 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Universal Domain Adaptation via Compressive Attention Matching
Apr 24, 2023
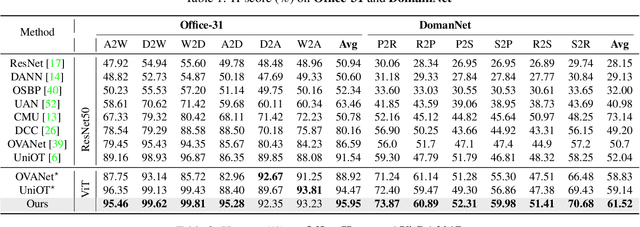

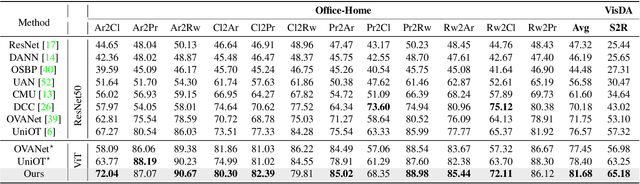
Universal domain adaptation (UniDA) aims to transfer knowledge from the source domain to the target domain without any prior knowledge about the label set. The challenge lies in how to determine whether the target samples belong to common categories. The mainstream methods make judgments based on the sample features, which overemphasizes global information while ignoring the most crucial local objects in the image, resulting in limited accuracy. To address this issue, we propose a Universal Attention Matching (UniAM) framework by exploiting the self-attention mechanism in vision transformer to capture the crucial object information. The proposed framework introduces a novel Compressive Attention Matching (CAM) approach to explore the core information by compressively representing attentions. Furthermore, CAM incorporates a residual-based measurement to determine the sample commonness. By utilizing the measurement, UniAM achieves domain-wise and category-wise Common Feature Alignment (CFA) and Target Class Separation (TCS). Notably, UniAM is the first method utilizing the attention in vision transformer directly to perform classification tasks. Extensive experiments show that UniAM outperforms the current state-of-the-art methods on various benchmark datasets.
Transcending Grids: Point Clouds and Surface Representations Powering Neurological Processing
May 17, 2023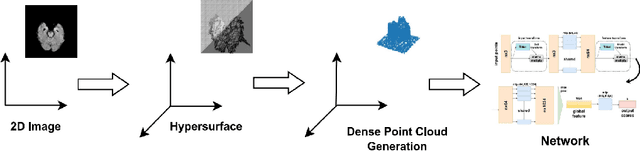
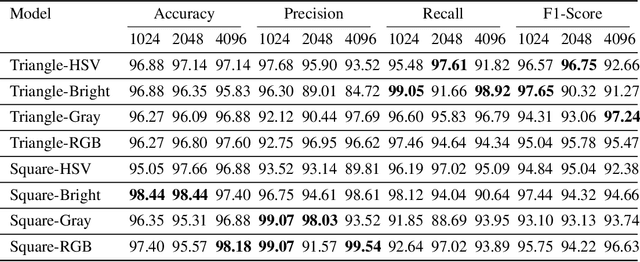
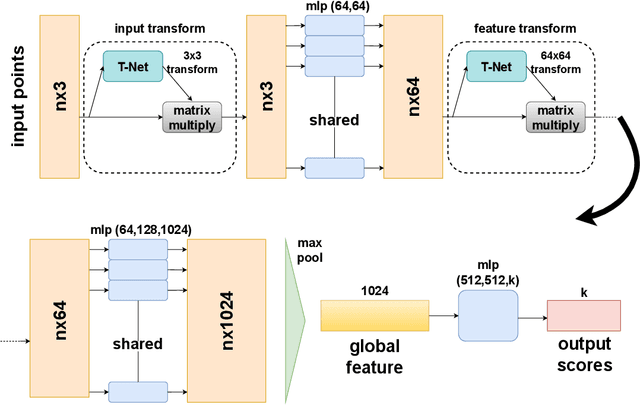
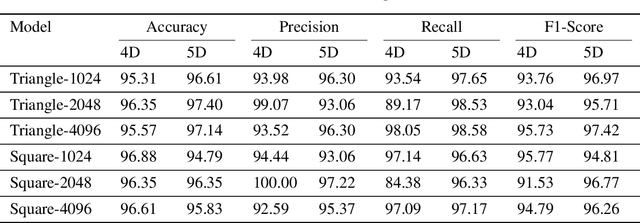
In healthcare, accurately classifying medical images is vital, but conventional methods often hinge on medical data with a consistent grid structure, which may restrict their overall performance. Recent medical research has been focused on tweaking the architectures to attain better performance without giving due consideration to the representation of data. In this paper, we present a novel approach for transforming grid based data into its higher dimensional representations, leveraging unstructured point cloud data structures. We first generate a sparse point cloud from an image by integrating pixel color information as spatial coordinates. Next, we construct a hypersurface composed of points based on the image dimensions, with each smooth section within this hypersurface symbolizing a specific pixel location. Polygonal face construction is achieved using an adjacency tensor. Finally, a dense point cloud is generated by densely sampling the constructed hypersurface, with a focus on regions of higher detail. The effectiveness of our approach is demonstrated on a publicly accessible brain tumor dataset, achieving significant improvements over existing classification techniques. This methodology allows the extraction of intricate details from the original image, opening up new possibilities for advanced image analysis and processing tasks.
