 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIll-Posed by Design: Probing Evidence Use in VLMs
Jun 23, 2026Counterfactual analysis is widely used to study evidence use in vision-language models, but its diagnostic value is limited on well-posed tasks: when several cues independently support the same answer, removing one may not change the prediction. We propose monocular metric object-size estimation as an ill-posed diagnostic setting for evidence selection: because physical size cannot be determined from a single uncalibrated image, models must rely on imperfect cues category priors, target appearance, local context, apparent image size, and scene geometry. We assemble Metric VQA ($10{,}813$ dimension queries from Objectron and $331$ tape-measured in-the-wild scenes) and evaluate $12$ open-weight VLMs ($3$--$397$\,B parameters) with counterfactual analysis decomposing six visual and language evidence channels. Even the largest VLMs tested (Qwen3-VL-235B, Qwen3.5-397B, InternVL3.5-241B) trail a text-only frontier LLM on the in-the-wild split. The diagnostic analysis shows: target identity is the most load-bearing cue, target pixels and local context help only some models, apparent size shifts predictions without a directional readout, and global scene geometry is largely unused. We analyze LoRA fine-tuning as an actionable intervention specific to metric estimation: while the task is learnable, the models do not learn to leverage scene geometry.
Balanced Thinking: Improving Chain of Thought Training in Vision Language Models
Mar 19, 2026Multimodal reasoning in vision-language models (VLMs) typically relies on a two-stage process: supervised fine-tuning (SFT) and reinforcement learning (RL). In standard SFT, all tokens contribute equally to the loss, even though reasoning data are inherently token-imbalanced. Long <think> traces overshadow short but task-critical <answer> segments, leading to verbose reasoning and inaccurate answers. We propose SCALe (Scheduled Curriculum Adaptive Loss), which explicitly separates supervision over reasoning and answer segments using dynamic, length-independent weighting. Unlike vanilla SFT, which overweights the <think> segment, SCALe-SFT gradually shifts the focus from <think> to <answer> throughout training via a cosine scheduling policy, encouraging concise and well-grounded reasoning. We evaluate SCALe across diverse benchmarks and architectures. Results show that SCALe consistently improves accuracy over vanilla SFT and matches the performance of the full two-phase SFT + GRPO pipeline while requiring only about one-seventh of the training time, making it a lightweight yet effective alternative. When combined with GRPO, SCALe achieves the best overall performance, highlighting its value both as a standalone method and as a strong foundation for reinforcement refinement.
Towards Multimodal In-Context Learning for Vision & Language Models
Mar 19, 2024



Inspired by the emergence of Large Language Models (LLMs) that can truly understand human language, significant progress has been made in aligning other, non-language, modalities to be `understandable' by an LLM, primarily via converting their samples into a sequence of embedded language-like tokens directly fed into the LLM (decoder) input stream. However, so far limited attention has been given to transferring (and evaluating) one of the core LLM capabilities to the emerging VLMs, namely the In-Context Learning (ICL) ability, or in other words to guide VLMs to desired target downstream tasks or output structure using in-context image+text demonstrations. In this work, we dive deeper into analyzing the capabilities of some of the state-of-the-art VLMs to follow ICL instructions, discovering them to be somewhat lacking. We discover that even models that underwent large-scale mixed modality pre-training and were implicitly guided to make use of interleaved image and text information (intended to consume helpful context from multiple images) under-perform when prompted with few-shot (ICL) demonstrations, likely due to their lack of `direct' ICL instruction tuning. To test this conjecture, we propose a simple, yet surprisingly effective, strategy of extending a common VLM alignment framework with ICL support, methodology, and curriculum. We explore, analyze, and provide insights into effective data mixes, leading up to a significant 21.03% (and 11.3% on average) ICL performance boost over the strongest VLM baselines and a variety of ICL benchmarks. We also contribute new benchmarks for ICL evaluation in VLMs and discuss their advantages over the prior art.
