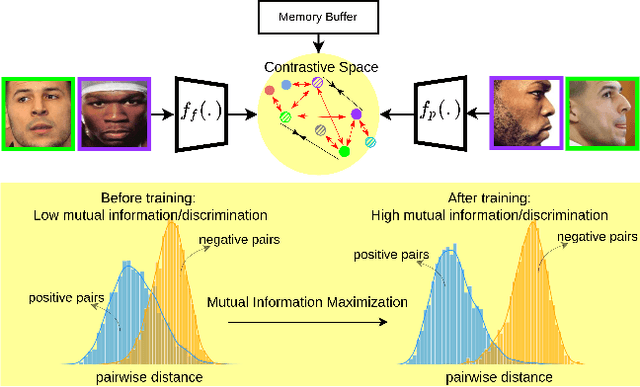
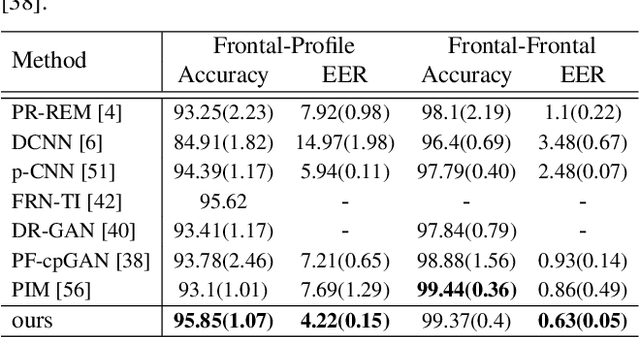
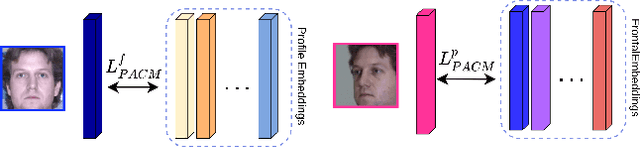
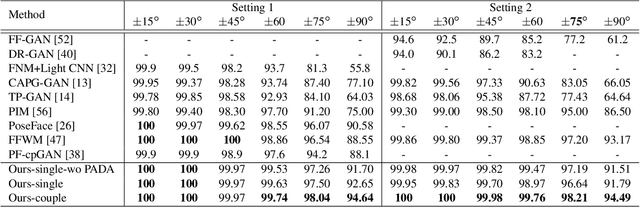
In this paper, we seek to draw connections between the frontal and profile face images in an abstract embedding space. We exploit this connection using a coupled-encoder network to project frontal/profile face images into a common latent embedding space. The proposed model forces the similarity of representations in the embedding space by maximizing the mutual information between two views of the face. The proposed coupled-encoder benefits from three contributions for matching faces with extreme pose disparities. First, we leverage our pose-aware contrastive learning to maximize the mutual information between frontal and profile representations of identities. Second, a memory buffer, which consists of latent representations accumulated over past iterations, is integrated into the model so it can refer to relatively much more instances than the mini-batch size. Third, a novel pose-aware adversarial domain adaptation method forces the model to learn an asymmetric mapping from profile to frontal representation. In our framework, the coupled-encoder learns to enlarge the margin between the distribution of genuine and imposter faces, which results in high mutual information between different views of the same identity. The effectiveness of the proposed model is investigated through extensive experiments, evaluations, and ablation studies on four benchmark datasets, and comparison with the compelling state-of-the-art algorithms.
