 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Personalized Page Content Ranking Using Customer Representation
May 09, 2023
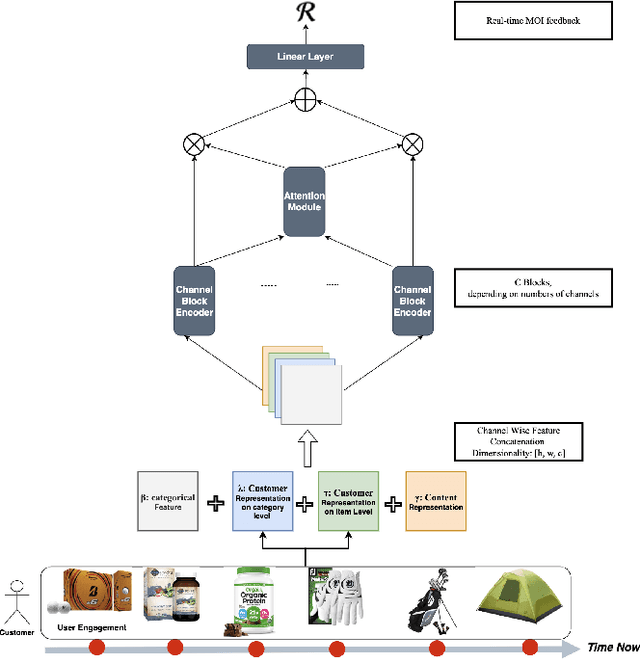
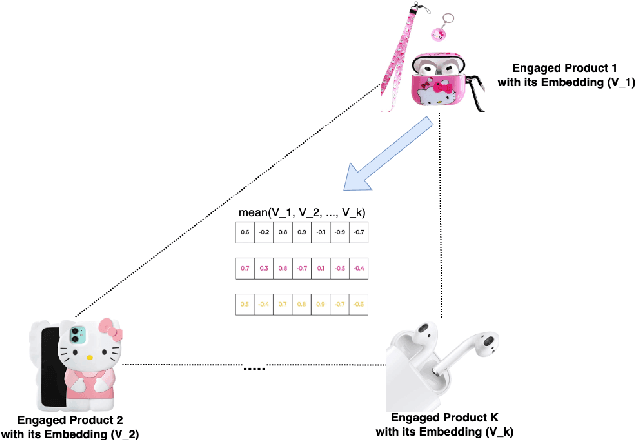
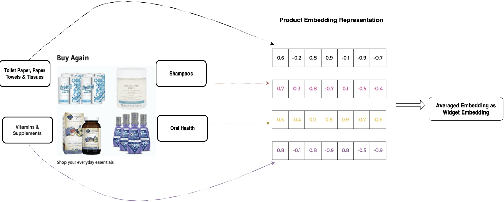

On E-commerce stores (Amazon, eBay etc.) there are rich recommendation content to help shoppers shopping more efficiently. However given numerous products, it's crucial to select most relevant content to reduce the burden of information overload. We introduced a content ranking service powered by a linear causal bandit algorithm to rank and select content for each shopper under each context. The algorithm mainly leverages aggregated customer behavior features, and ignores single shopper level past activities. We study the problem of inferring shoppers interest from historical activities. We propose a deep learning based bandit algorithm that incorporates historical shopping behavior, customer latent shopping goals, and the correlation between customers and content categories. This model produces more personalized content ranking measured by 12.08% nDCG lift. In the online A/B test setting, the model improved 0.02% annualized commercial impact measured by our business metric, validating its effectiveness.
