 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Categorization of Complexity Classes for Information Retrieval and Synthesis Using Natural Logic
Feb 28, 2024
Given the emergent reasoning abilities of large language models, information retrieval is becoming more complex. Rather than just retrieve a document, modern information retrieval systems advertise that they can synthesize an answer based on potentially many different documents, conflicting data sources, and using reasoning. But, different kinds of questions have different answers, and different answers have different complexities. In this paper, we introduce a novel framework for analyzing the complexity of a question answer based on the natural deduction calculus as presented in Prawitz (1965). Our framework is novel both in that no one to our knowledge has used this logic as a basis for complexity classes, and also in that no other existing complexity classes to these have been delineated using any analogous methods either. We identify three decidable fragments in particular called the forward, query and planning fragments, and we compare this to what would be needed to do proofs for the complete first-order calculus, for which theorem-proving is long known to be undecidable.
D-Cubed: Latent Diffusion Trajectory Optimisation for Dexterous Deformable Manipulation
Mar 19, 2024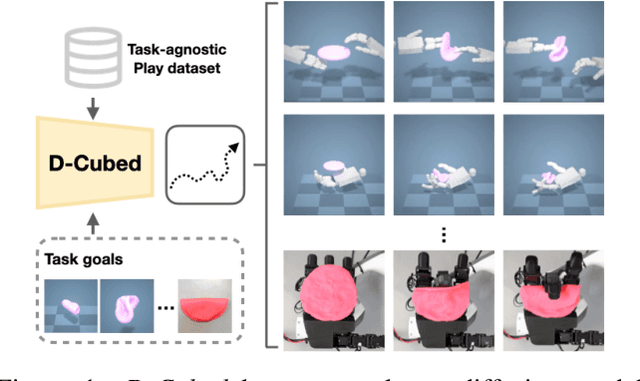

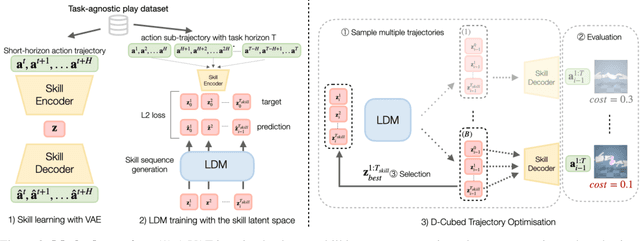
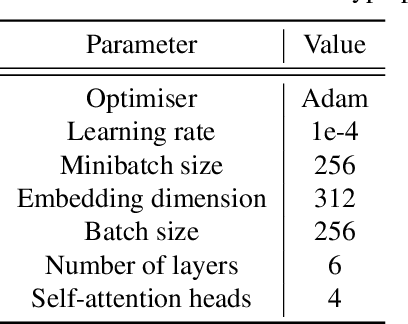
Mastering dexterous robotic manipulation of deformable objects is vital for overcoming the limitations of parallel grippers in real-world applications. Current trajectory optimisation approaches often struggle to solve such tasks due to the large search space and the limited task information available from a cost function. In this work, we propose D-Cubed, a novel trajectory optimisation method using a latent diffusion model (LDM) trained from a task-agnostic play dataset to solve dexterous deformable object manipulation tasks. D-Cubed learns a skill-latent space that encodes short-horizon actions in the play dataset using a VAE and trains a LDM to compose the skill latents into a skill trajectory, representing a long-horizon action trajectory in the dataset. To optimise a trajectory for a target task, we introduce a novel gradient-free guided sampling method that employs the Cross-Entropy method within the reverse diffusion process. In particular, D-Cubed samples a small number of noisy skill trajectories using the LDM for exploration and evaluates the trajectories in simulation. Then, D-Cubed selects the trajectory with the lowest cost for the subsequent reverse process. This effectively explores promising solution areas and optimises the sampled trajectories towards a target task throughout the reverse diffusion process. Through empirical evaluation on a public benchmark of dexterous deformable object manipulation tasks, we demonstrate that D-Cubed outperforms traditional trajectory optimisation and competitive baseline approaches by a significant margin. We further demonstrate that trajectories found by D-Cubed readily transfer to a real-world LEAP hand on a folding task.