Bengali Fake Review Detection using Semi-supervised Generative Adversarial Networks
Apr 05, 2023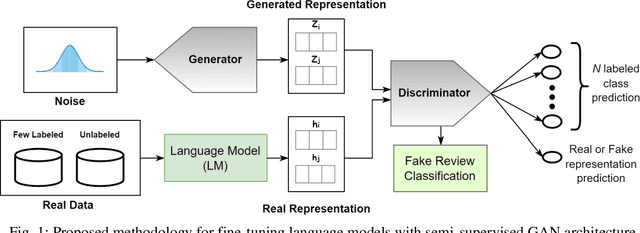
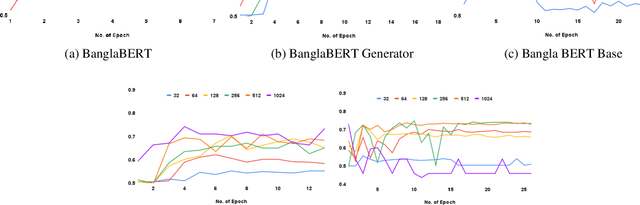
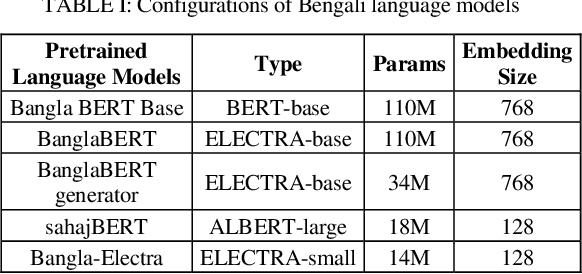
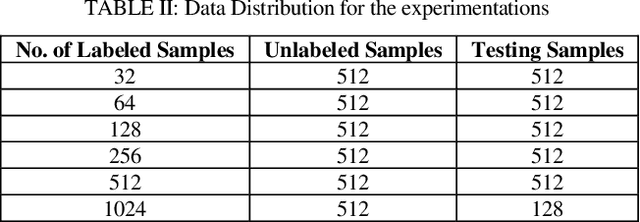
This paper investigates the potential of semi-supervised Generative Adversarial Networks (GANs) to fine-tune pretrained language models in order to classify Bengali fake reviews from real reviews with a few annotated data. With the rise of social media and e-commerce, the ability to detect fake or deceptive reviews is becoming increasingly important in order to protect consumers from being misled by false information. Any machine learning model will have trouble identifying a fake review, especially for a low resource language like Bengali. We have demonstrated that the proposed semi-supervised GAN-LM architecture (generative adversarial network on top of a pretrained language model) is a viable solution in classifying Bengali fake reviews as the experimental results suggest that even with only 1024 annotated samples, BanglaBERT with semi-supervised GAN (SSGAN) achieved an accuracy of 83.59% and a f1-score of 84.89% outperforming other pretrained language models - BanglaBERT generator, Bangla BERT Base and Bangla-Electra by almost 3%, 4% and 10% respectively in terms of accuracy. The experiments were conducted on a manually labeled food review dataset consisting of total 6014 real and fake reviews collected from various social media groups. Researchers that are experiencing difficulty recognizing not just fake reviews but other classification issues owing to a lack of labeled data may find a solution in our proposed methodology.
TM2D: Bimodality Driven 3D Dance Generation via Music-Text Integration
Apr 05, 2023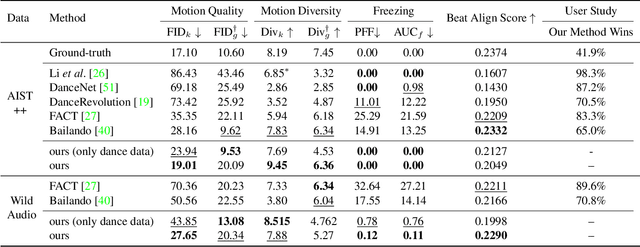
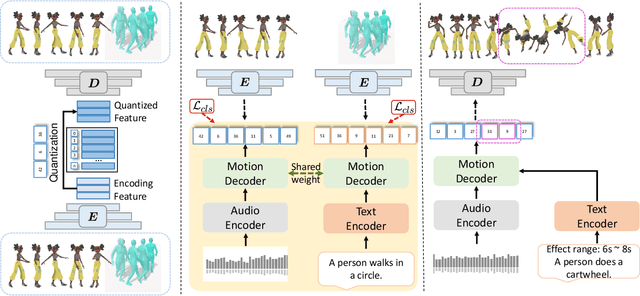
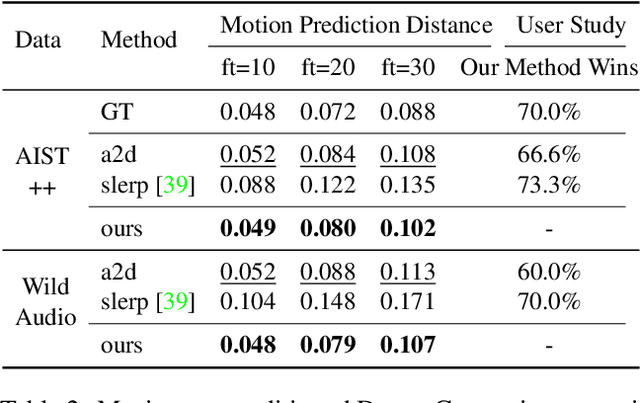
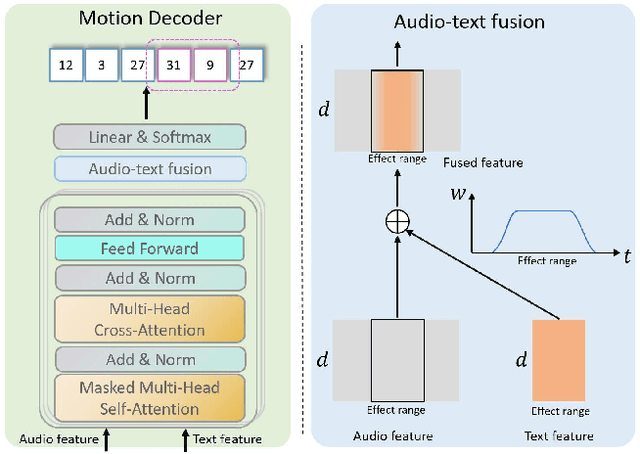