Learning Absorption Rates in Glucose-Insulin Dynamics from Meal Covariates
Apr 27, 2023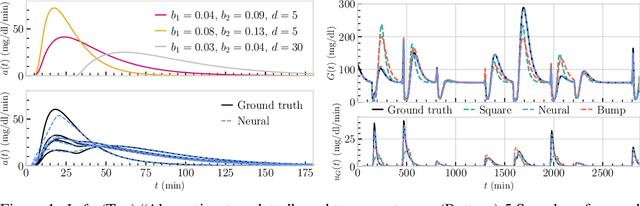

Traditional models of glucose-insulin dynamics rely on heuristic parameterizations chosen to fit observations within a laboratory setting. However, these models cannot describe glucose dynamics in daily life. One source of failure is in their descriptions of glucose absorption rates after meal events. A meal's macronutritional content has nuanced effects on the absorption profile, which is difficult to model mechanistically. In this paper, we propose to learn the effects of macronutrition content from glucose-insulin data and meal covariates. Given macronutrition information and meal times, we use a neural network to predict an individual's glucose absorption rate. We use this neural rate function as the control function in a differential equation of glucose dynamics, enabling end-to-end training. On simulated data, our approach is able to closely approximate true absorption rates, resulting in better forecast than heuristic parameterizations, despite only observing glucose, insulin, and macronutritional information. Our work readily generalizes to meal events with higher-dimensional covariates, such as images, setting the stage for glucose dynamics models that are personalized to each individual's daily life.
Syntactically Robust Training on Partially-Observed Data for Open Information Extraction
Jan 17, 2023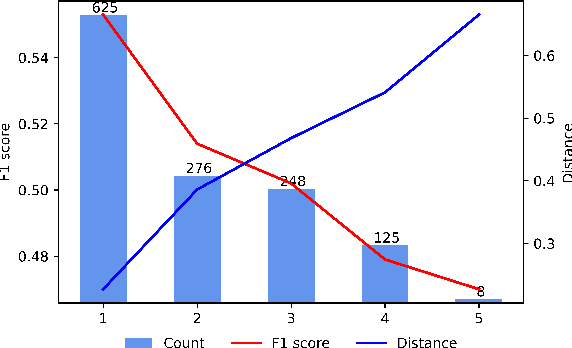
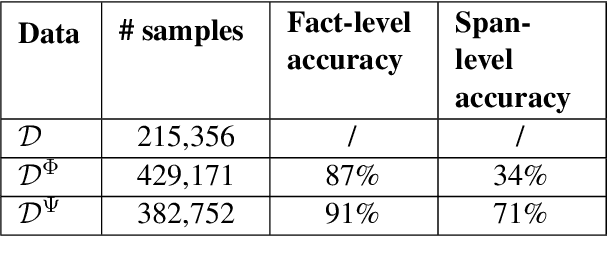
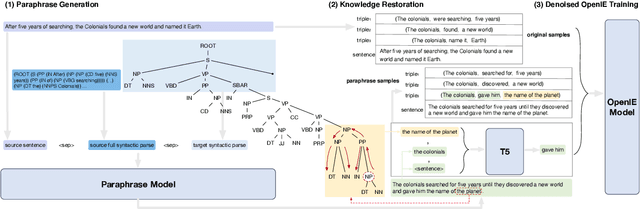
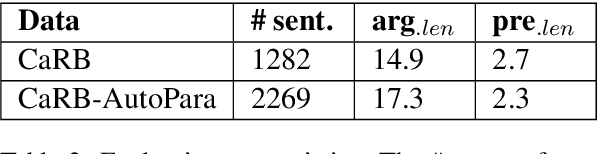
Open Information Extraction models have shown promising results with sufficient supervision. However, these models face a fundamental challenge that the syntactic distribution of training data is partially observable in comparison to the real world. In this paper, we propose a syntactically robust training framework that enables models to be trained on a syntactic-abundant distribution based on diverse paraphrase generation. To tackle the intrinsic problem of knowledge deformation of paraphrasing, two algorithms based on semantic similarity matching and syntactic tree walking are used to restore the expressionally transformed knowledge. The training framework can be generally applied to other syntactic partial observable domains. Based on the proposed framework, we build a new evaluation set called CaRB-AutoPara, a syntactically diverse dataset consistent with the real-world setting for validating the robustness of the models. Experiments including a thorough analysis show that the performance of the model degrades with the increase of the difference in syntactic distribution, while our framework gives a robust boundary. The source code is publicly available at https://github.com/qijimrc/RobustOIE.
