 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNECromancer: Breathing Life into Skeletons via BVH Animation
Feb 06, 2026Motion tokenization is a key component of generalizable motion models, yet most existing approaches are restricted to species-specific skeletons, limiting their applicability across diverse morphologies. We propose NECromancer (NEC), a universal motion tokenizer that operates directly on arbitrary BVH skeletons. NEC consists of three components: (1) an Ontology-aware Skeletal Graph Encoder (OwO) that encodes structural priors from BVH files, including joint semantics, rest-pose offsets, and skeletal topology, into skeletal embeddings; (2) a Topology-Agnostic Tokenizer (TAT) that compresses motion sequences into a universal, topology-invariant discrete representation; and (3) the Unified BVH Universe (UvU), a large-scale dataset aggregating BVH motions across heterogeneous skeletons. Experiments show that NEC achieves high-fidelity reconstruction under substantial compression and effectively disentangles motion from skeletal structure. The resulting token space supports cross-species motion transfer, composition, denoising, generation with token-based models, and text-motion retrieval, establishing a unified framework for motion analysis and synthesis across diverse morphologies. Demo page: https://animotionlab.github.io/NECromancer/
DiMo: Discrete Diffusion Modeling for Motion Generation and Understanding
Feb 04, 2026Prior masked modeling motion generation methods predominantly study text-to-motion. We present DiMo, a discrete diffusion-style framework, which extends masked modeling to bidirectional text--motion understanding and generation. Unlike GPT-style autoregressive approaches that tokenize motion and decode sequentially, DiMo performs iterative masked token refinement, unifying Text-to-Motion (T2M), Motion-to-Text (M2T), and text-free Motion-to-Motion (M2M) within a single model. This decoding paradigm naturally enables a quality-latency trade-off at inference via the number of refinement steps.We further improve motion token fidelity with residual vector quantization (RVQ) and enhance alignment and controllability with Group Relative Policy Optimization (GRPO). Experiments on HumanML3D and KIT-ML show strong motion quality and competitive bidirectional understanding under a unified framework. In addition, we demonstrate model ability in text-free motion completion, text-guided motion prediction and motion caption correction without architectural change.Additional qualitative results are available on our project page: https://animotionlab.github.io/DiMo/.
SWiT-4D: Sliding-Window Transformer for Lossless and Parameter-Free Temporal 4D Generation
Dec 11, 2025



Despite significant progress in 4D content generation, the conversion of monocular videos into high-quality animated 3D assets with explicit 4D meshes remains considerably challenging. The scarcity of large-scale, naturally captured 4D mesh datasets further limits the ability to train generalizable video-to-4D models from scratch in a purely data-driven manner. Meanwhile, advances in image-to-3D generation, supported by extensive datasets, offer powerful prior models that can be leveraged. To better utilize these priors while minimizing reliance on 4D supervision, we introduce SWiT-4D, a Sliding-Window Transformer for lossless, parameter-free temporal 4D mesh generation. SWiT-4D integrates seamlessly with any Diffusion Transformer (DiT)-based image-to-3D generator, adding spatial-temporal modeling across video frames while preserving the original single-image forward process, enabling 4D mesh reconstruction from videos of arbitrary length. To recover global translation, we further introduce an optimization-based trajectory module tailored for static-camera monocular videos. SWiT-4D demonstrates strong data efficiency: with only a single short (<10s) video for fine-tuning, it achieves high-fidelity geometry and stable temporal consistency, indicating practical deployability under extremely limited 4D supervision. Comprehensive experiments on both in-domain zoo-test sets and challenging out-of-domain benchmarks (C4D, Objaverse, and in-the-wild videos) show that SWiT-4D consistently outperforms existing baselines in temporal smoothness. Project page: https://animotionlab.github.io/SWIT4D/
MoCapAnything: Unified 3D Motion Capture for Arbitrary Skeletons from Monocular Videos
Dec 11, 2025Motion capture now underpins content creation far beyond digital humans, yet most existing pipelines remain species- or template-specific. We formalize this gap as Category-Agnostic Motion Capture (CAMoCap): given a monocular video and an arbitrary rigged 3D asset as a prompt, the goal is to reconstruct a rotation-based animation such as BVH that directly drives the specific asset. We present MoCapAnything, a reference-guided, factorized framework that first predicts 3D joint trajectories and then recovers asset-specific rotations via constraint-aware inverse kinematics. The system contains three learnable modules and a lightweight IK stage: (1) a Reference Prompt Encoder that extracts per-joint queries from the asset's skeleton, mesh, and rendered images; (2) a Video Feature Extractor that computes dense visual descriptors and reconstructs a coarse 4D deforming mesh to bridge the gap between video and joint space; and (3) a Unified Motion Decoder that fuses these cues to produce temporally coherent trajectories. We also curate Truebones Zoo with 1038 motion clips, each providing a standardized skeleton-mesh-render triad. Experiments on both in-domain benchmarks and in-the-wild videos show that MoCapAnything delivers high-quality skeletal animations and exhibits meaningful cross-species retargeting across heterogeneous rigs, enabling scalable, prompt-driven 3D motion capture for arbitrary assets. Project page: https://animotionlab.github.io/MoCapAnything/
