 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AMPERE: AMR-Aware Prefix for Generation-Based Event Argument Extraction Model
May 26, 2023
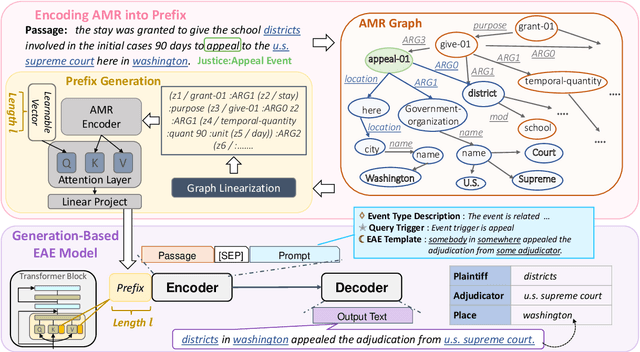
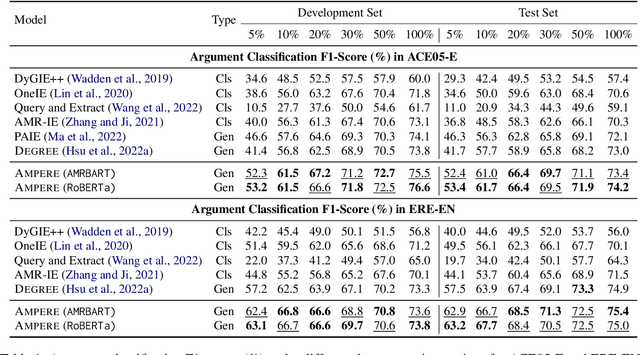
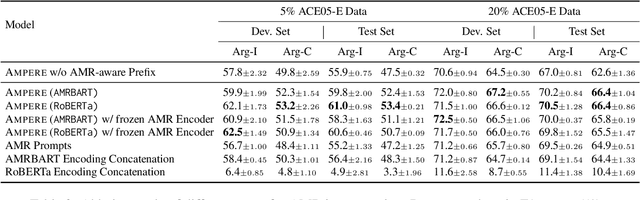
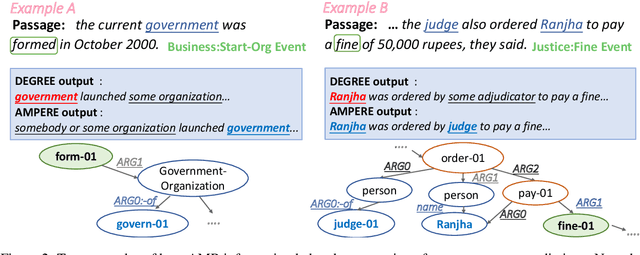
Event argument extraction (EAE) identifies event arguments and their specific roles for a given event. Recent advancement in generation-based EAE models has shown great performance and generalizability over classification-based models. However, existing generation-based EAE models mostly focus on problem re-formulation and prompt design, without incorporating additional information that has been shown to be effective for classification-based models, such as the abstract meaning representation (AMR) of the input passages. Incorporating such information into generation-based models is challenging due to the heterogeneous nature of the natural language form prevalently used in generation-based models and the structured form of AMRs. In this work, we study strategies to incorporate AMR into generation-based EAE models. We propose AMPERE, which generates AMR-aware prefixes for every layer of the generation model. Thus, the prefix introduces AMR information to the generation-based EAE model and then improves the generation. We also introduce an adjusted copy mechanism to AMPERE to help overcome potential noises brought by the AMR graph. Comprehensive experiments and analyses on ACE2005 and ERE datasets show that AMPERE can get 4% - 10% absolute F1 score improvements with reduced training data and it is in general powerful across different training sizes.
Is Centralized Training with Decentralized Execution Framework Centralized Enough for MARL?