Boosting Crop Classification by Hierarchically Fusing Satellite, Rotational, and Contextual Data
May 19, 2023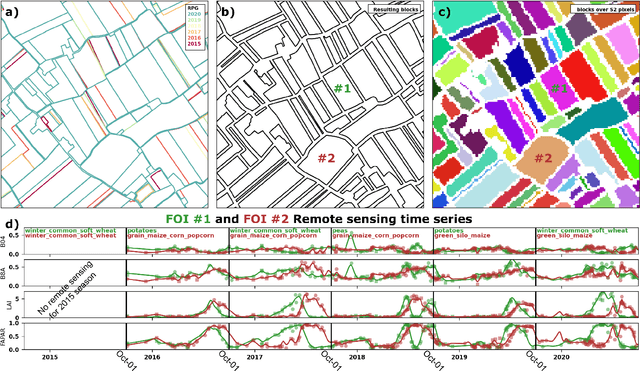
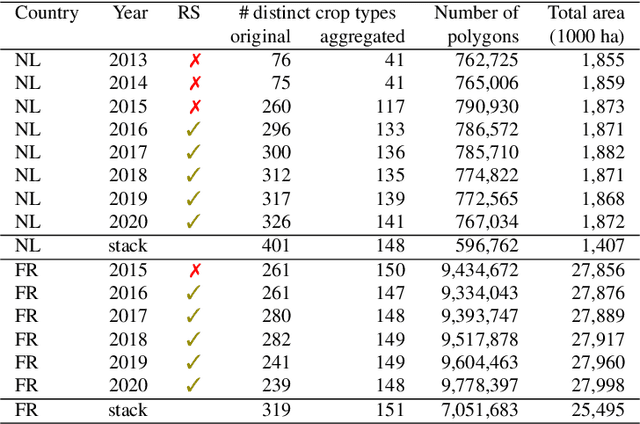
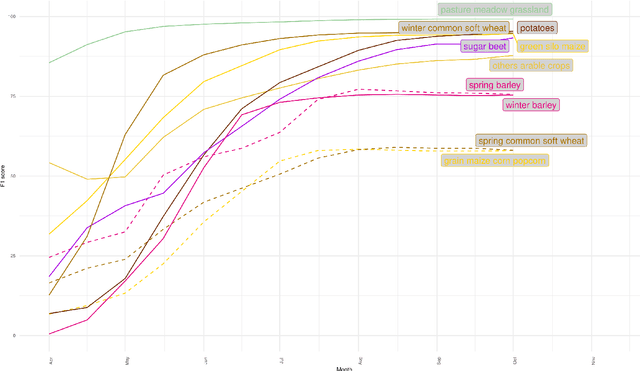
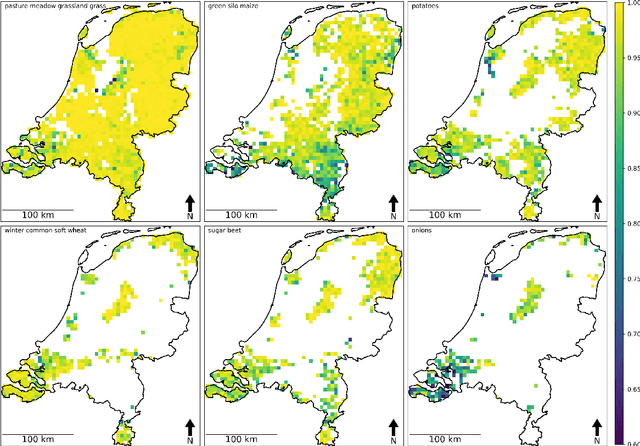
Accurate in-season crop type classification is crucial for the crop production estimation and monitoring of agricultural parcels. However, the complexity of the plant growth patterns and their spatio-temporal variability present significant challenges. While current deep learning-based methods show promise in crop type classification from single- and multi-modal time series, most existing methods rely on a single modality, such as satellite optical remote sensing data or crop rotation patterns. We propose a novel approach to fuse multimodal information into a model for improved accuracy and robustness across multiple years and countries. The approach relies on three modalities used: remote sensing time series from Sentinel-2 and Landsat 8 observations, parcel crop rotation and local crop distribution. To evaluate our approach, we release a new annotated dataset of 7.4 million agricultural parcels in France and Netherlands. We associate each parcel with time-series of surface reflectance (Red and NIR) and biophysical variables (LAI, FAPAR). Additionally, we propose a new approach to automatically aggregate crop types into a hierarchical class structure for meaningful model evaluation and a novel data-augmentation technique for early-season classification. Performance of the multimodal approach was assessed at different aggregation level in the semantic domain spanning from 151 to 8 crop types or groups. It resulted in accuracy ranging from 91\% to 95\% for NL dataset and from 85\% to 89\% for FR dataset. Pre-training on a dataset improves domain adaptation between countries, allowing for cross-domain zero-shot learning, and robustness of the performances in a few-shot setting from France to Netherlands. Our proposed approach outperforms comparable methods by enabling learning methods to use the often overlooked spatio-temporal context of parcels, resulting in increased preci...