Knowledge Graph Completion Models are Few-shot Learners: An Empirical Study of Relation Labeling in E-commerce with LLMs
May 17, 2023
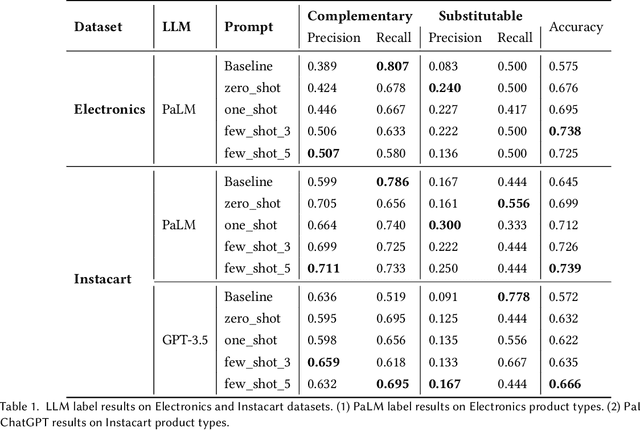
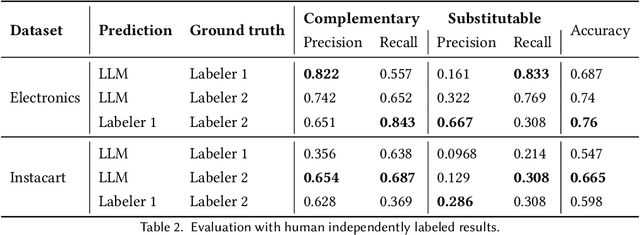
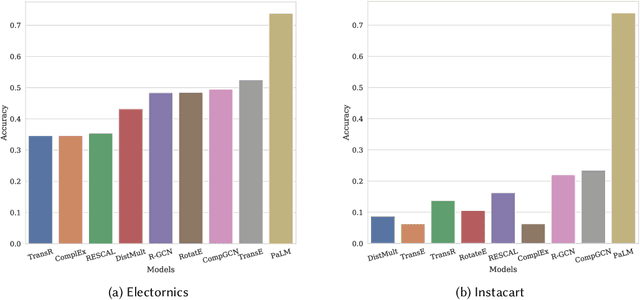
Knowledge Graphs (KGs) play a crucial role in enhancing e-commerce system performance by providing structured information about entities and their relationships, such as complementary or substitutable relations between products or product types, which can be utilized in recommender systems. However, relation labeling in KGs remains a challenging task due to the dynamic nature of e-commerce domains and the associated cost of human labor. Recently, breakthroughs in Large Language Models (LLMs) have shown surprising results in numerous natural language processing tasks. In this paper, we conduct an empirical study of LLMs for relation labeling in e-commerce KGs, investigating their powerful learning capabilities in natural language and effectiveness in predicting relations between product types with limited labeled data. We evaluate various LLMs, including PaLM and GPT-3.5, on benchmark datasets, demonstrating their ability to achieve competitive performance compared to humans on relation labeling tasks using just 1 to 5 labeled examples per relation. Additionally, we experiment with different prompt engineering techniques to examine their impact on model performance. Our results show that LLMs significantly outperform existing KG completion models in relation labeling for e-commerce KGs and exhibit performance strong enough to replace human labeling.