May 27, 2023
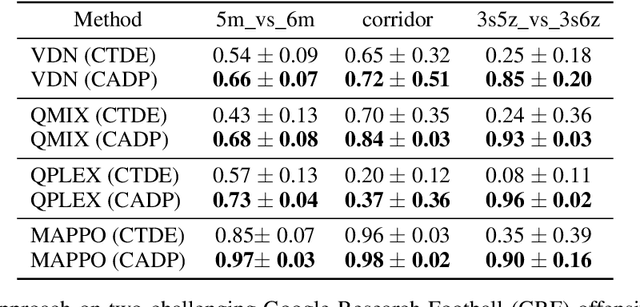
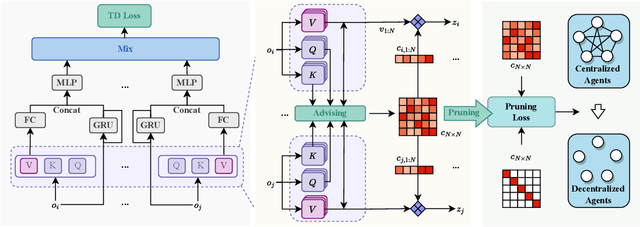
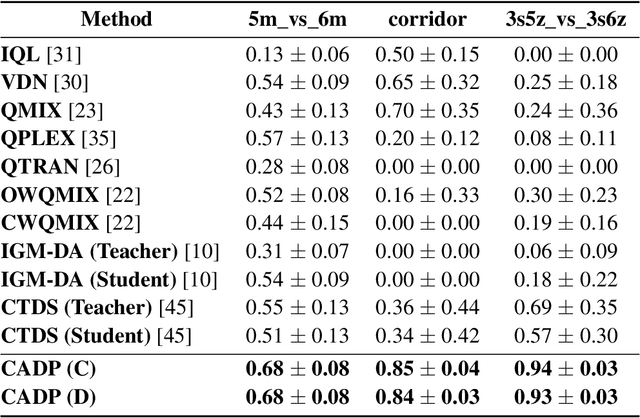
Centralized Training with Decentralized Execution (CTDE) has recently emerged as a popular framework for cooperative Multi-Agent Reinforcement Learning (MARL), where agents can use additional global state information to guide training in a centralized way and make their own decisions only based on decentralized local policies. Despite the encouraging results achieved, CTDE makes an independence assumption on agent policies, which limits agents to adopt global cooperative information from each other during centralized training. Therefore, we argue that existing CTDE methods cannot fully utilize global information for training, leading to an inefficient joint-policy exploration and even suboptimal results. In this paper, we introduce a novel Centralized Advising and Decentralized Pruning (CADP) framework for multi-agent reinforcement learning, that not only enables an efficacious message exchange among agents during training but also guarantees the independent policies for execution. Firstly, CADP endows agents the explicit communication channel to seek and take advices from different agents for more centralized training. To further ensure the decentralized execution, we propose a smooth model pruning mechanism to progressively constraint the agent communication into a closed one without degradation in agent cooperation capability. Empirical evaluations on StarCraft II micromanagement and Google Research Football benchmarks demonstrate that the proposed framework achieves superior performance compared with the state-of-the-art counterparts. Our code will be made publicly available.