Towards Multimodal In-Context Learning for Vision & Language Models
Mar 19, 2024
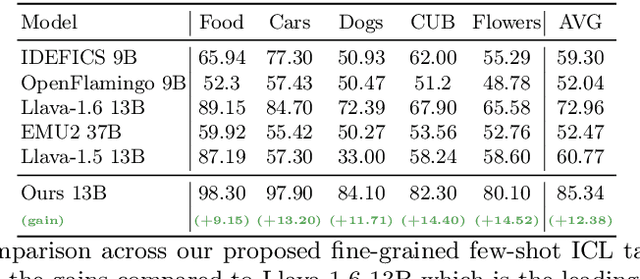
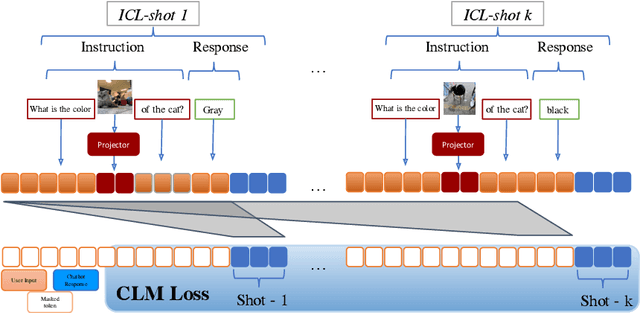
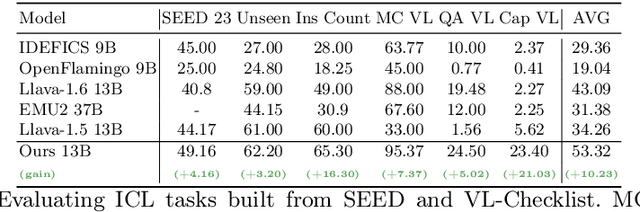
Inspired by the emergence of Large Language Models (LLMs) that can truly understand human language, significant progress has been made in aligning other, non-language, modalities to be `understandable' by an LLM, primarily via converting their samples into a sequence of embedded language-like tokens directly fed into the LLM (decoder) input stream. However, so far limited attention has been given to transferring (and evaluating) one of the core LLM capabilities to the emerging VLMs, namely the In-Context Learning (ICL) ability, or in other words to guide VLMs to desired target downstream tasks or output structure using in-context image+text demonstrations. In this work, we dive deeper into analyzing the capabilities of some of the state-of-the-art VLMs to follow ICL instructions, discovering them to be somewhat lacking. We discover that even models that underwent large-scale mixed modality pre-training and were implicitly guided to make use of interleaved image and text information (intended to consume helpful context from multiple images) under-perform when prompted with few-shot (ICL) demonstrations, likely due to their lack of `direct' ICL instruction tuning. To test this conjecture, we propose a simple, yet surprisingly effective, strategy of extending a common VLM alignment framework with ICL support, methodology, and curriculum. We explore, analyze, and provide insights into effective data mixes, leading up to a significant 21.03% (and 11.3% on average) ICL performance boost over the strongest VLM baselines and a variety of ICL benchmarks. We also contribute new benchmarks for ICL evaluation in VLMs and discuss their advantages over the prior art.
Distribution and Depth-Aware Transformers for 3D Human Mesh Recovery
