 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge6GAgentGym: Tool Use, Data Synthesis, and Agentic Learning for Network Management
Mar 31, 2026Autonomous 6G network management requires agents that can execute tools, observe the resulting state changes, and adapt their decisions accordingly. Existing benchmarks based on static questions or scripted episode replay, however, do not support such closed-loop interaction, limiting agents to passive evaluation without the ability to learn from environmental feedback. This paper presents 6GAgentGym to provide closed-loop capability. The framework provides an interactive environment with 42 typed tools whose effect classification distinguishes read-only observation from state-mutating configuration, backed by a learned Experiment Model calibrated on NS-3 simulation data. 6G-Forge bootstraps closed-loop training trajectories from NS-3 seeds via iterative Self-Instruct generation with execution verification against the Experiment Model. Supervised fine-tuning on the resulting corpus followed by reinforcement learning with online closed-loop interaction enables an 8B open-source model to achieve comparable overall success rate to GPT-5 on the accompanying 6GAgentBench, with stronger performance on long-horizon tasks. Together, these components provide a viable path toward autonomous, closed-loop network management.
VitalBench: A Rigorous Multi-Center Benchmark for Long-Term Vital Sign Prediction in Intraoperative Care
Nov 14, 2025Intraoperative monitoring and prediction of vital signs are critical for ensuring patient safety and improving surgical outcomes. Despite recent advances in deep learning models for medical time-series forecasting, several challenges persist, including the lack of standardized benchmarks, incomplete data, and limited cross-center validation. To address these challenges, we introduce VitalBench, a novel benchmark specifically designed for intraoperative vital sign prediction. VitalBench includes data from over 4,000 surgeries across two independent medical centers, offering three evaluation tracks: complete data, incomplete data, and cross-center generalization. This framework reflects the real-world complexities of clinical practice, minimizing reliance on extensive preprocessing and incorporating masked loss techniques for robust and unbiased model evaluation. By providing a standardized and unified platform for model development and comparison, VitalBench enables researchers to focus on architectural innovation while ensuring consistency in data handling. This work lays the foundation for advancing predictive models for intraoperative vital sign forecasting, ensuring that these models are not only accurate but also robust and adaptable across diverse clinical environments. Our code and data are available at https://github.com/XiudingCai/VitalBench.
AdaptFly: Prompt-Guided Adaptation of Foundation Models for Low-Altitude UAV Networks
Nov 13, 2025Low-altitude Unmanned Aerial Vehicle (UAV) networks rely on robust semantic segmentation as a foundational enabler for distributed sensing-communication-control co-design across heterogeneous agents within the network. However, segmentation foundation models deteriorate quickly under weather, lighting, and viewpoint drift. Resource-limited UAVs cannot run gradient-based test-time adaptation, while resource-massive UAVs adapt independently, wasting shared experience. To address these challenges, we propose AdaptFly, a prompt-guided test-time adaptation framework that adjusts segmentation models without weight updates. AdaptFly features two complementary adaptation modes. For resource-limited UAVs, it employs lightweight token-prompt retrieval from a shared global memory. For resource-massive UAVs, it uses gradient-free sparse visual prompt optimization via Covariance Matrix Adaptation Evolution Strategy. An activation-statistic detector triggers adaptation, while cross-UAV knowledge pool consolidates prompt knowledge and enables fleet-wide collaboration with negligible bandwidth overhead. Extensive experiments on UAVid and VDD benchmarks, along with real-world UAV deployments under diverse weather conditions, demonstrate that AdaptFly significantly improves segmentation accuracy and robustness over static models and state-of-the-art TTA baselines. The results highlight a practical path to resilient, communication-efficient perception in the emerging low-altitude economy.
