 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape of Thought: When Distribution Matters More than Correctness in Reasoning Tasks
Dec 24, 2025We present the surprising finding that a language model's reasoning capabilities can be improved by training on synthetic datasets of chain-of-thought (CoT) traces from more capable models, even when all of those traces lead to an incorrect final answer. Our experiments show this approach can yield better performance on reasoning tasks than training on human-annotated datasets. We hypothesize that two key factors explain this phenomenon: first, the distribution of synthetic data is inherently closer to the language model's own distribution, making it more amenable to learning. Second, these `incorrect' traces are often only partially flawed and contain valid reasoning steps from which the model can learn. To further test the first hypothesis, we use a language model to paraphrase human-annotated traces -- shifting their distribution closer to the model's own distribution -- and show that this improves performance. For the second hypothesis, we introduce increasingly flawed CoT traces and study to what extent models are tolerant to these flaws. We demonstrate our findings across various reasoning domains like math, algorithmic reasoning and code generation using MATH, GSM8K, Countdown and MBPP datasets on various language models ranging from 1.5B to 9B across Qwen, Llama, and Gemma models. Our study shows that curating datasets that are closer to the model's distribution is a critical aspect to consider. We also show that a correct final answer is not always a reliable indicator of a faithful reasoning process.
Characterizing Deep Research: A Benchmark and Formal Definition
Aug 06, 2025Information tasks such as writing surveys or analytical reports require complex search and reasoning, and have recently been grouped under the umbrella of \textit{deep research} -- a term also adopted by recent models targeting these capabilities. Despite growing interest, the scope of the deep research task remains underdefined and its distinction from other reasoning-intensive problems is poorly understood. In this paper, we propose a formal characterization of the deep research (DR) task and introduce a benchmark to evaluate the performance of DR systems. We argue that the core defining feature of deep research is not the production of lengthy report-style outputs, but rather the high fan-out over concepts required during the search process, i.e., broad and reasoning-intensive exploration. To enable objective evaluation, we define DR using an intermediate output representation that encodes key claims uncovered during search-separating the reasoning challenge from surface-level report generation. Based on this formulation, we propose a diverse, challenging benchmark LiveDRBench with 100 challenging tasks over scientific topics (e.g., datasets, materials discovery, prior art search) and public interest events (e.g., flight incidents, movie awards). Across state-of-the-art DR systems, F1 score ranges between 0.02 and 0.72 for any sub-category. OpenAI's model performs the best with an overall F1 score of 0.55. Analysis of reasoning traces reveals the distribution over the number of referenced sources, branching, and backtracking events executed by current DR systems, motivating future directions for improving their search mechanisms and grounding capabilities. The benchmark is available at https://github.com/microsoft/LiveDRBench.
Exploring Continual Fine-Tuning for Enhancing Language Ability in Large Language Model
Oct 21, 2024



A common challenge towards the adaptability of Large Language Models (LLMs) is their ability to learn new languages over time without hampering the model's performance on languages in which the model is already proficient (usually English). Continual fine-tuning (CFT) is the process of sequentially fine-tuning an LLM to enable the model to adapt to downstream tasks with varying data distributions and time shifts. This paper focuses on the language adaptability of LLMs through CFT. We study a two-phase CFT process in which an English-only end-to-end fine-tuned LLM from Phase 1 (predominantly Task Ability) is sequentially fine-tuned on a multilingual dataset -- comprising task data in new languages -- in Phase 2 (predominantly Language Ability). We observe that the ``similarity'' of Phase 2 tasks with Phase 1 determines the LLM's adaptability. For similar phase-wise datasets, the LLM after Phase 2 does not show deterioration in task ability. In contrast, when the phase-wise datasets are not similar, the LLM's task ability deteriorates. We test our hypothesis on the open-source \mis\ and \llm\ models with multiple phase-wise dataset pairs. To address the deterioration, we analyze tailored variants of two CFT methods: layer freezing and generative replay. Our findings demonstrate their effectiveness in enhancing the language ability of LLMs while preserving task performance, in comparison to relevant baselines.
InversionView: A General-Purpose Method for Reading Information from Neural Activations
May 27, 2024