Guided Attention for Next Active Object @ EGO4D STA Challenge
May 25, 2023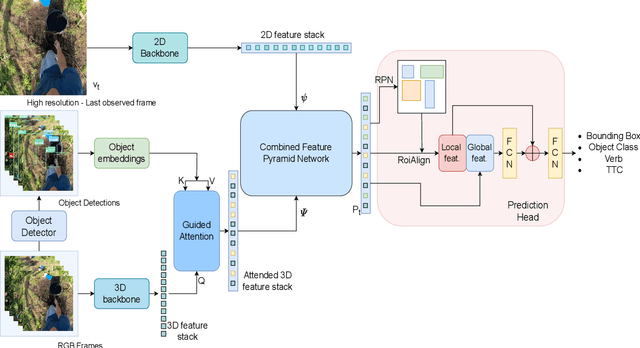
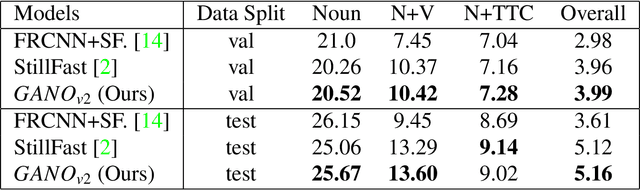
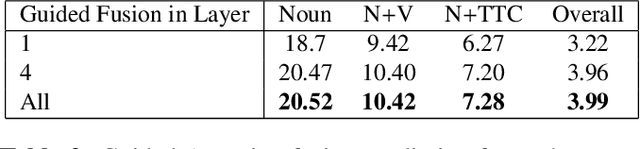
In this technical report, we describe the Guided-Attention mechanism based solution for the short-term anticipation (STA) challenge for the EGO4D challenge. It combines the object detections, and the spatiotemporal features extracted from video clips, enhancing the motion and contextual information, and further decoding the object-centric and motion-centric information to address the problem of STA in egocentric videos. For the challenge, we build our model on top of StillFast with Guided Attention applied on fast network. Our model obtains better performance on the validation set and also achieves state-of-the-art (SOTA) results on the challenge test set for EGO4D Short-Term Object Interaction Anticipation Challenge.
Tri-level Joint Natural Language Understanding for Multi-turn Conversational Datasets
May 28, 2023
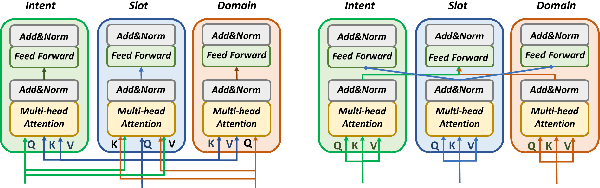
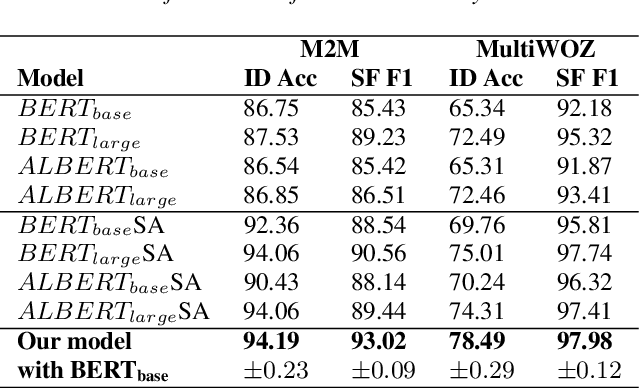
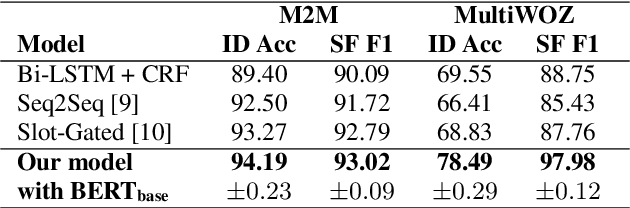
Natural language understanding typically maps single utterances to a dual level semantic frame, sentence level intent and slot labels at the word level. The best performing models force explicit interaction between intent detection and slot filling. We present a novel tri-level joint natural language understanding approach, adding domain, and explicitly exchange semantic information between all levels. This approach enables the use of multi-turn datasets which are a more natural conversational environment than single utterance. We evaluate our model on two multi-turn datasets for which we are the first to conduct joint slot-filling and intent detection. Our model outperforms state-of-the-art joint models in slot filling and intent detection on multi-turn data sets. We provide an analysis of explicit interaction locations between the layers. We conclude that including domain information improves model performance.