"Nothing Abnormal": Disambiguating Medical Reports via Contrastive Knowledge Infusion
May 15, 2023
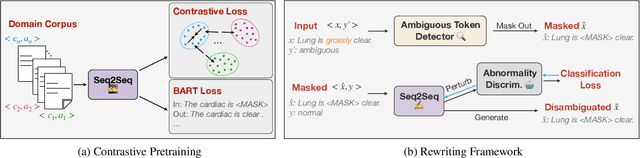
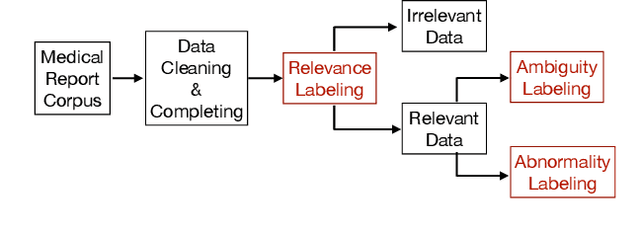

Sharing medical reports is essential for patient-centered care. A recent line of work has focused on automatically generating reports with NLP methods. However, different audiences have different purposes when writing/reading medical reports -- for example, healthcare professionals care more about pathology, whereas patients are more concerned with the diagnosis ("Is there any abnormality?"). The expectation gap results in a common situation where patients find their medical reports to be ambiguous and therefore unsure about the next steps. In this work, we explore the audience expectation gap in healthcare and summarize common ambiguities that lead patients to be confused about their diagnosis into three categories: medical jargon, contradictory findings, and misleading grammatical errors. Based on our analysis, we define a disambiguation rewriting task to regenerate an input to be unambiguous while preserving information about the original content. We further propose a rewriting algorithm based on contrastive pretraining and perturbation-based rewriting. In addition, we create two datasets, OpenI-Annotated based on chest reports and VA-Annotated based on general medical reports, with available binary labels for ambiguity and abnormality presence annotated by radiology specialists. Experimental results on these datasets show that our proposed algorithm effectively rewrites input sentences in a less ambiguous way with high content fidelity. Our code and annotated data are released to facilitate future research.
Horizon-free Reinforcement Learning in Adversarial Linear Mixture MDPs
May 15, 2023Recent studies have shown that episodic reinforcement learning (RL) is no harder than bandits when the total reward is bounded by $1$, and proved regret bounds that have a polylogarithmic dependence on the planning horizon $H$. However, it remains an open question that if such results can be carried over to adversarial RL, where the reward is adversarially chosen at each episode. In this paper, we answer this question affirmatively by proposing the first horizon-free policy search algorithm. To tackle the challenges caused by exploration and adversarially chosen reward, our algorithm employs (1) a variance-uncertainty-aware weighted least square estimator for the transition kernel; and (2) an occupancy measure-based technique for the online search of a \emph{stochastic} policy. We show that our algorithm achieves an $\tilde{O}\big((d+\log (|\mathcal{S}|^2 |\mathcal{A}|))\sqrt{K}\big)$ regret with full-information feedback, where $d$ is the dimension of a known feature mapping linearly parametrizing the unknown transition kernel of the MDP, $K$ is the number of episodes, $|\mathcal{S}|$ and $|\mathcal{A}|$ are the cardinalities of the state and action spaces. We also provide hardness results and regret lower bounds to justify the near optimality of our algorithm and the unavoidability of $\log|\mathcal{S}|$ and $\log|\mathcal{A}|$ in the regret bound.