The inner workings of neural networks can be better understood if we can fully decipher the information encoded in neural activations. In this paper, we argue that this information is embodied by the subset of inputs that give rise to similar activations. Computing such subsets is nontrivial as the input space is exponentially large. We propose InversionView, which allows us to practically inspect this subset by sampling from a trained decoder model conditioned on activations. This helps uncover the information content of activation vectors, and facilitates understanding of the algorithms implemented by transformer models. We present three case studies where we investigate models ranging from small transformers to GPT-2. In these studies, we demonstrate the characteristics of our method, show the distinctive advantages it offers, and provide causally verified circuits.
Learning Syntax Without Planting Trees: Understanding When and Why Transformers Generalize Hierarchically
Apr 25, 2024Transformers trained on natural language data have been shown to learn its hierarchical structure and generalize to sentences with unseen syntactic structures without explicitly encoding any structural bias. In this work, we investigate sources of inductive bias in transformer models and their training that could cause such generalization behavior to emerge. We extensively experiment with transformer models trained on multiple synthetic datasets and with different training objectives and show that while other objectives e.g. sequence-to-sequence modeling, prefix language modeling, often failed to lead to hierarchical generalization, models trained with the language modeling objective consistently learned to generalize hierarchically. We then conduct pruning experiments to study how transformers trained with the language modeling objective encode hierarchical structure. When pruned, we find joint existence of subnetworks within the model with different generalization behaviors (subnetworks corresponding to hierarchical structure and linear order). Finally, we take a Bayesian perspective to further uncover transformers' preference for hierarchical generalization: We establish a correlation between whether transformers generalize hierarchically on a dataset and whether the simplest explanation of that dataset is provided by a hierarchical grammar compared to regular grammars exhibiting linear generalization.
Guiding Language Models of Code with Global Context using Monitors
Jun 19, 2023



Language models of code (LMs) work well when the surrounding code in the vicinity of generation provides sufficient context. This is not true when it becomes necessary to use types or functionality defined in another module or library, especially those not seen during training. LMs suffer from limited awareness of such global context and end up hallucinating, e.g., using types defined in other files incorrectly. Recent work tries to overcome this issue by retrieving global information to augment the local context. However, this bloats the prompt or requires architecture modifications and additional training. Integrated development environments (IDEs) assist developers by bringing the global context at their fingertips using static analysis. We extend this assistance, enjoyed by developers, to the LMs. We propose a notion of monitors that use static analysis in the background to guide the decoding. Unlike a priori retrieval, static analysis is invoked iteratively during the entire decoding process, providing the most relevant suggestions on demand. We demonstrate the usefulness of our proposal by monitoring for type-consistent use of identifiers whenever an LM generates code for object dereference. To evaluate our approach, we curate PragmaticCode, a dataset of open-source projects with their development environments. On models of varying parameter scale, we show that monitor-guided decoding consistently improves the ability of an LM to not only generate identifiers that match the ground truth but also improves compilation rates and agreement with ground truth. We find that LMs with fewer parameters, when guided with our monitor, can outperform larger LMs. With monitor-guided decoding, SantaCoder-1.1B achieves better compilation rate and next-identifier match than the much larger text-davinci-003 model. The datasets and code will be released at https://aka.ms/monitors4codegen .
In-Context Learning through the Bayesian Prism
Jun 08, 2023



In-context learning is one of the surprising and useful features of large language models. How it works is an active area of research. Recently, stylized meta-learning-like setups have been devised that train these models on a sequence of input-output pairs $(x, f(x))$ from a function class using the language modeling loss and observe generalization to unseen functions from the same class. One of the main discoveries in this line of research has been that for several problems such as linear regression, trained transformers learn algorithms for learning functions in context. However, the inductive biases of these models resulting in this behavior are not clearly understood. A model with unlimited training data and compute is a Bayesian predictor: it learns the pretraining distribution. It has been shown that high-capacity transformers mimic the Bayesian predictor for linear regression. In this paper, we show empirical evidence of transformers exhibiting the behavior of this ideal learner across different linear and non-linear function classes. We also extend the previous setups to work in the multitask setting and verify that transformers can do in-context learning in this setup as well and the Bayesian perspective sheds light on this setting also. Finally, via the example of learning Fourier series, we study the inductive bias for in-context learning. We find that in-context learning may or may not have simplicity bias depending on the pretraining data distribution.
A Theory of Emergent In-Context Learning as Implicit Structure Induction
Mar 14, 2023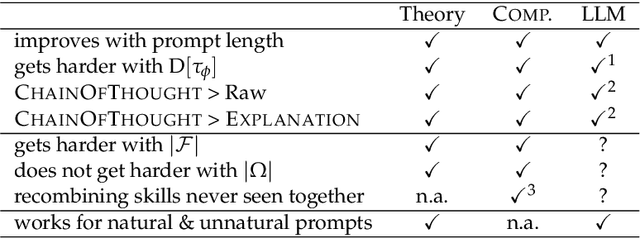
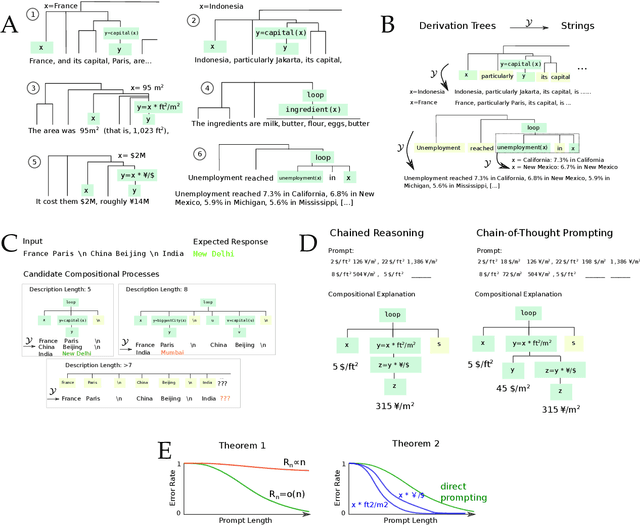