Mar 14, 2024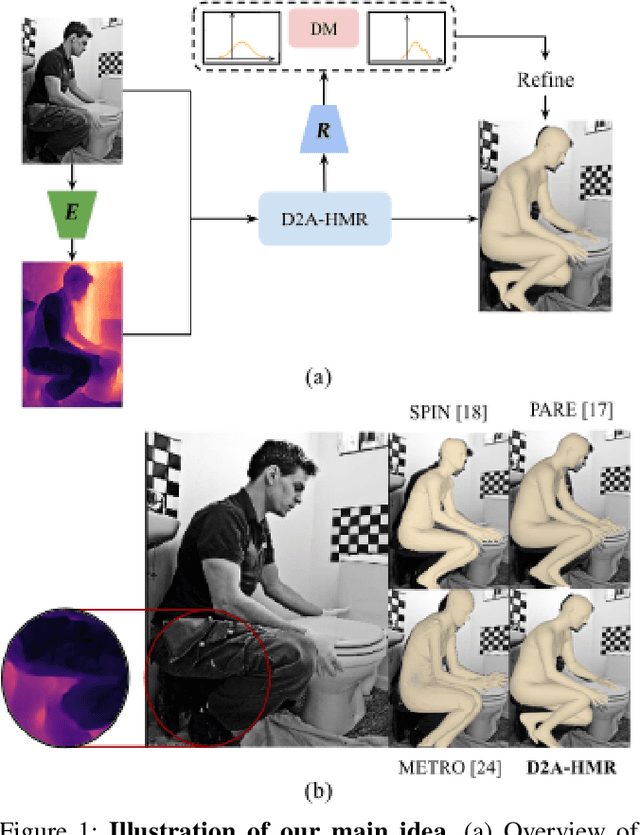
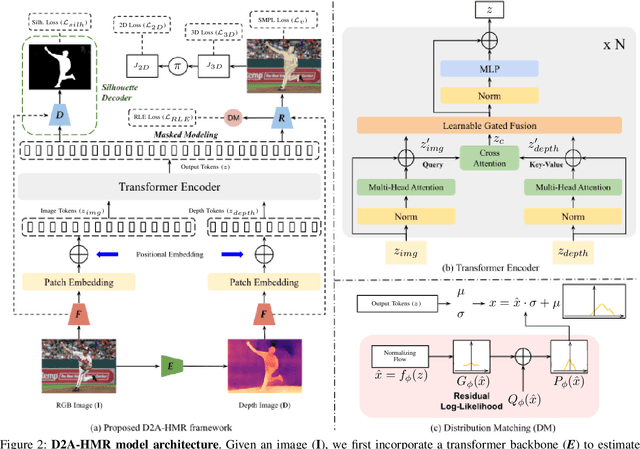


Precise Human Mesh Recovery (HMR) with in-the-wild data is a formidable challenge and is often hindered by depth ambiguities and reduced precision. Existing works resort to either pose priors or multi-modal data such as multi-view or point cloud information, though their methods often overlook the valuable scene-depth information inherently present in a single image. Moreover, achieving robust HMR for out-of-distribution (OOD) data is exceedingly challenging due to inherent variations in pose, shape and depth. Consequently, understanding the underlying distribution becomes a vital subproblem in modeling human forms. Motivated by the need for unambiguous and robust human modeling, we introduce Distribution and depth-aware human mesh recovery (D2A-HMR), an end-to-end transformer architecture meticulously designed to minimize the disparity between distributions and incorporate scene-depth leveraging prior depth information. Our approach demonstrates superior performance in handling OOD data in certain scenarios while consistently achieving competitive results against state-of-the-art HMR methods on controlled datasets.
Contextual Clarity: Generating Sentences with Transformer Models using Context-Reverso Data
Mar 14, 2024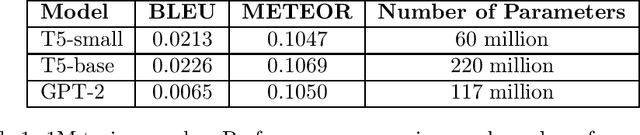

In the age of information abundance, the ability to provide users with contextually relevant and concise information is crucial. Keyword in Context (KIC) generation is a task that plays a vital role in and generation applications, such as search engines, personal assistants, and content summarization. In this paper, we present a novel approach to generating unambiguous and brief sentence-contexts for given keywords using the T5 transformer model, leveraging data obtained from the Context-Reverso API. The code is available at https://github.com/Rusamus/word2context/tree/main .