Integrating Multiple Sources Knowledge for Class Asymmetry Domain Adaptation Segmentation of Remote Sensing Images
May 17, 2023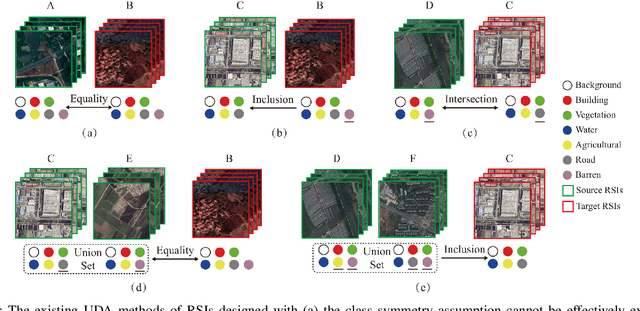
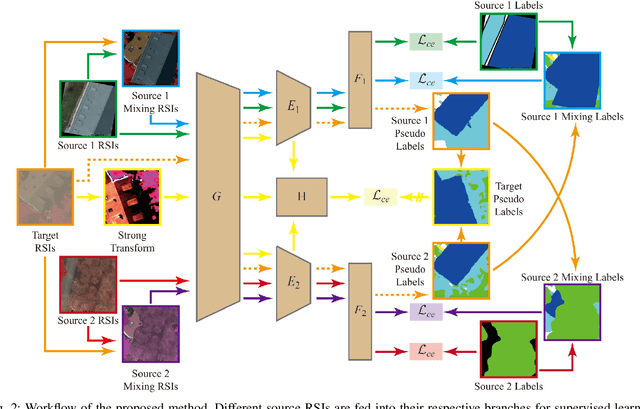
In the existing unsupervised domain adaptation (UDA) methods for remote sensing images (RSIs) semantic segmentation, class symmetry is an widely followed ideal assumption, where the source and target RSIs have exactly the same class space. In practice, however, it is often very difficult to find a source RSI with exactly the same classes as the target RSI. More commonly, there are multiple source RSIs available. To this end, a novel class asymmetry RSIs domain adaptation method with multiple sources is proposed in this paper, which consists of four key components. Firstly, a multi-branch segmentation network is built to learn an expert for each source RSI. Secondly, a novel collaborative learning method with the cross-domain mixing strategy is proposed, to supplement the class information for each source while achieving the domain adaptation of each source-target pair. Thirdly, a pseudo-label generation strategy is proposed to effectively combine strengths of different experts, which can be flexibly applied to two cases where the source class union is equal to or includes the target class set. Fourthly, a multiview-enhanced knowledge integration module is developed for the high-level knowledge routing and transfer from multiple domains to target predictions.