Fine-Grained Human Feedback Gives Better Rewards for Language Model Training
Jun 02, 2023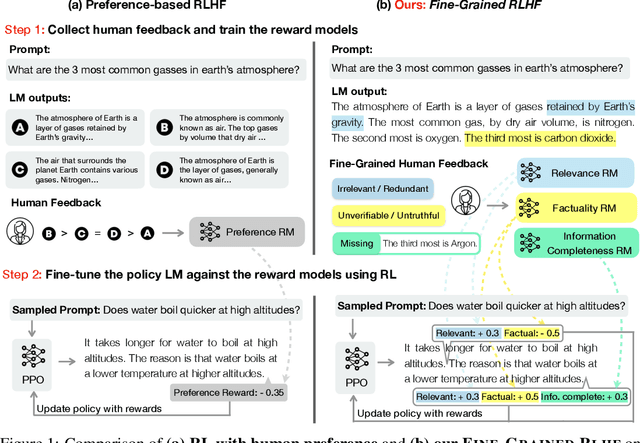
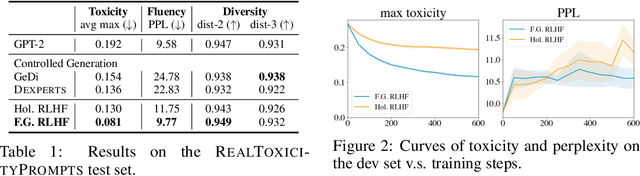
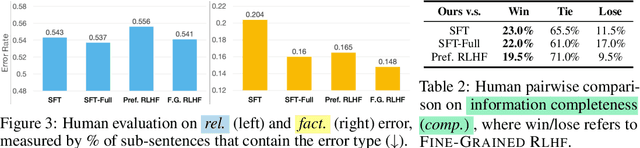
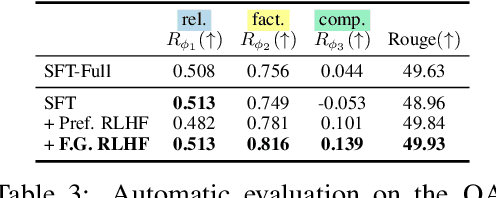
Language models (LMs) often exhibit undesirable text generation behaviors, including generating false, toxic, or irrelevant outputs. Reinforcement learning from human feedback (RLHF) - where human preference judgments on LM outputs are transformed into a learning signal - has recently shown promise in addressing these issues. However, such holistic feedback conveys limited information on long text outputs; it does not indicate which aspects of the outputs influenced user preference; e.g., which parts contain what type(s) of errors. In this paper, we use fine-grained human feedback (e.g., which sentence is false, which sub-sentence is irrelevant) as an explicit training signal. We introduce Fine-Grained RLHF, a framework that enables training and learning from reward functions that are fine-grained in two respects: (1) density, providing a reward after every segment (e.g., a sentence) is generated; and (2) incorporating multiple reward models associated with different feedback types (e.g., factual incorrectness, irrelevance, and information incompleteness). We conduct experiments on detoxification and long-form question answering to illustrate how learning with such reward functions leads to improved performance, supported by both automatic and human evaluation. Additionally, we show that LM behaviors can be customized using different combinations of fine-grained reward models. We release all data, collected human feedback, and codes at https://FineGrainedRLHF.github.io.