MotionMix: Weakly-Supervised Diffusion for Controllable Motion Generation
Jan 24, 2024



Controllable generation of 3D human motions becomes an important topic as the world embraces digital transformation. Existing works, though making promising progress with the advent of diffusion models, heavily rely on meticulously captured and annotated (e.g., text) high-quality motion corpus, a resource-intensive endeavor in the real world. This motivates our proposed MotionMix, a simple yet effective weakly-supervised diffusion model that leverages both noisy and unannotated motion sequences. Specifically, we separate the denoising objectives of a diffusion model into two stages: obtaining conditional rough motion approximations in the initial $T-T^*$ steps by learning the noisy annotated motions, followed by the unconditional refinement of these preliminary motions during the last $T^*$ steps using unannotated motions. Notably, though learning from two sources of imperfect data, our model does not compromise motion generation quality compared to fully supervised approaches that access gold data. Extensive experiments on several benchmarks demonstrate that our MotionMix, as a versatile framework, consistently achieves state-of-the-art performances on text-to-motion, action-to-motion, and music-to-dance tasks. Project page: https://nhathoang2002.github.io/MotionMix-page/
Priority-Centric Human Motion Generation in Discrete Latent Space
Aug 30, 2023Text-to-motion generation is a formidable task, aiming to produce human motions that align with the input text while also adhering to human capabilities and physical laws. While there have been advancements in diffusion models, their application in discrete spaces remains underexplored. Current methods often overlook the varying significance of different motions, treating them uniformly. It is essential to recognize that not all motions hold the same relevance to a particular textual description. Some motions, being more salient and informative, should be given precedence during generation. In response, we introduce a Priority-Centric Motion Discrete Diffusion Model (M2DM), which utilizes a Transformer-based VQ-VAE to derive a concise, discrete motion representation, incorporating a global self-attention mechanism and a regularization term to counteract code collapse. We also present a motion discrete diffusion model that employs an innovative noise schedule, determined by the significance of each motion token within the entire motion sequence. This approach retains the most salient motions during the reverse diffusion process, leading to more semantically rich and varied motions. Additionally, we formulate two strategies to gauge the importance of motion tokens, drawing from both textual and visual indicators. Comprehensive experiments on the HumanML3D and KIT-ML datasets confirm that our model surpasses existing techniques in fidelity and diversity, particularly for intricate textual descriptions.
TM2D: Bimodality Driven 3D Dance Generation via Music-Text Integration
Apr 05, 2023



We propose a novel task for generating 3D dance movements that simultaneously incorporate both text and music modalities. Unlike existing works that generate dance movements using a single modality such as music, our goal is to produce richer dance movements guided by the instructive information provided by the text. However, the lack of paired motion data with both music and text modalities limits the ability to generate dance movements that integrate both. To alleviate this challenge, we propose to utilize a 3D human motion VQ-VAE to project the motions of the two datasets into a latent space consisting of quantized vectors, which effectively mix the motion tokens from the two datasets with different distributions for training. Additionally, we propose a cross-modal transformer to integrate text instructions into motion generation architecture for generating 3D dance movements without degrading the performance of music-conditioned dance generation. To better evaluate the quality of the generated motion, we introduce two novel metrics, namely Motion Prediction Distance (MPD) and Freezing Score, to measure the coherence and freezing percentage of the generated motion. Extensive experiments show that our approach can generate realistic and coherent dance movements conditioned on both text and music while maintaining comparable performance with the two single modalities. Code will be available at: https://garfield-kh.github.io/TM2D/.