Robust Power Allocation for Integrated Visible Light Positioning and Communication Networks
May 17, 2023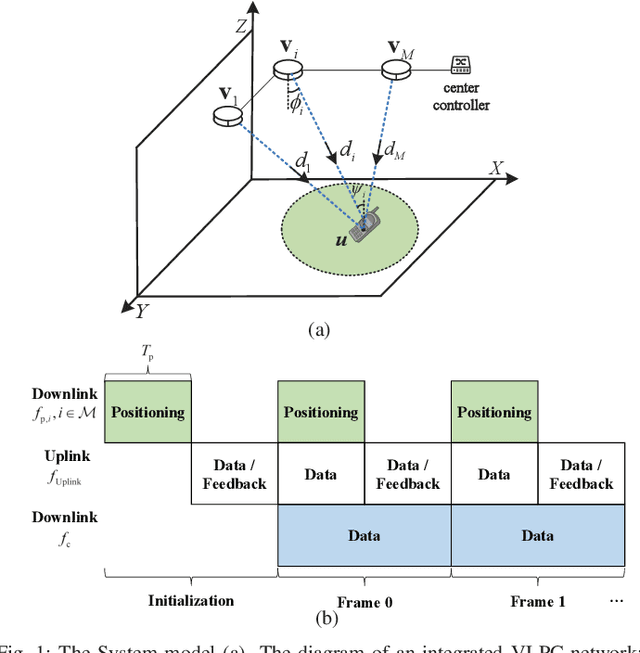
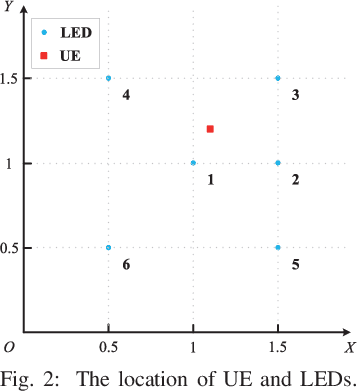
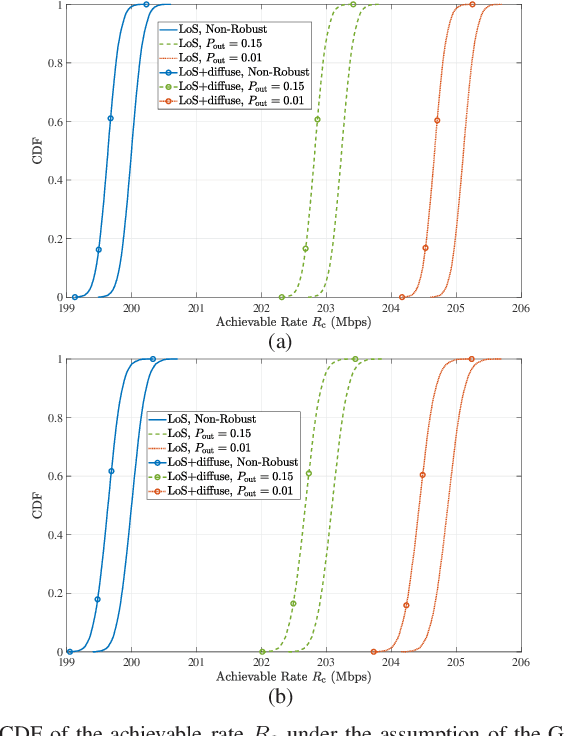
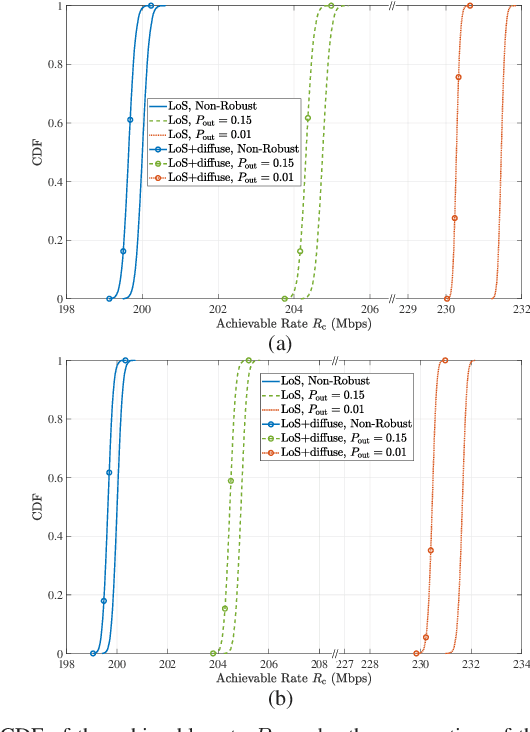
Integrated visible light positioning and communication (VLPC), capable of combining advantages of visible light communications (VLC) and visible light positioning (VLP), is a promising key technology for the future Internet of Things. In VLPC networks, positioning and communications are inherently coupled, which has not been sufficiently explored in the literature. We propose a robust power allocation scheme for integrated VLPC Networks by exploiting the intrinsic relationship between positioning and communications. Specifically, we derive explicit relationships between random positioning errors, following both a Gaussian distribution and an arbitrary distribution, and channel state information errors. Then, we minimize the Cramer-Rao lower bound (CRLB) of positioning errors, subject to the rate outage constraint and the power constraints, which is a chance-constrained optimization problem and generally computationally intractable. To circumvent the nonconvex challenge, we conservatively transform the chance constraints to deterministic forms by using the Bernstein-type inequality and the conditional value-at-risk for the Gaussian and arbitrary distributed positioning errors, respectively, and then approximate them as convex semidefinite programs. Finally, simulation results verify the robustness and effectiveness of our proposed integrated VLPC design schemes.