MolHF: A Hierarchical Normalizing Flow for Molecular Graph Generation
May 15, 2023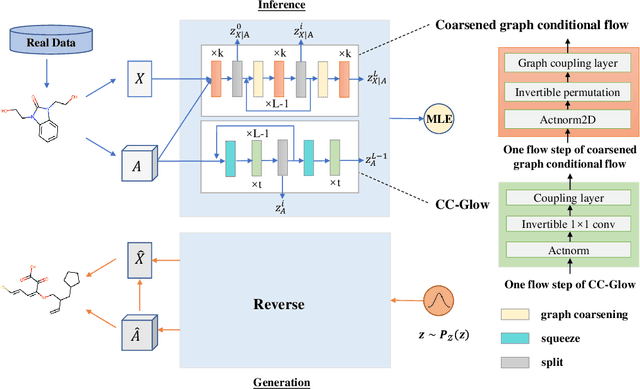
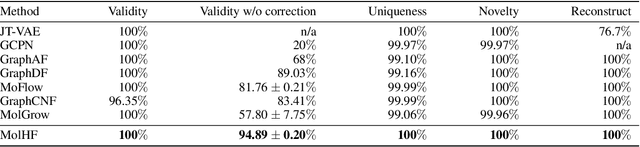
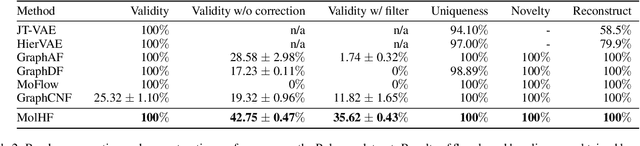
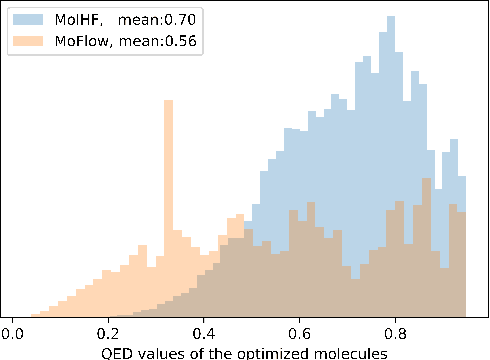
Molecular de novo design is a critical yet challenging task in scientific fields, aiming to design novel molecular structures with desired property profiles. Significant progress has been made by resorting to generative models for graphs. However, limited attention is paid to hierarchical generative models, which can exploit the inherent hierarchical structure (with rich semantic information) of the molecular graphs and generate complex molecules of larger size that we shall demonstrate to be difficult for most existing models. The primary challenge to hierarchical generation is the non-differentiable issue caused by the generation of intermediate discrete coarsened graph structures. To sidestep this issue, we cast the tricky hierarchical generation problem over discrete spaces as the reverse process of hierarchical representation learning and propose MolHF, a new hierarchical flow-based model that generates molecular graphs in a coarse-to-fine manner. Specifically, MolHF first generates bonds through a multi-scale architecture, then generates atoms based on the coarsened graph structure at each scale. We demonstrate that MolHF achieves state-of-the-art performance in random generation and property optimization, implying its high capacity to model data distribution. Furthermore, MolHF is the first flow-based model that can be applied to model larger molecules (polymer) with more than 100 heavy atoms. The code and models are available at https://github.com/violet-sto/MolHF.