PoseTriplet: Co-evolving 3D Human Pose Estimation, Imitation, and Hallucination under Self-supervision
Mar 29, 2022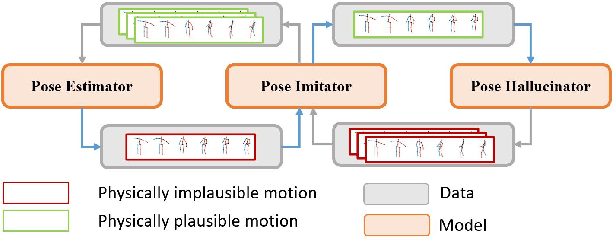
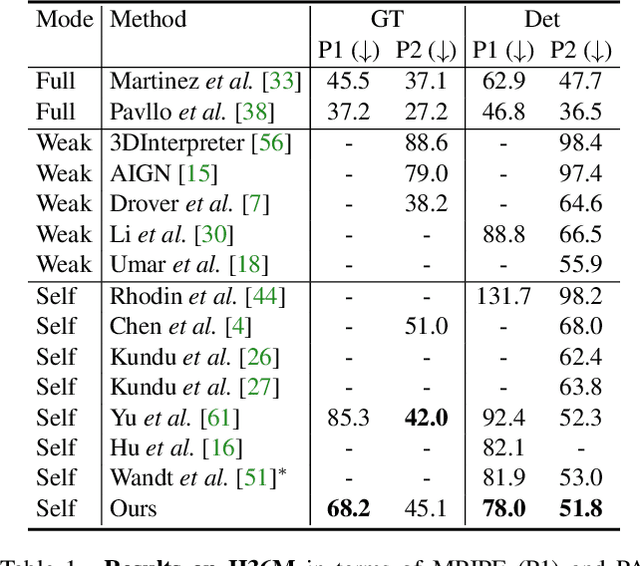
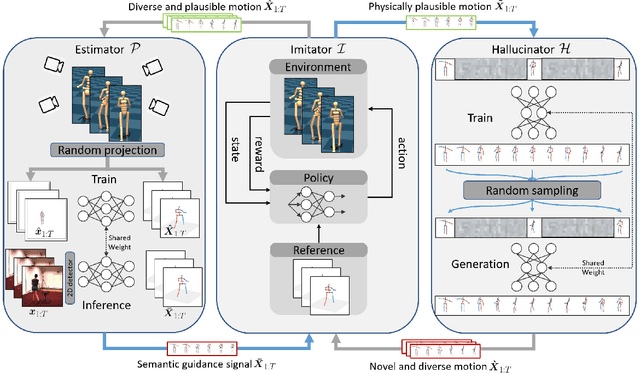
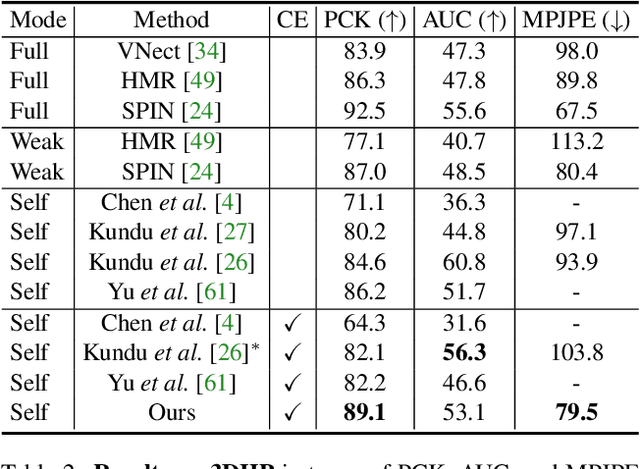
Existing self-supervised 3D human pose estimation schemes have largely relied on weak supervisions like consistency loss to guide the learning, which, inevitably, leads to inferior results in real-world scenarios with unseen poses. In this paper, we propose a novel self-supervised approach that allows us to explicitly generate 2D-3D pose pairs for augmenting supervision, through a self-enhancing dual-loop learning framework. This is made possible via introducing a reinforcement-learning-based imitator, which is learned jointly with a pose estimator alongside a pose hallucinator; the three components form two loops during the training process, complementing and strengthening one another. Specifically, the pose estimator transforms an input 2D pose sequence to a low-fidelity 3D output, which is then enhanced by the imitator that enforces physical constraints. The refined 3D poses are subsequently fed to the hallucinator for producing even more diverse data, which are, in turn, strengthened by the imitator and further utilized to train the pose estimator. Such a co-evolution scheme, in practice, enables training a pose estimator on self-generated motion data without relying on any given 3D data. Extensive experiments across various benchmarks demonstrate that our approach yields encouraging results significantly outperforming the state of the art and, in some cases, even on par with results of fully-supervised methods. Notably, it achieves 89.1% 3D PCK on MPI-INF-3DHP under self-supervised cross-dataset evaluation setup, improving upon the previous best self-supervised methods by 8.6%. Code can be found at: https://github.com/Garfield-kh/PoseTriplet
