 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Review of Edge Case Detection in Automated Driving: Methods, Challenges and Future Directions
Oct 11, 2024



The rapid development of automated vehicles (AVs) promises to revolutionize transportation by enhancing safety and efficiency. However, ensuring their reliability in diverse real-world conditions remains a significant challenge, particularly due to rare and unexpected situations known as edge cases. Although numerous approaches exist for detecting edge cases, there is a notable lack of a comprehensive survey that systematically reviews these techniques. This paper fills this gap by presenting a practical, hierarchical review and systematic classification of edge case detection and assessment methodologies. Our classification is structured on two levels: first, categorizing detection approaches according to AV modules, including perception-related and trajectory-related edge cases; and second, based on underlying methodologies and theories guiding these techniques. We extend this taxonomy by introducing a new class called "knowledge-driven" approaches, which is largely overlooked in the literature. Additionally, we review the techniques and metrics for the evaluation of edge case detection methods and identified edge cases. To our knowledge, this is the first survey to comprehensively cover edge case detection methods across all AV subsystems, discuss knowledge-driven edge cases, and explore evaluation techniques for detection methods. This structured and multi-faceted analysis aims to facilitate targeted research and modular testing of AVs. Moreover, by identifying the strengths and weaknesses of various approaches and discussing the challenges and future directions, this survey intends to assist AV developers, researchers, and policymakers in enhancing the safety and reliability of automated driving (AD) systems through effective edge case detection.
Autonomous Vehicles Path Planning under Temporal Logic Specifications
Oct 10, 2024Path planning is an essential component of autonomous driving. A global planner is responsible for the high-level planning. It basically performs a shortest-path search on a known map, thereby defining waypoints used to control the local (low-level) planner. Local planning is a runtime verification method which is repeatedly run on the vehicle itself in real-time, so as to find the optimal short-horizon path which leads to the desired waypoint in a way which is both efficient and safe. The challenge is that the local planner has to take into account repeatedly incoming updates about the information available of the environment. In addition, it performs a complex task, as it has to take into account a large variety of requirements, originating from the necessity of collision avoidance with obstacles, respecting traffic rules, sticking to regulatory requirements, and lastly to reach the next waypoint efficiently. In this paper, we describe a logic-based specification mechanism which fulfills all these requirements.
Gaussian-Based and Outside-the-Box Runtime Monitoring Join Forces
Oct 08, 2024Since neural networks can make wrong predictions even with high confidence, monitoring their behavior at runtime is important, especially in safety-critical domains like autonomous driving. In this paper, we combine ideas from previous monitoring approaches based on observing the activation values of hidden neurons. In particular, we combine the Gaussian-based approach, which observes whether the current value of each monitored neuron is similar to typical values observed during training, and the Outside-the-Box monitor, which creates clusters of the acceptable activation values, and, thus, considers the correlations of the neurons' values. Our experiments evaluate the achieved improvement.
AGNES: Abstraction-guided Framework for Deep Neural Networks Security
Nov 07, 2023Deep Neural Networks (DNNs) are becoming widespread, particularly in safety-critical areas. One prominent application is image recognition in autonomous driving, where the correct classification of objects, such as traffic signs, is essential for safe driving. Unfortunately, DNNs are prone to backdoors, meaning that they concentrate on attributes of the image that should be irrelevant for their correct classification. Backdoors are integrated into a DNN during training, either with malicious intent (such as a manipulated training process, because of which a yellow sticker always leads to a traffic sign being recognised as a stop sign) or unintentional (such as a rural background leading to any traffic sign being recognised as animal crossing, because of biased training data). In this paper, we introduce AGNES, a tool to detect backdoors in DNNs for image recognition. We discuss the principle approach on which AGNES is based. Afterwards, we show that our tool performs better than many state-of-the-art methods for multiple relevant case studies.