A graph convolutional autoencoder approach to model order reduction for parametrized PDEs
May 15, 2023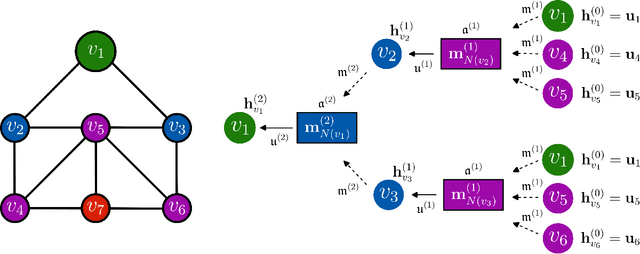
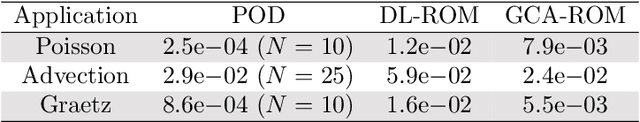
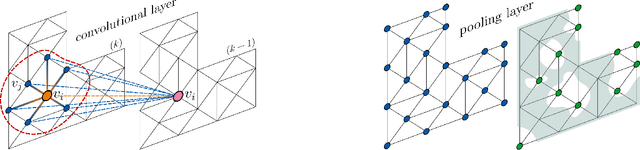
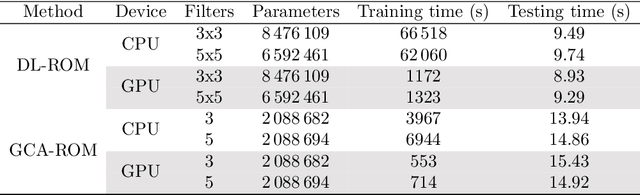
The present work proposes a framework for nonlinear model order reduction based on a Graph Convolutional Autoencoder (GCA-ROM). In the reduced order modeling (ROM) context, one is interested in obtaining real-time and many-query evaluations of parametric Partial Differential Equations (PDEs). Linear techniques such as Proper Orthogonal Decomposition (POD) and Greedy algorithms have been analyzed thoroughly, but they are more suitable when dealing with linear and affine models showing a fast decay of the Kolmogorov n-width. On one hand, the autoencoder architecture represents a nonlinear generalization of the POD compression procedure, allowing one to encode the main information in a latent set of variables while extracting their main features. On the other hand, Graph Neural Networks (GNNs) constitute a natural framework for studying PDE solutions defined on unstructured meshes. Here, we develop a non-intrusive and data-driven nonlinear reduction approach, exploiting GNNs to encode the reduced manifold and enable fast evaluations of parametrized PDEs. We show the capabilities of the methodology for several models: linear/nonlinear and scalar/vector problems with fast/slow decay in the physically and geometrically parametrized setting. The main properties of our approach consist of (i) high generalizability in the low-data regime even for complex regimes, (ii) physical compliance with general unstructured grids, and (iii) exploitation of pooling and un-pooling operations to learn from scattered data.