We propose a novel task for generating 3D dance movements that simultaneously incorporate both text and music modalities. Unlike existing works that generate dance movements using a single modality such as music, our goal is to produce richer dance movements guided by the instructive information provided by the text. However, the lack of paired motion data with both music and text modalities limits the ability to generate dance movements that integrate both. To alleviate this challenge, we propose to utilize a 3D human motion VQ-VAE to project the motions of the two datasets into a latent space consisting of quantized vectors, which effectively mix the motion tokens from the two datasets with different distributions for training. Additionally, we propose a cross-modal transformer to integrate text instructions into motion generation architecture for generating 3D dance movements without degrading the performance of music-conditioned dance generation. To better evaluate the quality of the generated motion, we introduce two novel metrics, namely Motion Prediction Distance (MPD) and Freezing Score, to measure the coherence and freezing percentage of the generated motion. Extensive experiments show that our approach can generate realistic and coherent dance movements conditioned on both text and music while maintaining comparable performance with the two single modalities. Code will be available at: https://garfield-kh.github.io/TM2D/.
METransformer: Radiology Report Generation by Transformer with Multiple Learnable Expert Tokens
Apr 05, 2023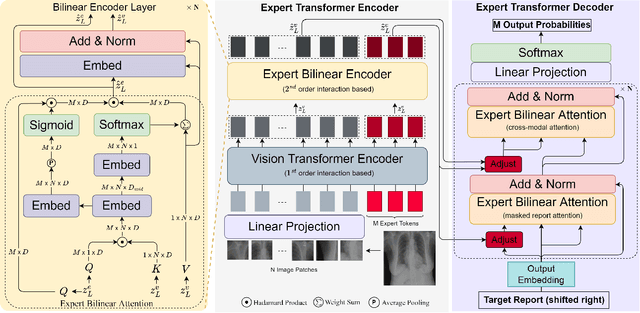
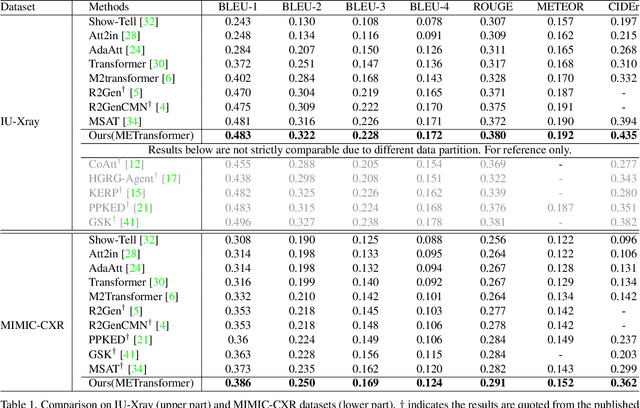
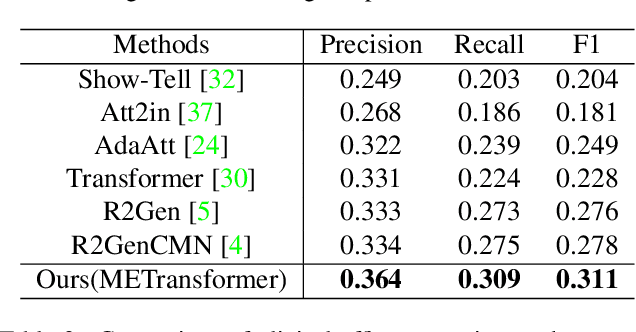
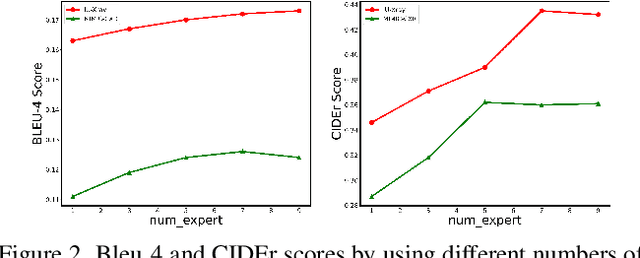
In clinical scenarios, multi-specialist consultation could significantly benefit the diagnosis, especially for intricate cases. This inspires us to explore a "multi-expert joint diagnosis" mechanism to upgrade the existing "single expert" framework commonly seen in the current literature. To this end, we propose METransformer, a method to realize this idea with a transformer-based backbone. The key design of our method is the introduction of multiple learnable "expert" tokens into both the transformer encoder and decoder. In the encoder, each expert token interacts with both vision tokens and other expert tokens to learn to attend different image regions for image representation. These expert tokens are encouraged to capture complementary information by an orthogonal loss that minimizes their overlap. In the decoder, each attended expert