Probing then Editing: A Push-Pull Framework for Retain-Free Machine Unlearning in Industrial IoT
Nov 12, 2025In dynamic Industrial Internet of Things (IIoT) environments, models need the ability to selectively forget outdated or erroneous knowledge. However, existing methods typically rely on retain data to constrain model behavior, which increases computational and energy burdens and conflicts with industrial data silos and privacy compliance requirements. To address this, we propose a novel retain-free unlearning framework, referred to as Probing then Editing (PTE). PTE frames unlearning as a probe-edit process: first, it probes the decision boundary neighborhood of the model on the to-be-forgotten class via gradient ascent and generates corresponding editing instructions using the model's own predictions. Subsequently, a push-pull collaborative optimization is performed: the push branch actively dismantles the decision region of the target class using the editing instructions, while the pull branch applies masked knowledge distillation to anchor the model's knowledge on retained classes to their original states. Benefiting from this mechanism, PTE achieves efficient and balanced knowledge editing using only the to-be-forgotten data and the original model. Experimental results demonstrate that PTE achieves an excellent balance between unlearning effectiveness and model utility across multiple general and industrial benchmarks such as CWRU and SCUT-FD.
FaultGPT: Industrial Fault Diagnosis Question Answering System by Vision Language Models
Feb 21, 2025


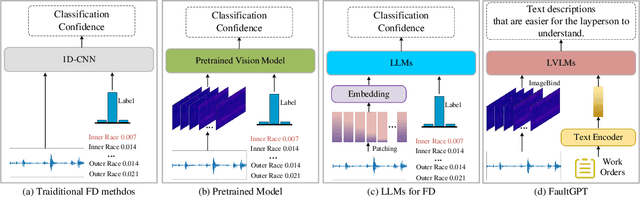
Recently, employing single-modality large language models based on mechanical vibration signals as Tuning Predictors has introduced new perspectives in intelligent fault diagnosis. However, the potential of these methods to leverage multimodal data remains underexploited, particularly in complex mechanical systems where relying on a single data source often fails to capture comprehensive fault information. In this paper, we present FaultGPT, a novel model that generates fault diagnosis reports directly from raw vibration signals. By leveraging large vision-language models (LVLM) and text-based supervision, FaultGPT performs end-to-end fault diagnosis question answering (FDQA), distinguishing itself from traditional classification or regression approaches. Specifically, we construct a large-scale FDQA instruction dataset for instruction tuning of LVLM. This dataset includes vibration time-frequency image-text label pairs and human instruction-ground truth pairs. To enhance the capability in generating high-quality fault diagnosis reports, we design a multi-scale cross-modal image decoder to extract fine-grained fault semantics and conducted instruction tuning without introducing additional training parameters into the LVLM. Extensive experiments, including fault diagnosis report generation, few-shot and zero-shot evaluation across multiple datasets, validate the superior performance and adaptability of FaultGPT in diverse industrial scenarios.
Improving Sequential Recommender Systems with Online and In-store User Behavior
Dec 03, 2024



Online e-commerce platforms have been extending in-store shopping, which allows users to keep the canonical online browsing and checkout experience while exploring in-store shopping. However, the growing transition between online and in-store becomes a challenge to sequential recommender systems for future online interaction prediction due to the lack of holistic modeling of hybrid user behaviors (online and in-store). The challenges are twofold. First, combining online and in-store user behavior data into a single data schema and supporting multiple stages in the model life cycle (pre-training, training, inference, etc.) organically needs a new data pipeline design. Second, online recommender systems, which solely rely on online user behavior sequences, must be redesigned to support online and in-store user data as input under the sequential modeling setting. To overcome the first challenge, we propose a hybrid, omnichannel data pipeline to compile online and in-store user behavior data by caching information from diverse data sources. Later, we introduce a model-agnostic encoder module to the sequential recommender system to interpret the user in-store transaction and augment the modeling capacity for better online interaction prediction given the hybrid user behavior.