Causal Analysis for Robust Interpretability of Neural Networks
May 15, 2023
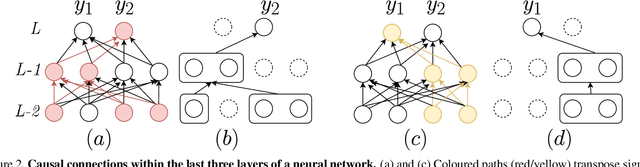
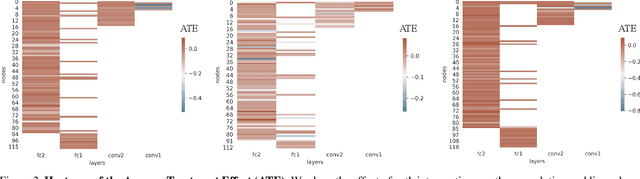
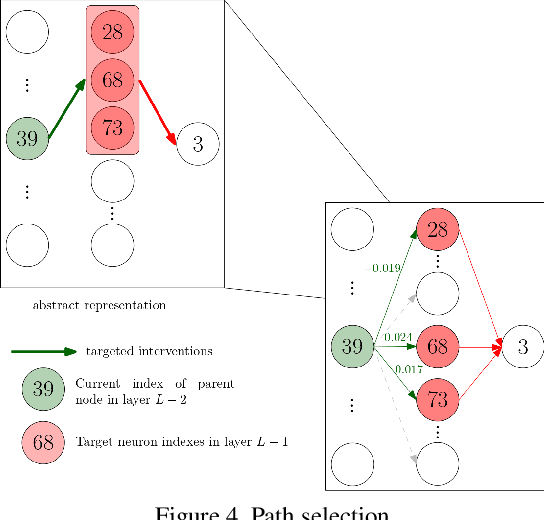
Interpreting the inner function of neural networks is crucial for the trustworthy development and deployment of these black-box models. Prior interpretability methods focus on correlation-based measures to attribute model decisions to individual examples. However, these measures are susceptible to noise and spurious correlations encoded in the model during the training phase (e.g., biased inputs, model overfitting, or misspecification). Moreover, this process has proven to result in noisy and unstable attributions that prevent any transparent understanding of the model's behavior. In this paper, we develop a robust interventional-based method grounded by causal analysis to capture cause-effect mechanisms in pre-trained neural networks and their relation to the prediction. Our novel approach relies on path interventions to infer the causal mechanisms within hidden layers and isolate relevant and necessary information (to model prediction), avoiding noisy ones. The result is task-specific causal explanatory graphs that can audit model behavior and express the actual causes underlying its performance. We apply our method to vision models trained on classification tasks. On image classification tasks, we provide extensive quantitative experiments to show that our approach can capture more stable and faithful explanations than standard attribution-based methods. Furthermore, the underlying causal graphs reveal the neural interactions in the model, making it a valuable tool in other applications (e.g., model repair).