Causal Analysis for Robust Interpretability of Neural Networks
May 15, 2023



Interpreting the inner function of neural networks is crucial for the trustworthy development and deployment of these black-box models. Prior interpretability methods focus on correlation-based measures to attribute model decisions to individual examples. However, these measures are susceptible to noise and spurious correlations encoded in the model during the training phase (e.g., biased inputs, model overfitting, or misspecification). Moreover, this process has proven to result in noisy and unstable attributions that prevent any transparent understanding of the model's behavior. In this paper, we develop a robust interventional-based method grounded by causal analysis to capture cause-effect mechanisms in pre-trained neural networks and their relation to the prediction. Our novel approach relies on path interventions to infer the causal mechanisms within hidden layers and isolate relevant and necessary information (to model prediction), avoiding noisy ones. The result is task-specific causal explanatory graphs that can audit model behavior and express the actual causes underlying its performance. We apply our method to vision models trained on classification tasks. On image classification tasks, we provide extensive quantitative experiments to show that our approach can capture more stable and faithful explanations than standard attribution-based methods. Furthermore, the underlying causal graphs reveal the neural interactions in the model, making it a valuable tool in other applications (e.g., model repair).
Runtime Monitoring for Out-of-Distribution Detection in Object Detection Neural Networks
Dec 15, 2022



Runtime monitoring provides a more realistic and applicable alternative to verification in the setting of real neural networks used in industry. It is particularly useful for detecting out-of-distribution (OOD) inputs, for which the network was not trained and can yield erroneous results. We extend a runtime-monitoring approach previously proposed for classification networks to perception systems capable of identification and localization of multiple objects. Furthermore, we analyze its adequacy experimentally on different kinds of OOD settings, documenting the overall efficacy of our approach.
Backdoor Mitigation in Deep Neural Networks via Strategic Retraining
Dec 14, 2022Deep Neural Networks (DNN) are becoming increasingly more important in assisted and automated driving. Using such entities which are obtained using machine learning is inevitable: tasks such as recognizing traffic signs cannot be developed reasonably using traditional software development methods. DNN however do have the problem that they are mostly black boxes and therefore hard to understand and debug. One particular problem is that they are prone to hidden backdoors. This means that the DNN misclassifies its input, because it considers properties that should not be decisive for the output. Backdoors may either be introduced by malicious attackers or by inappropriate training. In any case, detecting and removing them is important in the automotive area, as they might lead to safety violations with potentially severe consequences. In this paper, we introduce a novel method to remove backdoors. Our method works for both intentional as well as unintentional backdoors. We also do not require prior knowledge about the shape or distribution of backdoors. Experimental evidence shows that our method performs well on several medium-sized examples.
DeepAbstract: Neural Network Abstraction for Accelerating Verification
Jun 24, 2020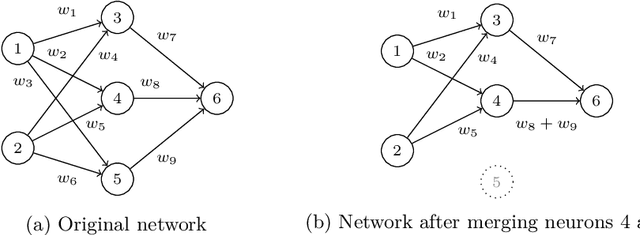
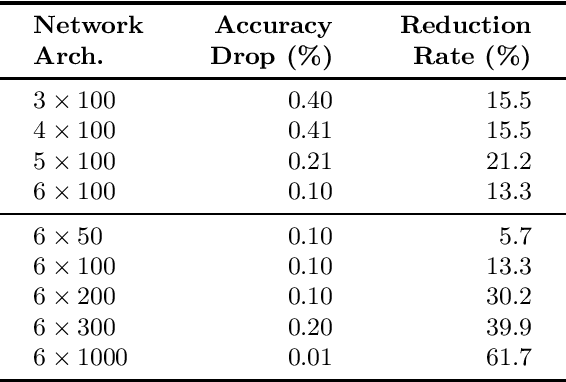
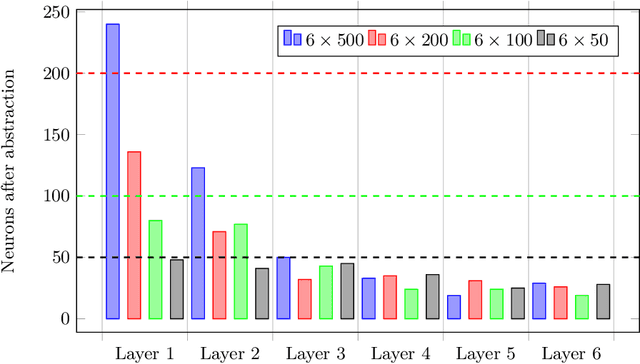
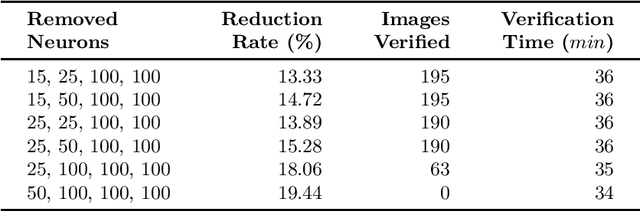
While abstraction is a classic tool of verification to scale it up, it is not used very often for verifying neural networks. However, it can help with the still open task of scaling existing algorithms to state-of-the-art network architectures. We introduce an abstraction framework applicable to fully-connected feed-forward neural networks based on clustering of neurons that behave similarly on some inputs. For the particular case of ReLU, we additionally provide error bounds incurred by the abstraction. We show how the abstraction reduces the size of the network, while preserving its accuracy, and how verification results on the abstract network can be transferred back to the original network.