The Battle of Information Representations: Comparing Sentiment and Semantic Features for Forecasting Market Trends
Mar 24, 2023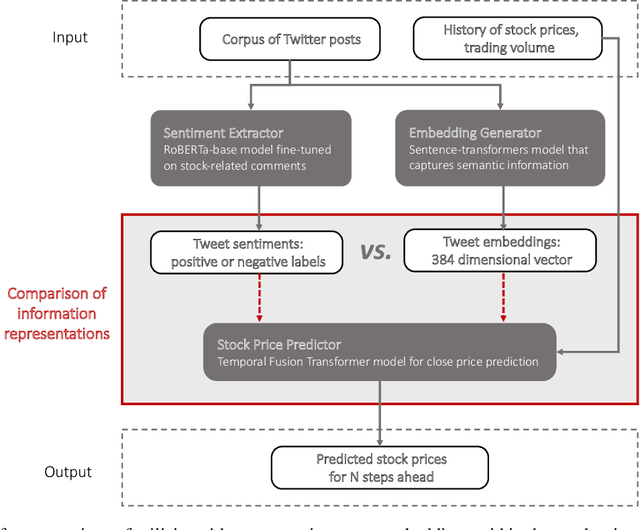
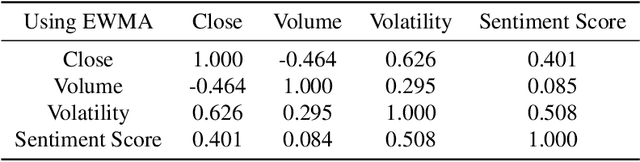
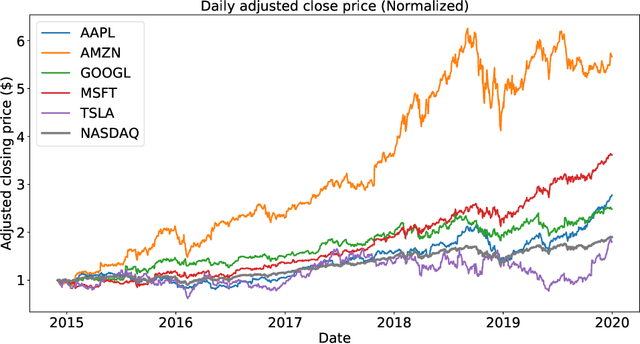

The study of the stock market with the attraction of machine learning approaches is a major direction for revealing hidden market regularities. This knowledge contributes to a profound understanding of financial market dynamics and getting behavioural insights, which could hardly be discovered with traditional analytical methods. Stock prices are inherently interrelated with world events and social perception. Thus, in constructing the model for stock price prediction, the critical stage is to incorporate such information on the outside world, reflected through news and social media posts. To accommodate this, researchers leverage the implicit or explicit knowledge representations: (1) sentiments extracted from the texts or (2) raw text embeddings. However, there is too little research attention to the direct comparison of these approaches in terms of the influence on the predictive power of financial models. In this paper, we aim to close this gap and figure out whether the semantic features in the form of contextual embeddings are more valuable than sentiment attributes for forecasting market trends. We consider the corpus of Twitter posts related to the largest companies by capitalization from NASDAQ and their close prices. To start, we demonstrate the connection of tweet sentiments with the volatility of companies' stock prices. Convinced of the existing relationship, we train Temporal Fusion Transformer models for price prediction supplemented with either tweet sentiments or tweet embeddings. Our results show that in the substantially prevailing number of cases, the use of sentiment features leads to higher metrics. Noteworthy, the conclusions are justifiable within the considered scenario involving Twitter posts and stocks of the biggest tech companies.
Semantic Segmentation on VSPW Dataset through Contrastive Loss and Multi-dataset Training Approach
Jun 06, 2023
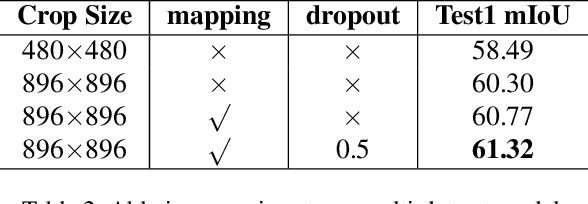
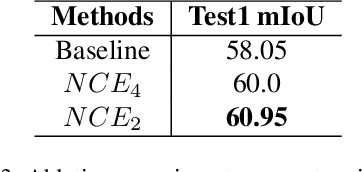
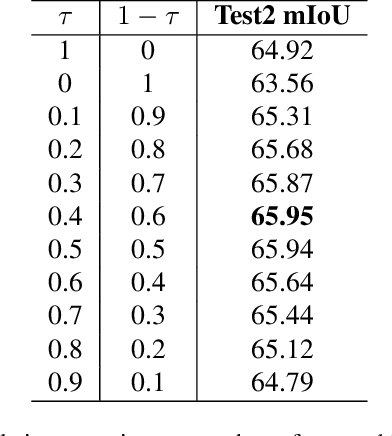
Video scene parsing incorporates temporal information, which can enhance the consistency and accuracy of predictions compared to image scene parsing. The added temporal dimension enables a more comprehensive understanding of the scene, leading to more reliable results. This paper presents the winning solution of the CVPR2023 workshop for video semantic segmentation, focusing on enhancing Spatial-Temporal correlations with contrastive loss. We also explore the influence of multi-dataset training by utilizing a label-mapping technique. And the final result is aggregating the output of the above two models. Our approach achieves 65.95% mIoU performance on the VSPW dataset, ranked 1st place on the VSPW challenge at CVPR 2023.