On-board Change Detection for Resource-efficient Earth Observation with LEO Satellites
May 17, 2023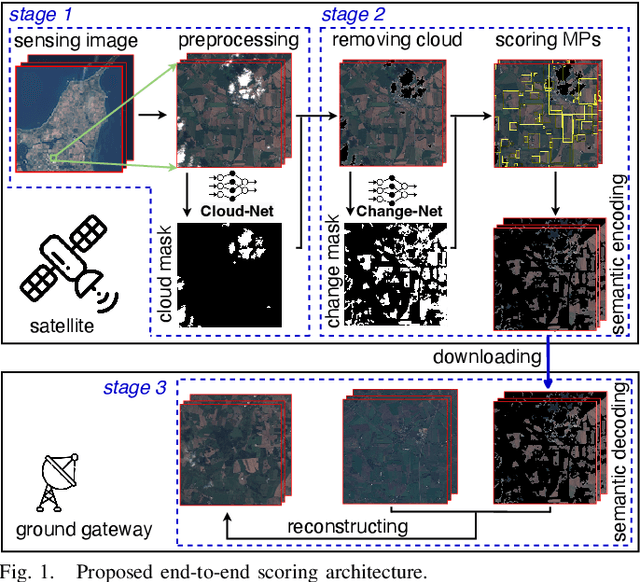
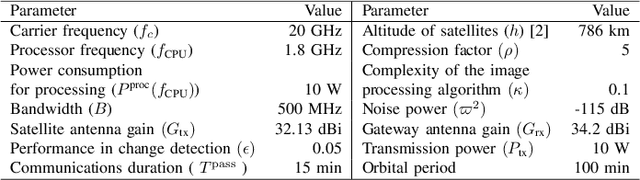
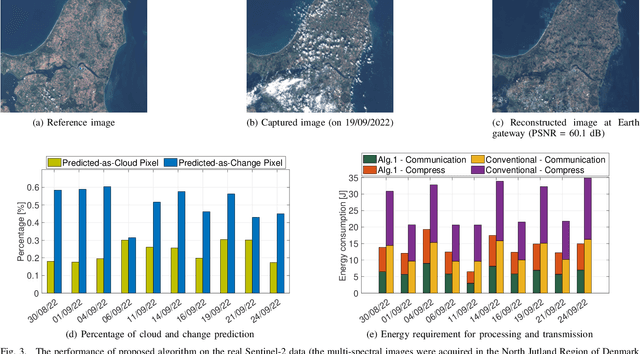
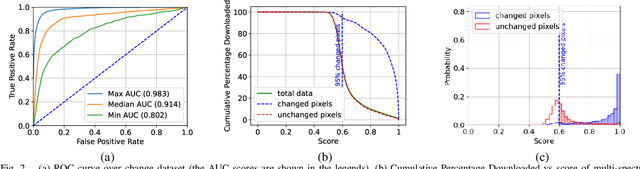
The amount of data generated by Earth observation satellites can be enormous, which poses a great challenge to the satellite-to-ground connections with limited rate. This paper considers problem of efficient downlink communication of multi-spectral satellite images for Earth observation using change detection. The proposed method for image processing consists of the joint design of cloud removal and change encoding, which can be seen as an instance of semantic communication, as it encodes important information, such as changed multi-spectral pixels (MPs), while aiming to minimize energy consumption. It comprises a three-stage end-to-end scoring mechanism that determines the importance of each MP before deciding its transmission. Specifically, the sensing image is (1) standardized, (2) passed through a high-performance cloud filtering via the Cloud-Net model, and (3) passed to the proposed scoring algorithm that uses Change-Net to identify MPs that have a high likelihood of being changed, compress them and forward the result to the ground station. The experimental results indicate that the proposed framework is effective in optimizing energy usage while preserving high-quality data transmission in satellite-based Earth observation applications.