PoseAug: A Differentiable Pose Augmentation Framework for 3D Human Pose Estimation
May 06, 2021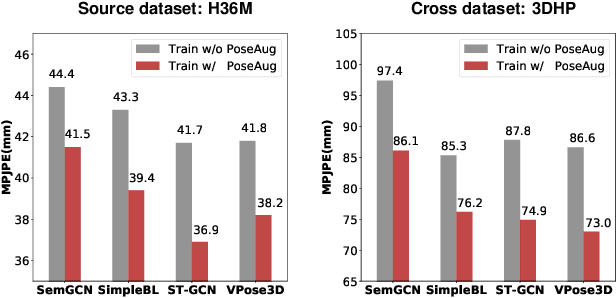
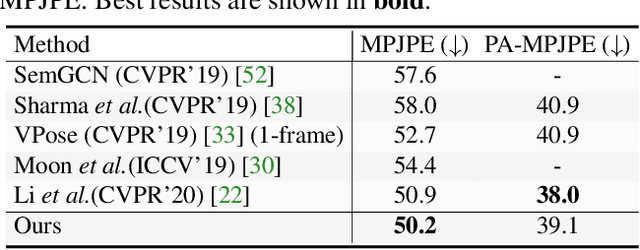
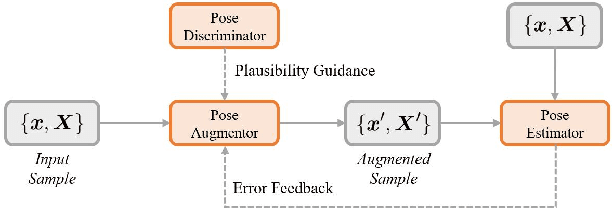
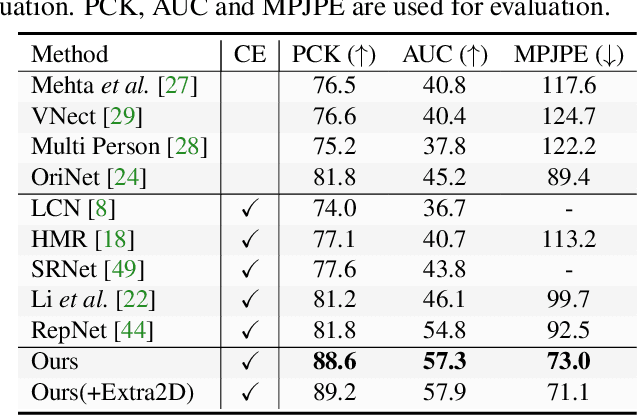
Existing 3D human pose estimators suffer poor generalization performance to new datasets, largely due to the limited diversity of 2D-3D pose pairs in the training data. To address this problem, we present PoseAug, a new auto-augmentation framework that learns to augment the available training poses towards a greater diversity and thus improve generalization of the trained 2D-to-3D pose estimator. Specifically, PoseAug introduces a novel pose augmentor that learns to adjust various geometry factors (e.g., posture, body size, view point and position) of a pose through differentiable operations. With such differentiable capacity, the augmentor can be jointly optimized with the 3D pose estimator and take the estimation error as feedback to generate more diverse and harder poses in an online manner. Moreover, PoseAug introduces a novel part-aware Kinematic Chain Space for evaluating local joint-angle plausibility and develops a discriminative module accordingly to ensure the plausibility of the augmented poses. These elaborate designs enable PoseAug to generate more diverse yet plausible poses than existing offline augmentation methods, and thus yield better generalization of the pose estimator. PoseAug is generic and easy to be applied to various 3D pose estimators. Extensive experiments demonstrate that PoseAug brings clear improvements on both intra-scenario and cross-scenario datasets. Notably, it achieves 88.6% 3D PCK on MPI-INF-3DHP under cross-dataset evaluation setup, improving upon the previous best data augmentation based method by 9.1%. Code can be found at: https://github.com/jfzhang95/PoseAug.