rFaceNet: An End-to-End Network for Enhanced Physiological Signal Extraction through Identity-Specific Facial Contours
Mar 17, 2024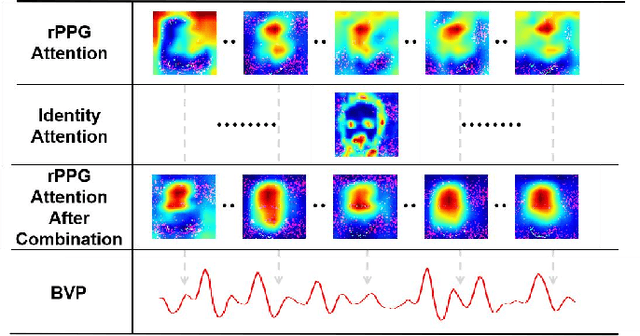
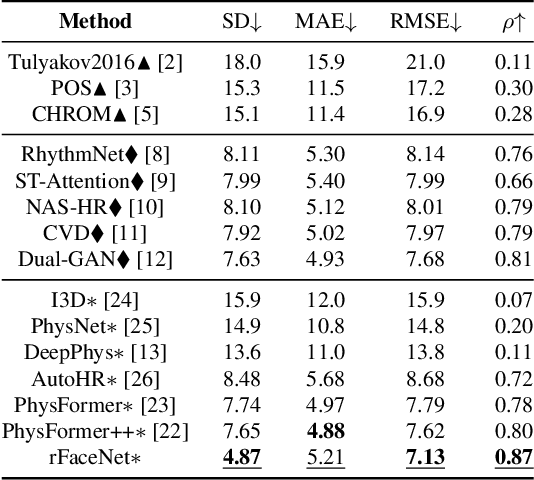
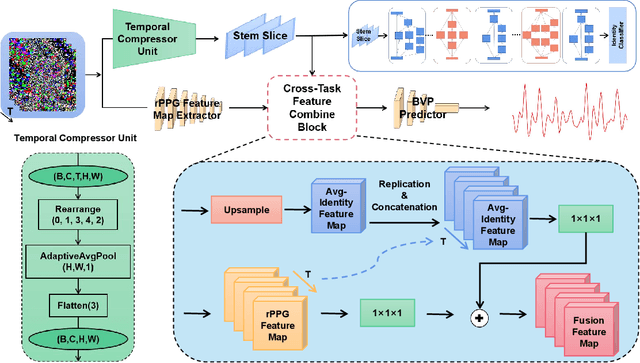
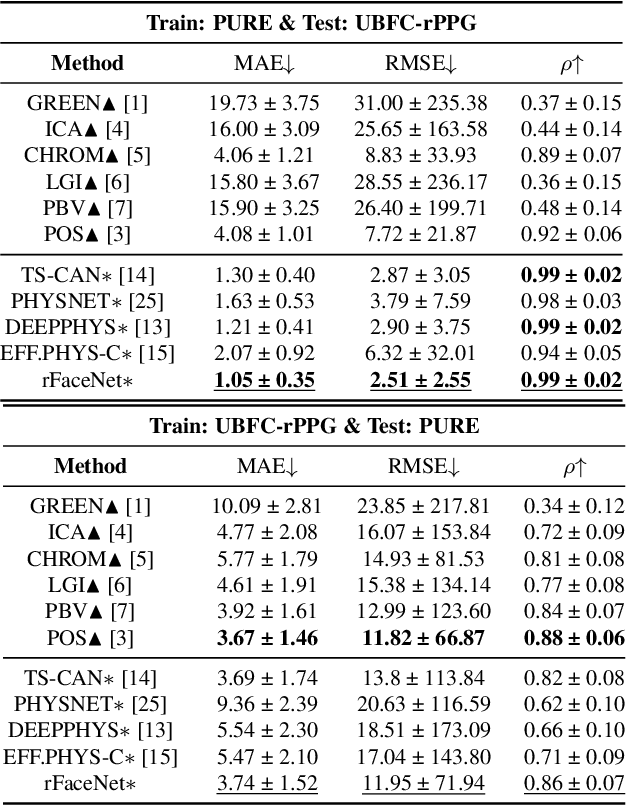
Remote photoplethysmography (rPPG) technique extracts blood volume pulse (BVP) signals from subtle pixel changes in video frames. This study introduces rFaceNet, an advanced rPPG method that enhances the extraction of facial BVP signals with a focus on facial contours. rFaceNet integrates identity-specific facial contour information and eliminates redundant data. It efficiently extracts facial contours from temporally normalized frame inputs through a Temporal Compressor Unit (TCU) and steers the model focus to relevant facial regions by using the Cross-Task Feature Combiner (CTFC). Through elaborate training, the quality and interpretability of facial physiological signals extracted by rFaceNet are greatly improved compared to previous methods. Moreover, our novel approach demonstrates superior performance than SOTA methods in various heart rate estimation benchmarks.