Towards General Industrial Intelligence: A Survey on IIoT-Enhanced Continual Large Models
Sep 02, 2024



Currently, most applications in the Industrial Internet of Things (IIoT) still rely on CNN-based neural networks. Although Transformer-based large models (LMs), including language, vision, and multimodal models, have demonstrated impressive capabilities in AI-generated content (AIGC), their application in industrial domains, such as detection, planning, and control, remains relatively limited. Deploying pre-trained LMs in industrial environments often encounters the challenge of stability and plasticity due to the complexity of tasks, the diversity of data, and the dynamic nature of user demands. To address these challenges, the pre-training and fine-tuning strategy, coupled with continual learning, has proven to be an effective solution, enabling models to adapt to dynamic demands while continuously optimizing their inference and decision-making capabilities. This paper surveys the integration of LMs into IIoT-enhanced General Industrial Intelligence (GII), focusing on two key areas: LMs for GII and LMs on GII. The former focuses on leveraging LMs to provide optimized solutions for industrial application challenges, while the latter investigates continuous optimization of LMs learning and inference capabilities in collaborative scenarios involving industrial devices, edge computing, and cloud computing. This paper provides insights into the future development of GII, aiming to establish a comprehensive theoretical framework and research direction for GII, thereby advancing GII towards a more general and adaptive future.
Edge-Cloud Collaborative Motion Planning for Autonomous Driving with Large Language Models
Aug 19, 2024Integrating large language models (LLMs) into autonomous driving enhances personalization and adaptability in open-world scenarios. However, traditional edge computing models still face significant challenges in processing complex driving data, particularly regarding real-time performance and system efficiency. To address these challenges, this study introduces EC-Drive, a novel edge-cloud collaborative autonomous driving system with data drift detection capabilities. EC-Drive utilizes drift detection algorithms to selectively upload critical data, including new obstacles and traffic pattern changes, to the cloud for processing by GPT-4, while routine data is efficiently managed by smaller LLMs on edge devices. This approach not only reduces inference latency but also improves system efficiency by optimizing communication resource use. Experimental validation confirms the system's robust processing capabilities and practical applicability in real-world driving conditions, demonstrating the effectiveness of this edge-cloud collaboration framework. Our data and system demonstration will be released at https://sites.google.com/view/ec-drive.
Continual Learning with Diffusion-based Generative Replay for Industrial Streaming Data
Jun 22, 2024



The Industrial Internet of Things (IIoT) integrates interconnected sensors and devices to support industrial applications, but its dynamic environments pose challenges related to data drift. Considering the limited resources and the need to effectively adapt models to new data distributions, this paper introduces a Continual Learning (CL) approach, i.e., Distillation-based Self-Guidance (DSG), to address challenges presented by industrial streaming data via a novel generative replay mechanism. DSG utilizes knowledge distillation to transfer knowledge from the previous diffusion-based generator to the updated one, improving both the stability of the generator and the quality of reproduced data, thereby enhancing the mitigation of catastrophic forgetting. Experimental results on CWRU, DSA, and WISDM datasets demonstrate the effectiveness of DSG. DSG outperforms the state-of-the-art baseline in accuracy, demonstrating improvements ranging from 2.9% to 5.0% on key datasets, showcasing its potential for practical industrial applications.
LLMs with User-defined Prompts as Generic Data Operators for Reliable Data Processing
Dec 26, 2023Data processing is one of the fundamental steps in machine learning pipelines to ensure data quality. Majority of the applications consider the user-defined function (UDF) design pattern for data processing in databases. Although the UDF design pattern introduces flexibility, reusability and scalability, the increasing demand on machine learning pipelines brings three new challenges to this design pattern -- not low-code, not dependency-free and not knowledge-aware. To address these challenges, we propose a new design pattern that large language models (LLMs) could work as a generic data operator (LLM-GDO) for reliable data cleansing, transformation and modeling with their human-compatible performance. In the LLM-GDO design pattern, user-defined prompts (UDPs) are used to represent the data processing logic rather than implementations with a specific programming language. LLMs can be centrally maintained so users don't have to manage the dependencies at the run-time. Fine-tuning LLMs with domain-specific data could enhance the performance on the domain-specific tasks which makes data processing knowledge-aware. We illustrate these advantages with examples in different data processing tasks. Furthermore, we summarize the challenges and opportunities introduced by LLMs to provide a complete view of this design pattern for more discussions.