High-bandwidth Close-Range Information Transport through Light Pipes
Jan 19, 2023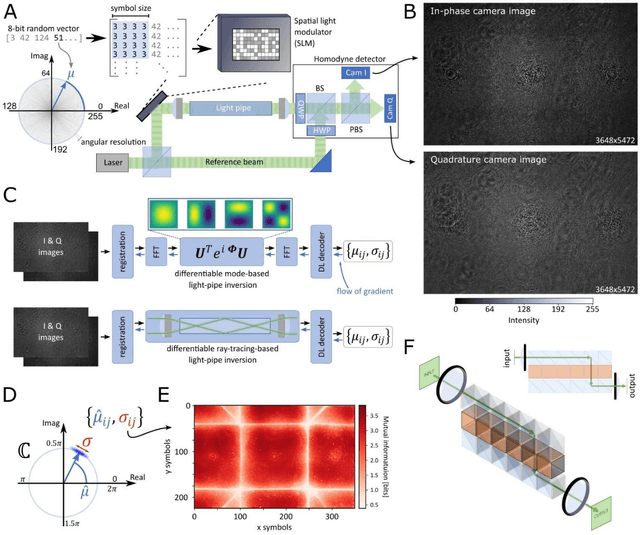
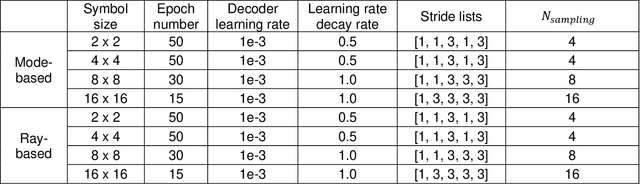

Image retrieval after propagation through multi-mode fibers is gaining attention due to their capacity to confine light and efficiently transport it over distances in a compact system. Here, we propose a generally applicable information-theoretic framework to transmit maximal-entropy (data) images and maximize the information transmission over sub-meter distances, a crucial capability that allows optical storage applications to scale and address different parts of storage media. To this end, we use millimeter-sized square optical waveguides to image a megapixel 8-bit spatial-light modulator. Data is thus represented as a 2D array of 8-bit values (symbols). Transmitting 100000s of symbols requires innovation beyond transmission matrix approaches. Deep neural networks have been recently utilized to retrieve images, but have been limited to small (thousands of symbols) and natural looking (low entropy) images. We maximize information transmission by combining a bandwidth-optimized homodyne detector with a differentiable hybrid neural-network consisting of a digital twin of the experiment setup and a U-Net. For the digital twin, we implement and compare a differentiable mode-based twin with a differentiable ray-based twin. Importantly, the latter can adapt to manufacturing-related setup imperfections during training which we show to be crucial. Our pipeline is trained end-to-end to recover digital input images while maximizing the achievable information page size based on a differentiable mutual-information estimator. We demonstrate retrieval of 66 kB at maximum with 1.7 bit per symbol on average with a range of 0.3 - 3.4 bit.