token guides the cross-attention between input words and visual tokens, thus influencing the generated report. A metrics-based expert voting strategy is further developed to generate the final report. By the multi-experts concept, our model enjoys the merits of an ensemble-based approach but through a manner that is computationally more efficient and supports more sophisticated interactions among experts. Experimental results demonstrate the promising performance of our proposed model on two widely used benchmarks. Last but not least, the framework-level innovation makes our work ready to incorporate advances on existing "single-expert" models to further improve its performance.
Spatial Scattering Modulation with Multipath Component Aggregation Based on Antenna Arrays
Apr 05, 2023
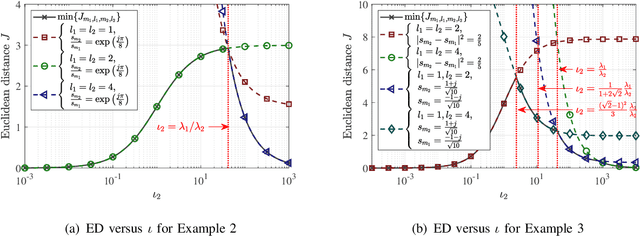
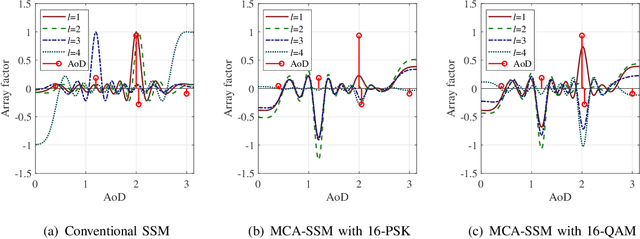
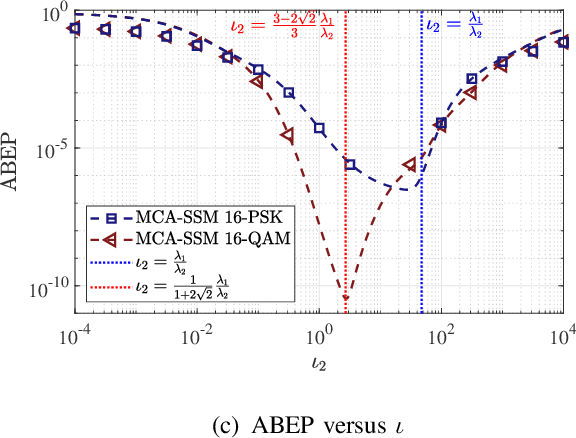
In this paper, a multipath component aggregation (MCA) mechanism is introduced for spatial scattering modulation (SSM) to overcome the limitation in conventional SSM that the transmit antenna array steers the beam to a single multipath (MP) component at each instance. In the proposed MCA-SSM system, information bits are divided into two streams. One is mapped to an amplitude-phase-modulation (APM) constellation symbol, and the other is mapped to a beam vector symbol which steers multiple beams to selected strongest MP components via an MCA matrix. In comparison with the conventional SSM system, the proposed MCA-SSM enhances the bit error performance by avoiding both low receiving power due to steering the beam to a single weak MP component and inter-MP interference due to MP components with close values of angle of arrival (AoA) or angle of departure (AoD). For the proposed MCA-SSM, a union upper bound (UUB) on the average bit error probability (ABEP) with any MCA matrix is analytically derived and validated via Monte Carlo simulations. Based on the UUB, the MCA matrix is analytically optimized to minimize the ABEP of the MCA-SSM. Finally, numerical experiments are carried out, which show that the proposed MCA-SSM system remarkably outperforms the state-of-the-art SSM system in terms of ABEP under a typical indoor environment.