Differential Convolutional Fuzzy Time Series Forecasting
May 15, 2023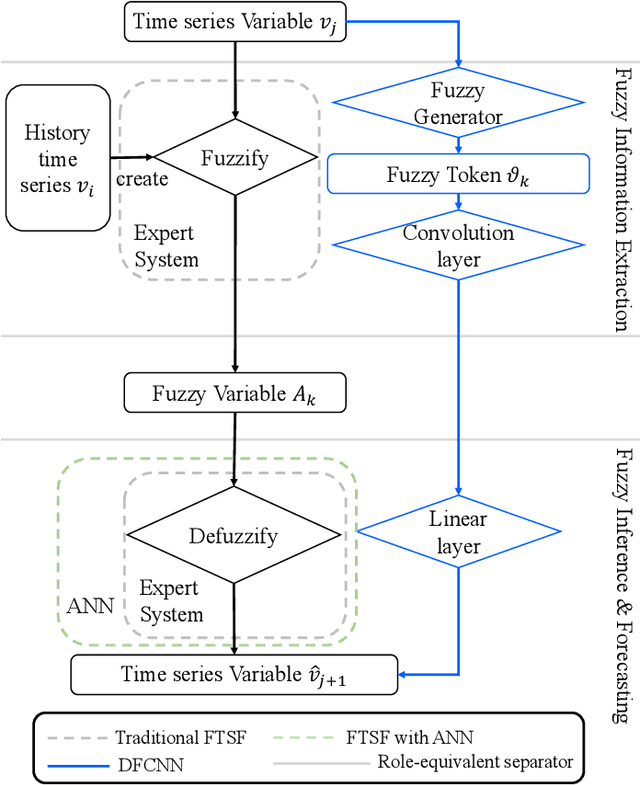
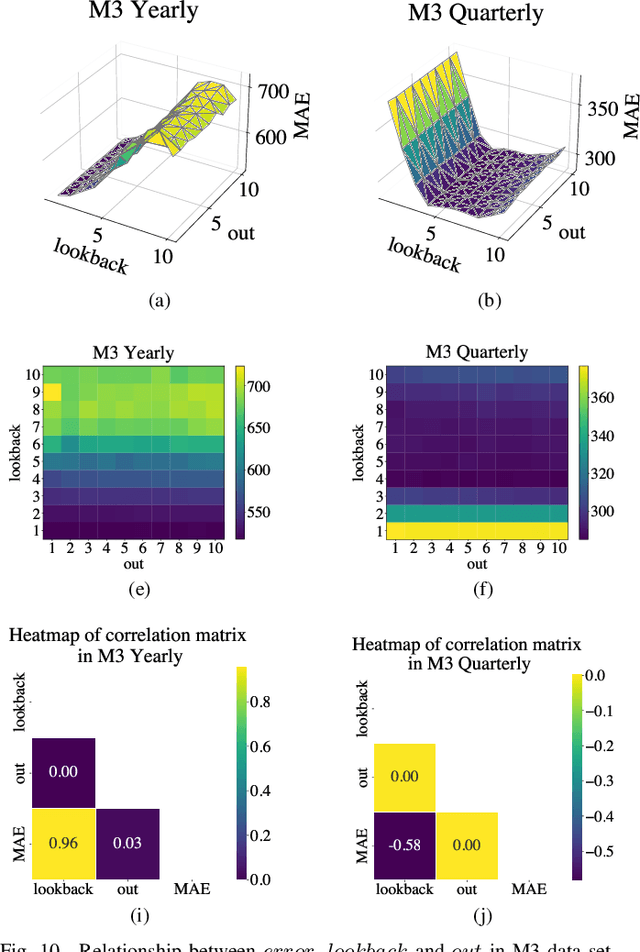
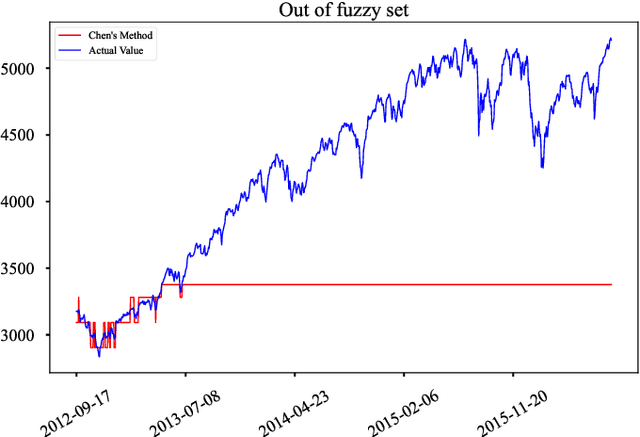
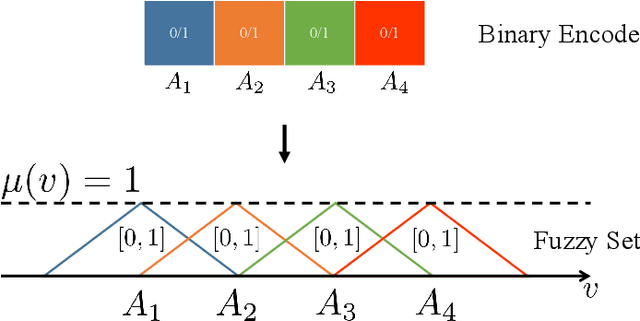
Fuzzy time series forecasting (FTSF) is a typical forecasting method with wide application. Traditional FTSF is regarded as an expert system which leads to lose the ability to recognize undefined feature. The mentioned is main reason of poor forecasting with FTSF. To solve the problem, the proposed model Differential Fuzzy Convolutional Neural Network (DFCNN) utilizes convolution neural network to re-implement FTSF with learnable ability. DFCNN is capable of recognizing the potential information and improve the forecasting accuracy. Thanks to learnable ability of neural network, length of fuzzy rules established in FTSF is expended to arbitrary length which expert is not able to be handle by expert system. At the same time, FTSF usually cannot achieve satisfactory performance of non-stationary time series due to trend of non-stationary time series. The trend of non-stationary time series causes the fuzzy set established by FTSF to invalid and cause the forecasting to fail. DFCNN utilizes the Difference algorithm to weaken the non-stationarity of time series, so that DFCNN can forecast the non-stationary time series with low error that FTSF cannot forecast in satisfactory performance. After mass of experiments, DFCNN has excellent prediction effect, which is ahead of the existing FTSF and common time series forecasting algorithms. Finally, DFCNN provides further ideas for improving FTSF and holds continued research value.