VideoAgent: Long-form Video Understanding with Large Language Model as Agent
Mar 15, 2024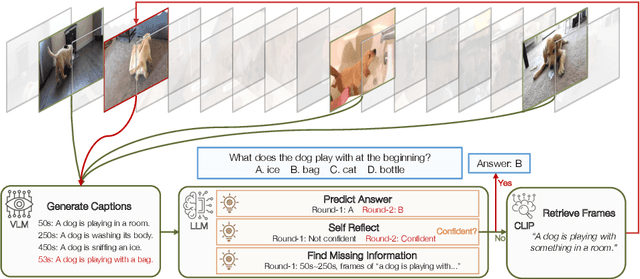
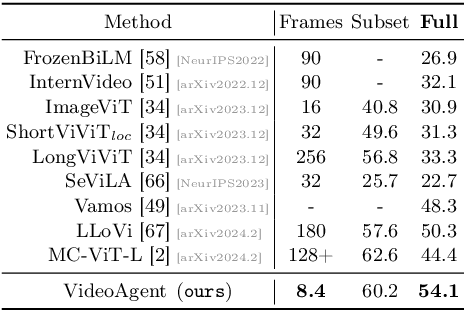

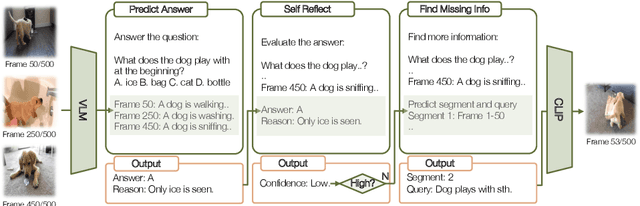
Long-form video understanding represents a significant challenge within computer vision, demanding a model capable of reasoning over long multi-modal sequences. Motivated by the human cognitive process for long-form video understanding, we emphasize interactive reasoning and planning over the ability to process lengthy visual inputs. We introduce a novel agent-based system, VideoAgent, that employs a large language model as a central agent to iteratively identify and compile crucial information to answer a question, with vision-language foundation models serving as tools to translate and retrieve visual information. Evaluated on the challenging EgoSchema and NExT-QA benchmarks, VideoAgent achieves 54.1% and 71.3% zero-shot accuracy with only 8.4 and 8.2 frames used on average. These results demonstrate superior effectiveness and efficiency of our method over the current state-of-the-art methods, highlighting the potential of agent-based approaches in advancing long-form video understanding.
Knowledge and Data Dual-Driven Channel Estimation and Feedback for Ultra-Massive MIMO Systems under Hybrid Field Beam Squint Effect
Mar 19, 2024
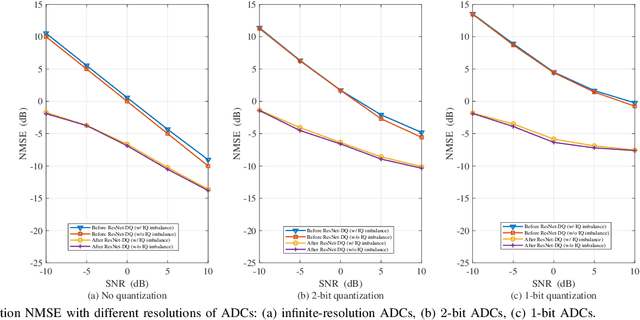
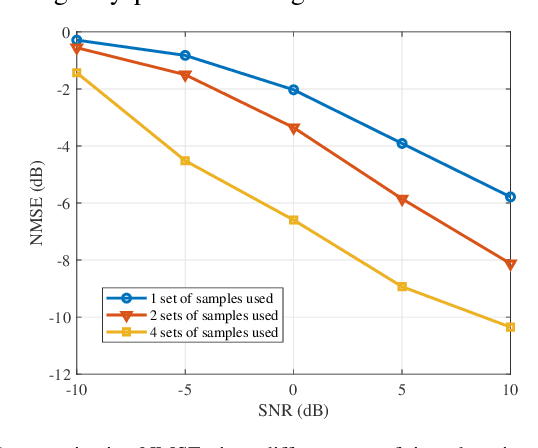
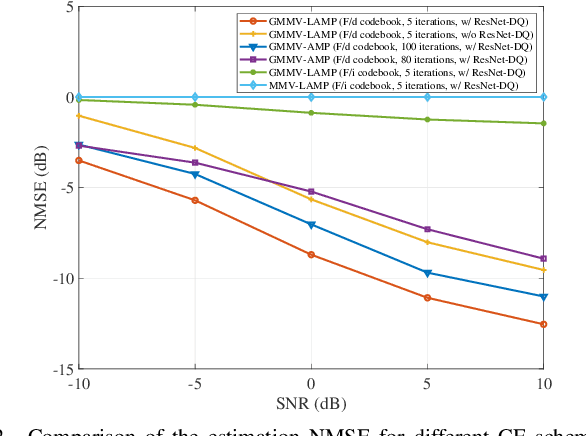
Acquiring accurate channel state information (CSI) at an access point (AP) is challenging for wideband millimeter wave (mmWave) ultra-massive multiple-input and multiple-output (UMMIMO) systems, due to the high-dimensional channel matrices, hybrid near- and far- field channel feature, beam squint effects, and imperfect hardware constraints, such as low-resolution analog-to-digital converters, and in-phase and quadrature imbalance. To overcome these challenges, this paper proposes an efficient downlink channel estimation (CE) and CSI feedback approach based on knowledge and data dual-driven deep learning (DL) networks. Specifically, we first propose a data-driven residual neural network de-quantizer (ResNet-DQ) to pre-process the received pilot signals at user equipment (UEs), where the noise and distortion brought by imperfect hardware can be mitigated. A knowledge-driven generalized multiple measurement vector learned approximate message passing (GMMV-LAMP) network is then developed to jointly estimate the channels by exploiting the approximately same physical angle shared by different subcarriers. In particular, two wideband redundant dictionaries (WRDs) are proposed