Mammography Dual View Mass Correspondence
Jul 02, 2018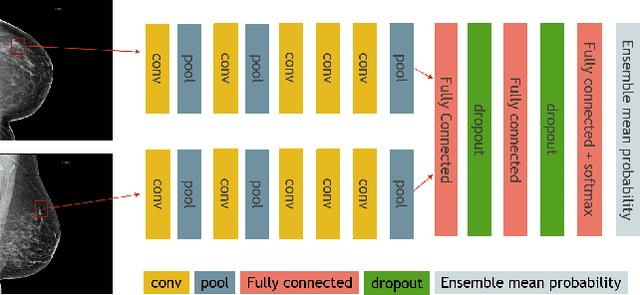
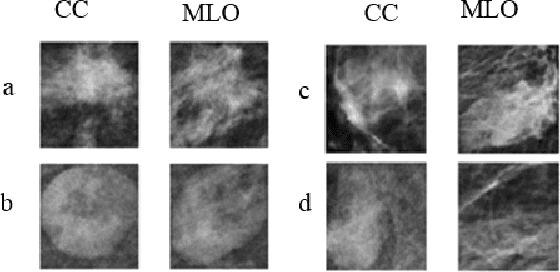
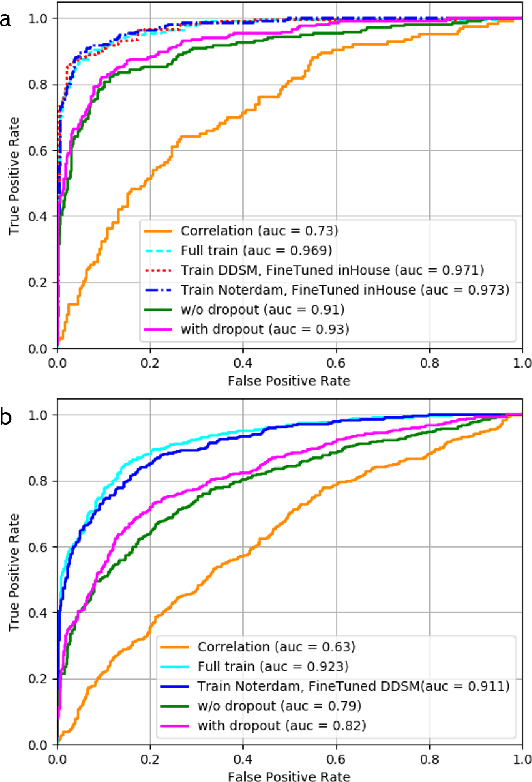
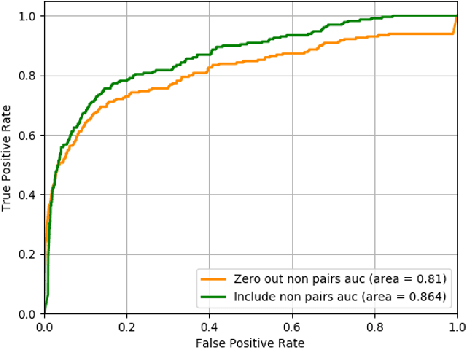
Standard breast cancer screening involves the acquisition of two mammography X-ray projections for each breast. Typically, a comparison of both views supports the challenging task of tumor detection and localization. We introduce a deep learning, patch-based Siamese network for lesion matching in dual-view mammography. Our locally-fitted approach generates a joint patch pair representation and comparison with a shared configuration between the two views. We performed a comprehensive set of experiments with the network on standard datasets, among them the large Digital Database for Screening Mammography (DDSM). We analyzed the effect of transfer learning with the network between different types of datasets and compared the network-based matching to using Euclidean distance by template matching. Finally, we evaluated the contribution of the matching network in a full detection pipeline. Experimental results demonstrate the promise of improved detection accuracy using our approach.