Basis Pursuit Denoising via Recurrent Neural Network Applied to Super-resolving SAR Tomography
May 23, 2023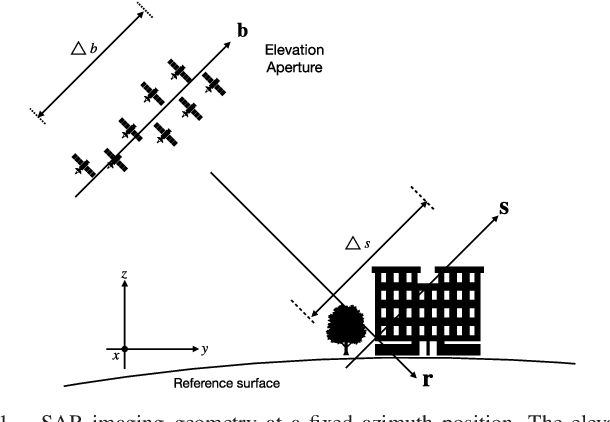
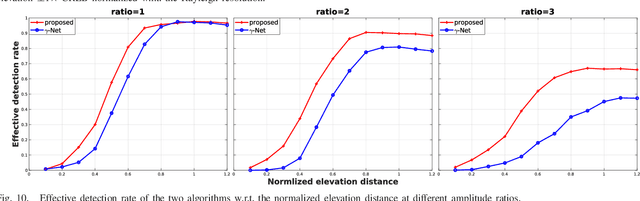
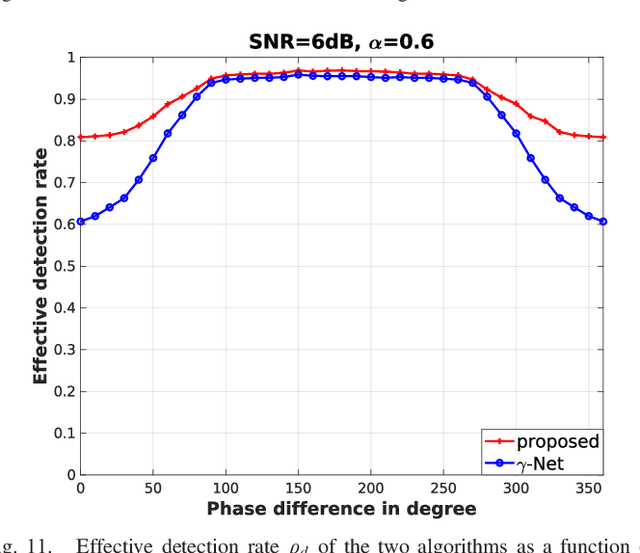

Finding sparse solutions of underdetermined linear systems commonly requires the solving of L1 regularized least squares minimization problem, which is also known as the basis pursuit denoising (BPDN). They are computationally expensive since they cannot be solved analytically. An emerging technique known as deep unrolling provided a good combination of the descriptive ability of neural networks, explainable, and computational efficiency for BPDN. Many unrolled neural networks for BPDN, e.g. learned iterative shrinkage thresholding algorithm and its variants, employ shrinkage functions to prune elements with small magnitude. Through experiments on synthetic aperture radar tomography (TomoSAR), we discover the shrinkage step leads to unavoidable information loss in the dynamics of networks and degrades the performance of the model. We propose a recurrent neural network (RNN) with novel sparse minimal gated units (SMGUs) to solve the information loss issue. The proposed RNN architecture with SMGUs benefits from incorporating historical information into optimization, and thus effectively preserves full information in the final output. Taking TomoSAR inversion as an example, extensive simulations demonstrated that the proposed RNN outperforms the state-of-the-art deep learning-based algorithm in terms of super-resolution power as well as generalization ability. It achieved a 10% to 20% higher double scatterers detection rate and is less sensitive to phase and amplitude ratio differences between scatterers. Test on real TerraSAR-X spotlight images also shows a high-quality 3-D reconstruction of the test site.