such that the measurement matrices of the GMMV-LAMP network can accommodate the far-field and near-field beam squint effect, respectively. Finally, we propose an encoder at the UEs and a decoder at the AP by a data-driven CSI residual network (CSI-ResNet) to compress the CSI matrix into a low-dimensional quantized bit vector for feedback, thereby reducing the feedback overhead substantially. Simulation results show that the proposed knowledge and data dual-driven approach outperforms conventional downlink CE and CSI feedback methods, especially in the case of low signal-to-noise ratios.
Advancing Time Series Classification with Multimodal Language Modeling
Mar 19, 2024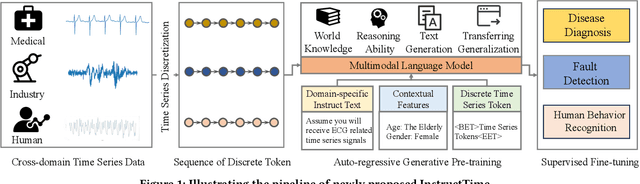
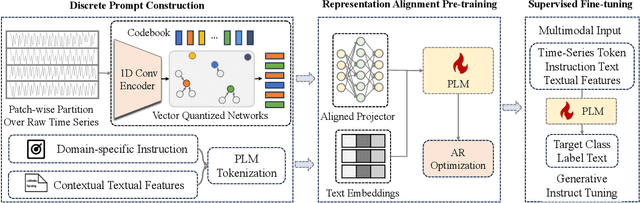

For the advancements of time series classification, scrutinizing previous studies, most existing methods adopt a common learning-to-classify paradigm - a time series classifier model tries to learn the relation between sequence inputs and target label encoded by one-hot distribution. Although effective, this paradigm conceals two inherent limitations: (1) encoding target categories with one-hot distribution fails to reflect the comparability and similarity between labels, and (2) it is very difficult to learn transferable model across domains, which greatly hinder the development of universal serving paradigm. In this work, we propose InstructTime, a novel attempt to reshape time series classification as a learning-to-generate paradigm. Relying on the powerful generative capacity of the pre-trained language model, the core idea is to formulate the classification of time series as a multimodal understanding task, in which both task-specific instructions and raw time series are treated as multimodal inputs while the label information is represented by texts. To accomplish this goal, three distinct designs are developed in the InstructTime. Firstly, a time series discretization module is designed to convert continuous time series into a sequence of hard tokens to solve the inconsistency issue across modal inputs. To solve the modality representation gap issue, for one thing, we introduce an alignment projected layer before feeding the transformed token of time series into language models. For another, we highlight the necessity of auto-regressive pre-training across domains, which can facilitate the transferability of the language model and boost the generalization performance. Extensive experiments are conducted over benchmark datasets, whose results uncover the superior performance of InstructTime and the potential for a universal foundation model in time series classification.