Personality-aware Human-centric Multimodal Reasoning: A New Task
Apr 05, 2023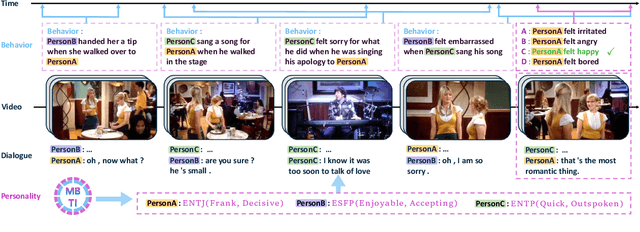
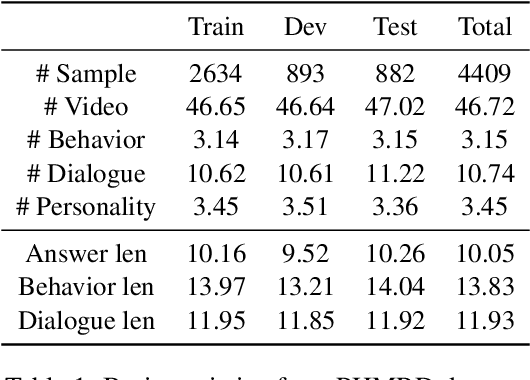

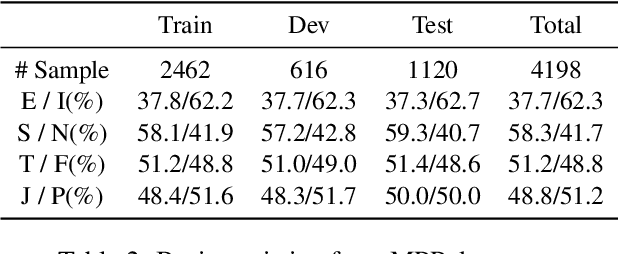
Multimodal reasoning, an area of artificial intelligence that aims at make inferences from multimodal signals such as vision, language and speech, has drawn more and more attention in recent years. People with different personalities may respond differently to the same situation. However, such individual personalities were ignored in the previous studies. In this work, we introduce a new Personality-aware Human-centric Multimodal Reasoning (Personality-aware HMR) task, and accordingly construct a new dataset based on The Big Bang Theory television shows, to predict the behavior of a specific person at a specific moment, given the multimodal information of its past and future moments. The Myers-Briggs Type Indicator (MBTI) was annotated and utilized in the task to represent individuals' personalities. We benchmark the task by proposing three baseline methods, two were adapted from the related tasks and one was newly proposed for our task. The experimental results demonstrate that personality can effectively improve the performance of human-centric multimodal reasoning. To further solve the lack of personality annotation in real-life scenes, we introduce an extended task called Personality-predicted HMR, and propose the corresponding methods, to predict the MBTI personality at first, and then use the predicted personality to help multimodal reasoning. The experimental results show that our method can accurately predict personality and achieves satisfactory multimodal reasoning performance without relying on personality annotations.