GIFT: Graph-Induced Fine-Tuning for Multi-Party Conversation Understanding
May 17, 2023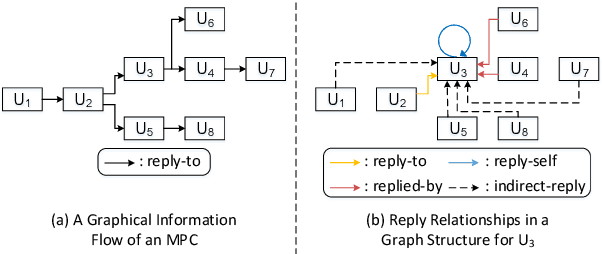
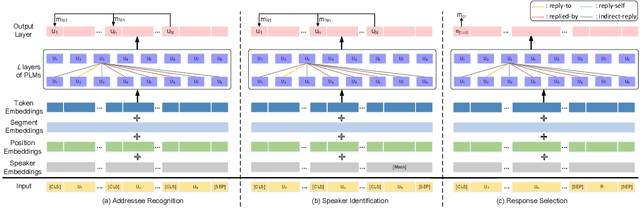
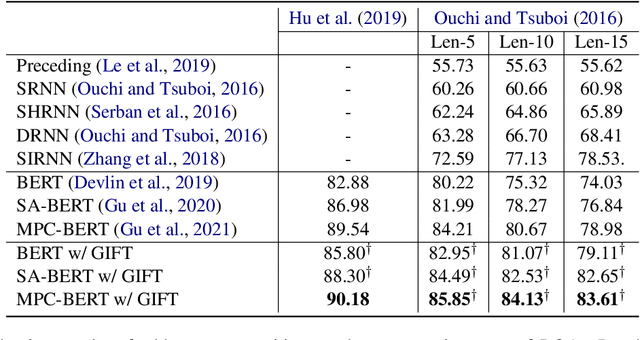
Addressing the issues of who saying what to whom in multi-party conversations (MPCs) has recently attracted a lot of research attention. However, existing methods on MPC understanding typically embed interlocutors and utterances into sequential information flows, or utilize only the superficial of inherent graph structures in MPCs. To this end, we present a plug-and-play and lightweight method named graph-induced fine-tuning (GIFT) which can adapt various Transformer-based pre-trained language models (PLMs) for universal MPC understanding. In detail, the full and equivalent connections among utterances in regular Transformer ignore the sparse but distinctive dependency of an utterance on another in MPCs. To distinguish different relationships between utterances, four types of edges are designed to integrate graph-induced signals into attention mechanisms to refine PLMs originally designed for processing sequential texts. We evaluate GIFT by implementing it into three PLMs, and test the performance on three downstream tasks including addressee recognition, speaker identification and response selection. Experimental results show that GIFT can significantly improve the performance of three PLMs on three downstream tasks and two benchmarks with only 4 additional parameters per encoding layer, achieving new state-of-the-art performance on MPC understanding.