Semisupervised score based matching algorithm to evaluate the effect of public health interventions
Mar 19, 2024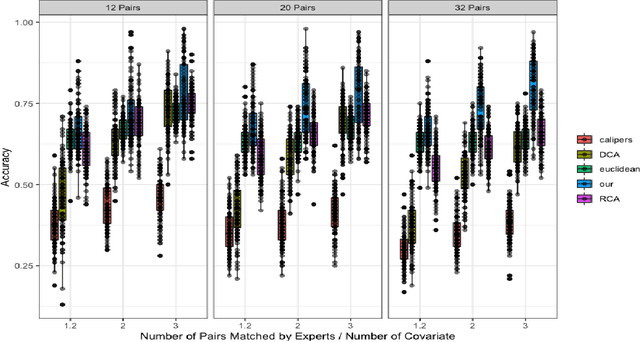
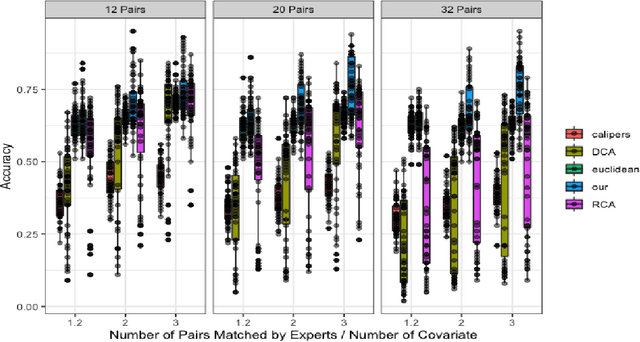
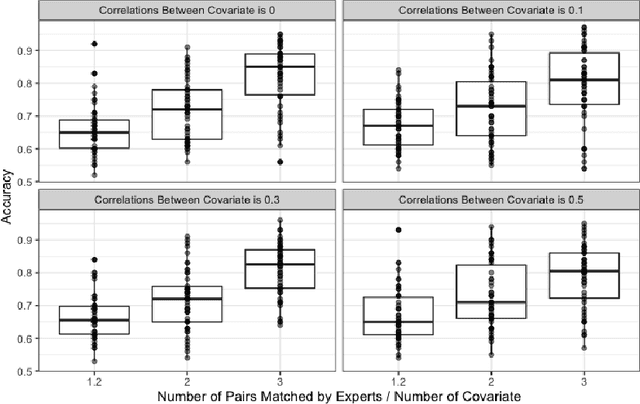
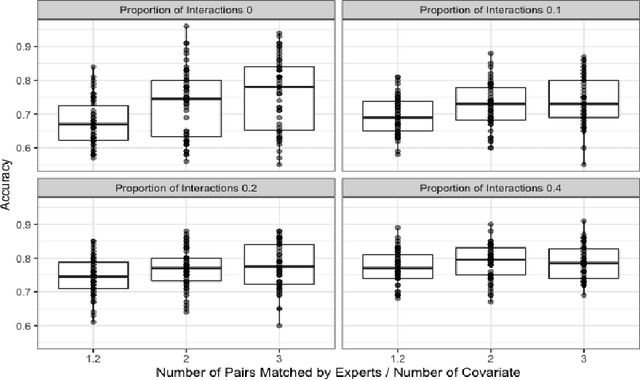
Multivariate matching algorithms "pair" similar study units in an observational study to remove potential bias and confounding effects caused by the absence of randomizations. In one-to-one multivariate matching algorithms, a large number of "pairs" to be matched could mean both the information from a large sample and a large number of tasks, and therefore, to best match the pairs, such a matching algorithm with efficiency and comparatively limited auxiliary matching knowledge provided through a "training" set of paired units by domain experts, is practically intriguing. We proposed a novel one-to-one matching algorithm based on a quadratic score function $S_{\beta}(x_i,x_j)= \beta^T (x_i-x_j)(x_i-x_j)^T \beta$. The weights $\beta$, which can be interpreted as a variable importance measure, are designed to minimize the score difference between paired training units while maximizing the score difference between unpaired training units. Further, in the typical but intricate case where the training set is much smaller than the unpaired set, we propose a \underline{s}emisupervised \underline{c}ompanion \underline{o}ne-\underline{t}o-\underline{o}ne \underline{m}atching \underline{a}lgorithm (SCOTOMA) that makes the best use of the unpaired units. The proposed weight estimator is proved to be consistent when the truth matching criterion is indeed the quadratic score function. When the model assumptions are violated, we demonstrate that the proposed algorithm still outperforms some popular competing matching algorithms through a series of simulations. We applied the proposed algorithm to a real-world study to investigate the effect of in-person schooling on community Covid-19 transmission rate for policy making purpose.