Guiding Language Models of Code with Global Context using Monitors
Jun 19, 2023
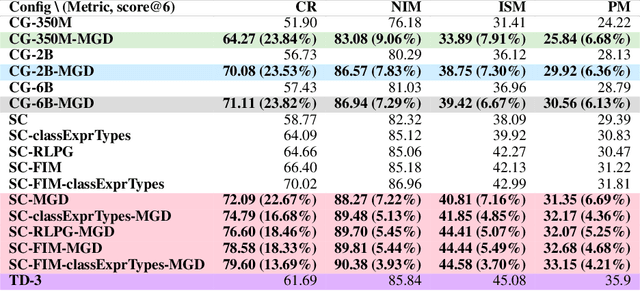
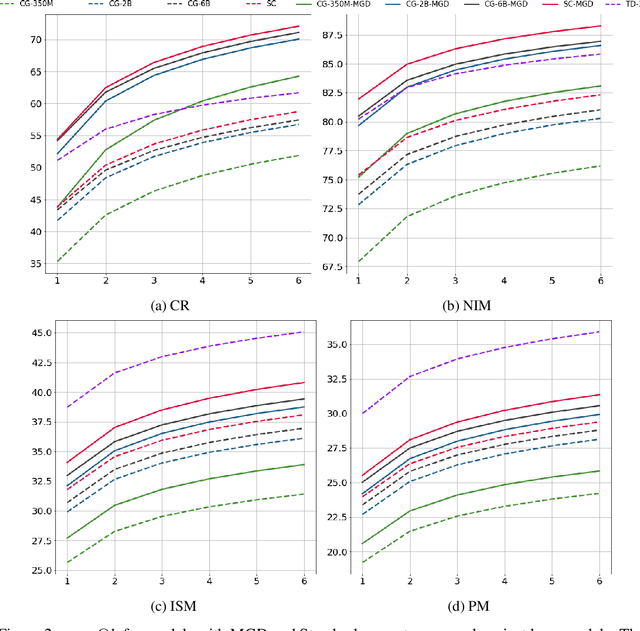
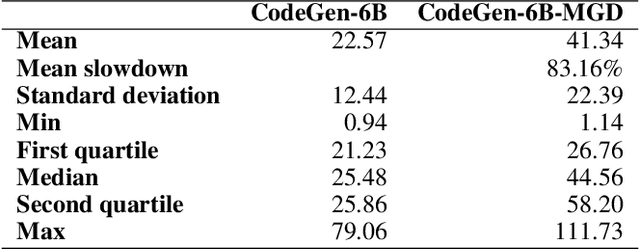
Language models of code (LMs) work well when the surrounding code in the vicinity of generation provides sufficient context. This is not true when it becomes necessary to use types or functionality defined in another module or library, especially those not seen during training. LMs suffer from limited awareness of such global context and end up hallucinating, e.g., using types defined in other files incorrectly. Recent work tries to overcome this issue by retrieving global information to augment the local context. However, this bloats the prompt or requires architecture modifications and additional training. Integrated development environments (IDEs) assist developers by bringing the global context at their fingertips using static analysis. We extend this assistance, enjoyed by developers, to the LMs. We propose a notion of monitors that use static analysis in the background to guide the decoding. Unlike a priori retrieval, static analysis is invoked iteratively during the entire decoding process, providing the most relevant suggestions on demand. We demonstrate the usefulness of our proposal by monitoring for type-consistent use of identifiers whenever an LM generates code for object dereference. To evaluate our approach, we curate PragmaticCode, a dataset of open-source projects with their development environments. On models of varying parameter scale, we show that monitor-guided decoding consistently improves the ability of an LM to not only generate identifiers that match the ground truth but also improves compilation rates and agreement with ground truth. We find that LMs with fewer parameters, when guided with our monitor, can outperform larger LMs. With monitor-guided decoding, SantaCoder-1.1B achieves better compilation rate and next-identifier match than the much larger text-davinci-003 model. The datasets and code will be released at https://aka.ms/monitors4codegen .