Binarized Spectral Compressive Imaging
May 17, 2023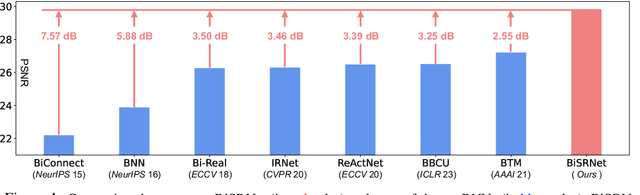
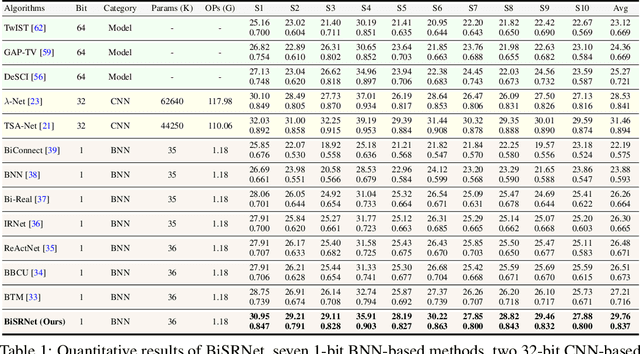
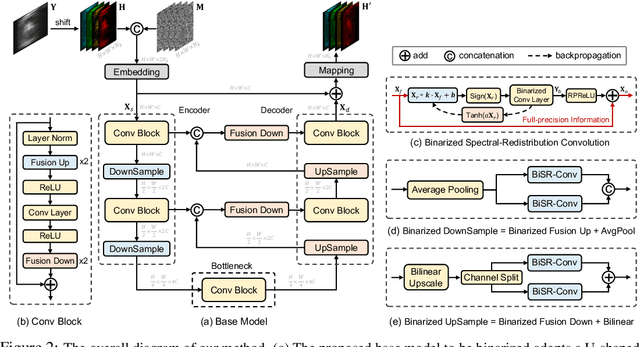
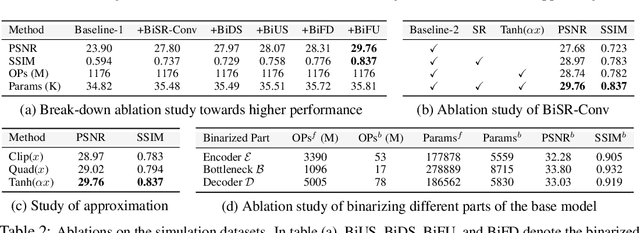
Existing deep learning models for hyperspectral image (HSI) reconstruction achieve good performance but require powerful hardwares with enormous memory and computational resources. Consequently, these methods can hardly be deployed on resource-limited mobile devices. In this paper, we propose a novel method, Binarized Spectral-Redistribution Network (BiSRNet), for efficient and practical HSI restoration from compressed measurement in snapshot compressive imaging (SCI) systems. Firstly, we redesign a compact and easy-to-deploy base model to be binarized. Then we present the basic unit, Binarized Spectral-Redistribution Convolution (BiSR-Conv). BiSR-Conv can adaptively redistribute the HSI representations before binarizing activation and uses a scalable hyperbolic tangent function to closer approximate the Sign function in backpropagation. Based on our BiSR-Conv, we customize four binarized convolutional modules to address the dimension mismatch and propagate full-precision information throughout the whole network. Finally, our BiSRNet is derived by using the proposed techniques to binarize the base model. Comprehensive quantitative and qualitative experiments manifest that our proposed BiSRNet outperforms state-of-the-art binarization methods and achieves comparable performance with full-precision algorithms. Code and models will be released at https://github.com/caiyuanhao1998/BiSCI and https://github.com/caiyuanhao1998/MST
Decentralized diffusion-based learning under non-parametric limited prior knowledge