Towards Diverse Binary Segmentation via A Simple yet General Gated Network
Mar 18, 2023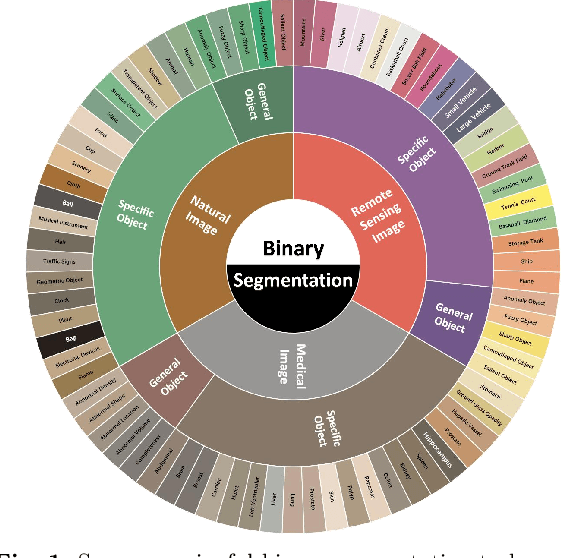
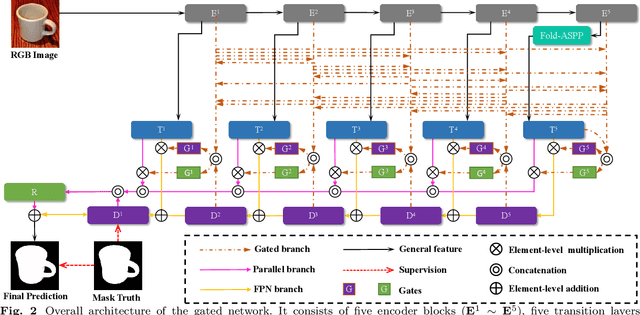
In many binary segmentation tasks, most CNNs-based methods use a U-shape encoder-decoder network as their basic structure. They ignore two key problems when the encoder exchanges information with the decoder: one is the lack of interference control mechanism between them, the other is without considering the disparity of the contributions from different encoder levels. In this work, we propose a simple yet general gated network (GateNet) to tackle them all at once. With the help of multi-level gate units, the valuable context information from the encoder can be selectively transmitted to the decoder. In addition, we design a gated dual branch structure to build the cooperation among the features of different levels and improve the discrimination ability of the network. Furthermore, we introduce a ``Fold'' operation to improve the atrous convolution and form a novel folded atrous convolution, which can be flexibly embedded in ASPP or DenseASPP to accurately localize foreground objects of various scales. GateNet can be easily generalized to many binary segmentation tasks, including general and specific object segmentation and multi-modal segmentation. Without bells and whistles, our network consistently performs favorably against the state-of-the-art methods under 10 metrics on 33 datasets of 10 binary segmentation tasks.
Gaussian Max-Value Entropy Search for Multi-Agent Bayesian Optimization
Mar 10, 2023


We study the multi-agent Bayesian optimization (BO) problem, where multiple agents maximize a black-box function via iterative queries. We focus on Entropy Search (ES), a sample-efficient BO algorithm that selects queries to maximize the mutual information about the maximum of the black-box function. One of the main challenges of ES is that calculating the mutual information requires computationally-costly approximation techniques. For multi-agent BO problems, the computational cost of ES is exponential in the number of agents. To address this challenge, we propose the Gaussian Max-value Entropy Search, a multi-agent BO algorithm with favorable sample and computational efficiency. The key to our idea is to use a normal distribution to approximate the function maximum and calculate its mutual information accordingly. The resulting approximation allows queries to be cast as the solution of a closed-form optimization problem which, in turn, can be solved via a modified gradient ascent algorithm and scaled to a large number of agents. We demonstrate the effectiveness of Gaussian max-value Entropy Search through numerical experiments on standard test functions and real-robot experiments on the source-seeking problem. Results show that the proposed algorithm outperforms the multi-agent BO baselines in the numerical experiments and can stably seek the source with a limited number of noisy observations on real robots.