Towards Safety Verification of Direct Perception Neural Networks
Apr 09, 2019

We study the problem of safety verification of direct perception neural networks, which take camera images as inputs and produce high-level features for autonomous vehicles to make control decisions. Formal verification of direct perception neural networks is extremely challenging, as it is difficult to formulate the specification that requires characterizing input conditions, while the number of neurons in such a network can reach millions. We approach the specification problem by learning an input property characterizer which carefully extends a direct perception neural network at close-to-output layers, and address the scalability problem by only analyzing networks starting from shared neurons without losing soundness. The presented workflow is used to understand a direct perception neural network (developed by Audi) which computes the next waypoint and orientation for autonomous vehicles to follow.
Multi-Objective Approaches to Markov Decision Processes with Uncertain Transition Parameters
Oct 20, 2017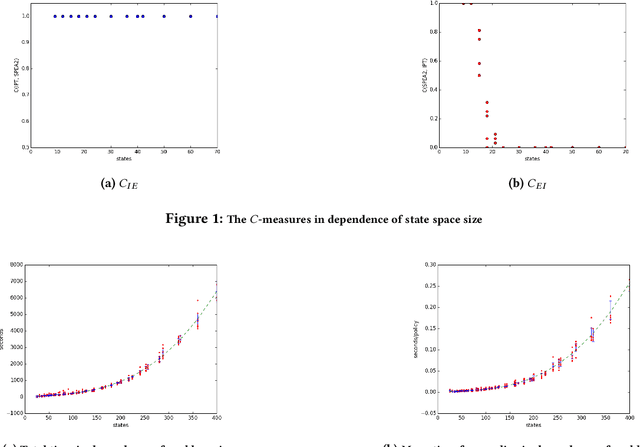
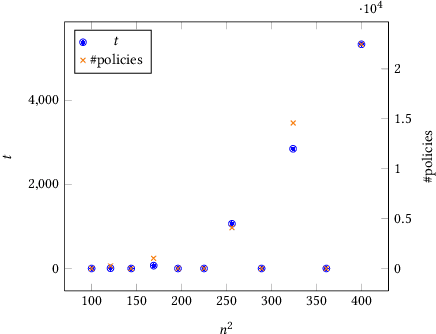
Markov decision processes (MDPs) are a popular model for performance analysis and optimization of stochastic systems. The parameters of stochastic behavior of MDPs are estimates from empirical observations of a system; their values are not known precisely. Different types of MDPs with uncertain, imprecise or bounded transition rates or probabilities and rewards exist in the literature. Commonly, analysis of models with uncertainties amounts to searching for the most robust policy which means that the goal is to generate a policy with the greatest lower bound on performance (or, symmetrically, the lowest upper bound on costs). However, hedging against an unlikely worst case may lead to losses in other situations. In general, one is interested in policies that behave well in all situations which results in a multi-objective view on decision making. In this paper, we consider policies for the expected discounted reward measure of MDPs with uncertain parameters. In particular, the approach is defined for bounded-parameter MDPs (BMDPs) [8]. In this setting the worst, best and average case performances of a policy are analyzed simultaneously, which yields a multi-scenario multi-objective optimization problem. The paper presents and evaluates approaches to compute the pure Pareto optimal policies in the value vector space.