Scaling large language models (LLMs) leads to an emergent capacity to learn in-context from example demonstrations. Despite progress, theoretical understanding of this phenomenon remains limited. We argue that in-context learning relies on recombination of compositional operations found in natural language data. We derive an information-theoretic bound showing how in-context learning abilities arise from generic next-token prediction when the pretraining distribution has sufficient amounts of compositional structure, under linguistically motivated assumptions. A second bound provides a theoretical justification for the empirical success of prompting LLMs to output intermediate steps towards an answer. To validate theoretical predictions, we introduce a controlled setup for inducing in-context learning; unlike previous approaches, it accounts for the compositional nature of language. Trained transformers can perform in-context learning for a range of tasks, in a manner consistent with the theoretical results. Mirroring real-world LLMs in a miniature setup, in-context learning emerges when scaling parameters and data, and models perform better when prompted to output intermediate steps. Probing shows that in-context learning is supported by a representation of the input's compositional structure. Taken together, these results provide a step towards theoretical understanding of emergent behavior in large language models.
Towards a Mathematics Formalisation Assistant using Large Language Models
Nov 14, 2022



Mathematics formalisation is the task of writing mathematics (i.e., definitions, theorem statements, proofs) in natural language, as found in books and papers, into a formal language that can then be checked for correctness by a program. It is a thriving activity today, however formalisation remains cumbersome. In this paper, we explore the abilities of a large language model (Codex) to help with formalisation in the Lean theorem prover. We find that with careful input-dependent prompt selection and postprocessing, Codex is able to formalise short mathematical statements at undergrad level with nearly 75\% accuracy for $120$ theorem statements. For proofs quantitative analysis is infeasible and we undertake a detailed case study. We choose a diverse set of $13$ theorems at undergrad level with proofs that fit in two-three paragraphs. We show that with a new prompting strategy Codex can formalise these proofs in natural language with at least one out of twelve Codex completion being easy to repair into a complete proof. This is surprising as essentially no aligned data exists for formalised mathematics, particularly for proofs. These results suggest that large language models are a promising avenue towards fully or partially automating formalisation.
When Can Transformers Ground and Compose: Insights from Compositional Generalization Benchmarks
Oct 31, 2022Humans can reason compositionally whilst grounding language utterances to the real world. Recent benchmarks like ReaSCAN use navigation tasks grounded in a grid world to assess whether neural models exhibit similar capabilities. In this work, we present a simple transformer-based model that outperforms specialized architectures on ReaSCAN and a modified version of gSCAN. On analyzing the task, we find that identifying the target location in the grid world is the main challenge for the models. Furthermore, we show that a particular split in ReaSCAN, which tests depth generalization, is unfair. On an amended version of this split, we show that transformers can generalize to deeper input structures. Finally, we design a simpler grounded compositional generalization task, RefEx, to investigate how transformers reason compositionally. We show that a single self-attention layer with a single head generalizes to novel combinations of object attributes. Moreover, we derive a precise mathematical construction of the transformer's computations from the learned network. Overall, we provide valuable insights about the grounded compositional generalization task and the behaviour of transformers on it, which would be useful for researchers working in this area.