Adaptive Supervised PatchNCE Loss for Learning H&E-to-IHC Stain Translation with Inconsistent Groundtruth Image Pairs
Mar 10, 2023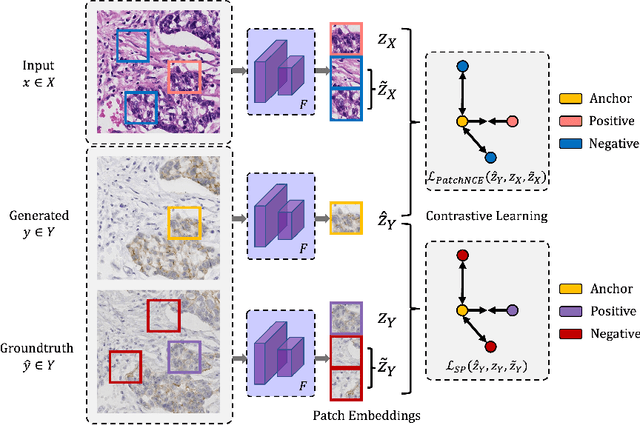
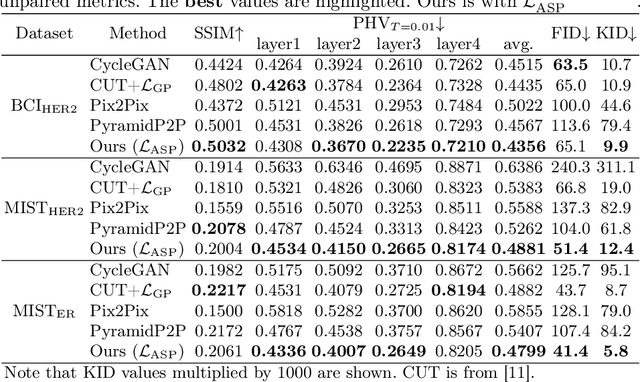
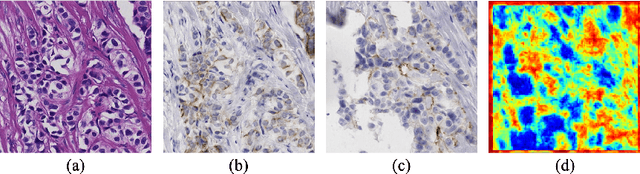
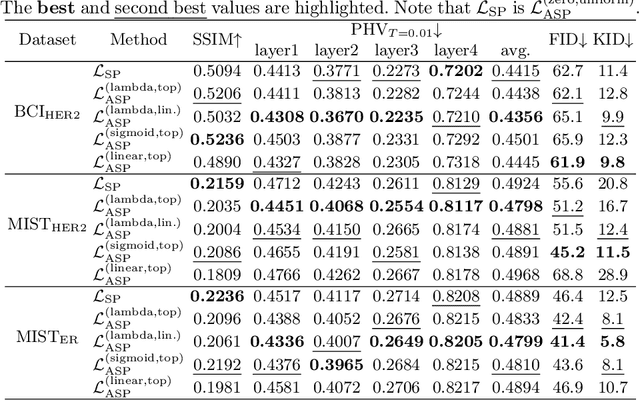
Immunohistochemical (IHC) staining highlights the molecular information critical to diagnostics in tissue samples. However, compared to H&E staining, IHC staining can be much more expensive in terms of both labor and the laboratory equipment required. This motivates recent research that demonstrates that the correlations between the morphological information present in the H&E-stained slides and the molecular information in the IHC-stained slides can be used for H&E-to-IHC stain translation. However, due to a lack of pixel-perfect H&E-IHC groundtruth pairs, most existing methods have resorted to relying on expert annotations. To remedy this situation, we present a new loss function, Adaptive Supervised PatchNCE (ASP), to directly deal with the input to target inconsistencies in a proposed H&E-to-IHC image-to-image translation framework. The ASP loss is built upon a patch-based contrastive learning criterion, named Supervised PatchNCE (SP), and augments it further with weight scheduling to mitigate the negative impact of noisy supervision. Lastly, we introduce the Multi-IHC Stain Translation (MIST) dataset, which contains aligned H&E-IHC patches for 4 different IHC stains critical to breast cancer diagnosis. In our experiment, we demonstrate that our proposed method outperforms existing image-to-image translation methods for stain translation to multiple IHC stains. All of our code and datasets are available at https://github.com/lifangda01/AdaptiveSupervisedPatchNCE.