May 05, 2023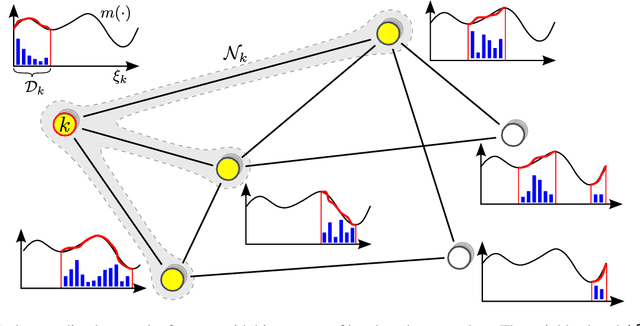
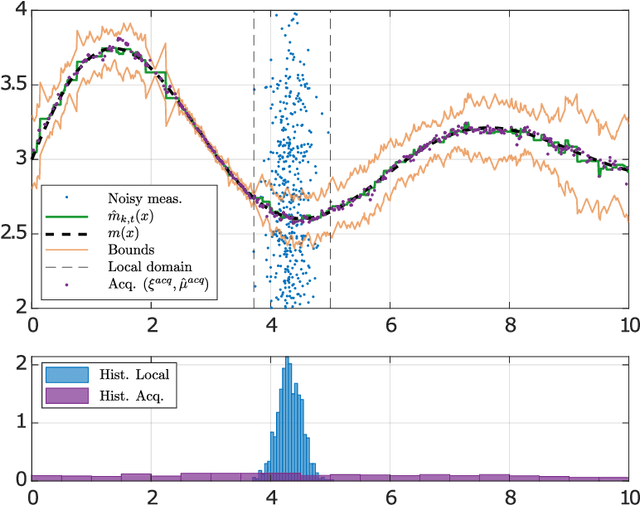
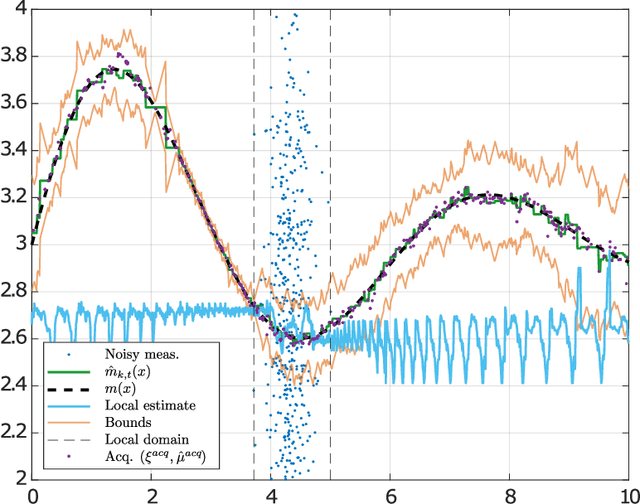
We study the problem of diffusion-based network learning of a nonlinear phenomenon, $m$, from local agents' measurements collected in a noisy environment. For a decentralized network and information spreading merely between directly neighboring nodes, we propose a non-parametric learning algorithm, that avoids raw data exchange and requires only mild \textit{a priori} knowledge about $m$. Non-asymptotic estimation error bounds are derived for the proposed method. Its potential applications are illustrated through simulation experiments.
On the Generalization Error of Meta Learning for the Gibbs Algorithm
Apr 27, 2023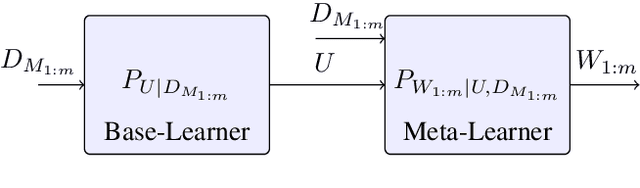
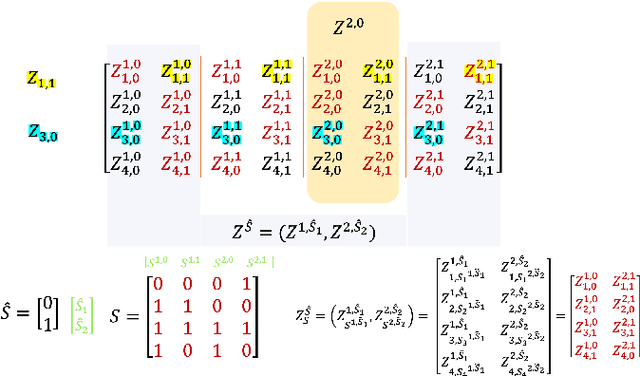
We analyze the generalization ability of joint-training meta learning algorithms via the Gibbs algorithm. Our exact characterization of the expected meta generalization error for the meta Gibbs algorithm is based on symmetrized KL information, which measures the dependence between all meta-training datasets and the output parameters, including task-specific and meta parameters. Additionally, we derive an exact characterization of the meta generalization error for the super-task Gibbs algorithm, in terms of conditional symmetrized KL information within the super-sample and super-task framework introduced in Steinke and Zakynthinou (2020) and Hellstrom and Durisi (2022) respectively. Our results also enable us to provide novel distribution-free generalization error upper bounds for these Gibbs algorithms applicable to meta learning.